Recognition: 2 theorem links
· Lean TheoremReCoVR: Closing the Loop in Interactive Composed Video Retrieval
Pith reviewed 2026-05-12 04:06 UTC · model grok-4.3
The pith
ReCoVR closes the loop in interactive video retrieval by adding a reflection pathway that diagnoses drifting searches from history and feedback.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
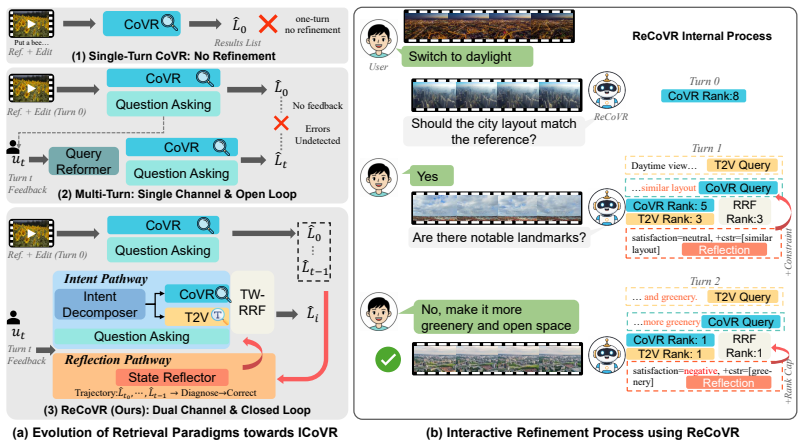
ReCoVR is a dual-pathway architecture for interactive composed video retrieval built on reflexive perception. An Intent Pathway routes heterogeneous user feedback to complementary retrieval channels, while a Reflection Pathway performs trajectory-level reflection on result evolution to monitor and correct retrieval errors across turns.
What carries the argument
Dual-pathway reflexive architecture: an Intent Pathway that routes feedback to retrieval channels and a Reflection Pathway that diagnoses retrieval trajectories from history.
If this is right
- Multi-turn video search becomes feasible with progressive natural-language refinements instead of single-round attempts.
- Retrieval performance improves consistently over open-loop interactive baselines on standard datasets.
- High recall at rank one (74.30 percent) is reachable after only one interactive round on WebVid-CoVR-Test.
- Both single-channel reliance and lack of self-diagnosis are mitigated by treating retrieval history as diagnostic input.
Where Pith is reading between the lines
- Similar reflection mechanisms could be added to other interactive retrieval or recommendation systems that maintain conversation history.
- Users may locate target videos with fewer total turns once the system begins self-correcting its own path.
- The approach opens a route to longer-horizon visual search sessions where cumulative feedback is actively monitored rather than discarded after each round.
Load-bearing premise
The reflection pathway can reliably detect when a retrieval trajectory is drifting or stagnating from the provided history and feedback.
What would settle it
A controlled test on a dataset with deliberately crafted feedback sequences that cause the reflection pathway to misdiagnose trajectories, after which ReCoVR shows no gain or a loss relative to non-reflexive baselines.
Figures








read the original abstract
Composed video retrieval (CoVR) searches for target videos using a reference video and a modification text, but existing methods are restricted to a single interaction round and cannot support the progressive nature of real-world visual search. To bridge this gap, we first formalize interactive composed video retrieval, a multi-turn extension of CoVR, where users progressively refine their search intent through natural-language feedback across turns. Adapting existing interactive retrieval methods to this setting reveals two structural weaknesses: reliance on a single retrieval channel and an open-loop retrieval design that consumes user feedback but does not diagnose whether its own retrieval trajectory is drifting or stagnating. To address these limitations, we propose ReCoVR (Reflexive Composed Video Retrieval), a dual-pathway architecture built on reflexive perception, where the system treats its retrieval history as diagnostic evidence alongside user feedback. Specifically, an Intent Pathway routes heterogeneous feedback to complementary retrieval channels, while a Reflection Pathway performs trajectory-level reflection to monitor result evolution and correct retrieval errors across turns. Experiments on multiple benchmarks show that ReCoVR consistently outperforms interactive baselines, notably achieving 74.30% R@1 after just one interactive round on the WebVid-CoVR-Test dataset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript formalizes interactive composed video retrieval (iCoVR) as a multi-turn extension of single-round CoVR, where users refine intent via natural-language feedback. It identifies two weaknesses in adapted baselines—single retrieval channel and open-loop design that ignores trajectory drift/stagnation—and proposes ReCoVR, a dual-pathway reflexive architecture. The Intent Pathway routes heterogeneous feedback to complementary channels; the Reflection Pathway monitors retrieval history to diagnose and correct errors across turns. Experiments on multiple benchmarks are reported to show consistent gains, including 74.30% R@1 after one round on WebVid-CoVR-Test.
