Recognition: 2 theorem links
· Lean TheoremProximal Causal Inference for Hidden Outcomes
Pith reviewed 2026-05-12 02:00 UTC · model grok-4.3
The pith
Proximal causal inference identifies causal effects with completely hidden outcomes by using the spectral structure of proxy variables.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
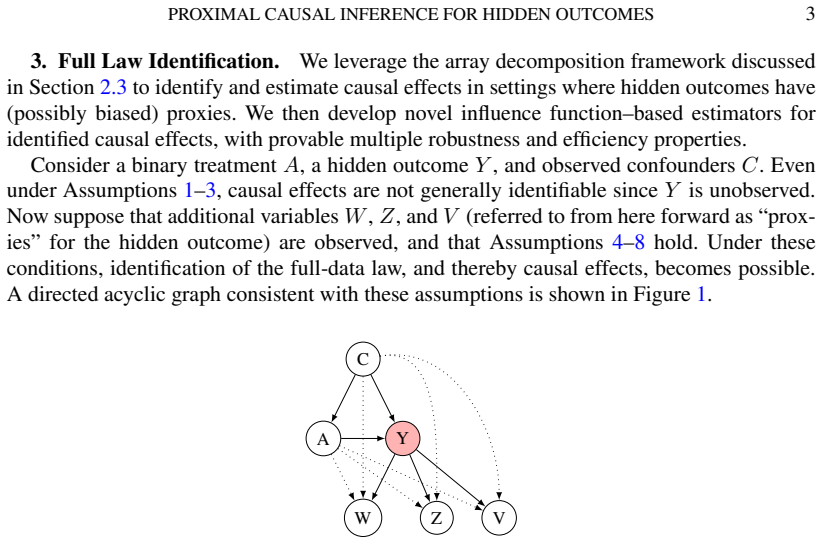
Within the proximal causal inference framework that exploits eigenvalue-eigenvector structure of proxies, the full data law is identified even when outcomes are hidden, and influence function based estimators for causal effects achieve multiple robustness and desirable efficiency properties without relying on unbiased proxy measurements or partial observation.
What carries the argument
proximal causal inference, the framework that reconstructs latent distributions from the eigenvalue-eigenvector decomposition of conditional expectation operators between proxies and hidden variables
If this is right
- Causal effects remain identifiable and consistently estimable when outcomes are never observed, provided the proxy spectral conditions hold.
- The resulting estimators are multiply robust, remaining consistent if at least one of several nuisance models is correct.
- The estimators attain the semiparametric efficiency bound under the identification conditions.
- Finite-sample performance is supported by simulation studies that vary the strength of the proxy relations.
Where Pith is reading between the lines
- The same spectral identification argument could be applied to longitudinal data with time-varying hidden outcomes.
- Empirical checks of the eigenvalue structure on observed proxies could serve as a diagnostic for whether the method is applicable to a given dataset.
- Hybrid estimators might combine the proximal approach with other latent-variable techniques when partial direct observations become available later in a study.
Load-bearing premise
The eigenvalue-eigenvector structure of the proxies is sufficient to identify the full data law in the presence of hidden outcomes.
What would settle it
A data-generating process in which the proxies obey the stated eigenvalue-eigenvector conditions yet the estimated causal effect differs from the true value computed from the full data.
Figures
read the original abstract
Methods that rely on proxies, without imposing strong parametric structure, are increasingly used to deal with unobserved variables in causal inference. One influential line of this work reconstructs latent distributions used to identify the target functional by exploiting eigenvalue eigenvector structure. Within this framework, we first establish identification of the full data law in the presence of hidden outcomes, and then develop influence function based estimators for causal effects. To the best of our knowledge, this is the first work to develop influence function based estimators in this setting without relying on unbiased proxy measurements or partial observation, while achieving multiple robustness and desirable efficiency properties. We demonstrate the performance of our approach through simulation studies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript establishes identification of the full data law for causal inference with hidden outcomes by exploiting eigenvalue-eigenvector structure in operators constructed from proxy variables. It then constructs influence-function-based estimators for causal effects that are claimed to be multiply robust and asymptotically efficient, without requiring unbiased proxies or partial observation of the outcome. Simulation studies are used to illustrate finite-sample performance.
