Recognition: no theorem link
When to Re-Commit: Temporal Abstraction Discovery for Long-Horizon Vision-Language Reasoning
Pith reviewed 2026-05-12 04:53 UTC · model grok-4.3
The pith
Vision-language policies that learn a state-dependent commitment depth solve more long-horizon puzzles with fewer actions than any fixed depth.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
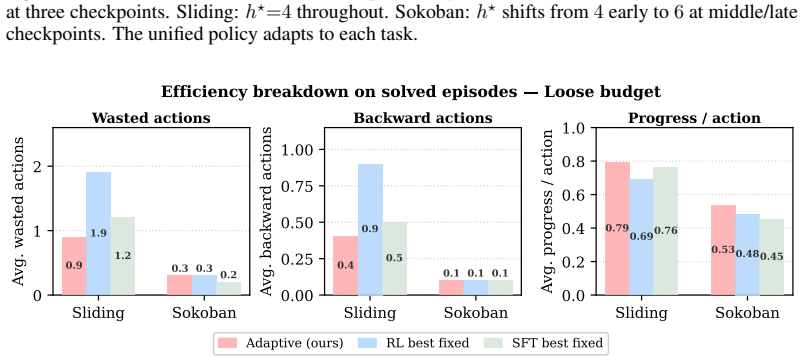
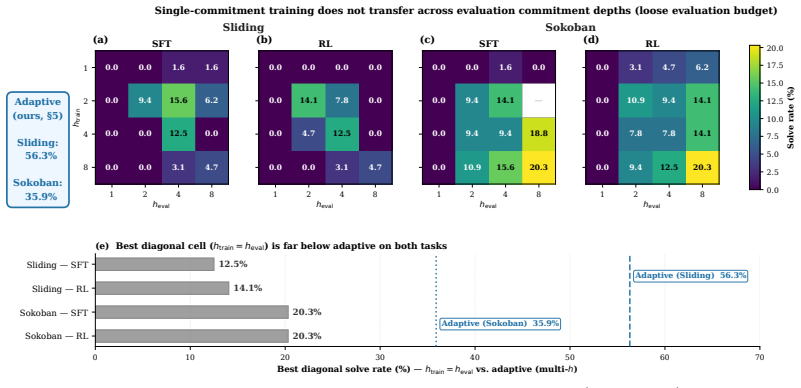
The central claim is that a model-native vision-language policy jointly predicting actions and state-conditioned commitment depth Pareto-dominates every non-degenerate fixed-depth baseline across Sliding Puzzle and Sokoban, delivering up to 12.5 percentage points higher solve rate with roughly 25 percent fewer primitive actions per episode, while a 7B model already exceeds GPT-5.5 and Claude Sonnet and every tested open-weight vision-language model scores zero zero-shot success; the theory further shows state-conditioned commitment strictly dominates fixed depth whenever locally optimal depths vary by state.
What carries the argument
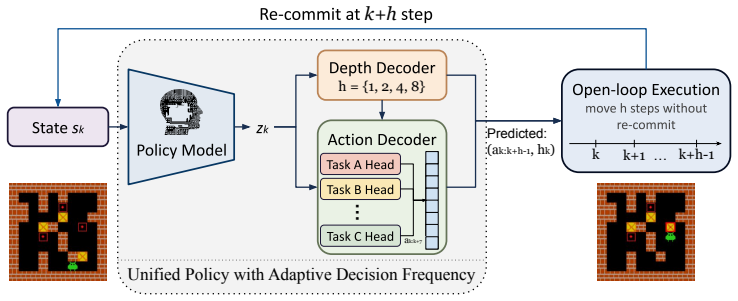
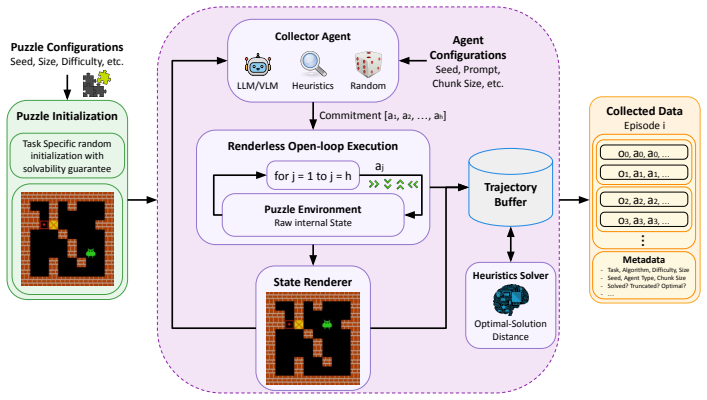
Commitment depth, defined as the number of primitive actions executed open-loop between replans and treated as a learnable state-conditioned variable output by the policy together with the action sequence.
