Recognition: 2 theorem links
· Lean TheoremUFO: A Unified Flow-Oriented Framework for Robust Continual Graph Learning
Pith reviewed 2026-05-12 05:08 UTC · model grok-4.3
The pith
A flow-based generative model produces synthetic replays of past graph tasks while reliability scores filter noisy labels, letting models learn from evolving graphs without storing data or reinforcing errors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
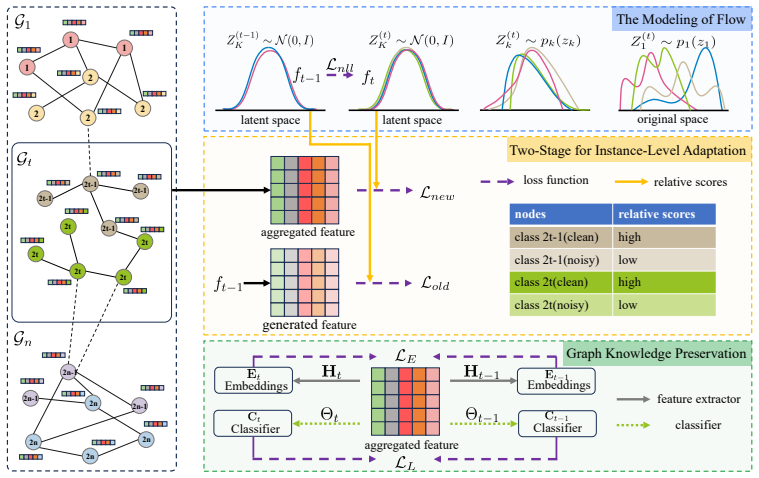
UFO models conditional feature distributions via flow-based generative modeling to produce replay representations that mitigate catastrophic forgetting without storing historical data, and simultaneously estimates instance-level reliability scores to distinguish clean from noisy nodes, thereby reducing the impact of corrupted supervision and alleviating catastrophic remembering.
What carries the argument
The UFO framework, which combines flow-based generative modeling to synthesize replay features from conditional distributions with instance-level reliability scoring to separate clean and noisy nodes.
If this is right
- Continual graph models can maintain high accuracy across sequential tasks without retaining raw historical graph data.
- The effect of label noise on performance is reduced because unreliable nodes are down-weighted during each task update.
- Catastrophic remembering is avoided because noisy instances do not persistently reinforce incorrect patterns across tasks.
- The same framework can be applied under varying noise ratios while still outperforming prior methods on standard graph benchmarks.
Where Pith is reading between the lines
- The same flow-plus-reliability pattern might transfer to continual learning on non-graph data such as images or sequences if the generative model can capture their feature distributions.
- If reliability scoring proves stable, it could reduce the cost of manually cleaning labels in production systems that ingest streaming graph data.
- Extending the approach to dynamic graphs with changing topology rather than only feature noise would test whether the flow component still suffices.
- Replacing the flow model with other conditional generators such as diffusion models could yield comparable replay quality with different computational trade-offs.
Load-bearing premise
Flow models trained on current data can generate replay features faithful enough to past tasks, and reliability scores computed without ground-truth labels can correctly separate clean nodes from noisy ones.
What would settle it
Running the four benchmark graph datasets with the reported noise ratios and finding that UFO shows no gains in accuracy or forgetting metrics over existing continual graph methods, or that its generated replays degrade performance relative to no-replay baselines.
