Recognition: 2 theorem links
· Lean TheoremLEAD: Length-Efficient Adaptive and Dynamic Reasoning for Large Language Models
Pith reviewed 2026-05-12 02:26 UTC · model grok-4.3
The pith
LEAD uses online adaptive mechanisms to dynamically balance accuracy and reasoning length in LLMs, achieving top accuracy-efficiency scores with shorter outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
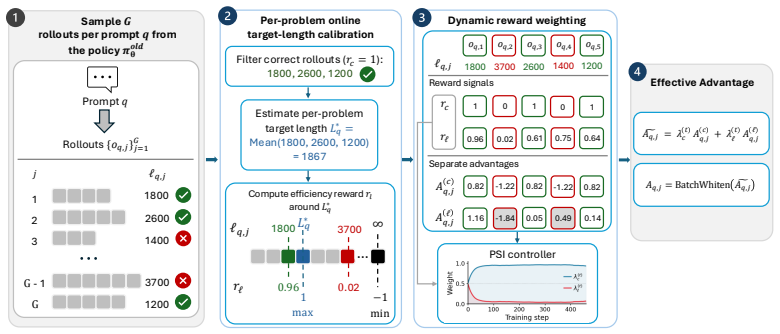
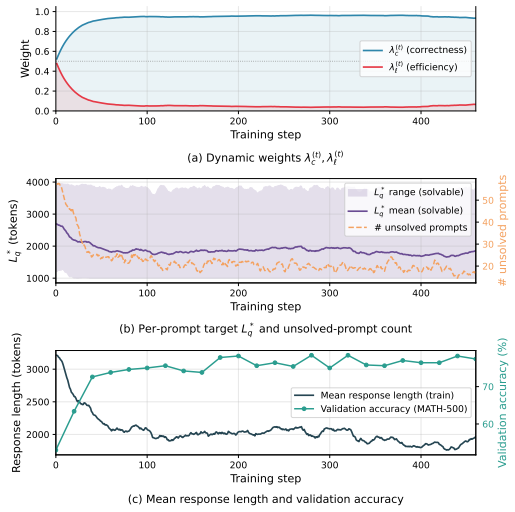
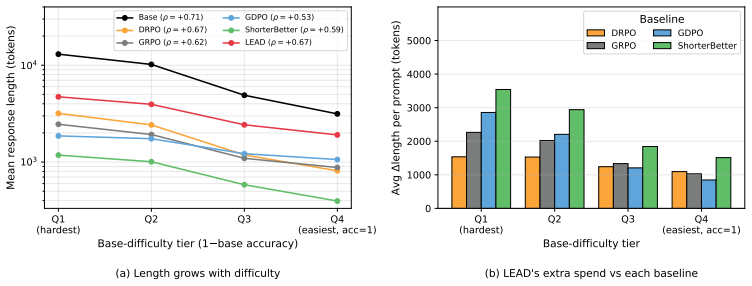
LEAD overcomes non-stationary trade-offs and varying problem budgets by calibrating the efficiency signal with Potential-Scaled Instability at each step and by deriving adaptive per-problem target lengths from correct rollouts to apply symmetric efficiency rewards. This produces the highest accuracy and Accuracy-Efficiency Score among RL-trained efficient-reasoning methods on five mathematical benchmarks, along with substantially shorter outputs than the base model.
What carries the argument
Potential-Scaled Instability for dynamic trade-off calibration at each training step, paired with online per-problem target length estimation from the model's correct rollouts enabling symmetric penalization of over- and under-reasoning.
If this is right
- LEAD achieves higher accuracy than static-reward RL baselines on mathematical reasoning tasks.
- It generates substantially shorter reasoning outputs than the base model, lowering compute and latency.
- The Accuracy-Efficiency Score improves over existing efficient-reasoning RL methods.
- Dynamic per-step and per-problem adaptation avoids accuracy degradation from fixed global constraints.
- Symmetric rewards prevent both verbose overthinking and harmful over-compression.
