Recognition: 2 theorem links
· Lean TheoremOperationalizing Cybersecurity Governance for Mitigation Planning with Attack-Path Modeling and Reinforcement Learning
Pith reviewed 2026-05-12 02:32 UTC · model grok-4.3
The pith
Mapping maturity assessments to adversary techniques lets reinforcement learning select budget-constrained mitigations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that linking CSF maturity assessments to ATT&CK mitigation capabilities, then embedding a variable-order Markov model of attack sequences inside a deep reinforcement learning environment, enables the generation of stable, resource-aware mitigation policies that optimize risk reduction while handling multiple concurrent adversaries and realistic costs.
What carries the argument
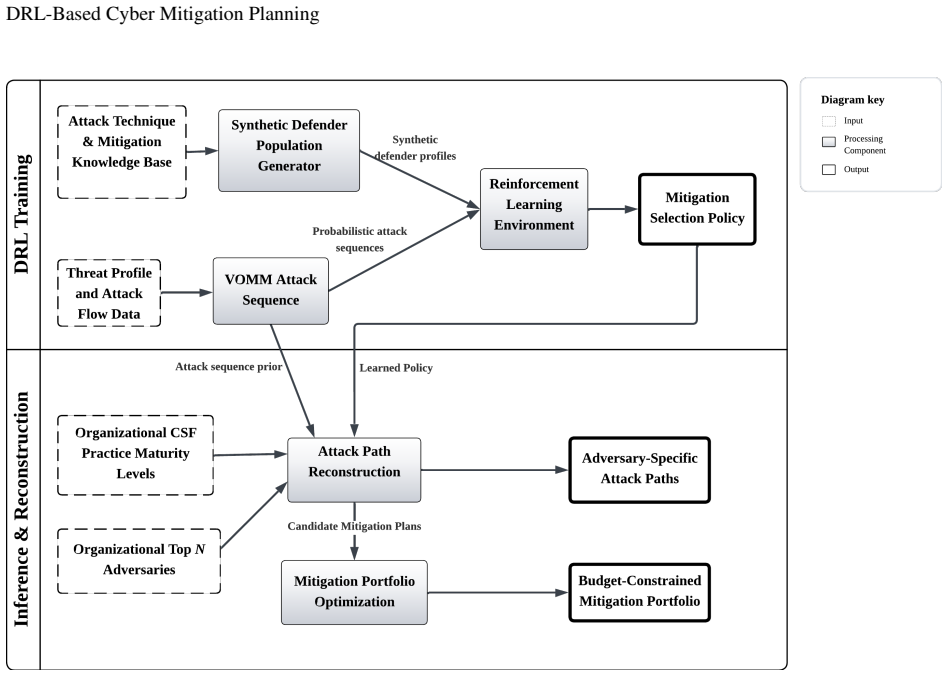
The central mechanism is the DRL environment that uses the CSF-to-ATT&CK mapping to define available actions and a variable-order Markov model trained on ATT&CK sequences to reconstruct attack paths via beam search for reward calculation and joint optimization under budget constraints.
If this is right
- Mitigation plans can be derived directly from standard CSF maturity assessments without manual translation.
- Defense choices adapt to observed adversary sequences rather than fixed rules or checklists.
- Explicit budget constraints produce measurable cost-risk trade-offs in the output policies.
- Stable policies emerge across multiple reward formulations and environment configurations.
- Concurrent adversary simulation yields more robust mitigation recommendations than single-path models.
Where Pith is reading between the lines
- The same mapping-plus-simulation structure could apply to other governance frameworks by building equivalent technique linkages.
- Generated plans might serve as initial inputs for automated security orchestration systems that enforce controls dynamically.
- Periodic retraining of the Markov model on fresh incident data could keep recommendations aligned with evolving threats.
- Comparison of model outputs against historical breach data would offer an independent check on the adversary simulation accuracy.
Load-bearing premise
The variable-order Markov model trained on ATT&CK sequences accurately captures real adversary behavior, and the CSF-to-ATT&CK mapping faithfully converts organizational maturity into usable mitigation options.