Figures








read the original abstract
Graph learning research has increasingly shifted toward continual graph learning (CGL), which better reflects real-world scenarios where graphs evolve over time. However, existing CGL methods largely assume clean supervision and overlook a critical challenge: the newly arriving portions of the graph are often noisy, due to annotation errors or adversarial corruption. This mismatch limits their applicability in practice. In this work, we study robust continual graph learning, where models must simultaneously handle catastrophic forgetting and noisy supervision in evolving graph data. We show that label noise introduces a new failure mode, catastrophic remembering, where models persistently reinforce corrupted knowledge across tasks. To address these challenges, we propose a Unified Flow-Oriented framework (UFO). First, UFO models conditional feature distributions via flow-based generative modeling and produces replay representations, mitigating forgetting without storing historical data. Second, UFO estimates instance-level reliability scores to distinguish clean from noisy nodes, reducing the impact of corrupted supervision and alleviating catastrophic remembering. Extensive experiments on four benchmark graph datasets under varying noise ratios demonstrate that UFO consistently outperforms existing methods in both accuracy and forgetting metrics. Code is available at: https://anonymous.4open.science/r/UFO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes UFO, a Unified Flow-Oriented framework for robust continual graph learning on evolving graphs. It employs flow-based generative modeling to produce replay representations that mitigate catastrophic forgetting without storing historical data, and estimates instance-level reliability scores to distinguish clean from noisy nodes, thereby reducing the impact of label noise and alleviating 'catastrophic remembering.' The authors report that extensive experiments on four benchmark graph datasets under varying noise ratios show consistent outperformance over existing methods in both accuracy and forgetting metrics.
Significance. If the core mechanisms are validated, this would represent a meaningful advance in continual graph learning by jointly addressing forgetting and robustness to noisy supervision in a memory-efficient manner. The flow-based replay approach is a notable strength, offering a generative alternative to exemplar storage, and the unified handling of noise-induced remembering could have practical implications for real-world graph streams. The availability of code supports reproducibility.
major comments (2)
- [§3.2] §3.2 (Instance-level Reliability Scoring): The central robustness claim rests on the reliability scores successfully separating clean from noisy nodes without ground-truth labels. However, these scores rely on internal proxies (e.g., loss magnitude, model uncertainty, or flow likelihood). In noisy continual settings, such proxies are known to be unreliable—overfit noisy nodes can exhibit low loss while clean nodes appear uncertain during task transitions. No validation (e.g., correlation analysis with oracle cleanliness or ablation on proxy choice) is provided to confirm the proxy works as assumed, which directly undermines the noise-mitigation and 'catastrophic remembering' alleviation claims.
- [§5] §5 (Experiments): The manuscript claims consistent outperformance in accuracy and forgetting across four datasets and noise ratios, but the results section lacks reported error bars, statistical significance tests (e.g., paired t-tests), detailed baseline descriptions, or full ablation studies isolating the reliability scoring component from the flow replay. Without these, it is impossible to determine whether observed gains are attributable to the full UFO pipeline or solely to the generative replay, weakening the empirical support for the unified framework.
minor comments (2)
- [§2] The abstract and introduction introduce 'catastrophic remembering' as a novel failure mode, but a more precise definition or illustrative example in §2 would improve clarity for readers unfamiliar with the interaction between noise and forgetting.
- [§3] Notation for the flow model parameters and reliability score formula could be made more explicit (e.g., consistent use of symbols across equations in §3) to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which has helped us strengthen the validation of our reliability scoring mechanism and improve the rigor of our experimental analysis. We address each major comment below and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Instance-level Reliability Scoring): The central robustness claim rests on the reliability scores successfully separating clean from noisy nodes without ground-truth labels. However, these scores rely on internal proxies (e.g., loss magnitude, model uncertainty, or flow likelihood). In noisy continual settings, such proxies are known to be unreliable—overfit noisy nodes can exhibit low loss while clean nodes appear uncertain during task transitions. No validation (e.g., correlation analysis with oracle cleanliness or ablation on proxy choice) is provided to confirm the proxy works as assumed, which directly undermines the noise-mitigation and 'catastrophic remembering' alleviation claims.
