Recognition: 3 theorem links
· Lean TheoremDeep Learning under Fractional-Order Differential Privacy
Pith reviewed 2026-05-12 04:38 UTC · model grok-4.3
The pith
FO-DP-SGD replaces the current gradient query with a fractional recursive one that incorporates memory from past private releases without raising the effective sensitivity beyond βC.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FO-DP-SGD replaces the current-only query before noise addition with a fractional recursive query that combines the current clipped sum with a finite-window, power-law-weighted aggregation of previously released private sum-level outputs. Under add/remove adjacency with Poisson subsampling the current-step sensitivity analysis shows that the only newly data-dependent term is the scaled current clipped sum, so the effective ℓ2-sensitivity is at most βC where β∈(0,1] controls the current-step contribution. Thus FO-DP-SGD admits standard per-step Rényi differential privacy accounting via a Poisson-subsampled Gaussian mechanism with effective noise-to-sensitivity ratio σ/β, and the bounds compos
What carries the argument
Fractional recursive query that mixes the current clipped sum with power-law-weighted past private releases before Gaussian noise is added.
If this is right
- The privacy accounting stays identical to standard DP-SGD except for the effective sensitivity βC, allowing the usual noise calibration to be tightened by the factor β.
- The fractional order, memory window length and mixing coefficient directly control the trade-off among current-step sensitivity, retention of past signal and influence of private history.
- The mechanism preserves the classical sum-then-noise-then-divide structure while adding memory, so existing DP-SGD code changes are minimal.
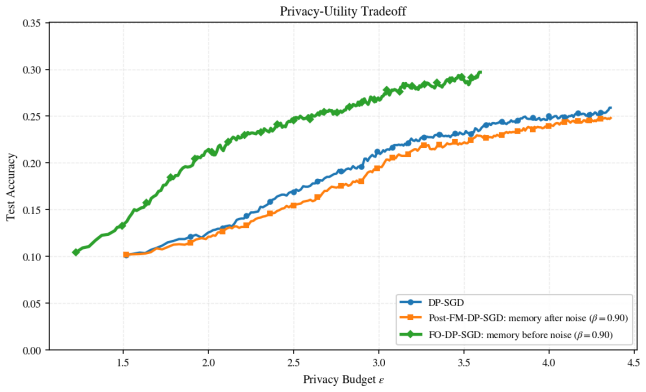
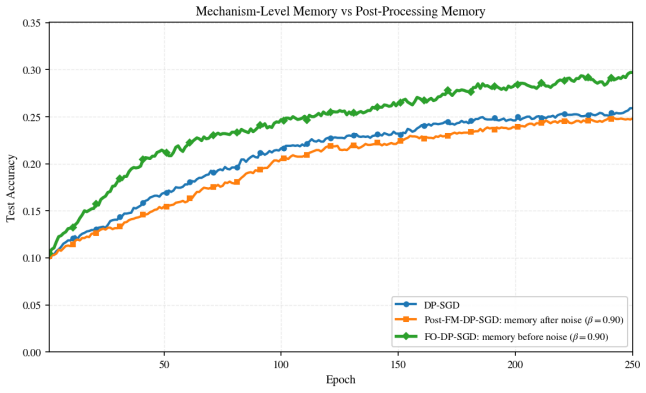
- Empirical results show improved test accuracy and privacy-utility curves on SVHN, CIFAR-10 and CIFAR-100 relative to DP-SGD, DP-Adam and listed baselines.
Where Pith is reading between the lines
- The same fractional-query idea could be applied to other first-order private optimizers such as DP-Adam without changing their per-step accounting.
- Choosing the power-law weights to decay faster might reduce the carry-over of early noisy steps, potentially improving convergence speed under fixed privacy budget.
- The construction supplies a natural testbed for studying whether long-memory private updates help on sequential or recurrent tasks beyond image classification.
Load-bearing premise
The fractional recursive query introduces no additional data-dependent terms beyond the scaled current clipped sum.
What would settle it
An explicit pair of add/remove-adjacent datasets and a concrete fractional order where the difference in the full recursive query output exceeds β times the difference in their current clipped sums would falsify the sensitivity claim.
