Recognition: 2 theorem links
· Lean TheoremUnified Approach for Weakly Supervised Multicalibration
Pith reviewed 2026-05-12 04:55 UTC · model grok-4.3
The pith
A unified framework corrects multicalibration errors using only weakly supervised data by rewriting risks through contamination matrices and enforcing constraints via witnesses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a unified framework for estimating and correcting multicalibration under weak supervision by combining contamination-matrix risk rewrites with witness-based calibration constraints, yielding corrected multicalibration moments with finite-sample guarantees. We further propose weak-label multicalibration boost (WLMC), a generic post-hoc recalibration algorithm under weak supervision.
What carries the argument
contamination-matrix risk rewrites combined with witness-based calibration constraints that together produce corrected multicalibration moments
If this is right
- Multicalibration error can be estimated and reduced without access to clean labels in standard weak-supervision regimes.
- The WLMC algorithm supplies a practical post-hoc recalibration procedure that inherits finite-sample guarantees from the framework.
- The same contamination-matrix rewrite applies uniformly to positive-unlabeled, unlabeled-unlabeled, and positive-confidence learning.
- Empirical behavior of uncertainty estimates can be studied directly under weak supervision rather than only under full supervision.
Where Pith is reading between the lines
- The approach may enable reliable subgroup-wise uncertainty quantification in domains such as medical imaging where expert labels are scarce.
- Joint learning of the contamination matrix alongside the predictor could further reduce the need for any prior knowledge of the weak-supervision process.
- The witness-based constraints could be combined with existing fairness or robustness methods that also operate on subgroup partitions.
Load-bearing premise
The weak supervision process can be accurately captured by a known contamination matrix and that suitable witness functions exist to enforce the desired calibration constraints.
What would settle it
A controlled simulation in which the supplied contamination matrix is deliberately misspecified by a known amount and the observed multicalibration error after correction exceeds the finite-sample bound predicted by the framework.
Figures
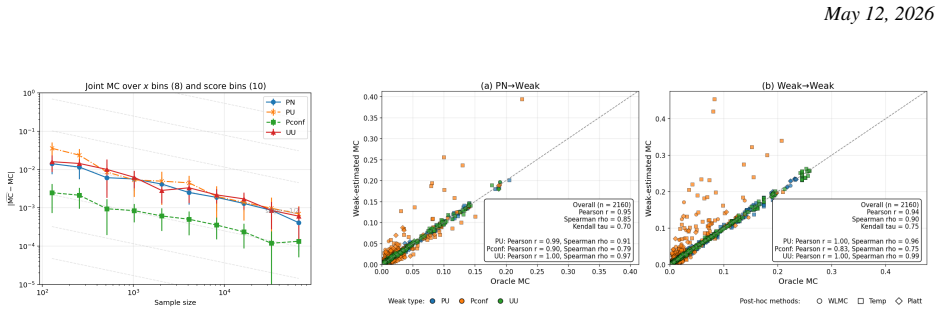

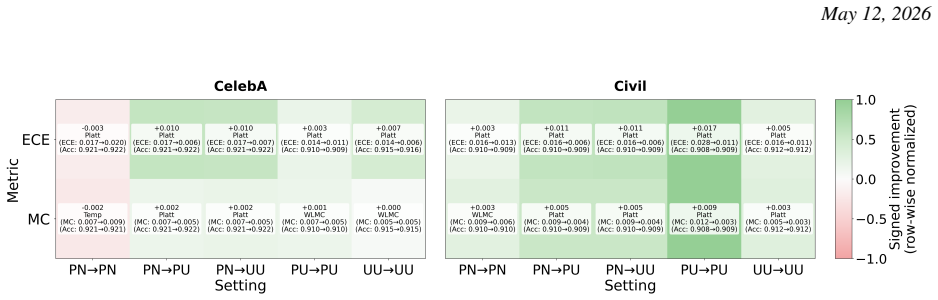
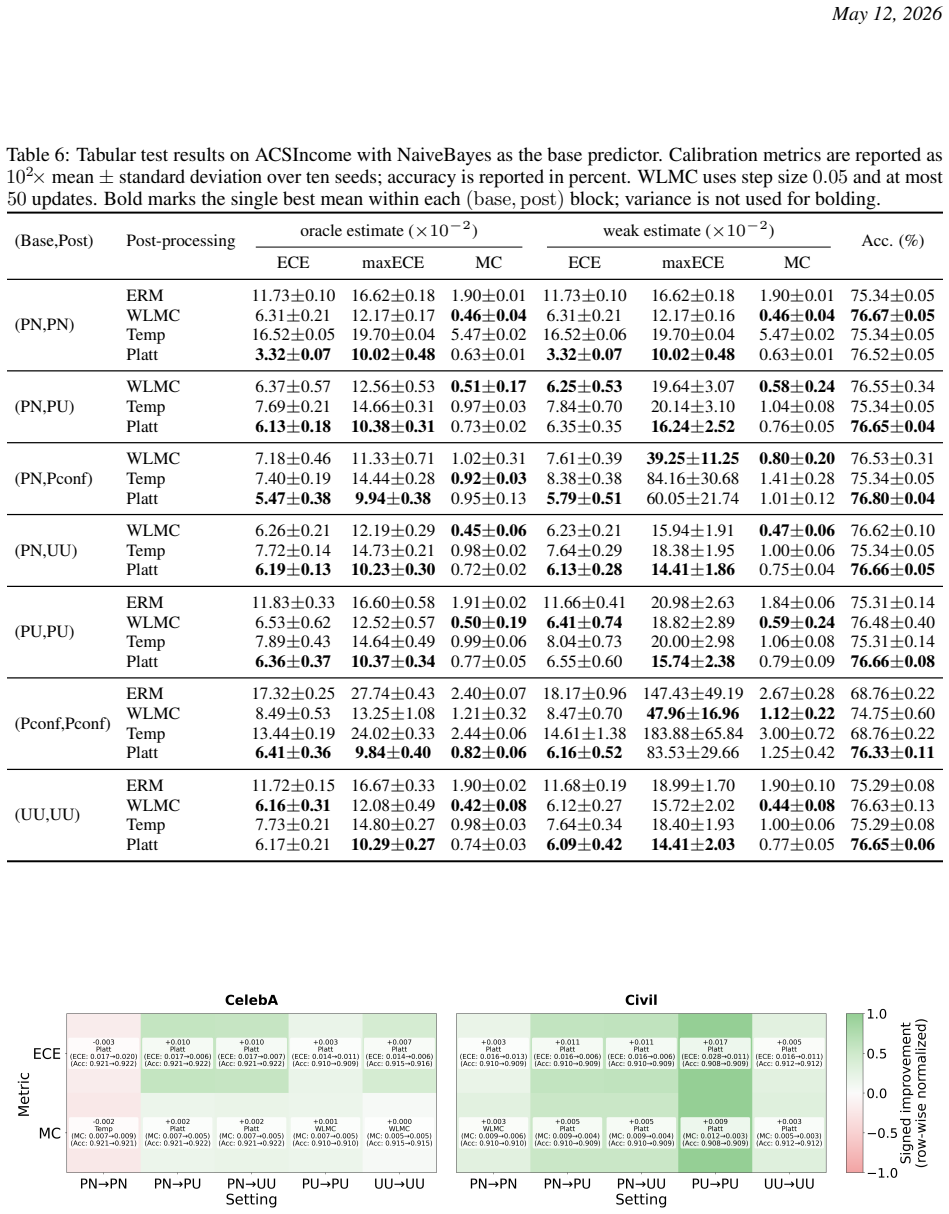

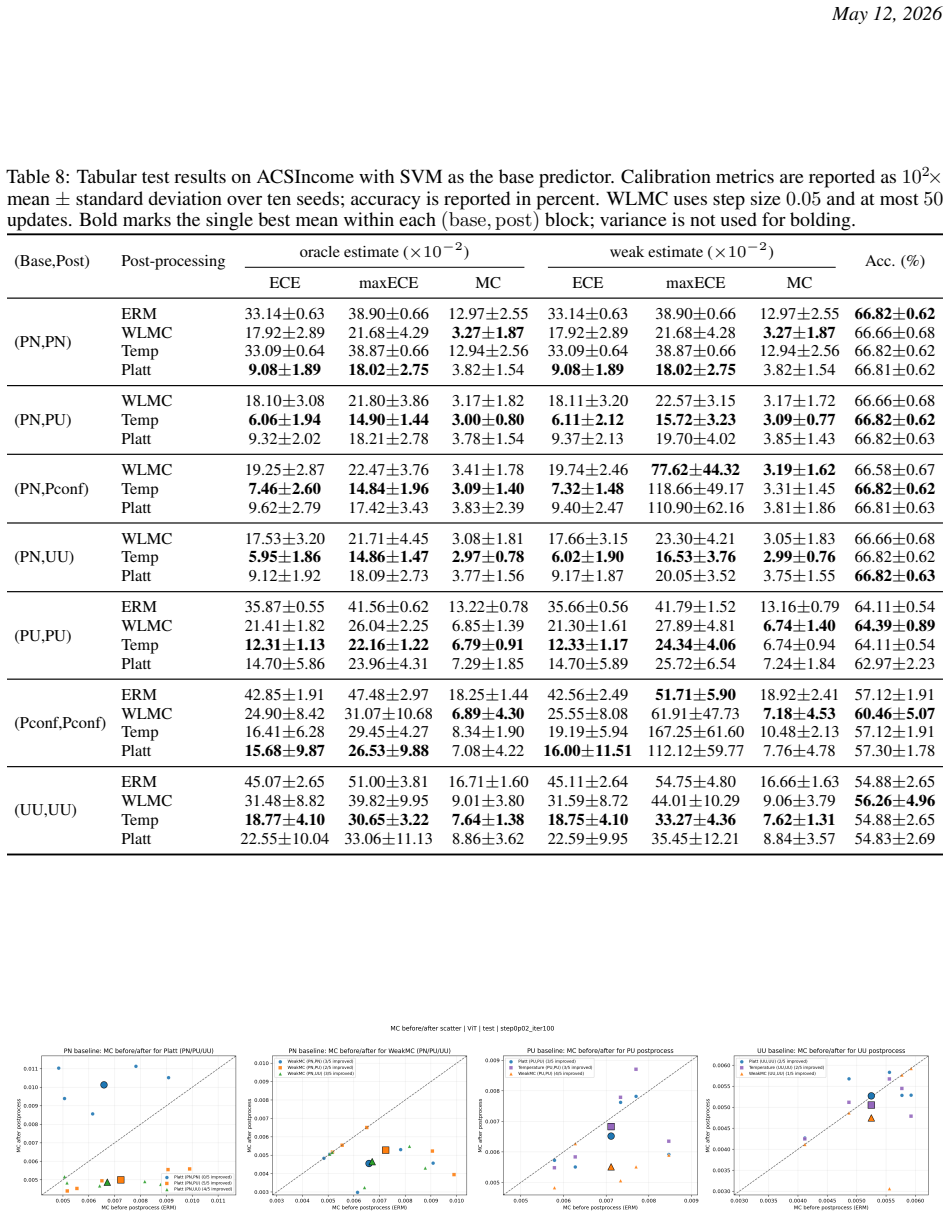
read the original abstract
Multicalibration requires predicted scores to agree with label probabilities across rich families of subgroups and score-dependent tests, but existing methods require clean input-label pairs for evaluation and post-processing. This assumption fails in weakly supervised learning (WSL) regimes -- including positive-unlabeled, unlabeled-unlabeled, and positive-confidence learning -- where clean labels are costly or unavailable even though reliable uncertainty estimates may be crucial. We address this gap by developing estimators of multicalibration error and post-hoc correction methods for WSL settings in which clean input-label pairs are unavailable. We propose a unified framework for estimating and correcting multicalibration under weak supervision by combining contamination-matrix risk rewrites with witness-based calibration constraints, yielding corrected multicalibration moments with finite-sample guarantees. We further propose weak-label multicalibration boost (WLMC), a generic post-hoc recalibration algorithm under weak supervision. Finally, we conduct experiments across multiple weak-supervision settings to evaluate multicalibration behavior and offer empirical insight into uncertainty estimation under weak supervision.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to develop a unified framework for estimating and correcting multicalibration error in weakly supervised learning (WSL) regimes such as positive-unlabeled, unlabeled-unlabeled, and positive-confidence learning. It combines contamination-matrix risk rewrites with witness-based calibration constraints to produce corrected multicalibration moments that enjoy finite-sample guarantees, introduces the WLMC (weak-label multicalibration boost) post-hoc recalibration algorithm, and reports experiments evaluating multicalibration behavior under weak supervision.