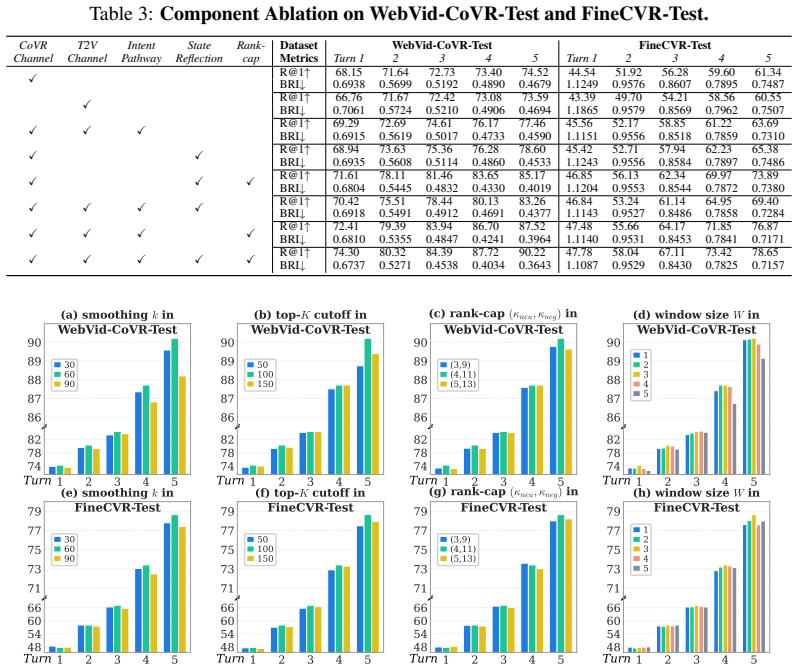
Significance. If the Reflection Pathway's trajectory diagnosis is shown to drive gains beyond the Intent Pathway alone, and if the empirical results prove robust, this work could meaningfully advance interactive video retrieval by introducing reflexive correction mechanisms that address a common failure mode in multi-turn search. The formalization of iCoVR itself is a clear contribution that enables future benchmarking.
major comments (3)
- [Abstract / Reflection Pathway description] Abstract and method description of Reflection Pathway: the central claim that the dual-pathway design 'closes the loop' by diagnosing drifting or stagnating trajectories requires explicit specification of (a) which history features are extracted, (b) the criteria or model used to detect drift/stagnation, and (c) how corrections are routed back to the retrieval channels. Without these, it is impossible to determine whether the Reflection Pathway performs substantive diagnosis or merely concatenates prior results.
- [Experiments / WebVid-CoVR-Test results] Experiments on WebVid-CoVR-Test (one-round result): the reported 74.30% R@1 after a single interactive round cannot involve the Reflection Pathway, as no retrieval history yet exists. This directly undermines the assertion that the dual-pathway architecture is responsible for the observed gains; an ablation isolating Intent Pathway alone versus full ReCoVR is required to support the claim.
- [Experiments / Ablations] Ablation and baseline comparison sections: no ablations or statistical significance tests are referenced that quantify the Reflection Pathway's incremental contribution over single-channel or open-loop baselines. Given that the one-round result is highlighted as evidence of closing the loop, this omission is load-bearing for the paper's primary thesis.
minor comments (1)
- [Abstract] The abstract would benefit from naming the full set of benchmarks and briefly indicating baseline adaptations to allow readers to gauge the scope of the empirical evaluation.
Simulated Author's Rebuttal
We thank the referee for their thorough and constructive review. We appreciate the recognition of the iCoVR formalization as a contribution and the identification of areas needing clarification. We address each major comment below and outline the revisions we will implement.
read point-by-point responses
-
Referee: [Abstract / Reflection Pathway description] Abstract and method description of Reflection Pathway: the central claim that the dual-pathway design 'closes the loop' by diagnosing drifting or stagnating trajectories requires explicit specification of (a) which history features are extracted, (b) the criteria or model used to detect drift/stagnation, and (c) how corrections are routed back to the retrieval channels. Without these, it is impossible to determine whether the Reflection Pathway performs substantive diagnosis or merely concatenates prior results.