What would settle it
A controlled red-team test that applies the generated mitigation plans yet still records high attack success rates using ATT&CK techniques outside the training sequences would falsify the effectiveness of the resulting strategies.
Figures



read the original abstract
We address a fundamental challenge in cybersecurity operations of translating governance frameworks into actionable mitigation decisions under realistic resource constraints. Frameworks such as the NIST Cybersecurity Framework (CSF) provide widely adopted measures of organizational maturity, but do not directly support the selection and prioritization of defensive strategies against adversarial behavior. We present a system that operationalizes governance frameworks by mapping CSF maturity assessments into MITRE ATT\&CK mitigation capabilities, which enables direct integration of organizational security posture with adversary-informed defensive planning. To manage adversary complexity, we employ a Variable-Order Markov Model (VOMM) trained on observed ATT\&CK technique sequences to enable scalable adversary simulation within a Deep Reinforcement Learning (DRL) environment. We reconstruct likely attack paths and defensive responses using beam search, and then jointly optimize mitigation selection under explicit budget constraints. Our environment supports concurrent adversaries and realistic mitigation costs. Across multiple reward formulations and configurations, we show that the approach produces stable policies, meaningful cost-risk trade-offs, and interpretable mitigation plans aligned with organizational maturity. These results demonstrate that adversary-aware DRL can generate practical, resource-constrained defense strategies grounded in real-world frameworks and threat behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to operationalize the NIST Cybersecurity Framework (CSF) by mapping maturity assessments to MITRE ATT&CK mitigation capabilities, training a Variable-Order Markov Model (VOMM) on observed ATT&CK technique sequences for adversary simulation, using beam search to reconstruct attack paths, and applying Deep Reinforcement Learning (DRL) to jointly optimize mitigation selection under explicit budget constraints and concurrent adversaries. It asserts that the resulting system yields stable policies, meaningful cost-risk trade-offs, and interpretable plans aligned with organizational maturity across multiple reward formulations.
Significance. If the central claims hold with proper validation, the work could meaningfully advance practical cybersecurity governance by providing a concrete, adversary-aware mechanism to translate high-level CSF assessments into prioritized, resource-constrained mitigations. The integration of established frameworks (CSF, ATT&CK) with scalable simulation and RL optimization is a strength that could improve actionability of governance frameworks in operational settings.
major comments (2)
- [Abstract] Abstract: the assertion that 'across multiple reward formulations and configurations, we show that the approach produces stable policies, meaningful cost-risk trade-offs' is presented without any quantitative results, tables, figures, convergence metrics, error bars, baseline comparisons, or validation details in the available manuscript text. This directly undermines evaluation of the central claim that adversary-aware DRL generates practical, governance-grounded strategies.
- [Model description] Model description (VOMM and CSF-to-ATT&CK mapping): the pipeline assumes the VOMM trained on ATT&CK sequences faithfully reproduces real-world adversary behavior for beam-search path reconstruction and DRL optimization, and that the CSF maturity mapping produces realistic available mitigations with accurate costs. No validation against incident data, cross-checks, sensitivity analysis, or fidelity metrics are reported; deviations here would render the reported policies simulation artifacts rather than evidence of practical utility.
minor comments (2)
- Clarify the exact mechanism and any assumptions in the CSF maturity to mitigation availability/cost mapping, including how maturity levels constrain the action space in the DRL environment.
- Ensure consistent definition of all acronyms (e.g., VOMM, DRL, CSF) on first use and provide a brief overview of the beam-search parameters used for attack-path reconstruction.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. The comments identify opportunities to strengthen the presentation of results and the discussion of modeling assumptions. We respond to each major comment below and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'across multiple reward formulations and configurations, we show that the approach produces stable policies, meaningful cost-risk trade-offs' is presented without any quantitative results, tables, figures, convergence metrics, error bars, baseline comparisons, or validation details in the available manuscript text. This directly undermines evaluation of the central claim that adversary-aware DRL generates practical, governance-grounded strategies.