Load-bearing premise
The vision-language policy can reliably predict a useful commitment depth from visual state alone and the standard surrogate for execution cost and error accumulation used in the analysis matches real performance.
What would settle it
Running the identical Sliding Puzzle and Sokoban evaluations with the learned policy forced to use a single fixed depth equal to the average of its own predicted depths and finding no drop in solve rate or increase in actions.
Figures






read the original abstract
Long-horizon reasoning requires deciding not only what actions to take, but how deeply to commit before the next observation. We formalize this as \emph{commitment depth}: the number of primitive actions executed open-loop between replans. Commitment depth induces a trade-off between replanning cost and compounding execution error, yet most existing long-horizon systems fix it as a hand-designed scalar. In this work, we instead treat commitment depth as a learnable, state-conditioned variable of the policy itself. We instantiate this within a model-native vision--language policy that jointly predicts both what to execute and for how long. Across Sliding Puzzle and Sokoban, the resulting adaptive policy Pareto-dominates every non-degenerate fixed-depth baseline, achieving up to 12.5 percentage points higher solve rate while using approximately 25\% fewer primitive actions per episode. Despite using a 7B backbone, our method outperforms GPT-5.5 and Claude Sonnet on both tasks, while every tested open-weight vision--language model achieves 0\% zero-shot success. We further present a theoretical analysis showing that, under the standard commitment-depth surrogate, state-conditioned commitment strictly dominates any fixed depth whenever the locally optimal depth varies across states.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes learning state-conditioned commitment depths as part of a vision-language policy for long-horizon tasks such as Sliding Puzzle and Sokoban. The adaptive policy is claimed to Pareto-dominate fixed-depth baselines, achieving up to 12.5 percentage points higher solve rates and approximately 25% fewer primitive actions per episode, while also outperforming GPT-5.5 and Claude Sonnet despite using a 7B backbone. A theoretical analysis shows that state-conditioned commitment strictly dominates any fixed depth under the standard surrogate when locally optimal depths vary across states.
Significance. The approach of making temporal abstraction learnable within the policy could have significant implications for efficient long-horizon vision-language reasoning if the results hold. The empirical Pareto dominance on two standard domains and the theoretical dominance argument are notable strengths. However, the absence of error bars, training details, and specific ablations in the provided claims reduces the immediate impact.