Where Pith is reading between the lines
- Similar online estimation from rollouts could extend to non-mathematical domains where optimal reasoning depth varies.
- The method suggests a general template for handling non-stationary rewards in LLM reinforcement learning.
- Adoption might allow larger models to fit within tighter context windows by default.
- Further work could test whether the estimated targets align with human-perceived minimal solution lengths.
Load-bearing premise
Estimating per-problem target lengths online from the model's own correct rollouts supplies a stable and unbiased signal for the symmetric efficiency reward without introducing instability or accuracy loss.
What would settle it
If retraining LEAD on a standard math benchmark results in either lower final accuracy than the base model or longer average output lengths than the reported gains, the central adaptive mechanism would be called into question.
Figures

read the original abstract
Large reasoning models, such as OpenAI o1 and DeepSeek-R1, tend to become increasingly verbose as their reasoning capabilities improve. These inflated Chain-of-Thought (CoT) trajectories often exceed what the underlying problems require, wasting compute, latency, and context budgets. While introducing length-based efficiency rewards during reinforcement learning offers a natural remedy, existing methods struggle with two fundamental challenges: the optimal balance between correctness and efficiency is non-stationary throughout training, and intrinsic reasoning budgets vary drastically across problems. Relying on static reward weights and global length constraints inevitably forces a compromise between degraded accuracy and unrealized compression. To overcome these limitations, we propose LEAD (Length-Efficient Adaptive and Dynamic reasoning), a method that replaces static heuristics with online, self-adaptive mechanisms. LEAD dynamically calibrates the correctness-efficiency trade-off at each step using a Potential-Scaled Instability, directing optimization capacity to the most informative learning signal. Furthermore, it estimates an adaptive per-problem target length online based on the model's own correct rollouts, applying a symmetric efficiency reward that penalizes both overthinking and over-compression. Evaluated on five mathematical reasoning benchmarks, LEAD achieves the highest accuracy and Accuracy-Efficiency Score among RL-trained efficient-reasoning methods while producing substantially shorter outputs than the base model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LEAD, a reinforcement learning method for length-efficient reasoning in LLMs. It replaces static rewards with two online mechanisms: a Potential-Scaled Instability term that dynamically weights the correctness-efficiency trade-off at each step, and an adaptive per-problem target length estimated from the model's own correct rollouts, which is then used in a symmetric efficiency reward that penalizes both overthinking and over-compression. On five mathematical reasoning benchmarks, LEAD is reported to achieve the highest accuracy and Accuracy-Efficiency Score among RL-trained efficient-reasoning baselines while producing substantially shorter outputs than the base model.
Significance. If the empirical claims hold under rigorous controls, LEAD would offer a practical advance over static length penalties by addressing non-stationary trade-offs and problem-specific reasoning budgets. The self-supervised target-length estimator and symmetric reward are conceptually attractive for reducing verbosity without manual tuning, but their stability directly determines whether the reported accuracy gains are reliable.
major comments (2)
- [Abstract and method description of adaptive target length] The central empirical claim (highest accuracy and AES with shorter outputs) depends on the stability of the online per-problem target-length estimator derived from correct rollouts. Because correct trajectories are initially sparse and their lengths may not be representative, the running estimate can exhibit high variance or systematic bias; the symmetric efficiency reward then applies penalties relative to this noisy target. This risk is load-bearing for the accuracy results and is not obviously mitigated by the Potential-Scaled Instability term.
- [Abstract (evaluation paragraph)] No details are provided on statistical significance testing, standard deviation across random seeds, exact baseline implementations, or safeguards against post-hoc hyperparameter selection. Without these, it is impossible to determine whether the reported superiority over other RL-trained methods is robust or could be explained by variance or implementation differences.
minor comments (2)
- [Method] Clarify the precise mathematical definition of Potential-Scaled Instability, including how the scaling factor is computed and whether it introduces additional free parameters beyond those already listed.