Authors: We agree that explicit validation of the reliability scoring proxies is essential, particularly given known limitations of loss- and uncertainty-based signals in noisy continual settings. In the revised manuscript, we have expanded §3.2 with a dedicated analysis subsection that includes: (i) Pearson correlation coefficients between the computed reliability scores and oracle cleanliness labels on controlled synthetic noise injections; (ii) ablation studies comparing single proxies (loss magnitude, predictive uncertainty, flow likelihood) against our combined scoring function; and (iii) visualizations of score distributions for clean versus noisy nodes across task transitions. These additions demonstrate that the unified proxy in UFO achieves higher correlation with ground-truth cleanliness and better mitigates catastrophic remembering than individual proxies, thereby supporting the robustness claims. The new results appear in Figure 3 and Table 2 of the revised §3.2, with further details in the appendix. revision: yes
-
Referee: [§5] §5 (Experiments): The manuscript claims consistent outperformance in accuracy and forgetting across four datasets and noise ratios, but the results section lacks reported error bars, statistical significance tests (e.g., paired t-tests), detailed baseline descriptions, or full ablation studies isolating the reliability scoring component from the flow replay. Without these, it is impossible to determine whether observed gains are attributable to the full UFO pipeline or solely to the generative replay, weakening the empirical support for the unified framework.
Authors: We concur that the original experimental presentation would benefit from greater statistical transparency and component isolation. The revised §5 now reports: (i) mean performance with standard deviation error bars over five random seeds; (ii) paired t-test p-values comparing UFO against each baseline to establish statistical significance; (iii) expanded baseline descriptions including key hyperparameters and implementation details; and (iv) comprehensive ablation tables that separately disable the reliability scoring module while retaining flow-based replay (and vice versa). These ablations confirm that both components contribute non-redundantly to the gains in accuracy and forgetting metrics. Updated tables (Table 3–5) and figures are included in the main text, with full per-dataset breakdowns and additional noise-ratio results moved to the appendix for completeness. revision: yes
Circularity Check
No circularity detected; method proposal and empirical validation remain independent
full rationale
The paper introduces UFO as a novel combination of flow-based replay generation and instance-level reliability scoring to address forgetting and label noise in continual graph learning. No equations, derivations, or self-citations are shown that reduce any claimed prediction or result to a fitted input or prior self-result by construction. The central claims rest on experimental outperformance across four datasets under noise, which are external to the method description and do not rely on renaming, self-definition, or load-bearing self-citations. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
UFO models conditional feature distributions via flow-based generative modeling and produces replay representations... estimates instance-level reliability scores to distinguish clean from noisy nodes
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We show that label noise introduces a new failure mode, catastrophic remembering
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Feng Xia, Ciyuan Peng, Jing Ren, et al. Graph learning. F oundations and Trends® in Signal Processing, pages 362–519, 2026
work page 2026
-
[2]
Deep gaussian embedding of graphs: Unsu- pervised inductive learning via ranking
Aleksandar Bojchevski and Stephan Günnemann. Deep gaussian embedding of graphs: Unsu- pervised inductive learning via ranking. In International Conference on Learning Representa- tions, 2018
work page 2018
-
[3]