major comments (3)
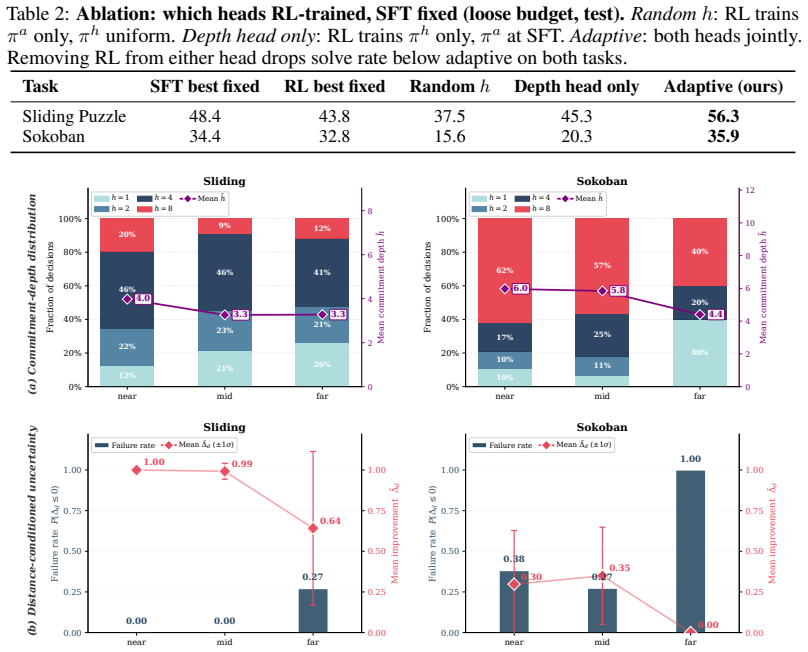
- [Empirical Evaluation] The central empirical claim of Pareto dominance and performance gains (12.5 pp solve rate, 25% fewer actions) lacks an ablation study that fixes the commitment depth prediction while retaining the joint policy training. Without this, it is unclear whether the improvements stem from adaptive depths or from the joint optimization of the prediction head itself.
- [Theoretical Analysis] The strict dominance result is derived from the standard commitment-depth surrogate cost model. However, no empirical validation is provided showing that this surrogate accurately captures the real execution costs and error accumulation in the Sliding Puzzle and Sokoban environments.
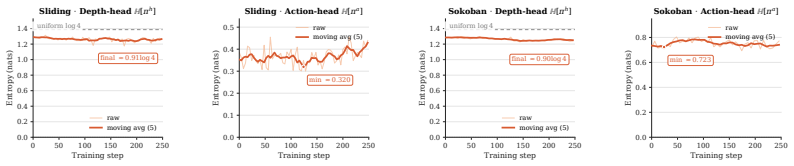
- [Results] No information is given on the distribution of predicted commitment depths across states or per-state comparisons to locally optimal depths. This is necessary to confirm that the policy learns meaningful state-varying commitments rather than a near-constant depth.
minor comments (2)
- [Abstract] The abstract states that every tested open-weight vision-language model achieves 0% zero-shot success, but does not specify which models were evaluated or the exact zero-shot setup.
- [Abstract] Training details, hyperparameters, and error bars for the reported solve rates and action counts are not mentioned, which would aid in assessing the reliability of the 12.5 pp and 25% figures.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and outline revisions that will strengthen the manuscript.
read point-by-point responses
-
Referee: [Empirical Evaluation] The central empirical claim of Pareto dominance and performance gains (12.5 pp solve rate, 25% fewer actions) lacks an ablation study that fixes the commitment depth prediction while retaining the joint policy training. Without this, it is unclear whether the improvements stem from adaptive depths or from the joint optimization of the prediction head itself.
Authors: We agree that isolating the contribution of state-conditioned depths from joint training is important. In the revised manuscript we will add an ablation that trains the full model jointly but then freezes the commitment-depth head to output a constant value (the mean depth observed during training) at evaluation time. This will be compared directly against the adaptive policy on the same backbone and training regime to quantify the benefit attributable to adaptivity. revision: yes
-
Referee: [Theoretical Analysis] The strict dominance result is derived from the standard commitment-depth surrogate cost model. However, no empirical validation is provided showing that this surrogate accurately captures the real execution costs and error accumulation in the Sliding Puzzle and Sokoban environments.