Significance. If the identification result holds under the stated conditions and the estimators achieve the claimed robustness and efficiency, the work would provide a useful extension of proximal causal inference methods to settings with completely hidden outcomes. The influence-function approach could enable valid inference and efficiency gains over existing methods that rely on stronger parametric assumptions or different proxy structures.
major comments (1)
- [§3] §3 (Identification): The eigen-decomposition step used to recover the law of the hidden outcome and treatment from the observed proxy joint distribution does not explicitly invoke or verify a distinct-eigenvalue condition or a completeness assumption on the relevant operator. Standard results on conditional expectation operators require such conditions to guarantee that the decomposition is unique and the mapping from proxy law to full-data law is injective. Absent this, there exist non-identifiable configurations (repeated eigenvalues or non-trivial kernels) in which the same observed proxy distribution is consistent with multiple distinct full-data laws, which would invalidate both the identification claim and the subsequent influence-function construction that depends on it.
minor comments (2)
- The abstract and introduction could more clearly delineate the precise proxy assumptions (e.g., whether the proxies are required to be conditionally independent of the outcome given the latent variables) relative to prior proximal inference literature.
- Simulation results would benefit from reporting coverage probabilities and bias under the exact data-generating processes used for the identification proof, rather than only summary performance metrics.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comment on the identification section is well-taken and highlights an important point about ensuring uniqueness of the eigen-decomposition. We address it below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3] §3 (Identification): The eigen-decomposition step used to recover the law of the hidden outcome and treatment from the observed proxy joint distribution does not explicitly invoke or verify a distinct-eigenvalue condition or a completeness assumption on the relevant operator. Standard results on conditional expectation operators require such conditions to guarantee that the decomposition is unique and the mapping from proxy law to full-data law is injective. Absent this, there exist non-identifiable configurations (repeated eigenvalues or non-trivial kernels) in which the same observed proxy distribution is consistent with multiple distinct full-data laws, which would invalidate both the identification claim and the subsequent influence-function construction that depends on it.
Authors: We agree that an explicit distinct-eigenvalue (or completeness) condition is required for the eigen-decomposition to be unique and for the mapping from the observed proxy law to the full-data law to be injective. While our identification argument in §3 relies on the operator having distinct eigenvalues (a standard requirement in the proximal inference literature to rule out non-trivial kernels), this assumption was not stated formally. In the revised manuscript we will add a new assumption (e.g., Assumption 3.3) requiring that the relevant conditional expectation operator has distinct eigenvalues and is complete. We will then restate the identification theorem to make the injectivity explicit and verify that the subsequent influence-function construction remains valid under this condition. This clarification does not change the substantive results but strengthens the rigor of the identification step. revision: yes
Circularity Check
No circularity: identification and estimation steps are mathematically derived from proxy structure without reduction to inputs by construction
full rationale
The abstract states that identification of the full data law is first established via eigenvalue-eigenvector structure of the proxies, followed by construction of influence-function estimators that achieve multiple robustness. No quoted equation or step reduces a claimed prediction or result to a fitted parameter, self-defined quantity, or self-citation chain that would make the output equivalent to the input by definition. The derivation chain is presented as a sequence of identification then estimation, with no evidence of self-definitional loops, fitted inputs relabeled as predictions, or load-bearing uniqueness imported solely from the authors' prior unverified work. This is the normal case of a self-contained mathematical and statistical argument.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearWe leverage the array decomposition framework... exploiting eigenvalue-eigenvector structure... completeness conditions... Theorem 3.1. Under Assumptions 4-8, the full-data law... is identified.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearKruskal’s uniqueness theorem for the Candecomp/Parafac (CP) decomposition... unique eigenspaces... eigendecomposition steps
Reference graph
Works this paper leans on
-
[1]