Significance. If the finite-sample guarantees hold under the paper's assumptions, the work would meaningfully extend multicalibration techniques to settings where clean labels are unavailable, enabling reliable uncertainty estimation in practically important WSL regimes. The empirical component provides useful insight into how multicalibration behaves when only weak labels are present.
major comments (2)
- [Abstract / unified framework] Abstract and central construction: the finite-sample guarantees on corrected multicalibration moments are asserted via the combination of contamination-matrix rewrites and witness constraints, but the skeptic's concern is load-bearing: the rewrite assumes the contamination rates are independent of group membership G. For rich subgroup families in multicalibration, subgroup-dependent noise (common in PU/UU settings) would bias the rewritten moments, invalidating the guarantees. The manuscript does not appear to provide per-subgroup contamination modeling or a robustness analysis.
- [WLMC algorithm description] WLMC algorithm and witness functions: the approach relies on the existence of suitable witness functions to enforce calibration constraints without clean labels. The weakest assumption (that such witnesses exist and can be estimated reliably from weak supervision) is not accompanied by explicit conditions or failure modes, which is necessary to support the claim that the corrected moments remain valid.
minor comments (2)
- Notation for the contamination matrix and witness functions could be clarified with an explicit table or diagram showing how the rewrite maps original to corrected moments.
- The experimental section would benefit from an ablation isolating the effect of the contamination rewrite versus the witness constraints.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each major comment point by point below, providing clarifications and indicating the revisions we will make.
read point-by-point responses
-
Referee: [Abstract / unified framework] Abstract and central construction: the finite-sample guarantees on corrected multicalibration moments are asserted via the combination of contamination-matrix rewrites and witness constraints, but the skeptic's concern is load-bearing: the rewrite assumes the contamination rates are independent of group membership G. For rich subgroup families in multicalibration, subgroup-dependent noise (common in PU/UU settings) would bias the rewritten moments, invalidating the guarantees. The manuscript does not appear to provide per-subgroup contamination modeling or a robustness analysis.
Authors: We agree that the contamination-matrix risk rewrites central to our framework assume contamination rates are independent of group membership G. This is a standard modeling choice in the weakly supervised learning literature (e.g., classic PU and UU settings), under which our finite-sample guarantees hold. We acknowledge that subgroup-dependent contamination, which can arise in some practical multicalibration scenarios with rich subgroup families, would introduce bias and invalidate the guarantees as stated. In the revised manuscript we will add an explicit discussion subsection on this assumption, its scope of validity, and directions for extension (including sensitivity analysis and more flexible per-subgroup contamination models). We will also note this limitation in the abstract and introduction to better delineate the claims. revision: partial
-
Referee: [WLMC algorithm description] WLMC algorithm and witness functions: the approach relies on the existence of suitable witness functions to enforce calibration constraints without clean labels. The weakest assumption (that such witnesses exist and can be estimated reliably from weak supervision) is not accompanied by explicit conditions or failure modes, which is necessary to support the claim that the corrected moments remain valid.