Authors: The theoretical claim is stated under the standard surrogate used throughout the temporal-abstraction literature. To address the request for validation, the revision will include a new subsection that correlates predicted commitment depths with measured per-step error rates and replanning frequency observed in our rollouts, thereby providing empirical grounding for the surrogate within the evaluated domains. revision: yes
-
Referee: [Results] No information is given on the distribution of predicted commitment depths across states or per-state comparisons to locally optimal depths. This is necessary to confirm that the policy learns meaningful state-varying commitments rather than a near-constant depth.
Authors: We concur that such diagnostics are needed to demonstrate that the policy exploits state variation. The revised manuscript will add a figure showing the histogram of predicted depths over held-out states for both environments, together with per-state comparisons to locally optimal depths (computed via breadth-first search on solvable small instances) to confirm that the learned policy deviates meaningfully from any fixed depth. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The paper's central theoretical result states that state-conditioned commitment strictly dominates fixed depth under the standard commitment-depth surrogate whenever locally optimal depth varies across states. This is presented as a general mathematical property of the surrogate cost model rather than a quantity fitted or defined inside the paper. Empirical claims compare the learned policy against external fixed-depth baselines and other VLMs without reducing reported gains to any self-defined parameter or self-citation chain. No self-definitional loops, fitted inputs renamed as predictions, or ansatzes imported via author-overlapping citations are exhibited in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The commitment-depth surrogate (replanning cost plus compounding execution error) is a faithful proxy for true task performance.
invented entities (1)
-
state-conditioned commitment depth
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Wisdom C Agboh and Mehmet R Dogar. Robust physics-based manipulation by interleaving open and closed-loop execution.arXiv preprint arXiv:2105.08325, 2021
-
[2]
Hindsight experience replay.Advances in neural information processing systems, 30, 2017
Marcin Andrychowicz, Filip Wolski, Alex Ray, Jonas Schneider, Rachel Fong, Peter Welinder, Bob McGrew, Josh Tobin, OpenAI Pieter Abbeel, and Wojciech Zaremba. Hindsight experience replay.Advances in neural information processing systems, 30, 2017
work page 2017
-
[3]
Jason Ansel, Edward Yang, Horace He, Natalia Gimelshein, Animesh Jain, Michael V oznesen- sky, Bin Bao, Peter Bell, David Berard, Evgeni Burovski, Geeta Chauhan, Anjali Chourdia, Will Constable, Alban Desmaison, Zachary DeVito, Elias Ellison, Will Feng, Jiong Gong, Michael Gschwind, Brian Hirsh, Sherlock Huang, Kshiteej Kalambarkar, Laurent Kirsch, Michae...
-
[4]
The claude 3 model family: Opus, sonnet, haiku, 2025
Anthropic. The claude 3 model family: Opus, sonnet, haiku, 2025. URL https://api. semanticscholar.org/CorpusID:268232499
work page 2025
-
[5]
The option-critic architecture
Pierre-Luc Bacon, Jean Harb, and Doina Precup. The option-critic architecture. InProceedings of the AAAI conference on artificial intelligence, volume 31, 2017
work page 2017
-
[6]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report,
-
[8]
URLhttps://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Abhinav Bhatia, Philip S Thomas, and Shlomo Zilberstein. Adaptive rollout length for model- based rl using model-free deep rl.arXiv preprint arXiv:2206.02380, 2022
-
[10]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
work page 2025
-
[11]
On the Measure of Intelligence