Authors: We agree that the Reflection Pathway requires more explicit specification to substantiate its diagnostic role. In the revised manuscript, we will expand the method section to detail: (a) the extracted history features, including temporal shifts in retrieval similarity scores, result diversity indices, and cumulative intent drift metrics; (b) the detection criteria, implemented via a trajectory analyzer that combines rule-based thresholds on stagnation (e.g., repeated low-variance results) with a lightweight classifier for drift; and (c) the routing of corrections, where diagnostic outputs adjust channel priorities and query reformulations in the Intent Pathway. We will also update the abstract to reference these mechanisms, ensuring the description moves beyond high-level claims. revision: yes
-
Referee: [Experiments / WebVid-CoVR-Test results] Experiments on WebVid-CoVR-Test (one-round result): the reported 74.30% R@1 after a single interactive round cannot involve the Reflection Pathway, as no retrieval history yet exists. This directly undermines the assertion that the dual-pathway architecture is responsible for the observed gains; an ablation isolating Intent Pathway alone versus full ReCoVR is required to support the claim.
Authors: The referee is correct that the one-round 74.30% R@1 on WebVid-CoVR-Test reflects the Intent Pathway alone, since no prior trajectory exists for reflection. We will revise the text to explicitly distinguish this result as validation of the intent-routing component rather than the full dual-pathway claim. To address the concern, we will add multi-turn experiments on appropriate benchmarks and include an ablation comparing the Intent Pathway-only variant against the complete ReCoVR model, thereby isolating the Reflection Pathway's incremental value in extended interactions. revision: partial
-
Referee: [Experiments / Ablations] Ablation and baseline comparison sections: no ablations or statistical significance tests are referenced that quantify the Reflection Pathway's incremental contribution over single-channel or open-loop baselines. Given that the one-round result is highlighted as evidence of closing the loop, this omission is load-bearing for the paper's primary thesis.
Authors: We acknowledge the lack of targeted ablations and significance testing for the Reflection Pathway in the current manuscript. In the revision, we will add ablation experiments that disable the Reflection Pathway while retaining the Intent Pathway, reporting performance deltas against both the full model and the open-loop baselines. We will also incorporate statistical significance tests (paired t-tests with p-values and effect sizes) on the key metrics to rigorously quantify the Reflection Pathway's contributions. These additions will directly support the primary thesis. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper formalizes interactive composed video retrieval as a multi-turn extension of CoVR, identifies structural weaknesses in prior single-channel open-loop methods, and proposes a dual-pathway ReCoVR architecture (Intent Pathway for routing feedback and Reflection Pathway for trajectory diagnosis) as a design choice. All reported outcomes are empirical performance numbers (e.g., R@1 on WebVid-CoVR-Test) obtained from experiments on external benchmarks rather than quantities derived by definition, fitted parameters renamed as predictions, or self-citation chains. No equations, uniqueness theorems, or ansatzes are invoked that reduce to the paper's own inputs; the central claim rests on measured gains against baselines, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Neural networks can effectively encode and combine video and text features for retrieval tasks.