Authors: We thank the referee for highlighting this point. The witness-based calibration constraints are indeed foundational to enforcing the corrected moments without clean labels. In the revised manuscript we will augment the WLMC algorithm description and the theoretical sections with explicit conditions on the existence and reliable estimation of witness functions from weak supervision data. We will also include a discussion of failure modes (e.g., when weak labels provide insufficient signal for witness recovery) and their implications for the validity of the finite-sample guarantees. These additions will strengthen the supporting claims without altering the core algorithm. revision: yes
Circularity Check
No circularity: framework combines standard risk rewrites with independent constraints
full rationale
The paper develops estimators and a post-hoc algorithm (WLMC) by rewriting multicalibration risk via contamination matrices and enforcing witness-based constraints, then deriving finite-sample guarantees. These steps rely on established weak-supervision risk-rewrite techniques and calibration witnesses whose validity is not defined in terms of the target multicalibration moments. No self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided abstract or description; the central claims retain independent content from the combination of rewrites and constraints. The derivation is therefore self-contained against external benchmarks in the weak-supervision literature.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Weak supervision regimes can be represented using contamination matrices that relate observed labels to true labels
- domain assumption Witness functions can be chosen to enforce relevant multicalibration constraints under the weak supervision model
invented entities (1)
-
WLMC (weak-label multicalibration boost) algorithm
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J uniqueness) unclearWe propose a unified framework for estimating and correcting multicalibration under weak supervision by combining contamination-matrix risk rewrites with witness-based calibration constraints, yielding corrected multicalibration moments with finite-sample guarantees.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearTheorem 1 (Generic WSL rewrite for multicalibration)... R^{WSL}_{c,w}(f) := ∫ L_{c,w}(x;f)^T M^†_corr dP-bar(x)
Reference graph
Works this paper leans on
-
[1]
A unifying theory of distance from calibration
Błasiok, J., Gopalan, P., Hu, L., and Nakkiran, P. A unifying theory of distance from calibration. InProceedings of the 55th Annual ACM Symposium on Theory of Computing, pp. 1727–1740, 2023
work page 2023
-
[2]
Nuanced metrics for measuring unintended bias with real data for text classification
Borkan, D., Dixon, L., Sorensen, J., Thain, N., and Vasserman, L. Nuanced metrics for measuring unintended bias with real data for text classification. InCompanion proceedings of the 2019 world wide web conference, pp. 491–500, 2019. 9 May 12, 2026
work page 2019
-
[3]
Cauchois, M., Gupta, S., Ali, A., and Duchi, J. C. Predictive inference with weak supervision.Journal of Machine Learning Research, 25(118):1–45, 2024. URLhttp://jmlr.org/papers/v25/23-0253.html
work page 2024
-
[4]
Chiang, C.-K. and Sugiyama, M. Unified risk analysis for weakly supervised learning.Transactions on Machine Learning Research, 2025. ISSN 2835-8856. URLhttps://openreview.net/forum?id=RGsdAwWuu6. Survey Certification
work page 2025
-
[5]
F., Barocas, S., De Sa, C., and Sen, S
Cooper, A. F., Barocas, S., De Sa, C., and Sen, S. Variance, self-consistency, and arbitrariness in fair classification. arXiv preprint arXiv:2301.11562, pp. 1–84, 2023
-
[6]
Dawid, A. P. The well-calibrated Bayesian.Journal of the American Statistical Association, 77(379):605–610,
-
[7]
doi: 10.1080/01621459.1982.10477856
-
[8]
Ding, F., Hardt, M., Miller, J., and Schmidt, L. Retiring adult: New datasets for fair machine learning.Advances in neural information processing systems, 34:6478–6490, 2021
work page 2021
-
[9]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[10]
du Plessis, M. C., Niu, G., and Sugiyama, M. Analysis of learning from positive and unlabeled data. In Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N., and Weinberger, K. (eds.),Advances in Neural Information Processing Systems, volume 27. Curran Associates, Inc., 2014. URL https://proceedings.neurips.cc/paper_ files/paper/2014/file/f032bc3f1eb547f7...