Figures






read the original abstract
Differentially private stochastic gradient descent (DP-SGD) is a standard approach to privacy-preserving learning based on per-example clipping, subsampling, Gaussian perturbation, and privacy accounting. Classical DP-SGD releases a noisy version of the current clipped subsampled gradient sum. We propose Fractional-Order Differentially Private Stochastic Gradient Descent (\textbf{FO-DP-SGD}), a mechanism-level extension that replaces this current-only query, before Gaussian noise is added, with a fractional recursive query combining the current clipped sum with a finite-window, power-law-weighted aggregation of previously released private sum-level outputs. This injects fractional memory into the release mechanism while preserving the standard \emph{sum-then-noise-then-divide} structure. Under add/remove adjacency with Poisson subsampling, the current-step sensitivity analysis shows that the only newly data-dependent term is the scaled current clipped sum. Hence, conditioned on the private history, the effective \(\ell_2\)-sensitivity is at most \(\beta C\), where \(C\) is the clipping threshold and \(\beta\in(0,1]\) controls the current-step contribution. Thus, FO-DP-SGD admits standard per-step R\'enyi differential privacy accounting via a Poisson-subsampled Gaussian mechanism with effective noise-to-sensitivity ratio \(\sigma/\beta\), and composes to yield overall \((\varepsilon,\delta)\)-differential privacy guarantees. FO-DP-SGD provides a framework for studying long-memory effects in private optimization. The fractional order, memory window, and mixing coefficient govern the trade-off among current-step sensitivity, signal retention, and private-history influence. Experiments on SVHN, CIFAR-10, and CIFAR-100 show improved test accuracy and privacy--utility performance over DP-SGD and private baselines including DP-Adam, DP-IS, SA-DP-SGD, ADP-AdamW, DP-SAT, and DP-Adam-AC.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Fractional-Order Differentially Private Stochastic Gradient Descent (FO-DP-SGD), a modification to DP-SGD that replaces the standard current-only clipped gradient query with a fractional recursive query: a linear combination of the current clipped sum (scaled by mixing coefficient β) and a finite-window power-law weighted aggregation of prior private outputs. Under add/remove adjacency and Poisson subsampling, it claims the effective ℓ₂-sensitivity remains at most βC (C the clipping threshold), permitting standard per-step Rényi DP accounting for the Poisson-subsampled Gaussian mechanism with noise-to-sensitivity ratio σ/β. The paper presents this as a framework for long-memory effects in private optimization and reports improved test accuracy over DP-SGD and several private baselines on SVHN, CIFAR-10, and CIFAR-100.
Significance. If the sensitivity reduction holds, the work supplies a clean mechanism-level route to injecting controllable memory into private gradient releases without altering the core sum-then-noise structure or requiring new accounting primitives beyond a rescaled Gaussian. This could facilitate systematic study of long-memory phenomena in DP training. The multi-dataset experiments provide initial evidence of utility gains, though their strength depends on reproducibility details.
major comments (2)
- [§3] §3 (Mechanism and Sensitivity Analysis): The central claim that, conditioned on the private history, the fractional query introduces no additional data-dependent terms beyond β times the current clipped sum (yielding effective sensitivity βC) is asserted to follow directly from the definition but is not accompanied by an explicit derivation or expansion of the query difference under add/remove neighbors. A step-by-step calculation showing that all prior terms become fixed constants under conditioning is required to confirm the bound is load-bearing for the subsequent RDP reduction.
- [§5] §5 (Experiments): The reported accuracy improvements lack sufficient detail on hyper-parameter search procedures, random seeds, number of runs, and exact baseline implementations (e.g., how DP-Adam, SA-DP-SGD, and ADP-AdamW were tuned and whether they used identical clipping and noise schedules). Without these, it is difficult to assess whether the gains are robust or attributable to the fractional memory rather than optimization differences.
minor comments (2)
- [Abstract / §1] The abstract and introduction use the phrase 'standard per-step Rényi differential privacy accounting' without citing the precise RDP composition theorem or the Poisson-subsampling RDP bound being invoked (e.g., the specific form from Mironov et al. or Abadi et al.). Adding the reference would improve traceability.
- [§2 / §3] Notation for the fractional order, memory window length, and power-law weights is introduced but not consistently symbolized across the mechanism definition and the sensitivity argument; a single table or equation block collecting all free parameters would aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation and reproducibility.
read point-by-point responses
-
Referee: [§3] §3 (Mechanism and Sensitivity Analysis): The central claim that, conditioned on the private history, the fractional query introduces no additional data-dependent terms beyond β times the current clipped sum (yielding effective sensitivity βC) is asserted to follow directly from the definition but is not accompanied by an explicit derivation or expansion of the query difference under add/remove neighbors. A step-by-step calculation showing that all prior terms become fixed constants under conditioning is required to confirm the bound is load-bearing for the subsequent RDP reduction.
