Recognition: 2 theorem links
· Lean TheoremSupercharging Bayesian Inference with Reliable AI-Informed Priors
Pith reviewed 2026-05-12 04:18 UTC · model grok-4.3
The pith
Rectifying the AI-induced law before embedding it as a prior reduces bias and improves credible interval coverage in Bayesian inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
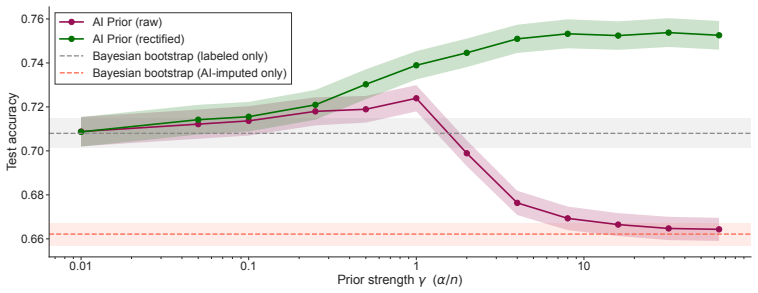
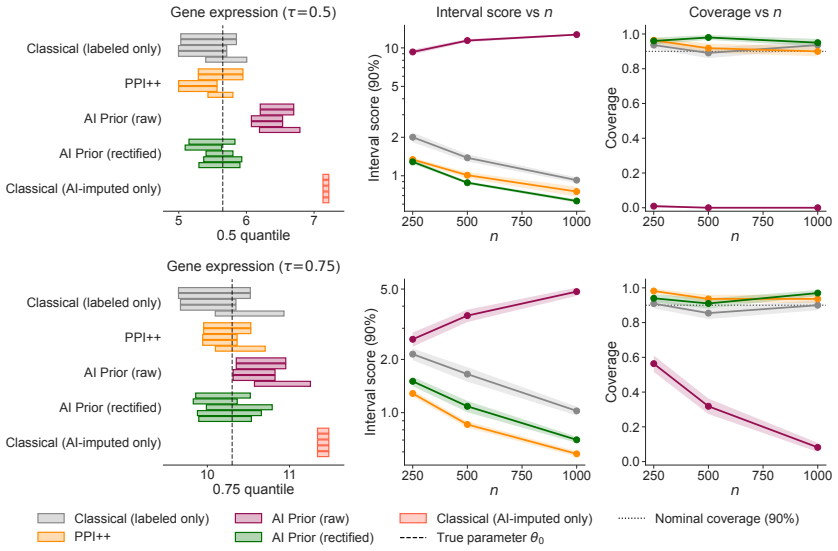
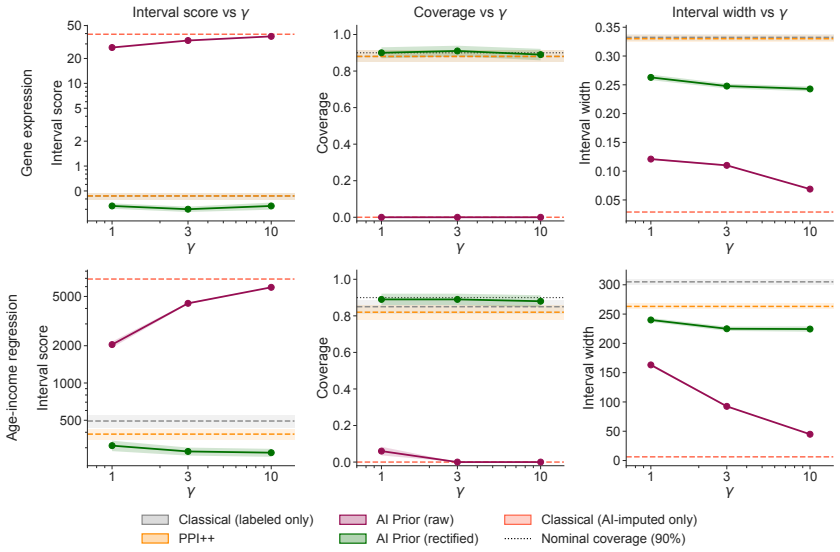
By rectifying the AI-induced law that generates synthetic data and using the rectified law as a base measure in a Dirichlet process prior, the corresponding posterior achieves Gaussian asymptotics under non-vanishing prior strength together with a first-order expression for its centering bias; the construction substantially reduces bias relative to standard AI-informed priors and improves the coverage of credible intervals.