work page 2014
-
[11]
Dwork, C., Kim, M. P., Reingold, O., Rothblum, G. N., and Yona, G. Outcome indistinguishability. InProceedings of the 53rd Annual ACM SIGACT Symposium on Theory of Computing, pp. 1095–1108, 2021
work page 2021
-
[12]
N., Gendler, A., and Romano, Y
Einbinder, B.-S., Feldman, S., Bates, S., Angelopoulos, A. N., Gendler, A., and Romano, Y . Label noise robustness of conformal prediction.Journal of Machine Learning Research, 25(328):1–66, 2024. URL http: //jmlr.org/papers/v25/23-1549.html
work page 2024
-
[13]
Foster, D. P. and V ohra, R. V . Asymptotic calibration.Biometrika, 85(2):379–390, 1998
work page 1998
-
[14]
Futami, F. and Fujisawa, M. Information-theoretic generalization analysis for expected calibration error. In Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., and Zhang, C. (eds.),Advances in Neural Information Processing Systems, volume 37, pp. 84246–84297. Curran Associates, Inc., 2024
work page 2024
-
[15]
Futami, F. and Nitanda, A. Smooth calibration error: Uniform convergence and functional gradient analysis. In The Fourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum?id=qXVmmj8J0T
work page 2026
-
[16]
Multicalibration as boosting for regression
Globus-Harris, I., Harrison, D., Kearns, M., Roth, A., and Sorrell, J. Multicalibration as boosting for regression. In Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., and Scarlett, J. (eds.),Proceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pp. 11459–11492. PMLR, 23...
work page 2023
-
[17]
Gopalan, P., Kim, M. P., Singhal, M. A., and Zhao, S. Low-degree multicalibration. InConference on Learning Theory, pp. 3193–3234. PMLR, 2022
work page 2022
-
[18]
Gopalan, P., Hu, L., and Rothblum, G. N. On computationally efficient multi-class calibration. InThe Thirty Seventh Annual Conference on Learning Theory, pp. 1983–2026. PMLR, 2024
work page 1983
-
[19]
Guo, C., Pleiss, G., Sun, Y ., and Weinberger, K. Q. On calibration of modern neural networks. InInternational conference on machine learning, pp. 1321–1330, 2017
work page 2017
-
[20]
Gupta, C., Podkopaev, A., and Ramdas, A. Distribution-free binary classification: prediction sets, confidence intervals and calibration.Advances in Neural Information Processing Systems, 33:3711–3723, 2020
work page 2020
-
[21]
Hansen, D., Devic, S., Nakkiran, P., and Sharan, V . When is multicalibration post-processing necessary?Advances in Neural Information Processing Systems, 37:38383–38455, 2024
work page 2024
-
[22]
Deep residual learning for image recognition
He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016
work page 2016
-
[23]
Multicalibration: Calibration for the (Computationally-identifiable) masses
Hebert-Johnson, U., Kim, M., Reingold, O., and Rothblum, G. Multicalibration: Calibration for the (Computationally-identifiable) masses. In Dy, J. and Krause, A. (eds.),Proceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pp. 1939–1948. PMLR, 10–15 Jul 2018
work page 1939
-
[24]
Testing calibration in nearly-linear time
Hu, L., Jambulapati, A., Tian, K., and Yang, C. Testing calibration in nearly-linear time. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. 10 May 12, 2026
work page 2024
-
[25]
Binary classification from positive-confidence data
Ishida, T., Niu, G., and Sugiyama, M. Binary classification from positive-confidence data. In Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., and Garnett, R. (eds.),Advances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018. URL https://proceedings.neurips. cc/paper_files/paper/2018/file/bd1354624fb...
work page 2018
-
[26]
Kearns, M., Neel, S., Roth, A., and Wu, Z. S. Preventing fairness gerrymandering: Auditing and learning for subgroup fairness. In Dy, J. and Krause, A. (eds.),Proceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pp. 2564–2572. PMLR, 10–15 Jul 2018. URLhttps://proceedings.mlr.press/v80/...