ALLMAN, E., MATIAS, C. and RHODES, J. (2009). Identifiability of Parameters in Latent Structure Models with Many Observed Variables.The Annals of Statistics373099-3132
work page 2009
-
[2]
CANAY, I. A., SANTOS, A. and SHAIKH, A. M. (2013). On the Testability of Identification in Some Nonparametric Models With Endogeneity.Econometrica812535-2559. https://doi.org/10.3982/ ECTA10851
work page 2013
-
[3]
CHEN, J. M., MALINSKY, D. and BHATTACHARYA, R. (2023). Causal inference with outcome-dependent missingness and self-censoring. InProceedings of the Thirty-Ninth Conference on Uncertainty in Ar- tificial Intelligence.UAI ’23. JMLR.org
work page 2023
-
[4]
CUI, Y., PU, H., SHI, X., MIAO, W. and TCHETGEN, E. T. (2024). Semiparametric Proximal Causal Inference.Journal of the American Statistical Association1191348–1359. https://doi.org/10.1080/ 01621459.2023.2191817
-
[5]
DEANER, B. (2023). Controlling for Latent Confounding with Triple Proxies. 20
work page 2023
-
[6]
DING, P. and LI, F. (2018). Causal Inference: A Missing Data Perspective.Statistical Science33214 – 237. https://doi.org/10.1214/18-STS645
-
[7]
DUARTE, G., FINKELSTEIN, N., KNOX, D., MUMMOLO, J. and SHPITSER, I. (2024). An Automated Approach to Causal Inference in Discrete Settings.Journal of the American Statistical Association 1191778–1793. https://doi.org/10.1080/01621459.2023.2216909
-
[8]
FU, J. and GREEN, D. P. Nonparametric Identification and Estimation of Causal Effects on Latent Out- comes.arXiv
-
[9]
GHASSAMI, A., YANG, A., SHPITSER, I. and TCHETGENTCHETGEN, E. (2025). Causal inference with hidden mediators.Biometrika112asae037. https://doi.org/10.1093/biomet/asae037
-
[10]
GUO, H., OGBURN, E. L. and SHPITSER, I. Comparing Two Proxy Methods for Causal Identification. arXiv
-
[11]
HU, Y. and SCHENNACH, S. (2008). Instrumental Variable Treatment of Nonclassical Measurement Error Models.Econometrica76195–216. https://doi.org/10.1111/j.0012-9682.2008.00823.x
-
[12]
IMAI, K. and YAMAMOTO, T. (2010). Causal Inference with Differential Measurement Error: Nonparamet- ric Identification and Sensitivity Analysis.American Journal of Political Science54543–560
work page 2010
-
[13]
KENNEDY, E. H. (2024). Semiparametric Doubly Robust Targeted Double Machine Learning: A Review. In Handbook of Statistical Methods for Precision Medicine1 ed. 10, 207–236. Chapman and Hall/CRC
work page 2024
-
[14]
KENNEDY, E. H., BALAKRISHNAN, S. and G’SELL, M. (2020). Sharp instruments for classifying compli- ers and generalizing causal effects.The Annals of Statistics482008–2030
work page 2020
-
[15]
KOLDA, T. G. and HONG, D. (2020). Stochastic Gradients for Large-Scale Tensor Decomposition.SIAM Journal on Mathematics of Data Science21066-1095. https://doi.org/10.1137/19M1266265
-
[16]
KRUSKAL, J. (1977). Three-way arrays: rank and uniqueness of trilinear decompositions, with applications to arithmetic complexity and statistics.Linear Algebra and its Applications1895–138. https://doi. org/10.1016/0024-3795(77)90069-6
-
[17]
KUROKI, M. and PEARL, J. (2014). Measurement bias and effect restoration in causal inference.Biometrika 101423-437
work page 2014
-
[18]
MIAO, W., GENG, Z. and TCHETGENTCHETGEN, E. J. (2018). Identifying causal effects with proxy variables of an unmeasured confounder.Biometrika105987–993
work page 2018
-
[19]
(1988).Probabilistic Reasoning in Intelligent Systems
PEARL, J. (1988).Probabilistic Reasoning in Intelligent Systems. Morgan and Kaufmann, San Mateo
work page 1988
- [20]
-
[21]
PHUNG, T., LEE, J. J. R., OLADAPO-SHITTU, O., KLEIN, E. Y., GURSES, A. P., HANNUM, S. M., WEEMS, K., MARSTELLER, J. A., COSGROVE, S. E., KELLER, S. C. and SHPITSER, I. (2024). Zero Inflation as a Missing Data Problem: a Proxy-based Approach. InProceedings of The 39th Uncertainty in Artificial Intelligence Conference
work page 2024
-
[22]
RHODES, J. A. (2010). A concise proof of Kruskal’s theorem on tensor decomposition.Linear Algebra and its Applications4321818-1824. https://doi.org/10.1016/j.laa.2009.11.033
-
[23]
RICHARDSON, T. S. and ROBINS, J. M. (2013). Single World Intervention Graphs (SWIGs): A Unification of the Counterfactual and Graphical Approaches to Causality.preprint: http://www.csss.washington. edu/Papers/wp128.pdf
work page 2013
-
[24]
ROBINS, J. M., ROTNITZKY, A. and ZHAO, L. P. (1994). Estimation of regression coefficients when some regressors are not always observed.Journal of the American Statistical Association89846-866
work page 1994
-
[25]
SPIRTES, P., GLYMOUR, C. and SCHEINES, R. (2001).Causation, Prediction, and Search, 2 ed. Springer Verlag, New York
work page 2001
-
[26]
USCHMAJEW, A. (2012). Local Convergence of the Alternating Least Squares Algorithm for Canonical Tensor Approximation.SIAM Journal on Matrix Analysis and Applications33639-652. https://doi. org/10.1137/110843587
-
[27]
VANDERWEELE, T. J. and HERNÁN, M. A. (2012). Results on Differential and Dependent Measurement Error of the Exposure and the Outcome Using Signed Directed Acyclic Graphs.American Journal of Epidemiology1751303–1310. https://doi.org/10.1093/aje/kwr458
-
[28]
ZHOU, Y. and TCHETGENTCHETGEN, E. (2024). Causal Inference for a Hidden Treatment
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.