- [Method] The abstract states that the target length is estimated 'online based on the model's own correct rollouts'; specify the exact update rule, window size, and handling of problems with zero correct rollouts in early training.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review of our manuscript. We have carefully addressed each major comment below with point-by-point responses. Where the concerns identify areas for improved clarity or additional evidence, we will incorporate revisions in the next version of the paper.
read point-by-point responses
-
Referee: [Abstract and method description of adaptive target length] The central empirical claim (highest accuracy and AES with shorter outputs) depends on the stability of the online per-problem target-length estimator derived from correct rollouts. Because correct trajectories are initially sparse and their lengths may not be representative, the running estimate can exhibit high variance or systematic bias; the symmetric efficiency reward then applies penalties relative to this noisy target. This risk is load-bearing for the accuracy results and is not obviously mitigated by the Potential-Scaled Instability term.
Authors: We appreciate the referee's focus on the stability of the per-problem target-length estimator, which is indeed central to LEAD. While early training stages feature sparse correct rollouts, the estimator maintains a per-problem running average (exponential moving average with decay factor 0.9) that incorporates every correct trajectory as it appears; this design ensures variance decreases monotonically with additional successful samples rather than remaining persistently high. The Potential-Scaled Instability term explicitly modulates the efficiency reward weight according to the instantaneous variance in the correctness signal, thereby attenuating the influence of any noisy target length during periods of high instability. This coupling prevents the symmetric reward from over-penalizing efficiency before the estimator has stabilized. To make this mitigation explicit, the revised manuscript will add a dedicated subsection with convergence plots of target lengths across training steps for representative problems, an ablation isolating the estimator with and without PSI, and quantitative measures of estimator variance reduction over time. revision: yes
-
Referee: [Abstract (evaluation paragraph)] No details are provided on statistical significance testing, standard deviation across random seeds, exact baseline implementations, or safeguards against post-hoc hyperparameter selection. Without these, it is impossible to determine whether the reported superiority over other RL-trained methods is robust or could be explained by variance or implementation differences.
Authors: We agree that these experimental details are essential for establishing robustness. The revised manuscript will expand the evaluation section to report: (i) accuracy and Accuracy-Efficiency Score means accompanied by standard deviations computed over five independent random seeds for LEAD and all baselines; (ii) results of paired t-tests with p-values comparing LEAD against each baseline; (iii) precise implementation specifications for every baseline, including any necessary adaptations from their original publications together with hyperparameter values and training configurations; and (iv) a transparent description of our hyperparameter search procedure, including the ranges explored, the validation protocol used for selection, and confirmation that no post-hoc adjustments were made after observing test-set results. These additions will allow readers to assess the reliability of the reported gains directly. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper describes LEAD as using online estimation of per-problem target lengths from the model's correct rollouts during RL training, combined with a symmetric efficiency reward and Potential-Scaled Instability to balance correctness and length. This adaptive process is a dynamic component of the training loop rather than a self-referential definition where any claimed result (such as shorter outputs or higher AES) is forced by construction from the inputs. No equations or steps are shown reducing a prediction to a fitted parameter, no load-bearing self-citations or uniqueness theorems from prior author work are invoked, and no ansatz or renaming of known results is presented as a derivation. The method is self-contained with external benchmark evaluations providing independent assessment.
