Recognition: 2 theorem links
· Lean TheoremContinuous Latent Contexts Enable Efficient Online Learning in Transformers
Pith reviewed 2026-05-12 05:02 UTC · model grok-4.3
The pith
Transformers implement weighted majority and Q-learning using continuous latent context tokens to store state.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We give explicit constructions of constant-depth transformers that implement two foundational online decision-making procedures -- the weighted majority algorithm and Q-learning -- by storing their algorithmic state as linear combinations of feature embeddings, using a small number of latent context tokens. We further train a small GPT-2-style transformer with latent contexts using a multi-curriculum objective that does not directly supervise the latent states. On long synthetic online prediction sequences, this model outperforms larger and more complex LLMs. Our results suggest that continuous latent contexts provide a simple and effective persistent state for transformers to implement在线学习.
What carries the argument
Continuous latent context tokens that store algorithmic state as linear combinations of feature embeddings across transformer layers.
If this is right
- Constant-depth transformers can execute online learning algorithms without any parameter updates.
- Algorithmic state persists reliably using only a fixed small number of tokens regardless of sequence length.
- Multi-curriculum training allows the model to acquire online behaviors without direct labels on the internal states.
- Small models using this method achieve higher accuracy than much larger LLMs on long-horizon online prediction.
Where Pith is reading between the lines
- The same latent token mechanism could support other online algorithms such as bandit methods or policy iteration in transformer form.
- Persistent contexts might reduce the need for external memory modules in long interactive dialogues or agent tasks.
- Scaling the approach to real-world feedback streams like user interactions could produce more adaptive deployed models.
- One could test extensions by measuring how well the constructions transfer when the input features come from pretrained embeddings rather than synthetic ones.
Load-bearing premise
The continuous latent context tokens can be reliably maintained and updated across arbitrary-length sequences in a transformer forward pass without degradation or the need for explicit supervision on the latent states themselves.
What would settle it
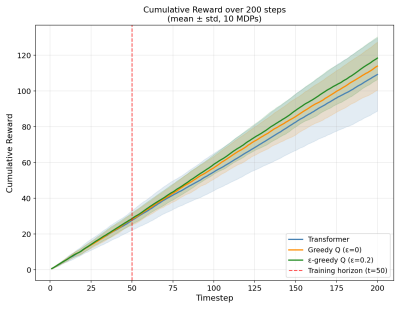
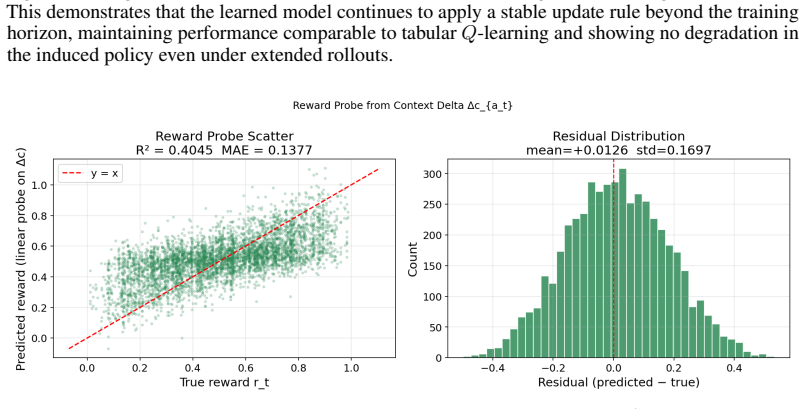
A trained transformer with latent contexts that fails to match the exact update rules of weighted majority or Q-learning on extended synthetic sequences, or whose performance no longer exceeds larger models without such tokens.
Figures












read the original abstract
Large language models (LLMs) exhibit a strong capacity for in-context learning: Given labeled examples, they can generate good predictions without parameter updates. However, many interactive settings go beyond static prediction to online decision-making, in which effective behavior demands adaptation over long multi-turn horizons in response to feedback, and efficient algorithms in these domains must use compact representations of what they have learned. Recently, continuous transformer architectures with latent chain of thought have shown promise for offline iterative tasks such as directed graph-reachability. Motivated by this, we study whether continuous latent context tokens equip transformers to more effectively realize online learning. We give explicit constructions of constant-depth transformers that implement two foundational online decision-making procedures -- the weighted majority algorithm and $Q$-learning -- by storing their algorithmic state as linear combinations of feature embeddings, using a small number of latent context tokens. We further train a small GPT-2-style transformer with latent contexts using a multi-curriculum objective that does not directly supervise the latent states. On long synthetic online prediction sequences, this model outperforms larger and more complex LLMs, including Qwen-3-14B and DeepSeek-V3. Our results suggest that continuous latent contexts provide a simple and effective persistent state for transformers to implement online learning algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that constant-depth transformers equipped with a small number of continuous latent context tokens can exactly implement two core online learning algorithms—the weighted majority algorithm and Q-learning—by representing algorithmic state as linear combinations of feature embeddings. It further shows that a small GPT-2-style transformer trained with a multi-curriculum objective (without direct latent supervision) outperforms much larger models such as Qwen-3-14B and DeepSeek-V3 on long synthetic online prediction sequences.