What carries the argument
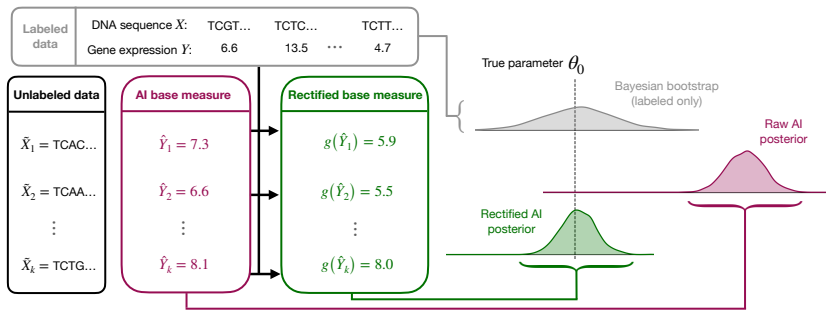
The rectified AI prior, formed by correcting the AI-induced law before it is embedded into synthetic-data-driven prior elicitation such as a Dirichlet process prior on the data-generating process.
If this is right
- The rectified AI posterior exhibits lower centering bias than unrectified AI-informed priors under the same prior strength.
- Credible intervals constructed from the rectified posterior achieve improved frequentist coverage.
- AI-derived prior information becomes more reliable for downstream inference when data are scarce.
- The same rectification can be embedded in other synthetic-data prior constructions beyond the Dirichlet process.
Where Pith is reading between the lines
- The rectification technique could be combined with existing robust Bayesian methods that adjust priors for model misspecification.
- In applications such as medical imaging, the improved coverage may translate into more trustworthy uncertainty statements for downstream decisions.
- Extensions to non-Dirichlet process priors or to settings with streaming data would test whether the asymptotic guarantees survive beyond the paper's stated conditions.
Load-bearing premise
The rectification of the AI-induced law preserves the claimed Gaussian asymptotics and first-order bias expression without introducing new uncontrolled errors or requiring data-dependent tuning that affects the central guarantees.
What would settle it
Apply the rectified prior to a data-generating process where the original AI model is known to have a fixed, quantifiable bias; check whether the posterior centering bias remains at the derived first-order level and whether credible-interval coverage stays at or above the nominal level.
Figures

read the original abstract
Modern predictive systems encode beliefs that can act as useful prior information for statistical inference in data-limited settings. Using them for prior construction introduces a tradeoff: an informative prior built from a predictive model can sharpen inference from limited data, but also risks propagating error from the model into the posterior. We propose a framework for AI-informed prior elicitation that mitigates this tension by rectifying the AI-induced law that generates synthetic data before using it to inform a prior. The rectified law can be embedded into synthetic data-driven prior elicitation techniques, including as a base measure in a Dirichlet process (DP) prior on the data-generating process. We refer to the resulting prior and corresponding posterior as the rectified AI prior and rectified AI posterior. We establish Gaussian asymptotics for the rectified AI posterior under non-vanishing prior strength and derive a first-order expression for its centering bias. Our rectified AI priors substantially reduce bias compared to standard approaches, improve the coverage of credible intervals, and make AI-powered prior information more reliable. We additionally apply the rectified AI prior to a real skin disease classification task and show that it can meaningfully boost predictive performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a framework for AI-informed prior elicitation that rectifies the AI-induced law generating synthetic data before embedding it into prior construction techniques, such as using it as a base measure in a Dirichlet process prior. The resulting rectified AI prior and posterior are analyzed by establishing Gaussian asymptotics under non-vanishing prior strength and deriving a first-order expression for centering bias. The authors claim these rectified priors substantially reduce bias relative to standard approaches, improve credible interval coverage, and demonstrate boosted predictive performance on a real skin disease classification task.
Significance. If the asymptotic results and bias control can be rigorously verified, the work would offer a principled approach to incorporating outputs from predictive AI systems as priors while mitigating error propagation, which addresses an important practical challenge in Bayesian inference with limited data. The combination of theoretical claims with an empirical application adds relevance for hybrid AI-statistical methods.
major comments (2)
- [Abstract and theoretical results section] The abstract asserts that Gaussian asymptotics for the rectified AI posterior under non-vanishing prior strength and a first-order centering bias expression are derived, yet the manuscript supplies no explicit derivation steps, assumptions on the rectification operator, or uniform error bounds ensuring the rectification error remains o(1/sqrt(n)) in the non-vanishing prior regime. This is load-bearing for the central claim that bias is reduced without introducing new uncontrolled errors.