James Kirkpatrick, Razvan Pascanu, Neil C. Rabinowitz, et al. Overcoming catastrophic forget- ting in neural networks. Proceedings of the National Academy of Sciences , pages 3521–3526, 2017
work page 2017
-
[4]
What matters in graph class incremental learning? An information preservation perspective
Jialu Li, Y u Wang, Pengfei Zhu, et al. What matters in graph class incremental learning? An information preservation perspective. In Proceedings of the 38th International Conference on Neural Information Processing Systems, pages 26195–26223, 2024
work page 2024
-
[5]
SELFIE: Refurbishing unclean samples for ro- bust deep learning
Hwanjun Song, Minseok Kim, and Jae-Gil Lee. SELFIE: Refurbishing unclean samples for ro- bust deep learning. In Proceedings of the 36th International Conference on Machine Learning , pages 5907–5915, 2019
work page 2019
-
[6]
NoisyGL: A comprehensive benchmark for graph neural networks under label noise
Zhonghao Wang, Danyu Sun, Sheng Zhou, et al. NoisyGL: A comprehensive benchmark for graph neural networks under label noise. In Proceedings of the 38th International Conference on Neural Information Processing Systems , pages 38142–38170, 2024
work page 2024
-
[7]
Kunlun Xu, Haozhuo Zhang, Y u Li, et al. Mitigate catastrophic remembering via continual knowledge purification for noisy lifelong person re-identification. In Proceedings of the 32nd ACM International Conference on Multimedia , pages 5790–5799, 2024
work page 2024
-
[8]
Hierarchical prototype networks for continual graph representation learning
Xikun Zhang, Dongjin Song, and Dacheng Tao. Hierarchical prototype networks for continual graph representation learning. IEEE Transactions on Pattern Analysis and Machine Intelli- gence, pages 4622–4636, 2023
work page 2023
-
[9]
Co-teaching: robust training of deep neural net- works with extremely noisy labels
Bo Han, Quanming Y ao, Xingrui Y u, et al. Co-teaching: robust training of deep neural net- works with extremely noisy labels. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, pages 8536–8546, 2018
work page 2018
-
[10]
Revealing an overlooked challenge in class-incremental graph learning
Daiqing Qi, Handong Zhao, Xiaowei Jia, and Sheng Li. Revealing an overlooked challenge in class-incremental graph learning. Transactions on Machine Learning Research, 2024
work page 2024
-
[11]
ErrorEraser: Unlearning data bias for improved con- tinual learning
Xuemei Cao, Hanlin Gu, Xin Y ang, et al. ErrorEraser: Unlearning data bias for improved con- tinual learning. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V .2, pages 119–130, 2025
work page 2025
-
[12]
Continual learning on noisy data streams via self-purified replay
Chris Dongjoo Kim, Jinseo Jeong, Sangwoo Moon, et al. Continual learning on noisy data streams via self-purified replay. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 537–547, 2021
work page 2021
-
[13]
Leveraging peer-informed label consistency for robust graph neural networks with noisy labels
Kailai Li, Jiawei Sun, Jiong Lou, Zhanbo Feng, Hefeng Zhou, Chentao Wu, Guangtao Xue, Wei Zhao, and Jie Li. Leveraging peer-informed label consistency for robust graph neural networks with noisy labels. In James Kwok, editor, Proceedings of the Thirty-F ourth Interna- tional Joint Conference on Artificial Intelligence, IJCAI-25 , pages 5598–5606. Internati...
work page 2025
-
[14]
Xikun Zhang, Dongjin Song, and Dacheng Tao. Continual learning on graphs: Challenges, solutions, and opportunities. arXiv preprint arXiv:2402.11565, 2024
-
[15]
Zhizhong Li and Derek Hoiem. Learning without forgetting. IEEE Transactions on Pattern Analysis and Machine Intelligence , 40(12):2935–2947, 2017. 10
work page 2017
-
[16]
Overcoming catastrophic forgetting in graph neural networks
Huihui Liu, Yiding Y ang, and Xinchao Wang. Overcoming catastrophic forgetting in graph neural networks. Proceedings of the AAAI Conference on Artificial Intelligence , pages 8653– 8661, 2021
work page 2021
-
[17]
Towards continuous reuse of graph models via holistic memory diversification