work page 2018
-
[27]
Kim, M. P., Ghorbani, A., and Zou, J. Multiaccuracy: Black-box post-processing for fairness in classification. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, pp. 247–254, 2019
work page 2019
-
[28]
Kiryo, R., Niu, G., du Plessis, M. C., and Sugiyama, M. Positive-unlabeled learning with non-negative risk estimator. In Guyon, I., Luxburg, U. V ., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., and Garnett, R. (eds.),Advances in Neural Information Processing Systems, volume 30. Curran Asso- ciates, Inc., 2017. URL https://proceedings.neurips.cc/...
work page 2017
-
[29]
Estimating expected calibration error for positive-unlabeled learning
Kiryo, R., Futami, F., and Sugiyama, M. Estimating expected calibration error for positive-unlabeled learning. Transactions on Machine Learning Research, 2026. ISSN 2835-8856. URL https://openreview.net/ forum?id=SvoBtLIrPZ
work page 2026
-
[30]
Deep learning face attributes in the wild
Liu, Z., Luo, P., Wang, X., and Tang, X. Deep learning face attributes in the wild. InProceedings of the IEEE international conference on computer vision, pp. 3730–3738, 2015
work page 2015
-
[31]
Lu, N., Niu, G., Menon, A. K., and Sugiyama, M. On the minimal supervision for training any binary classifier from only unlabeled data. InInternational Conference on Learning Representations, 2019. URL https: //openreview.net/forum?id=B1xWcj0qYm
work page 2019
-
[32]
Binary classification from multiple unlabeled datasets via surrogate set classification
Lu, N., Lei, S., Niu, G., Sato, I., and Sugiyama, M. Binary classification from multiple unlabeled datasets via surrogate set classification. In Meila, M. and Zhang, T. (eds.),Proceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pp. 7134–7144. PMLR, 18–24 Jul 2021. URLhttps://proceedi...
work page 2021
-
[33]
Calibration by distribution matching: Trainable kernel calibration metrics
Marx, C., Zalouk, S., and Ermon, S. Calibration by distribution matching: Trainable kernel calibration metrics. Advances in Neural Information Processing Systems, 36:25910–25928, 2023
work page 2023
-
[34]
Platt, J. et al. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. Advances in large margin classifiers, 10(3):61–74, 1999
work page 1999
-
[35]
Plessis, M. D., Niu, G., and Sugiyama, M. Convex formulation for learning from positive and unlabeled data. In Bach, F. and Blei, D. (eds.),Proceedings of the 32nd International Conference on Machine Learning, volume 37 ofProceedings of Machine Learning Research, pp. 1386–1394, Lille, France, 07–09 Jul 2015. PMLR. URL https://proceedings.mlr.press/v37/ple...
work page 2015
-
[36]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Sanh, V ., Debut, L., Chaumond, J., and Wolf, T. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter.arXiv preprint arXiv:1910.01108, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[37]
H., Paydarfar, D., and Ghosh, J
Sharma, S., Gee, A. H., Paydarfar, D., and Ghosh, J. Fair-n: Fair and robust neural networks for structured data. InProceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society, pp. 946–955, 2021
work page 2021
-
[38]
Calibration tests beyond classification
Widmann, D., Lindsten, F., and Zachariah, D. Calibration tests beyond classification. InInternational Conference on Learning Representations, 2021
work page 2021
-
[39]
Yeh, I.-C. Default of Credit Card Clients. UCI Machine Learning Repository, 2009. DOI: https://doi.org/10.24432/C55S3H. 11 May 12, 2026 A Proofs for the generic rewrite statements A.1 Review of the risk rewrite Starting from Eq. (5), write Rℓ(f) = Z X Lℓ(x;f) ⊤ dB(x). Substituting the decontamination identityB=M † corr ¯Pfrom Eq. (6) gives Rℓ(f) = Z X Lℓ(...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.