François Chollet. On the measure of intelligence.arXiv preprint arXiv:1911.01547, 2019
work page internal anchor Pith review arXiv 1911
-
[12]
Arc prize 2024: Technical report
Francois Chollet, Mike Knoop, Gregory Kamradt, and Bryan Landers. Arc prize 2024: Technical report.arXiv preprint arXiv:2412.04604, 2024
-
[13]
Arc prize 2025: Technical report, 2026
François Chollet, Mike Knoop, Gregory Kamradt, and Bryan Landers. Arc prize 2025: Technical report, 2026. URLhttps://arxiv.org/abs/2601.10904
-
[14]
Thomas G Dietterich. Hierarchical reinforcement learning with the maxq value function decomposition.Journal of artificial intelligence research, 13:227–303, 2000. 10
work page 2000
-
[15]
Learning and executing generalized robot plans.Artificial intelligence, 3:251–288, 1972
Richard E Fikes, Peter E Hart, and Nils J Nilsson. Learning and executing generalized robot plans.Artificial intelligence, 3:251–288, 1972
work page 1972
-
[16]
ARC-AGI-3: A New Challenge for Frontier Agentic Intelligence
ARC Foundation. Arc-agi-3: A new challenge for frontier agentic intelligence.arXiv preprint arXiv:2603.24621, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Thinkmorph: Emergent properties in multimodal interleaved chain-of-thought reasoning
Jiawei Gu, Yunzhuo Hao, Huichen Will Wang, Linjie Li, Michael Qizhe Shieh, Yejin Choi, Ranjay Krishna, and Yu Cheng. Thinkmorph: Emergent properties in multimodal interleaved chain-of-thought reasoning, 2026. URLhttps://arxiv.org/abs/2510.27492
-
[18]
Human-like planning for reaching in cluttered environments
Mohamed Hasan, Matthew Warburton, Wisdom C Agboh, Mehmet R Dogar, Matteo Leonetti, He Wang, Faisal Mushtaq, Mark Mon-Williams, and Anthony G Cohn. Human-like planning for reaching in cluttered environments. In2020 IEEE International Conference on Robotics and Automation (ICRA), pages 7784–7790. IEEE, 2020
work page 2020
-
[19]
Milos Hauskrecht, Nicolas Meuleau, Leslie Pack Kaelbling, Thomas L Dean, and Craig Boutilier. Hierarchical solution of markov decision processes using macro-actions.arXiv preprint arXiv:1301.7381, 2013
-
[20]
Kohei Honda, Ryo Yonetani, Mai Nishimura, and Tadashi Kozuno. When to replan? an adaptive replanning strategy for autonomous navigation using deep reinforcement learning. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6650–6656. IEEE, 2024
work page 2024
-
[21]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
work page 2022
-
[22]
Visual sketchpad: Sketching as a visual chain of thought for multimodal language models, 2024
Yushi Hu, Weijia Shi, Xingyu Fu, Dan Roth, Mari Ostendorf, Luke Zettlemoyer, Noah A Smith, and Ranjay Krishna. Visual sketchpad: Sketching as a visual chain of thought for multimodal language models, 2024. URLhttps://arxiv.org/abs/2406.09403
-
[23]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsc...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Mixture of horizons in action chunking.arXiv preprint arXiv:2511.19433, 2025
Dong Jing, Gang Wang, Jiaqi Liu, Weiliang Tang, Zelong Sun, Yunchao Yao, Zhenyu Wei, Yunhui Liu, Zhiwu Lu, and Mingyu Ding. Mixture of horizons in action chunking, 2025. URL https://arxiv.org/abs/2511.19433
-
[25]
Randomized preprocessing of configuration for fast path plan- ning
Lydia Kavraki and J-C Latombe. Randomized preprocessing of configuration for fast path plan- ning. InProceedings of the 1994 IEEE International Conference on Robotics and Automation, pages 2138–2145. IEEE, 1994
work page 1994
-
[26]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Visualwebarena: Evaluating multimodal agents on realistic visual web tasks
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Russ Salakhutdinov, and Daniel Fried. Visualwebarena: Evaluating multimodal agents on realistic visual web tasks. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 881–905, 2024
work page 2024
-
[28]