Significance. If the constructions hold, the work supplies a concrete mechanistic account of how transformers can maintain persistent algorithmic state for online adaptation, linking classical online learning theory to modern architectures. The explicit constructions are a notable strength, as is the demonstration that latent contexts can be learned without direct supervision. The empirical outperformance on long-horizon tasks, if reproducible, would indicate practical utility for interactive decision-making settings where standard LLMs falter.
major comments (2)
- [§3.1–3.2] §3.1–3.2 (WMA and Q-learning constructions): The claim that a fixed-depth transformer exactly reproduces the multiplicative weight updates of WMA and the Bellman updates of Q-learning at every step relies on the attention and FFN layers performing precise linear combinations in the latent tokens while leaving other computations identity-like. No argument is given that the composite map over arbitrary T steps remains faithful once softmax normalization, layer norms, and residual connections are applied; single-step mechanics do not automatically guarantee multi-step stability when inputs vary.
- [§4] §4 (empirical evaluation): The statement that the trained latent-context model outperforms Qwen-3-14B and DeepSeek-V3 on long synthetic sequences is load-bearing for the practical claim, yet the manuscript provides insufficient detail on sequence generation, feature embedding construction, baseline prompting, number of independent runs, and statistical testing. Without these, it is impossible to determine whether the reported gains are robust or sensitive to the particular synthetic distribution.
minor comments (2)
- [Abstract] The abstract references prior latent chain-of-thought work but does not include a citation; adding the relevant reference would improve context.
- [§2] A small diagram illustrating the flow of latent context tokens across time steps would clarify how the state is updated and read out.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below and have revised the manuscript to strengthen the presentation of the theoretical constructions and to supply the requested empirical details.
read point-by-point responses
-
Referee: [§3.1–3.2] §3.1–3.2 (WMA and Q-learning constructions): The claim that a fixed-depth transformer exactly reproduces the multiplicative weight updates of WMA and the Bellman updates of Q-learning at every step relies on the attention and FFN layers performing precise linear combinations in the latent tokens while leaving other computations identity-like. No argument is given that the composite map over arbitrary T steps remains faithful once softmax normalization, layer norms, and residual connections are applied; single-step mechanics do not automatically guarantee multi-step stability when inputs vary.
Authors: We appreciate the referee drawing attention to the multi-step composition. In the constructions, the latent context tokens are isolated by the attention pattern so that the main sequence tokens receive identity-like treatment, while the FFN applies the exact linear combination required by the WMA or Q-learning update. Layer norms are configured (via the specific scaling and zero-bias choices described in the appendix) to act as the identity on the dimensions carrying the algorithmic state, and residuals simply add the update without scaling. Because the output embedding of the context tokens after one forward pass is identical in format to the input embedding for the next pass, the per-step map composes exactly by induction for any T. We have added a short inductive paragraph immediately after the constructions in the revised §3 to make this explicit. revision: yes
-
Referee: [§4] §4 (empirical evaluation): The statement that the trained latent-context model outperforms Qwen-3-14B and DeepSeek-V3 on long synthetic sequences is load-bearing for the practical claim, yet the manuscript provides insufficient detail on sequence generation, feature embedding construction, baseline prompting, number of independent runs, and statistical testing. Without these, it is impossible to determine whether the reported gains are robust or sensitive to the particular synthetic distribution.