Authors: We agree that the abstract would be strengthened by including specific quantitative indicators. The full manuscript reports experimental outcomes in Sections 5 and 6, including convergence behavior under different reward formulations, policy stability metrics, cost-risk trade-off tables, and comparisons across budget constraints and adversary counts. We will revise the abstract to concisely summarize representative quantitative findings (e.g., stability scores and risk-reduction ranges) so that the high-level claims are directly supported by the empirical content already present in the paper. revision: yes
-
Referee: [Model description] Model description (VOMM and CSF-to-ATT&CK mapping): the pipeline assumes the VOMM trained on ATT&CK sequences faithfully reproduces real-world adversary behavior for beam-search path reconstruction and DRL optimization, and that the CSF maturity mapping produces realistic available mitigations with accurate costs. No validation against incident data, cross-checks, sensitivity analysis, or fidelity metrics are reported; deviations here would render the reported policies simulation artifacts rather than evidence of practical utility.
Authors: The referee correctly notes the absence of direct empirical validation for the VOMM fidelity and the CSF-to-mitigation cost mapping. The manuscript (Section 3) describes the data sources, training procedure, and mapping rules, but does not report incident-log validation, sensitivity sweeps, or fidelity metrics. We will add a new subsection that explicitly states the modeling assumptions, discusses potential deviations from real-world behavior, and outlines planned validation steps (including fidelity metrics and sensitivity analysis on cost assignments). This addition will clarify the current scope as a framework demonstration while transparently addressing the practical-utility concern. revision: partial
Circularity Check
No significant circularity; derivation is simulation-driven from external data and frameworks
full rationale
The paper trains a VOMM on observed ATT&CK sequences (external data), maps CSF maturity to mitigations via the NIST framework, reconstructs paths with beam search, and optimizes via DRL under budget constraints. The reported stable policies and cost-risk trade-offs emerge from running the RL agent in this constructed environment; they are not equivalent to the inputs by definition, nor do they rely on fitted parameters renamed as predictions or self-citation chains for uniqueness. No load-bearing step reduces to a tautology or prior author result invoked as an external theorem. This is a standard simulation-optimization pipeline whose validity hinges on external fidelity assumptions rather than internal circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption CSF maturity assessments can be reliably mapped to MITRE ATT&CK mitigation capabilities for planning purposes
- domain assumption VOMM trained on observed ATT&CK sequences produces realistic attack-path distributions
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We employ a Variable-Order Markov Model (VOMM) trained on observed ATT&CK technique sequences... LLM-assisted semantic translation layer that converts NIST CSF practice assessments into mitigation maturity levels
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We reconstruct likely attack paths and defensive responses using beam search, and then jointly optimize mitigation selection under explicit budget constraints
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mitre att&ck applications in cybersecurity and the way forward.arXiv preprint arXiv:2502.10825, 2025
Yuning Jiang, Qiaoran Meng, Feiyang Shang, Nay Oo, Le Thi Hong Minh, Hoon Wei Lim, and Biplab Sikdar. Mitre att&ck applications in cybersecurity and the way forward.arXiv preprint arXiv:2502.10825, 2025
-
[2]
The never-evolving threat landscape: Forever techniques and the illusion of change
Brian Donohue. The never-evolving threat landscape: Forever techniques and the illusion of change. Presentation at ATT&CKcon 6.0, October 2025. MITRE ATT&CK Conference, slides
work page 2025
-
[3]
Cyborg: A gym for the development of autonomous cyber agents.arXiv preprint arXiv:2108.09118, 2021
Maxwell Standen, Martin Lucas, David Bowman, Toby J Richer, Junae Kim, and Damian Marriott. Cyborg: A gym for the development of autonomous cyber agents.arXiv preprint arXiv:2108.09118, 2021
-
[4]
Mitchell Kiely, Metin Ahiskali, Etienne Borde, Benjamin Bowman, David Bowman, Dirk Van Bruggen, KC Cowan, Prithviraj Dasgupta, Erich Devendorf, Ben Edwards, et al. Cage challenge 4: A scalable multi-agent reinforcement learning gym for autonomous cyber defence.AI Magazine, 46(3):e70021, 2025. 22 DRL-Based Cyber Mitigation Planning Algorithm 1Attack Path R...