invented entities (2)
-
Intent Pathway
no independent evidence
-
Reflection Pathway
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ReCoVR... dual-pathway architecture... Intent Pathway routes heterogeneous feedback to complementary retrieval channels, while a Reflection Pathway performs trajectory-level reflection to monitor result evolution and correct retrieval errors across turns.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Covr: Learning composed video retrieval from web video captions
Lucas Ventura, Antoine Yang, Cordelia Schmid, and Gül Varol. Covr: Learning composed video retrieval from web video captions. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 5270–5279, 2024
work page 2024
-
[2]
Lucas Ventura, Antoine Yang, Cordelia Schmid, and Gül Varol. Covr-2: Automatic data construction for composed video retrieval.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):11409–11421, 2024
work page 2024
-
[3]
Beyond simple edits: Composed video retrieval with dense modifications
Omkar Thawakar, Dmitry Demidov, Ritesh Thawkar, Rao Muhammad Anwer, Mubarak Shah, Fahad Shahbaz Khan, and Salman Khan. Beyond simple edits: Composed video retrieval with dense modifications. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20435–20444, 2025
work page 2025
-
[4]
WU Yue, Zhaobo Qi, Yiling Wu, Junshu Sun, Yaowei Wang, and Shuhui Wang. Learning fine-grained representations through textual token disentanglement in composed video retrieval. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[5]
Composed video retrieval via enriched context and discriminative embeddings
Omkar Thawakar, Muzammal Naseer, Rao Muhammad Anwer, Salman Khan, Michael Felsberg, Mubarak Shah, and Fahad Shahbaz Khan. Composed video retrieval via enriched context and discriminative embeddings. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26896–26906, 2024
work page 2024
-
[6]
Exploratory search: from finding to understanding.Communications of the ACM, 49(4):41–46, 2006
Gary Marchionini. Exploratory search: from finding to understanding.Communications of the ACM, 49(4):41–46, 2006
work page 2006
-
[7]
Simple baselines for interactive video retrieval with questions and answers
Kaiqu Liang and Samuel Albanie. Simple baselines for interactive video retrieval with questions and answers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11091–11101, 2023
work page 2023
-
[8]
Donghoon Han, Eunhwan Park, Gisang Lee, Adam Lee, and Nojun Kwak. Merlin: Multimodal embedding refinement via llm-based iterative navigation for text-video retrieval-rerank pipeline. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 547–562, 2024
work page 2024
-
[9]
Bingqing Zhang, Zhuo Cao, Heming Du, Yang Li, Xue Li, Jiajun Liu, and Sen Wang. Quantify- ing and narrowing the unknown: Interactive text-to-video retrieval via uncertainty minimization. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22120– 22130, 2025
work page 2025
-
[10]
Xiaoxiao Guo, Hui Wu, Yu Cheng, Steven Rennie, Gerald Tesauro, and Rogerio Feris. Dialog- based interactive image retrieval.Advances in neural information processing systems, 31, 2018
work page 2018
-
[11]
Fashionntm: Multi-turn fashion image retrieval via cascaded memory
Anwesan Pal, Sahil Wadhwa, Ayush Jaiswal, Xu Zhang, Yue Wu, Rakesh Chada, Pradeep Natarajan, and Henrik I Christensen. Fashionntm: Multi-turn fashion image retrieval via cascaded memory. InProceedings of the IEEE/CVF international conference on computer vision, pages 11323–11334, 2023
work page 2023
-
[12]
Mai: A multi-turn aggregation- iteration model for composed image retrieval
Yanzhe Chen, Zhiwen Yang, Jinglin Xu, and Yuxin Peng. Mai: A multi-turn aggregation- iteration model for composed image retrieval. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[13]
Imagescope: Unifying language-guided image retrieval via large multimodal model collective reasoning
Pengfei Luo, Jingbo Zhou, Tong Xu, Yuan Xia, Linli Xu, and Enhong Chen. Imagescope: Unifying language-guided image retrieval via large multimodal model collective reasoning. In Proceedings of the ACM on Web Conference 2025, pages 1666–1682, 2025
work page 2025
-
[14]
Automatic spatially-aware fashion concept discovery
Xintong Han, Zuxuan Wu, Phoenix X Huang, Xiao Zhang, Menglong Zhu, Yuan Li, Yang Zhao, and Larry S Davis. Automatic spatially-aware fashion concept discovery. InProceedings of the IEEE international conference on computer vision, pages 1463–1471, 2017. 10
work page 2017
-
[15]
Composing text and image for image retrieval-an empirical odyssey
Nam V o, Lu Jiang, Chen Sun, Kevin Murphy, Li-Jia Li, Li Fei-Fei, and James Hays. Composing text and image for image retrieval-an empirical odyssey. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6439–6448, 2019
work page 2019
-
[16]