Authors: We agree that reproducibility requires these details. The revised §4 now includes: (i) the exact generative process for the synthetic online sequences (a mixture of linear and nonlinear prediction tasks with Bernoulli feedback), (ii) the feature-embedding construction (random Fourier features of the input tokens), (iii) the precise few-shot prompting templates and temperature settings used for Qwen-3-14B and DeepSeek-V3, (iv) the number of independent runs (10 runs with distinct random seeds), and (v) statistical results (mean accuracy differences and paired t-test p-values). These additions confirm that the performance advantage is consistent and statistically significant across the tested distributions. revision: yes
Circularity Check
No significant circularity; constructions are independent explicit mappings.
full rationale
The paper presents explicit constructions of constant-depth transformers implementing WMA and Q-learning via linear combinations in latent context tokens, which are self-contained mathematical derivations rather than reductions to fitted inputs or self-citations. The training uses a multi-curriculum objective without direct latent supervision, and no load-bearing steps reduce by definition or self-citation chain to the target claims. The derivation chain remains independent of its outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A constant-depth transformer with latent context tokens can maintain and update algorithmic state across arbitrary sequence lengths without degradation
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe give explicit constructions of constant-depth transformers that implement two foundational online decision-making procedures -- the weighted majority algorithm and Q-learning -- by storing their algorithmic state as linear combinations of feature embeddings, using a small number of latent context tokens.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclearthe latent contexts encode the intended superposition states
Reference graph
Works this paper leans on
-
[1]
Emile Anand and Ishani Karmarkar
URLhttps://arxiv.org/abs/2602.08332. Emile Anand and Ishani Karmarkar. Learning Approximate Nash Equilibria in Cooperative Multi- Agent Reinforcement Learning via Mean-Field Subsampling, 2026. Emile Anand and Guannan Qu. Efficient Reinforcement Learning for Global Decision Making in the Presence of Local Agents at Scale, 2024. Emile Timothy Anand and Sara...
-
[2]
David Chiang, Peter Cholak, and Anand Pillay
URLhttps://arxiv.org/abs/2412.02975. David Chiang, Peter Cholak, and Anand Pillay. Tighter bounds on the expressivity of transformer encoders. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors,Proceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of M...
-
[3]
URLhttps://arxiv.org/abs/2410.08292. Jonas Geiping, Sean McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein. Scaling up test-time compute with latent reasoning: A recurrent depth approach.arXiv preprint arXiv:2502.05171, 2025. 11 Sachin Goyal, Ziwei Ji, Ankit Singh Rawat, Aditya...
-
[4]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
URLhttps://arxiv.org/abs/2201.11903. Jianzhe Wei, Siyu Chen, Jianliang He, and Zhuoran Yang. HOW TRANSFORMERS LEARN CAUSAL STRUCTURES IN-CONTEXT: EXPLAINABLE MECHANISM MEETS THEORETI- CAL GUARANTEE. InThe Fourteenth International Conference on Learning Representations,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
arXiv preprint arXiv:2405.21046 , year=
URLhttps://openreview.net/forum?id=bpF8zgSt41. Tengyang Xie, Dylan J. Foster, Akshay Krishnamurthy, Corby Rosset, Ahmed Awadallah, and Alexander Rakhlin. Exploratory Preference Optimization: Harnessing Implicit Q*-Approximation for Sample-Efficient RLHF, 2024. URLhttps://arxiv.org/abs/2405.21046. 13 An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan...
-
[6]
Our dataset comprises of 3000 sequences, where each sequence length comprises of steps of length 100
Model:We train a GPT-2 style decoder [Radford et al., 2019] with AdamW, learning rate = 10−4 (cosine scheduler), weight decay = 10−2, and gradient clipping at 1.0. Our dataset comprises of 3000 sequences, where each sequence length comprises of steps of length 100. In addition to the discrete tokens, every step is prefixed with a single continuous context...
work page 2019
-
[7]
Dataset:The expert qualities are initiated uniformly at random between [0.3,0.9] . At each step, there is a random binary true label, and each expert predicts the correct label with its probability (which is the quality), and gets a loss of 0 is correct and 1 if wrong. We train via a curriculum strategy where the losses are computed only at the masked pos...
-
[8]
Curriculum Strategy:We teach the model to learn to reason over progressively larger MW sequences, one stage at a time. Specifically, for 1≤i≤10 , it trains on sequences truncated to 5i steps, and for 11≤i≤13 , it trains on sequences It trains on sequences truncated to 50 + 15(i−10) steps. Every sequence is cut to these steps so the model doesn’t see longe...
-
[9]
Training:We train on 13 stages for up to 30 epochs/stage. Each epoch runs for 300 steps, and we set an early stopping after 5 stages if the loss did not decrease significantly (with a patience of3steps to prevent stochastic early stopping),
-
[10]
Evaluation:We evaluate the performance of our trained model in Figure 7 as well as in Figure 8 and Figure 9. Our results indicate that the latent context significantly improves the performance of the model on long synthetic prediction tasks, performing comparably to the optimal multiplicative weights update algorithm. Of note, when the quality of the best...