work page 2025
-
[5]
Mitre att&ck: Design and philosophy.MITRE Technical Report, 2018
Blake Strom, Andy Applebaum, Doug Miller, Kathryn Nickels, Adam Pennington, and Cody Thomas. Mitre att&ck: Design and philosophy.MITRE Technical Report, 2018
work page 2018
-
[6]
Mitre att&ck for industrial control systems, 2024
MITRE Corporation. Mitre att&ck for industrial control systems, 2024. https://attack.mitre.org/matrices/ics/
work page 2024
-
[7]
The Center for Threat-Informed Defense. Attack flow v3, 2025. https://ctid.mitre.org/projects/attack-flow/
work page 2025
-
[8]
Executive order 13636: Improving critical infrastructure cybersecurity
Executive Office of the President. Executive order 13636: Improving critical infrastructure cybersecurity. https://www.federalregister.gov/documents/2013/02/19/2013-03915/ improving-critical-infrastructure-cybersecurity, 2013
work page 2013
-
[9]
Cybersecurity framework (csf) 2.0
National Institute of Standards and Technology. Cybersecurity framework (csf) 2.0. https://www.nist.gov/ cyberframework, 2024
work page 2024
-
[10]
Mazen Brho, Amer Jazairy, and Aaron V Glassburner. The finance of cybersecurity: Quantitative modeling of investment decisions and net present value.International Journal of Production Economics, 279:109448, 2025
work page 2025
-
[11]
Optimal network security hardening using attack graph games
Karel Durkota, Viliam Lis `y, Branislav Bosansk `y, and Christopher Kiekintveld. Optimal network security hardening using attack graph games. InIJCAI, pages 526–532, 2015
work page 2015
-
[12]
Intelligent, automated red team emulation
Andy Applebaum, Doug Miller, Blake Strom, Chris Korban, and Ross Wolf. Intelligent, automated red team emulation. InProceedings of the 32nd annual conference on computer security applications, pages 363–373, 2016
work page 2016
-
[13]
Heuristic search value iteration for one-sided partially observable stochastic games
Karel Horák, Branislav Bošansk`y, and Michal Pˇechouˇcek. Heuristic search value iteration for one-sided partially observable stochastic games. InProceedings of the AAAI conference on artificial intelligence, volume 31, 2017
work page 2017
-
[14]
A Game-Theoretical Approach to Cyber-Security of Critical Infrastructures Based on Multi-Agent Reinforcement Learning, 2018
work page 2018
-
[15]
Tom Purves, Konstantinos G Kyriakopoulos, Sian Jenkins, Iain Phillips, and Tim Dudman. Causally aware reinforcement learning agents for autonomous cyber defence.Knowledge-Based Systems, 304:112521, 2024
work page 2024
-
[16]
Merve Ozkan-Okay, Erdal Akin, Ömer Aslan, Selahattin Kosunalp, Teodor Iliev, Ivaylo Stoyanov, and Ivan Beloev. A comprehensive survey: Evaluating the efficiency of artificial intelligence and machine learning techniques on cyber security solutions.IEEe Access, 12:12229–12256, 2024
work page 2024
-
[17]
Large language models are autonomous cyber defenders.arXiv [cs.AI], July 2025
Sebastián R Castro, Roberto Campbell, Nancy Lau, Octavio Villalobos, Jiaqi Duan, and Alvaro A Cardenas. Large language models are autonomous cyber defenders.arXiv [cs.AI], July 2025. 23 DRL-Based Cyber Mitigation Planning
work page 2025
-
[18]
Design and evaluation of an autonomous cyber defence agent using DRL and an augmented LLM.Comput
Johannes Loevenich, Erik Adler, Tobias Hürten, and Roberto Rigolin F Lopes. Design and evaluation of an autonomous cyber defence agent using DRL and an augmented LLM.Comput. Netw., 262(111162):111162, May 2025
work page 2025
-
[19]
Sayak Mukherjee, Samrat Chatterjee, Emilie Purvine, Ted Fujimoto, and Tegan Emerson. Large language model-based reward design for deep reinforcement learning-driven autonomous cyber defense.arXiv [cs.LG], November 2025
work page 2025