Axiom & Free-Parameter Ledger
free parameters (2)
- Instability scaling factors
- Per-problem length target estimator
invented entities (1)
-
Potential-Scaled Instability
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J-cost uniqueness) echoesSymmetric efficiency reward: rℓ(oq,j , q) = max(-1, 1 - |ℓq,j - L*_q| / L*_q ) ... estimated ... from the model’s own correct rollouts
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection (coupling combiner) unclearPotential-Scaled Instability (PSI) controller ... adapts λ online from instability and headroom
Reference graph
Works this paper leans on
-
[1]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
work page 2022
-
[2]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, et al. Least-to-most prompting enables complex reasoning in large language models.arXiv preprint arXiv:2205.10625, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models.Ad- vances in neural information processing systems, 36:11809–11822, 2023
work page 2023
-
[5]
Graph of thoughts: Solving elaborate problems with large language models
Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, et al. Graph of thoughts: Solving elaborate problems with large language models. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 17682–17690, 2024
work page 2024
-
[6]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36:68539– 68551, 2023
work page 2023
-
[8]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
Xingyu Chen, Jiahao Xu, Tian Liang, Zhiwei He, Jianhui Pang, Dian Yu, Linfeng Song, Qiuzhi Liu, Mengfei Zhou, Zhuosheng Zhang, et al. Do not think that much for 2+ 3=? on the overthinking of o1-like llms.arXiv preprint arXiv:2412.21187, 2024
work page internal anchor Pith review arXiv 2024
-
[11]
Junyi Chen, Chuheng Du, Renyuan Liu, Shuochao Yao, Dingtian Yan, Jiang Liao, Shengzhong Liu, Fan Wu, and Guihai Chen. Tokenflow: Responsive llm text streaming serving under request burst via preemptive scheduling.arXiv preprint arXiv:2510.02758, 2025. 10
-
[12]
Training language models to reason efficiently
Daman Arora and Andrea Zanette. Training language models to reason efficiently.arXiv preprint arXiv:2502.04463, 2025
-
[13]
Violet Xiang, Chase Blagden, Rafael Rafailov, Nathan Lile, Sang Truong, Chelsea Finn, and Nick Haber. Just enough thinking: Efficient reasoning with adaptive length penalties reinforcement learning.arXiv preprint arXiv:2506.05256, 2025
-
[14]
L1: Controlling how long a reasoning model thinks with reinforcement learning
Pranjal Aggarwal and Sean Welleck. L1: Controlling how long a reasoning model thinks with reinforcement learning.arXiv preprint arXiv:2503.04697, 2025
-
[15]
O1-pruner: Length-harmonizing fine-tuning for o1-like reasoning pruning
Haotian Luo, Li Shen, Haiying He, Yibo Wang, Shiwei Liu, Wei Li, Naiqiang Tan, Xiaochun Cao, and Dacheng Tao. O1-pruner: Length-harmonizing fine-tuning for o1-like reasoning pruning.arXiv preprint arXiv:2501.12570, 2025
-
[16]
Jingyang Yi, Jiazheng Wang, and Sida Li. Shorterbetter: Guiding reasoning models to find optimal inference length for efficient reasoning.arXiv preprint arXiv:2504.21370, 2025
-
[17]
Smartthinker: Learning to compress and preserve reasoning by step-level length control
Xingyang He, Xiao Ling, and Jie Liu. Smartthinker: Learning to compress and preserve reasoning by step-level length control.arXiv preprint arXiv:2507.04348, 2025
-
[18]
Gang Li, Yan Chen, Ming Lin, and Tianbao Yang. Drpo: Efficient reasoning via decoupled reward policy optimization.arXiv preprint arXiv:2510.04474, 2025
-
[19]
Learn to reason efficiently with adaptive length-based reward shaping
Wei Liu, Ruochen Zhou, Yiyun Deng, Yuzhen Huang, Junteng Liu, Yuntian Deng, Yizhe Zhang, and Junxian He. Learn to reason efficiently with adaptive length-based reward shaping.arXiv preprint arXiv:2505.15612, 2025
-
[20]
SelfBudgeter: Adaptive Token Allocation for Efficient LLM Reasoning
Zheng Li, Qingxiu Dong, Jingyuan Ma, Di Zhang, Kai Jia, and Zhifang Sui. Selfbudgeter: Adaptive token allocation for efficient llm reasoning.arXiv preprint arXiv:2505.11274, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Sample more to think less: Group filtered policy optimiza- tion for concise reasoning