Learning joint visual semantic matching embeddings for language-guided retrieval
Yanbei Chen and Loris Bazzani. Learning joint visual semantic matching embeddings for language-guided retrieval. InEuropean Conference on Computer Vision, pages 136–152. Springer, 2020
work page 2020
-
[17]
Image retrieval on real-life images with pre-trained vision-and-language models
Zheyuan Liu, Cristian Rodriguez-Opazo, Damien Teney, and Stephen Gould. Image retrieval on real-life images with pre-trained vision-and-language models. InProceedings of the IEEE/CVF international conference on computer vision, pages 2125–2134, 2021
work page 2021
-
[18]
Fashion iq: A new dataset towards retrieving images by natural language feedback
Hui Wu, Yupeng Gao, Xiaoxiao Guo, Ziad Al-Halah, Steven Rennie, Kristen Grauman, and Rogerio Feris. Fashion iq: A new dataset towards retrieving images by natural language feedback. InProceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pages 11307–11317, 2021
work page 2021
-
[19]
Hud: Hierarchi- cal uncertainty-aware disambiguation network for composed video retrieval
Zhiwei Chen, Yupeng Hu, Zixu Li, Zhiheng Fu, Haokun Wen, and Weili Guan. Hud: Hierarchi- cal uncertainty-aware disambiguation network for composed video retrieval. InProceedings of the 33rd ACM International Conference on Multimedia, pages 6143–6152, 2025
work page 2025
-
[20]
Hao Wang, Fang Liu, Licheng Jiao, Jiahao Wang, Shuo Li, Lingling Li, Puhua Chen, and Xu Liu. Vision-by-prompt: Context-aware dual prompts for composed video retrieval.Pattern Recognition, page 112378, 2025
work page 2025
-
[21]
Refine: Composed video retrieval via shared and differential semantics enhancement
Yupeng Hu, Zixu Li, Zhiwei Chen, Qinlei Huang, Zhiheng Fu, Mingzhu Xu, and Liqiang Nie. Refine: Composed video retrieval via shared and differential semantics enhancement. ACM Trans. Multimedia Comput. Commun. Appl., February 2026. ISSN 1551-6857. doi: 10.1145/3796712. Just Accepted
-
[22]
Egocvr: An egocentric benchmark for fine-grained composed video retrieval
Thomas Hummel, Shyamgopal Karthik, Mariana-Iuliana Georgescu, and Zeynep Akata. Egocvr: An egocentric benchmark for fine-grained composed video retrieval. InEuropean Conference on Computer Vision, pages 1–17. Springer, 2024
work page 2024
-
[23]
Animesh Gupta, Jay Parmar, Ishan Rajendrakumar Dave, and Mubarak Shah. From play to replay: Composed video retrieval for temporally fine-grained videos.arXiv preprint arXiv:2506.05274, 2025
-
[24]
OmniCVR: A benchmark for omni-composed video retrieval with vision, audio, and text
Junyang Ji, Shengjun Zhang, Da Li, Yuxiao Luo, Yan Wang, Di Xu, Biao Yang, Wei Yuan, Fan Yang, Zhihai He, and Wenming Yang. OmniCVR: A benchmark for omni-composed video retrieval with vision, audio, and text. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=KxxR7emO5K
work page 2026
-
[25]
Covr-r: Reason-aware composed video retrieval.arXiv preprint arXiv:2603.20190, 2026
Omkar Thawakar, Dmitry Demidov, Vaishnav Potlapalli, Sai Prasanna Teja Reddy Bogireddy, Viswanatha Reddy Gajjala, Alaa Mostafa Lasheen, Rao Muhammad Anwer, and Fahad Khan. Covr-r: Reason-aware composed video retrieval.arXiv preprint arXiv:2603.20190, 2026
-
[26]
Yong Rui, Thomas S Huang, Michael Ortega, and Sharad Mehrotra. Relevance feedback: a power tool for interactive content-based image retrieval.IEEE Transactions on circuits and systems for video technology, 8(5):644–655, 1998
work page 1998
-
[27]
Willhunter: interactive image retrieval with multilevel relevance
Hong Wu, Hanqing Lu, and Songde Ma. Willhunter: interactive image retrieval with multilevel relevance. InProceedings of the 17th International Conference on Pattern Recognition, 2004. ICPR 2004., volume 2, pages 1009–1012. IEEE, 2004
work page 2004
-
[28]
Ask&confirm: active detail enriching for cross-modal retrieval with partial query
Guanyu Cai, Jun Zhang, Xinyang Jiang, Yifei Gong, Lianghua He, Fufu Yu, Pai Peng, Xiaowei Guo, Feiyue Huang, and Xing Sun. Ask&confirm: active detail enriching for cross-modal retrieval with partial query. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1835–1844, 2021
work page 2021
-
[29]
Conversational fashion image retrieval via multiturn natural language feedback
Yifei Yuan and Wai Lam. Conversational fashion image retrieval via multiturn natural language feedback. InProceedings of the 44th International ACM SIGIR conference on research and development in information retrieval, pages 839–848, 2021. 11
work page 2021
-
[30]
Conversational com- posed retrieval with iterative sequence refinement
Hao Wei, Shuhui Wang, Zhe Xue, Shengbo Chen, and Qingming Huang. Conversational com- posed retrieval with iterative sequence refinement. InProceedings of the 31st ACM international conference on multimedia, pages 6390–6399, 2023
work page 2023
-
[31]