Da Kong and Vadim Indelman. Open-loop pomdp simplification and safe skipping of replanning with formal performance guarantees.arXiv preprint arXiv:2604.01352, 2026
-
[29]
Macro-operators: A weak method for learning.Artificial intelligence, 26(1): 35–77, 1985
Richard E Korf. Macro-operators: A weak method for learning.Artificial intelligence, 26(1): 35–77, 1985. 11
work page 1985
-
[30]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large lan- guage model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
work page 2023
-
[31]
Rapidly-exploring random trees: Progress and prospects: Steven m
Steven M LaValle and James J Kuffner. Rapidly-exploring random trees: Progress and prospects: Steven m. lavalle, iowa state university, a james j. kuffner, jr., university of tokyo, tokyo, japan. Algorithmic and computational robotics, pages 303–307, 2001
work page 2001
-
[32]
Erwan Lecarpentier, Guillaume Infantes, Charles Lesire, and Emmanuel Rachelson. Open loop execution of tree-search algorithms, extended version.arXiv preprint arXiv:1805.01367, 2018
-
[33]
Adaptive Action Chunking at Inference-time for Vision-Language-Action Models
Yuanchang Liang, Xiaobo Wang, Kai Wang, Shuo Wang, Xiaojiang Peng, Haoyu Chen, David Kim Huat Chua, and Prahlad Vadakkepat. Adaptive action chunking at inference-time for vision-language-action models.arXiv preprint arXiv:2604.04161, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Visual agentic reinforcement fine-tuning
Ziyu Liu, Yuhang Zang, Yushan Zou, Zijian Liang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, and Jiaqi Wang. Visual agentic reinforcement fine-tuning, 2025. URL https://arxiv.org/abs/2505.14246
-
[35]
Constrained model predictive control: Stability and optimality.Automatica, 36(6):789–814, 2000
David Q Mayne, James B Rawlings, Christopher V Rao, and Pierre OM Scokaert. Constrained model predictive control: Stability and optimality.Automatica, 36(6):789–814, 2000
work page 2000
-
[36]
OpenAI. Thinking with images, 2025. URL https://openai.com/index/ thinking-with-images/
work page 2025
-
[37]
Efficient reductions for imitation learning
Stéphane Ross and Drew Bagnell. Efficient reductions for imitation learning. InProceedings of the thirteenth international conference on artificial intelligence and statistics, pages 661–668. JMLR Workshop and Conference Proceedings, 2010
work page 2010
-
[38]
A reduction of imitation learning and structured prediction to no-regret online learning
Stéphane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the fourteenth interna- tional conference on artificial intelligence and statistics, pages 627–635. JMLR Workshop and Conference Proceedings, 2011
work page 2011
- [39]
-
[40]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Sahil Sharma, Aravind Srinivas, and Balaraman Ravindran. Learning to repeat: Fine grained action repetition for deep reinforcement learning.arXiv preprint arXiv:1702.06054, 2017
-
[42]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, Akshay Nathan, Alan Luo, Alec Helyar, Aleksander Madry, Aleksandr Efremov, Aleksandra Spyra, Alex Baker-Whitcomb, Alex Beutel, Alex Karpenko, Alex Makelov, Alex Neitz, Alex Wei, Alexandra Barr, Alexandre Kirchmeyer, Ale...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
Dynamic frame skip deep q network
Aravind Srinivas, Sahil Sharma, and Balaraman Ravindran. Dynamic frame skip deep q network. arXiv preprint arXiv:1605.05365, 2016
-
[44]
Zhaochen Su, Peng Xia, Hangyu Guo, Zhenhua Liu, Yan Ma, Xiaoye Qu, Jiaqi Liu, Yanshu Li, Kaide Zeng, Zhengyuan Yang, Linjie Li, Yu Cheng, Heng Ji, Junxian He, and Yi R. Fung. Thinking with images for multimodal reasoning: Foundations, methods, and future frontiers,
-
[45]
URLhttps://arxiv.org/abs/2506.23918
work page internal anchor Pith review arXiv
-
[46]
Richard S Sutton, Doina Precup, and Satinder Singh. Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning.Artificial intelligence, 112(1-2): 181–211, 1999