Ziyue Qiao, Junren Xiao, Qingqiang Sun, et al. Towards continuous reuse of graph models via holistic memory diversification. In International Conference on Learning Representations, 2025
work page 2025
-
[18]
DSLR: Diversity enhancement and structure learning for rehearsal-based graph continual learning
Seungyoon Choi, Wonjoong Kim, Sungwon Kim, et al. DSLR: Diversity enhancement and structure learning for rehearsal-based graph continual learning. In Proceedings of the ACM Web Conference 2024, pages 733–744, 2024
work page 2024
-
[19]
Mengmeng Sheng, Zeren Sun, Tianfei Zhou, et al. CA2C: A prior-knowledge-free approach for robust label noise learning via asymmetric co-learning and co-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 901–911, 2025
work page 2025
-
[20]
Learning from noisy labels with deep neural networks: A survey
Hwanjun Song, Minseok Kim, Dongmin Park, et al. Learning from noisy labels with deep neural networks: A survey. IEEE Transactions on Neural Networks and Learning Systems , pages 8135–8153, 2023
work page 2023
-
[21]
Generalized cross entropy loss for training deep neural networks with noisy labels
Zhilu Zhang and Mert R Sabuncu. Generalized cross entropy loss for training deep neural networks with noisy labels. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, pages 8792–8802, 2018
work page 2018
-
[22]
Probabilistic end-to-end noise correction for learning with noisy labels
Kun Yi and Jianxin Wu. Probabilistic end-to-end noise correction for learning with noisy labels. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7017–7025, 2019
work page 2019
-
[23]
Xingrui Y u, Bo Han, Jiangchao Y ao, et al. How does disagreement help generalization against label corruption? In International Conference on Machine Learning , pages 7164–7173, 2019
work page 2019
-
[24]
Symmetric cross entropy for robust learning with noisy labels
Yisen Wang, Xingjun Ma, Zaiyi Chen, et al. Symmetric cross entropy for robust learning with noisy labels. In Proceedings of the IEEE/CVF international conference on computer vision , pages 322–330, 2019
work page 2019
-
[25]
Training deep neural networks on noisy labels with bootstrapping
Scott Reed, Honglak Lee, Dragomir Anguelov, et al. Training deep neural networks on noisy labels with bootstrapping. arXiv preprint arXiv:1412.6596, 2014
-
[26]
CLNode: Curriculum learning for node classification
Xiaowen Wei, Xiuwen Gong, Yibing Zhan, et al. CLNode: Curriculum learning for node classification. In Proceedings of the 16th ACM International Conference on Web Search and Data Mining, pages 670–678, 2023
work page 2023
-
[27]
Learning from graph: Mitigating label noise on graph through topological feature reconstruction
Zhonghao Wang, Y uanchen Bei, Sheng Zhou, et al. Learning from graph: Mitigating label noise on graph through topological feature reconstruction. In Proceedings of the 34th ACM In- ternational Conference on Information and Knowledge Management , pages 3261–3270, 2025
work page 2025
-
[28]
Mitigating label noise on graphs via topological sample selection
Y uhao Wu, Jiangchao Y ao, Xiaobo Xia, et al. Mitigating label noise on graphs via topological sample selection. In Proceedings of the 41st International Conference on Machine Learning , pages 53944–53972, 2024
work page 2024
-
[29]
V ariational inference with normalizing flows
Danilo Rezende and Shakir Mohamed. V ariational inference with normalizing flows. In Pro- ceedings of the 32nd International Conference on Machine Learning , pages 1530–1538, 2015
work page 2015
-
[30]
Density estimation using real NVP
Laurent Dinh, Jascha Sohl-Dickstein, and Samy Bengio. Density estimation using real NVP. In International Conference on Learning Representations , 2017
work page 2017
-
[31]
Semi-supervised learning with normalizing flows
Pavel Izmailov, Polina Kirichenko, Marc Finzi, and Andrew Gordon Wilson. Semi-supervised learning with normalizing flows. In Hal Daumé III and Aarti Singh, editors, Proceedings of the 37th International Conference on Machine Learning , volume 119 of Proceedings of Machine Learning Research, pages 4615–4630, 13–18 Jul 2020