-
[11]
, c|A| are prepended to each step’s discrete token sequence: [BOS, c1,
Model:Pre-norm GPT-2 style decoder ( nlayers = 4, nheads = 8, dmodel = 256, dff = 1024, dropout 0.1) with a recurrent continuous-context interface: |A| learned context vectors c1, . . . , c|A| are prepended to each step’s discrete token sequence: [BOS, c1, . . . , c|A|, Qcurr, st, at, rt, Qnext,(s t+1, a1)|A| i=1,Select, a ⋆,Update] The hidden state at Up...
-
[12]
Each episode samples nS ∼ U({2,
Dataset: 50,000 tabular Q-learning trajectories (45k train / 5k val). Each episode samples nS ∼ U({2, . . . ,8}) , nA ∼ U({2,3,4}) , nsteps ∼ U({10, . . . ,50}) , exploration ε∼ U(0,1) , with fixed α= 0.1, γ= 0.9 . MDPs are sampled across a grid of 6 reward distributions (peaked / bimodal / uniform / sparse / dense Beta, plus Bernoulli)× 3 transition conc...
-
[13]
Curriculum is overaction count: training is split into 3 stages, each introducing one larger nA
Curriculum / Loss Function:Per-step cross-entropy on the SELECT logits against the tabular targeta ⋆, masking phantom action slots when|A|<max|A|: L := 1 T TX t=1 CE SELECT logitst, a⋆ t . Curriculum is overaction count: training is split into 3 stages, each introducing one larger nA. Stage k (epochs in [ (k−1)E 3 , kE 3 ]) trains on episodes with nA ∈ {2...
-
[14]
Training: E= 28 epochs total, batch size 64, BPTT through full episodes with truncation window 10 (context detached every 10 steps to bound memory). Validation every 500 steps and at end of epoch; best-by-val-CE checkpoint is kept. E.2.5 Additional Experimental Results Figure 10: Full causal attention heatmap on a 4-state, 2-action linear-chain MDP where ...
work page 2025
-
[15]
Prediction turn In a prediction turn, you are given: * a short note from earlier rounds, * this round's predictions from the four experts. You should use the note and the experts'predictions to make your prediction for this round.,→ Input format: { "turn_type": "prediction", "note": "<short text>", "Expert_A": 0 or 1, "Expert_B": 0 or 1, "Expert_C": 0 or ...
-
[16]
Feedback turn In a feedback turn, you are given: * the previous note, * this round's predictions from the four experts, * the true label for this round. You should produce a new short note for future rounds. The note should keep only the information that is most useful for making later predictions.,→ Input format: { "turn_type": "feedback", "note": "<shor...
-
[17]
Prediction turn In a prediction turn, you are given: * this round's predictions from the four experts. You should use the experts'predictions to make your prediction for this round. Input format: { "turn_type": "prediction", "Expert_A": 0 or 1, "Expert_B": 0 or 1, "Expert_C": 0 or 1, "Expert_D": 0 or 1 } Output format: { "prediction": 0 or 1 }
-
[18]
Feedback turn In a feedback turn, you are given: * the true label for this round. 30 You do not need to output anything for the feedback turn. Use this feedback when making later predictions.,→ Input format: { "turn_type": "feedback", "true_label": 0 or 1 } Important requirements: * Do not use any external tools. * Do not write or execute code. * Do not p...
-
[19]
Forecast turn In a forecast turn, you are given: * a short note from earlier days, * today's predictions from the four experts. You should use the note and the experts'predictions to make your prediction for today.,→ Input format: { "turn_type": "forecast", "note": "<short text>", "Expert_A": "sunny" or "rainy", "Expert_B": "sunny" or "rainy", "Expert_C":...
-
[20]
Feedback turn In a feedback turn, you are given: * the previous note, * today's predictions from the four experts, * the actual weather for today. 31 You should produce a new short note for future days. The note should keep only the information that is most useful for making later guesses.,→ Input format: { "turn_type": "feedback", "note": "<short text>",...
-
[21]
Forecast turn In a forecast turn, you are given: * today's predictions from the four experts. You should use the experts'predictions to make your prediction for today. Input format: { "turn_type": "forecast", "Expert_A": "sunny" or "rainy", "Expert_B": "sunny" or "rainy", "Expert_C": "sunny" or "rainy", "Expert_D": "sunny" or "rainy" } Output format: { "p...
-
[22]
Feedback turn In a feedback turn, you are given: * the actual weather for today. You do not need to output anything for the feedback turn. Use this feedback when making later guesses.,→ Input format: { "turn_type": "feedback", "actual_weather": "sunny" or "rainy" } Important requirements: * Do not use any external tools. * Do not write or execute code. * ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.