-
[20]
The path to autonomous cyberdefense.IEEE Secur
Sean Oesch, Phillipe Austria, Amul Chaulagain, Brian Weber, Cory Watson, Matthew Dixson, and Amir Sadovnik. The path to autonomous cyberdefense.IEEE Secur. Priv., 23(1):38–46, January 2025
work page 2025
-
[21]
Entity-based reinforcement learning for autonomous cyber defence
Isaac Symes Thompson, Alberto Caron, Chris Hicks, and Vasilios Mavroudis. Entity-based reinforcement learning for autonomous cyber defence. InProceedings of the Workshop on Autonomous Cybersecurity, pages 56–67, 2023
work page 2023
-
[22]
{AIRS}: Explanation for deep reinforcement learning based security applications
Jiahao Yu, Wenbo Guo, Qi Qin, Gang Wang, Ting Wang, and Xinyu Xing. {AIRS}: Explanation for deep reinforcement learning based security applications. In32nd USENIX Security Symposium (USENIX Security 23), pages 7375–7392, 2023
work page 2023
-
[23]
Atheer Alaa Hammad and Firas Tarik Jasim. Adaptive cyber defense using advanced deep reinforcement learning algorithms: a real-time comparative analysis.Journal of Computing Theories and Applications, 2(4):523–535, 2025
work page 2025
-
[24]
Alec Wilson, Ryan Menzies, Neela Morarji, David Foster, Marco Casassa Mont, Esin Turkbeyler, and Lisa Gralewski. Multi-agent reinforcement learning for maritime operational technology cyber security.arXiv preprint arXiv:2401.10149, 2024
-
[25]
Probabilistic attack sequence generation and execution based on mitre att&ck for ics datasets
Seungoh Choi, Jeong-Han Yun, and Byung-Gil Min. Probabilistic attack sequence generation and execution based on mitre att&ck for ics datasets. InProceedings of the 14th Cyber Security Experimentation and Test Workshop, pages 41–48, 2021
work page 2021
-
[26]
Mitre att&ck-driven cyber risk assessment
Mohamed Ahmed, Sakshyam Panda, Christos Xenakis, and Emmanouil Panaousis. Mitre att&ck-driven cyber risk assessment. InProceedings of the 17th International Conference on Availability, Reliability and Security, pages 1–10, 2022
work page 2022
-
[27]
Att&ck behavior forecasting based on collaborative filtering and graph databases
Masaki Kuwano, Momoka Okuma, Satoshi Okada, and Takuho Mitsunaga. Att&ck behavior forecasting based on collaborative filtering and graph databases. In2022 IEEE International Conference on Computing (ICOCO), pages 191–197. IEEE, 2022
work page 2022
-
[28]
Linking threat agents to targeted organizations: A pipeline for enhanced cybersecurity risk metrics
Spencer Massengale and Philip Huff. Linking threat agents to targeted organizations: A pipeline for enhanced cybersecurity risk metrics. In2024 4th Intelligent Cybersecurity Conference (ICSC), pages 132–141. IEEE, 2024
work page 2024
-
[29]
Large language models for cyber threat intelligence: Extracting mitre with llms
Andraž Krašovec, Gary Steri, Georgios Karopoulos, and Mirko Trapani. Large language models for cyber threat intelligence: Extracting mitre with llms. InInternational Conference on Availability, Reliability and Security, pages 80–89. Springer, 2025
work page 2025
-
[30]
Staying ahead of threat actors in the age of AI
Microsoft Security and OpenAI. Staying ahead of threat actors in the age of AI. https://www.microsoft. com/en-us/security/blog/2024/02/14/staying-ahead-of-threat-actors-in-the-age-of-ai/ , February 2024. Industry threat intelligence report
work page 2024
-
[31]
Assessing and prioritizing ransomware risk based on historical victim data
Spencer Massengale and Philip Huff. Assessing and prioritizing ransomware risk based on historical victim data. InInternational Conference on Security and Privacy in Communication Systems, pages 351–369. Springer, 2024. 24
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.