work page 2020
-
[32]
Normalizing flows for probabilistic modeling and inference
George Papamakarios, Eric Nalisnick, Danilo Jimenez Rezende, et al. Normalizing flows for probabilistic modeling and inference. Journal of Machine Learning Research, (57):1–64, 2021. 11
work page 2021
-
[33]
Neubm: Mitigating model bias in graph neural networks through neutral input calibration
Jiawei Gu, Ziyue Qiao, and Xiao Luo. Neubm: Mitigating model bias in graph neural networks through neutral input calibration. In Proceedings of the 34th International Joint Conference on Artificial Intelligence, pages 2829–2837, 2025
work page 2025
-
[34]
Inductive representation learning on large graphs
William L Hamilton, Rex Ying, and Jure Leskovec. Inductive representation learning on large graphs. In Proceedings of the 31st International Conference on Neural Information Processing Systems, pages 1025–1035, 2017
work page 2017
-
[35]
Learning with instance-dependent label noise: A sample sieve approach
Hao Cheng, Zhaowei Zhu, Xingyu Li, et al. Learning with instance-dependent label noise: A sample sieve approach. In International Conference on Learning Representations , 2021
work page 2021
-
[36]
Accurate forgetting for heteroge- neous federated continual learning
Abudukelimu Wuerkaixi, Sen Cui, Jingfeng Zhang, et al. Accurate forgetting for heteroge- neous federated continual learning. In The 12th International Conference on Learning Repre- sentations, 2024
work page 2024
-
[37]
NRGNN: Learning a label noise resistant graph neural network on sparsely and noisily labeled graphs
Enyan Dai, Charu Aggarwal, and Suhang Wang. NRGNN: Learning a label noise resistant graph neural network on sparsely and noisily labeled graphs. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining , pages 227–236, 2021
work page 2021
-
[38]
Handling label noise via instance-level diffi- culty modeling and dynamic optimization
Kuan Zhang, Chengliang Chai, Jingzhe Xu, et al. Handling label noise via instance-level diffi- culty modeling and dynamic optimization. In Proceedings of the 39th International Conference on Neural Information Processing Systems , pages 46667–46696, 2025
work page 2025
-
[39]
Distilling knowledge from graph convolutional networks
Yiding Y ang, Jiayan Qiu, Mingli Song, et al. Distilling knowledge from graph convolutional networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition, pages 7074–7083, 2020
work page 2020
-
[40]
Pitfalls of Graph Neural Network Evaluation
Oleksandr Shchur, Maximilian Mumme, Aleksandar Bojchevski, and Stephan Günnemann. Pitfalls of graph neural network evaluation. arXiv preprint arXiv:1811.05868, 2018
work page Pith review arXiv 2018
-
[41]
Péter Mernyei and C ˘at˘alina Cangea. Wiki-CS: A wikipedia-based benchmark for graph neural networks. arXiv preprint arXiv:2007.02901, 2020
-
[42]
CGLB: benchmark tasks for continual graph learning
Xikun Zhang, Dongjin Song, and Dacheng Tao. CGLB: benchmark tasks for continual graph learning. In Proceedings of the 36th International Conference on Neural Information Process- ing Systems, pages 13006–13021, 2022
work page 2022
-
[43]
Overcoming catastrophic forgetting in graph neural networks with experience replay
Fan Zhou and Chengtai Cao. Overcoming catastrophic forgetting in graph neural networks with experience replay. Proceedings of the AAAI Conference on Artificial Intelligence , pages 4714–4722, 2021
work page 2021
-
[44]
Ting Wu, Jingyi Liu, Rui Zheng, et al. Enhancing contrastive learning with noise-guided attack: Towards continual relation extraction in the wild. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers) , pages 2227–2239, 2024
work page 2024
-
[45]
Federated continual graph learning
Yinlin Zhu, Miao Hu, and Di Wu. Federated continual graph learning. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V .2 , pages 4203– 4213, 2025. 12 A Implementation Details A.1 Datasets In our experiments, we evaluate our method on four widely used graph datasets. • CoraFull [2] is an academic citation network wit...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.