- [Rectification framework and prior elicitation section] The rectification is presented as an independent, pre-elicitation correction that preserves the claimed asymptotics and bias expression, but no verification is given that the operation is parameter-free, non-post-hoc, or free of data-dependent tuning whose error could alter the leading bias term. This directly impacts the soundness of the bias reduction and coverage guarantees.
minor comments (2)
- [Abstract] The abstract states that rectified priors 'substantially reduce bias' and 'improve the coverage of credible intervals' without referencing specific quantitative results, figures, or tables that support these improvements.
- [Empirical application section] The application to the skin disease classification task would benefit from additional details on baseline methods, sample sizes, and error bars to allow assessment of the claimed predictive performance boost.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which help clarify the presentation of our theoretical results. We address each major comment below and will incorporate revisions to enhance the rigor and explicitness of the derivations and framework.
read point-by-point responses
-
Referee: [Abstract and theoretical results section] The abstract asserts that Gaussian asymptotics for the rectified AI posterior under non-vanishing prior strength and a first-order centering bias expression are derived, yet the manuscript supplies no explicit derivation steps, assumptions on the rectification operator, or uniform error bounds ensuring the rectification error remains o(1/sqrt(n)) in the non-vanishing prior regime. This is load-bearing for the central claim that bias is reduced without introducing new uncontrolled errors.
Authors: We agree that the manuscript would be strengthened by providing more explicit derivation steps and supporting bounds. In the revised version, we will expand the theoretical results section with a step-by-step outline of the Gaussian asymptotics derivation under non-vanishing prior strength. We will also add an appendix specifying the assumptions on the rectification operator (including that it is a contraction with Lipschitz constant strictly less than 1) and deriving uniform error bounds via empirical process techniques to confirm the rectification error is o(1/sqrt(n)). These additions will directly support the bias reduction and coverage claims without new uncontrolled errors. revision: yes
-
Referee: [Rectification framework and prior elicitation section] The rectification is presented as an independent, pre-elicitation correction that preserves the claimed asymptotics and bias expression, but no verification is given that the operation is parameter-free, non-post-hoc, or free of data-dependent tuning whose error could alter the leading bias term. This directly impacts the soundness of the bias reduction and coverage guarantees.
Authors: We acknowledge the need for explicit verification here. In revision, we will augment the rectification framework section with a formal definition of the operator as a fixed, parameter-free transformation depending only on the AI model's known output law, applied strictly pre-elicitation. We will include a lemma showing it is non-post-hoc by construction and a perturbation analysis demonstrating that any approximation error in the rectification is of strictly higher order than the leading bias term, thus preserving the first-order centering bias expression and the associated coverage guarantees. revision: yes
Circularity Check
No circularity: asymptotics and bias derivation are independent of rectification definition
full rationale
The paper defines a rectification operation on the AI-induced law as an independent preprocessing step prior to embedding in a DP or other prior elicitation method. It then states that Gaussian asymptotics and a first-order centering bias are established separately for the resulting rectified AI posterior under non-vanishing prior strength. These derivations do not reduce by the paper's own equations to a fitted quantity, a self-referential definition, or a self-citation chain; the bias-reduction claim follows from comparing the derived expression against the unrectified case rather than being assumed by construction. No load-bearing step matches any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An AI predictive model induces a data-generating law that can be rectified without introducing new uncontrolled bias.
invented entities (1)
-
Rectified AI law / rectified AI prior
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe establish Gaussian asymptotics for the rectified AI posterior under non-vanishing prior strength and derive a first-order expression for its centering bias.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearThe rectified law can be embedded into synthetic data-driven prior elicitation techniques, including as a base measure in a Dirichlet process (DP) prior
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
URLhttps://doi.org/10.1214/ss/1009212673
doi: 10.1214/ss/1009212673. URLhttps://doi.org/10.1214/ss/1009212673. R. Dale, J. Rodu, and M. Baiocchi. Synthetic data, information, and prior knowledge: Why synthetic 10 data augmentation to boost sample doesn’t work for statistical inference,
-
[4]
URLhttps://arxiv. org/abs/2603.18345. N. Egami, M. Hinck, B. Stewart, and H. Wei. Using imperfect surrogates for downstream in- ference: Design-based supervised learning for social science applications of large language models. In A. Oh, T . Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors, Advances in Neural Information Processing Syste...