work page 1999
-
[47]
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M. Dai, Anja Hauth, Katie Millican, David Silver, Melvin Johnson, Ioannis Antonoglou, Julian Schrittwieser, Amelia Glaese, Jilin Chen, Emily Pitler, Timothy Lillicrap, Angeliki Lazaridou, Orhan Firat, James Molloy, Michael Isard, Paul R. Ba...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Feudal networks for hierarchical reinforcement learning
Alexander Sasha Vezhnevets, Simon Osindero, Tom Schaul, Nicolas Heess, Max Jaderberg, David Silver, and Koray Kavukcuoglu. Feudal networks for hierarchical reinforcement learning. InInternational conference on machine learning, pages 3540–3549. PMLR, 2017
work page 2017
-
[49]
TRL: Transformers Rein- forcement Learning, 2020
Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tristan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Quentin Gallouédec. TRL: Transformers Rein- forcement Learning, 2020. URLhttps://github.com/huggingface/trl
work page 2020
-
[50]
Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning
Haozhe Wang, Alex Su, Weiming Ren, Fangzhen Lin, and Wenhu Chen. Pixel reasoner: Incentivizing pixel-space reasoning with curiosity-driven reinforcement learning, 2025. URL https://arxiv.org/abs/2505.15966
work page internal anchor Pith review arXiv 2025
-
[51]
Chenjun Xiao, Yifan Wu, Chen Ma, Dale Schuurmans, and Martin Müller. Learning to combat compounding-error in model-based reinforcement learning.arXiv preprint arXiv:1912.11206, 2019
-
[52]
Visual planning: Let’s think only with images, 2026
Yi Xu, Chengzu Li, Han Zhou, Xingchen Wan, Caiqi Zhang, Anna Korhonen, and Ivan Vuli´c. Visual planning: Let’s think only with images, 2026. URL https://arxiv.org/abs/2505. 11409
work page 2026
-
[53]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
work page 2024
-
[54]
Ruihan Yang, Fanghua Ye, Xiang We, Ruoqing Zhao, Kang Luo, Xinbo Xu, Bo Zhao, Ruotian Ma, Shanyi Wang, Zhaopeng Tu, et al. Think fast and slow: Step-level cognitive depth adaptation for llm agents.arXiv preprint arXiv:2602.12662, 2026
-
[55]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[56]
arXiv preprint arXiv:2510.24514 , year=
Huanyu Zhang, Wenshan Wu, Chengzu Li, Ning Shang, Yan Xia, Yangyu Huang, Yifan Zhang, Li Dong, Zhang Zhang, Liang Wang, Tieniu Tan, and Furu Wei. Latent sketchpad: Sketching visual thoughts to elicit multimodal reasoning in mllms, 2025. URL https://arxiv.org/ abs/2510.24514
-
[57]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[58]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
Ziwei Zheng, Michael Yang, Jack Hong, Chenxiao Zhao, Guohai Xu, Le Yang, Chao Shen, and Xing Yu. Deepeyes: Incentivizing "thinking with images" via reinforcement learning, 2026. URLhttps://arxiv.org/abs/2505.14362
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[59]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, Zhangwei Gao, Erfei Cui, Xuehui Wang, Yue Cao, Yangzhou Liu, Xingguang Wei, Hongjie Zhang, Haomin Wang, Weiye Xu, Hao Li, Jiahao Wang, Nianchen Deng, Songze Li, Yinan He, Tan Jiang, Jiapeng Luo, Yi Wang, Conghui He, Botian Shi, Xingcheng Zh...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
For Lemma 1, the existence of an interior optimum requires only that q(h)/h→0 as h→0 + and q(h)→1 as h grows; the precise functional form determines the location of h⋆ but not its existence
-
[61]
For Prop. 1, strict dominance requires only that the per-state optimum h⋆(s) be a non- constant function of state; this is a structural property of the state-dependent error landscape, not of any specific functional form. Power-law is the cleanest stylization in which to make these arguments precise. Why we do not estimate (c, α) empirically.The power-law...
work page 2022
-
[62]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.