Matan Levy, Rami Ben-Ari, Nir Darshan, and Dani Lischinski. Chatting makes perfect: Chat- based image retrieval.Advances in Neural Information Processing Systems, 36:61437–61449, 2023
work page 2023
-
[32]
Interactive text-to- image retrieval with large language models: A plug-and-play approach
Saehyung Lee, Sangwon Yu, Junsung Park, Jihun Yi, and Sungroh Yoon. Interactive text-to- image retrieval with large language models: A plug-and-play approach. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 791–809, 2024
work page 2024
-
[33]
Interactive cross-modal learning for text-3d scene retrieval
Yanglin Feng, Yongxiang Li, Yuan Sun, Yang Qin, Dezhong Peng, and Peng Hu. Interactive cross-modal learning for text-3d scene retrieval. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[34]
Yiding Lu, Mouxing Yang, Dezhong Peng, Peng Hu, Yijie Lin, and Xi Peng. Llava-reid: Selective multi-image questioner for interactive person re-identification.arXiv preprint arXiv:2504.10174, 2025
-
[35]
Chat-based person retrieval via dialogue-refined cross-modal alignment
Yang Bai, Yucheng Ji, Min Cao, Jinqiao Wang, and Mang Ye. Chat-based person retrieval via dialogue-refined cross-modal alignment. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3952–3962, 2025
work page 2025
-
[36]
Chatting with interactive memory for text-based person retrieval.Multimedia Systems, 31(1):31, 2025
Chen He, Shenshen Li, Zheng Wang, Hua Chen, Fumin Shen, and Xing Xu. Chatting with interactive memory for text-based person retrieval.Multimedia Systems, 31(1):31, 2025
work page 2025
-
[37]
Human-centered interactive learning via mllms for text-to-image person re-identification
Yang Qin, Chao Chen, Zhihang Fu, Dezhong Peng, Xi Peng, and Peng Hu. Human-centered interactive learning via mllms for text-to-image person re-identification. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14390–14399, 2025
work page 2025
-
[38]
Ivcr-200k: A large-scale multi-turn dialogue benchmark for interactive video corpus retrieval
Ning Han, Yawen Zeng, Shaohua Long, Chengqing Li, Sijie Yang, Dun Tan, Jianfeng Dong, and Jingjing Chen. Ivcr-200k: A large-scale multi-turn dialogue benchmark for interactive video corpus retrieval. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 127–137, 2025
work page 2025
-
[39]
Multimodal llm-based query paraphrasing for video search.arXiv preprint arXiv:2407.12341, 2024
Jiaxin Wu, Chong-Wah Ngo, Wing-Kwong Chan, Sheng-Hua Zhong, Xiong-Yong Wei, and Qing Li. Multimodal llm-based query paraphrasing for video search.arXiv preprint arXiv:2407.12341, 2024
-
[40]
A study of methods for negative relevance feedback
Xuanhui Wang, Hui Fang, and ChengXiang Zhai. A study of methods for negative relevance feedback. InProceedings of the 31st annual international ACM SIGIR conference on Research and development in information retrieval, pages 219–226, 2008
work page 2008
-
[41]
Conversational product search based on negative feedback
Keping Bi, Qingyao Ai, Yongfeng Zhang, and W Bruce Croft. Conversational product search based on negative feedback. InProceedings of the 28th acm international conference on information and knowledge management, pages 359–368, 2019
work page 2019
-
[42]
Reciprocal rank fusion outper- forms condorcet and individual rank learning methods
Gordon V Cormack, Charles LA Clarke, and Stefan Buettcher. Reciprocal rank fusion outper- forms condorcet and individual rank learning methods. InProceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval, pages 758–759, 2009
work page 2009
-
[43]
MSR-VTT: A large video description dataset for bridging video and language
Jun Xu, Tao Mei, Ting Yao, and Yong Rui. MSR-VTT: A large video description dataset for bridging video and language. In2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV , USA, June 27-30, 2016, pages 5288–5296. IEEE Computer Society, 2016. doi: 10.1109/CVPR.2016.571
-
[44]
A joint sequence fusion model for video question answering and retrieval
Youngjae Yu, Jongseok Kim, and Gunhee Kim. A joint sequence fusion model for video question answering and retrieval. InProceedings of the European conference on computer vision (ECCV), pages 471–487, 2018. 12
work page 2018
-
[45]
Audio visual scene-aware dialog
Huda Alamri, Vincent Cartillier, Abhishek Das, Jue Wang, Anoop Cherian, Irfan Essa, Dhruv Batra, Tim K Marks, Chiori Hori, Peter Anderson, et al. Audio visual scene-aware dialog. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7558–7567, 2019
work page 2019
-
[46]
Chenyang Lyu, Manh-Duy Nguyen, Van-Tu Ninh, Liting Zhou, Cathal Gurrin, and Jennifer Foster. Dialogue-to-video retrieval. In Jaap Kamps, Lorraine Goeuriot, Fabio Crestani, Maria Maistro, Hideo Joho, Brian Davis, Cathal Gurrin, Udo Kruschwitz, and Annalina Caputo, editors, Advances in Information Retrieval - 45th European Conference on Information Retrieva...