-
[5]
URLhttps://proceedings.neurips.cc/paper_files/paper/2023/file/ d862f7f5445255090de13b825b880d59-Paper-Conference.pdf. E. Fong, S. Lyddon, and C. Holmes. Scalable nonparametric sampling from multimodal posteriors with the posterior bootstrap. In K. Chaudhuri and R. Salakhutdinov, editors,Proceedings of the 36th International Conference on Machine Learning,...
work page 2023
-
[6]
URLhttps://proceedings.mlr.press/v97/ fong19a.html. K. Gligori´c, T . Zrnic, C. Lee, E. Candès, and D. Jurafsky. Can unconfident LLM annotations be used for confident conclusions? In L. Chiruzzo, A. Ritter, and L. Wang, editors,Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human...
work page 2025
-
[7]
Association for Computational Linguistics. ISBN 979-8-89176-189-6. doi: 10.18653/v1/2025.naacl-long.179. URLhttps://aclanthology.org/2025.naacl-long.179/. T . Gneiting and A. E. Raftery . Strictly proper scoring rules, prediction, and estimation.Journal of the American Statistical Association, 102(477):359–378,
-
[8]
URLhttps://doi.org/10.1214/24-STS930
doi: 10.1214/ 24-STS930. URLhttps://doi.org/10.1214/24-STS930. N. Ilter and H. Guvenir. Dermatology. UCI Machine Learning Repository,
-
[10]
Highly accurate protein structure prediction with AlphaFold
ISSN 1476-4687. doi: 10.1038/s41586-021-03819-2. URLhttps://doi.org/10.1038/s41586-021-03819-2. M. Kull, M. Perello Nieto, M. Kängsepp, T . Silva Filho, H. Song, and P . Flach. Beyond temperature scaling: Obtaining well-calibrated multi-class probabilities with Dirichlet calibration. In H. Wallach, H. Larochelle, A. Beygelzimer, F . d'Alché-Buc, E. Fox, a...
-
[11]
neurips.cc/paper_files/paper/2019/file/8ca01ea920679a0fe3728441494041b9-Paper.pdf
URLhttps://proceedings. neurips.cc/paper_files/paper/2019/file/8ca01ea920679a0fe3728441494041b9-Paper.pdf. R. Lam, A. Sanchez-Gonzalez, M. Willson, P . Wirnsberger, M. Fortunato, F . Alet, S. Ravuri, T . Ewalds, Z. Eaton-Rosen, W . Hu, A. Merose, S. Hoyer, G. Holland, O. Vinyals, J. Stott, A. Pritzel, S. Mohamed, and P . Battaglia. Learning skillful mediu...
work page 2019
-
[12]
Learning skillful medium-range global weather forecasting,
doi: 10.1126/science.adi2336. URLhttps://www.science.org/doi/abs/10. 1126/science.adi2336. S. P . Lyddon, C. C. Holmes, and S. G. Walker. General Bayesian updating and the loss-likelihood 11 bootstrap.Biometrika, 106(2):465–478, 06
- [14]
-
[15]
URLhttp://www.jstor.org/stable/4140597
ISSN 00063444. URLhttp://www.jstor.org/stable/4140597. M. A. Riegler, K. H. Hellton, V . Thambawita, and H. L. Hammer. Using large language models to suggest informative prior distributions in Bayesian regression analysis.Scientific Reports, 15(1): 33386, Sep
-
[16]
doi: 10.1038/s41598-025-18425-9
ISSN 2045-2322. doi: 10.1038/s41598-025-18425-9. URLhttps://doi.org/10. 1038/s41598-025-18425-9. D. B. Rubin. The Bayesian bootstrap.The Annals of Statistics, 9(1):130 – 134,
-
[17]
URLhttps://doi.org/10.1214/aos/1176345338
doi: 10.1214/ aos/1176345338. URLhttps://doi.org/10.1214/aos/1176345338. S. Salerno, K. Hoffman, A. Afiaz, A. Neufeld, T . H. McCormick, and J. T . Leek. Do we really even need data? A modern look at drawing inference with predicted data,
- [18]
-
[19]