Vaishnavi Shrivastava, Ahmed Awadallah, Vidhisha Balachandran, Shivam Garg, Harkirat Behl, and Dimitris Papailiopoulos. Sample more to think less: Group filtered policy optimization for concise reasoning.arXiv preprint arXiv:2508.09726, 2025
-
[22]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Hapo: Training language models to reason concisely via history-aware policy optimization
Chengyu Huang et al. HAPO: History-aware policy optimization for efficient reasoning.arXiv preprint arXiv:2505.11225, 2025
-
[24]
Shih-Yang Liu, Xin Dong, Ximing Lu, Shizhe Diao, Peter Belcak, Mingjie Liu, Min-Hung Chen, Hongxu Yin, Yu-Chiang Frank Wang, Kwang-Ting Cheng, et al. Gdpo: Group reward- decoupled normalization policy optimization for multi-reward rl optimization.arXiv preprint arXiv:2601.05242, 2026
-
[25]
Yining Lu, Zilong Wang, Shiyang Li, Xin Liu, Changlong Yu, Qingyu Yin, Zhan Shi, Zixuan Zhang, and Meng Jiang. Learning to optimize multi-objective alignment through dynamic reward weighting.arXiv preprint arXiv:2509.11452, 2025
-
[26]
Thinkprune: Pruning long chain-of-thought of llms via reinforcement learning
Bairu Hou, Yang Zhang, Jiabao Ji, Yujian Liu, Kaizhi Qian, Jacob Andreas, and Shiyu Chang. Thinkprune: Pruning long chain-of-thought of llms via reinforcement learning.arXiv preprint arXiv:2504.01296, 2025
-
[27]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori B Hashimoto. s1: Simple test-time scaling. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 20286–20332, 2025. 11
work page 2025
-
[29]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tianyi T...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Conor F. Hayes, Roxana R˘adulescu, Eugenio Bargiacchi, Johan Källström, Matthew Macfar- lane, Mathieu Reymond, Timothy Verstraeten, Luisa M. Zintgraf, Richard Dazeley, Fredrik Heintz, Enda Howley, Athirai A. Irissappane, Patrick Mannion, Ann Nowé, Gabriel Ramos, Marcello Restelli, Peter Vamplew, and Diederik M. Roijers. A practical guide to multi-objectiv...
work page 2022
-
[31]
e1: Learning adaptive control of reasoning effort.arXiv preprint arXiv:2510.27042, 2025
Michael Kleinman, Matthew Trager, Alessandro Achille, Wei Xia, and Stefano Soatto. e1: Learning adaptive control of reasoning effort.arXiv preprint arXiv:2510.27042, 2025
-
[32]
Plan and budget: Effective and efficient test-time scaling on large language model reasoning
Junhong Lin, Xinyue Zeng, Jie Zhu, Song Wang, Julian Shun, Jun Wu, and Dawei Zhou. Plan and budget: Effective and efficient test-time scaling on large language model reasoning.arXiv preprint arXiv:2505.16122, 2025
-
[33]
Aradhye Agarwal, Ayan Sengupta, and Tanmoy Chakraborty. The art of scaling test-time compute for large language models.arXiv preprint arXiv:2512.02008, 2025
-
[34]
Gradnorm: Gra- dient normalization for adaptive loss balancing in deep multitask networks
Zhao Chen, Vijay Badrinarayanan, Chen-Yu Lee, and Andrew Rabinovich. Gradnorm: Gra- dient normalization for adaptive loss balancing in deep multitask networks. InInternational conference on machine learning, pages 794–803. PMLR, 2018
work page 2018
-
[35]
Multi-task learning using uncertainty to weigh losses for scene geometry and semantics
Alex Kendall, Yarin Gal, and Roberto Cipolla. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 7482–7491, 2018
work page 2018
-
[36]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[37]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large lan- guage model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
work page 2023
-
[39]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, et al. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Paper...
work page 2024
-
[40]
A sober look at progress in language model reasoning: Pitfalls and paths to reproducibility
Andreas Hochlehnert, Hardik Bhatnagar, Vishaal Udandarao, Samuel Albanie, Ameya Prabhu, and Matthias Bethge. A sober look at progress in language model reasoning: Pitfalls and paths to reproducibility.arXiv preprint arXiv:2504.07086, 2025. A Limitations and Broader Impact A.1 Limitations LEAD is designed for reinforcement learning settings where correctne...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.