-
[47]
Learning to retrieve videos by asking questions
Avinash Madasu, Junier Oliva, and Gedas Bertasius. Learning to retrieve videos by asking questions. In João Magalhães, Alberto Del Bimbo, Shin’ichi Satoh, Nicu Sebe, Xavier Alameda- Pineda, Qin Jin, Vincent Oria, and Laura Toni, editors,MM ’22: The 30th ACM International Conference on Multimedia, Lisboa, Portugal, October 10 - 14, 2022, pages 356–365. ACM,
work page 2022
-
[48]
doi: 10.1145/3503161.3548361
-
[49]
Usimagent: Large language models for simulating search users
Erhan Zhang, Xingzhu Wang, Peiyuan Gong, Yankai Lin, and Jiaxin Mao. Usimagent: Large language models for simulating search users. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2687–2692, 2024
work page 2024
-
[50]
User simulation for evaluating information access systems
Krisztian Balog and ChengXiang Zhai. User simulation for evaluating information access systems. InProceedings of the Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region, pages 302–305, 2023
work page 2023
-
[51]
Adept: An entropy-driven dual-strategy agent for interactive video retrieval
Ke Chen, Shengyuan Han, Yongfeng Huang, Yujin Zhu, Jingwei Xiong, Liang Xu, and Jun- dong Liu. Adept: An entropy-driven dual-strategy agent for interactive video retrieval. In ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 9442–9446. IEEE, 2026
work page 2026
-
[52]
Yao Dou, Michel Galley, Baolin Peng, Chris Kedzie, Weixin Cai, Alan Ritter, Chris Quirk, Wei Xu, and Jianfeng Gao. Simulatorarena: Are user simulators reliable proxies for multi-turn evaluation of ai assistants? InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 35200–35278, 2025
work page 2025
-
[53]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language- image pre-training for unified vision-language understanding and generation. InInternational conference on machine learning, pages 12888–12900. PMLR, 2022
work page 2022
-
[55]
Lorenzo Agnolucci, Alberto Baldrati, Alberto Del Bimbo, and Marco Bertini. isearle: Improving textual inversion for zero-shot composed image retrieval.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[56]
Xr: Cross-modal agents for composed image retrieval.arXiv preprint arXiv:2601.14245, 2026
Zhongyu Yang, Wei Pang, and Yingfang Yuan. Xr: Cross-modal agents for composed image retrieval.arXiv preprint arXiv:2601.14245, 2026
-
[57]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021. 13
work page 2021
-
[58]
Bin Zhu, Bin Lin, Munan Ning, Yang Yan, Jiaxi Cui, HongFa Wang, Yatian Pang, Wenhao Jiang, Junwu Zhang, Zongwei Li, et al. Languagebind: Extending video-language pretraining to n-modality by language-based semantic alignment.arXiv preprint arXiv:2310.01852, 2023
-
[59]
Mingxin Li, Yanzhao Zhang, Dingkun Long, Keqin Chen, Sibo Song, Shuai Bai, Zhibo Yang, Pengjun Xie, An Yang, Dayiheng Liu, Jingren Zhou, and Junyang Lin. Qwen3-vl-embedding and qwen3-vl-reranker: A unified framework for state-of-the-art multimodal retrieval and ranking.arXiv, 2026
work page 2026
-
[60]
Trec cast 2019: The conversational assistance track overview.arXiv preprint arXiv:2003.13624, 2020
Jeffrey Dalton, Chenyan Xiong, and Jamie Callan. Trec cast 2019: The conversational assistance track overview.arXiv preprint arXiv:2003.13624, 2020
-
[61]
Building simulated queries for known- item topics: an analysis using six european languages
Leif Azzopardi, Maarten De Rijke, and Krisztian Balog. Building simulated queries for known- item topics: an analysis using six european languages. InProceedings of the 30th annual international ACM SIGIR conference on Research and development in information retrieval, pages 455–462, 2007
work page 2007
-
[62]
Towards a domain expert evaluation framework for conversational search in healthcare