ISSN 0006-3444. doi: 10.1093/biomet/asy054. URLhttps://doi.org/10.1093/biomet/ asy054. E. D. Vaishnav, C. G. de Boer, J. Molinet, M. Yassour, L. Fan, X. Adiconis, D. A. Thompson, J. Z. Levin, F . A. Cubillos, and A. Regev. The evolution, evolvability and engineering of gene regulatory DNA. Nature, 603(7901):455–463, Mar
-
[21]
URLhttps://www.pnas.org/doi/abs/10.1073/ pnas.2001238117
doi: 10.1073/pnas.2001238117. URLhttps://www.pnas.org/doi/abs/10.1073/ pnas.2001238117. C. Ziems, W . Held, O. Shaikh, J. Chen, Z. Zhang, and D. Yang. Can large language models transform computational social science?Computational Linguistics, 50(1):237–291, Mar
-
[22]
URLhttps://aclanthology.org/2024.cl-1.8/
doi: 10.1162/ coli_a_00502. URLhttps://aclanthology.org/2024.cl-1.8/. T . Zrnic and E. J. Candès. Cross-prediction-powered inference.Proceedings of the National Academy of Sciences, 121(15):e2322083121,
work page 2024
-
[23]
doi: 10.1073/pnas.2322083121. URLhttps://www.pnas. org/doi/abs/10.1073/pnas.2322083121. 12 A Proofs In this section, we provide proofs for the results discussed in the main text. The following conditions are sufficient for Theorem 3.1. All op(·)and Op(·)statements involving Pˆηm are with respect to the joint randomness of the calibration and inference sam...
-
[24]
ThenR γ 0,m(θ)−R γ(θ) =γ Pˆηm ℓθ −P 0ℓθ
First consider the oracle mixed riskR γ 0,m(θ):=P 0ℓθ +γP ˆηm ℓθ. ThenR γ 0,m(θ)−R γ(θ) =γ Pˆηm ℓθ −P 0ℓθ . Therefore, sup θ∈Θ Rγ 0,m(θ)−R γ(θ) ≤γsup θ∈Θ Pˆηm ℓθ −P 0ℓθ =o p(1). (A.1) We apply Theorem 5.7 of van der Vaart, 1998 to the negative risks. Set Mm(θ ) = −Rγ 0,m(θ )and M (θ ) = −Rγ(θ ). Then, the uniform convergence condition of Theorem 5.7 is sa...
work page 1998
-
[25]
The triangle inequality then yields ∥P ˆηmh−P 0h∥ ≤ ∥P ˆηmh−P mh∥+∥P mh−P 0h∥. The first term is Op(m−1/2)by assumption, and the second term is Op(m−1/2)by the multivariate central limit theorem, using the assumption that P0∥h∥2 <∞ . Therefore, we may conclude that (P ˆηm −P 0)g θ0 =O p(m−1/2). 15 5 6 7 0.5 quantile Classical (labeled only) PPI++ AI Prior...
work page 2023
-
[26]
For moment matching, we fit a parametric rectifier (a scalar additive shift for gene expression, and an affine transformation for the OLS coefficient) by choosing its parameters to match the relevant empirical statistic on the calibration sample. Fixed, split, and NPB strategies refer to constructing the calibration sample by using the entire labeled samp...
work page 2000
-
[27]
URLhttps://proceedings.neurips.cc/paper_files/paper/2021/file/ 32e54441e6382a7fbacbbbaf3c450059-Paper.pdf. N. Ilter and H. Guvenir. Dermatology. UCI Machine Learning Repository,
work page 2021
-
[28]
DOI: https://doi.org/10.24432/C5FK5P . S. P . Lyddon, C. C. Holmes, and S. G. Walker. General Bayesian updating and the loss-likelihood bootstrap.Biometrika, 106(2):465–478, 06
-
[29]
ISSN 0006-3444. doi: 10.1093/biomet/asz006. URLhttps://doi.org/10.1093/biomet/asz006. M. A. Newton.The Weighted Likelihood Bootstrap and an Algorithm for Prepivoting. PhD thesis, University of Washington, Seattle, WA, USA,
-
[30]
doi: 10.1038/s41586-022-04506-6. A. W . van der Vaart.Asymptotic Statistics. Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.