Chadha Degachi, Ujjayan Dhar, Evangelos Niforatos, and Gerd Kortuem. Towards a domain expert evaluation framework for conversational search in healthcare. InProceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems, pages 1–9, 2025
work page 2025
-
[63]
Interactions with generative information retrieval systems
Mohammad Aliannejadi, Jacek Gwizdka, and Hamed Zamani. Interactions with generative information retrieval systems. InInformation Access in the Era of Generative AI, pages 47–71. Springer, 2024
work page 2024
-
[64]
A survey of conversational search.ACM Transactions on Information Systems, 43(6):1–50, 2025
Fengran Mo, Kelong Mao, Ziliang Zhao, Hongjin Qian, Haonan Chen, Yiruo Cheng, Xiaoxi Li, Yutao Zhu, Zhicheng Dou, and Jian-Yun Nie. A survey of conversational search.ACM Transactions on Information Systems, 43(6):1–50, 2025
work page 2025
-
[65]
An in-depth investigation of user response simulation for conversational search
Zhenduo Wang, Zhichao Xu, Vivek Srikumar, and Qingyao Ai. An in-depth investigation of user response simulation for conversational search. InProceedings of the ACM Web Conference 2024, pages 1407–1418, 2024
work page 2024
-
[66]
Interactive query clarification and refinement via user simulation
Pierre Erbacher, Ludovic Denoyer, and Laure Soulier. Interactive query clarification and refinement via user simulation. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2420–2425, 2022
work page 2022
-
[67]
Jielin Qiu, Yi Zhu, Xingjian Shi, Florian Wenzel, Zhiqiang Tang, Ding Zhao, Bo Li, and Mu Li. Benchmarking robustness of multimodal image-text models under distribution shift.arXiv preprint arXiv:2212.08044, 2022
-
[68]
Methods for evaluating interactive information retrieval systems with users
Diane Kelly. Methods for evaluating interactive information retrieval systems with users. Foundations and Trends® in Information Retrieval, 3(1–2):1–224, 2009
work page 2009
-
[69]
Jenny Preece, Yvonne Rogers, Helen Sharp, David Benyon, Simon Holland, and Tom Carey. Human-computer interaction. Addison-Wesley Longman Ltd., 1994
work page 1994
-
[70]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
work page 2022
-
[71]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023. 14 A More Ablation and Generalization Studies. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ...
-
[72]
Determine whether the feedback mainly answers the previous question
-
[73]
Determine whether the feedback contains explicit edit intent (change/remove/replace/add/make/swap/turn/switch/modify, etc.)
-
[74]
Extract search_query_info as target-descriptive information (objects/actions/scenes) when available
-
[75]
Extract edit_query_info only when edit intent exists
-
[76]
If feedback is purely an answer and no clear standalone target description is provided, search_query_info can be empty
-
[77]
If no edit intent, set edit_query_info to an empty string. Return JSON only: {output_schema} Output schema{"reasoning": "string (1-2 sentences)", "is_answer_to_prev_question": "boolean", "has_edit_intent": "boolean", "search_query_info": "string", "edit_query_info": "string"} Design Trade-offs and Deployment.ReCoVR uses simple, training-free, rank-level o...
-
[78]
Use only visible video content plus the given edit instruction
-
[79]
Produce one concise target description for retrieval
-
[80]
Keep key visual details (objects, actions, scene, attributes) while avoiding unnecessary verbosity. Return JSON only: {output_schema} Output schema{"reasoning": "string (1 sentence)", "search_query": "string"} Modulerewrite_queries(Turnt≥1, triggered when query exceeds length threshold) System promptnull TemplateTask: Compress a long retrieval query while...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.