Authors: We agree that an explicit derivation would improve clarity. In the revised manuscript we will insert a step-by-step expansion of the query difference Δq under add/remove adjacency. We will show that, when conditioned on the shared private history, every term involving prior private outputs is identical for neighboring datasets and therefore reduces to a fixed constant; the only data-dependent contribution is the current clipped sum, which differs by at most C and is scaled by β. This confirms the ℓ₂-sensitivity bound of βC and directly justifies the subsequent Poisson-subsampled Gaussian RDP accounting. revision: yes
-
Referee: [§5] §5 (Experiments): The reported accuracy improvements lack sufficient detail on hyper-parameter search procedures, random seeds, number of runs, and exact baseline implementations (e.g., how DP-Adam, SA-DP-SGD, and ADP-AdamW were tuned and whether they used identical clipping and noise schedules). Without these, it is difficult to assess whether the gains are robust or attributable to the fractional memory rather than optimization differences.
Authors: We acknowledge the need for greater experimental transparency. The revised §5 will describe the hyper-parameter search procedure (grid search ranges for learning rate, β, memory window, and fractional order), the number of independent runs and random seeds employed, and the precise baseline configurations, including how clipping thresholds and noise multipliers were matched across methods to ensure fair comparison. These additions will allow readers to evaluate whether the observed gains are attributable to the fractional-memory mechanism. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines FO-DP-SGD explicitly as a linear combination of the current clipped sum (scaled by β) and fixed weights on prior private outputs. The sensitivity claim then follows by direct inspection: under add/remove adjacency and conditioning on history, all prior terms are constants, so the query difference reduces exactly to β times the current clipped sum difference (bounded by C). This is standard conditional sensitivity analysis for the Poisson-subsampled Gaussian mechanism and does not rely on fitted parameters, self-citations, or any reduction of the output to the input by construction. The overall RDP accounting is therefore the usual one applied to the effective ratio σ/β, making the derivation self-contained.
Axiom & Free-Parameter Ledger
free parameters (3)
- β
- fractional order
- memory window
axioms (2)
- domain assumption Add/remove adjacency relation under Poisson subsampling
- domain assumption The fractional recursive query preserves the sum-then-noise-then-divide structure with no additional data-dependent terms beyond the scaled current sum
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearthe recursive sum-level private query is rt(D;mt,ht)=βst(D;mt)+(1−β)uCA t−1(ht)
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction unclearK=8 memory window; fractional order α∈(0,1]
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability uncleareffective ℓ2-sensitivity at most βC
Reference graph
Works this paper leans on
-
[1]
URL http: //dx.doi.org/10.1145/2976749.2978318
Martín Abadi, Andy Chu, Ian Goodfellow, H. Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. Deep learning with differential privacy. InProceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security (CCS), pages 308–318. ACM, 2016. doi: 10.1145/2976749.2978318
-
[2]
Mohan Suriyakumar, Om Thakkar, and Abhradeep Thakurta
Eyal Amid, Ananda Ganesh, Rajiv Mathews, Swaroop Ramaswamy, Shuang Song, Thomas Steinke, V . Mohan Suriyakumar, Om Thakkar, and Abhradeep Thakurta. Public data-assisted mirror descent for private model training. InProceedings of the 39th International Conference on Machine Learning (ICML), pages 517–535, 2022. 9
work page 2022
-
[3]
Brendan McMahan, and Swaroop Ramaswamy
Galen Andrew, Om Thakkar, H. Brendan McMahan, and Swaroop Ramaswamy. Differentially private learning with adaptive clipping. InAdvances in Neural Information Processing Systems 34 (NeurIPS), pages 17455–17466, 2021
work page 2021
-
[4]
Duchi, Alireza Fallah, Omid Javidbakht, and Kunal Talwar
Hilal Asi, John C. Duchi, Alireza Fallah, Omid Javidbakht, and Kunal Talwar. Private adaptive gradient methods for convex optimization. InProceedings of the 38th International Conference on Machine Learning (ICML), pages 383–392, 2021
work page 2021
-
[5]
Borja Balle and Yu-Xiang Wang. Improving the gaussian mechanism for differential pri- vacy: Analytical calibration and optimal denoising. InProceedings of the 35th International Conference on Machine Learning (ICML), pages 394–403, 2018
work page 2018
-
[6]
Fractional-order deep backpropagation neural network
Chao Bao, Yifei Pu, and Yuan Zhang. Fractional-order deep backpropagation neural network. Computational Intelligence and Neuroscience, 2018:7361628, 2018
work page 2018
-
[7]
Private empirical risk minimization: Efficient algorithms and tight error bounds
Raef Bassily, Adam Smith, and Abhradeep Thakurta. Private empirical risk minimization: Efficient algorithms and tight error bounds. InIEEE 55th Annual Symposium on Foundations of Computer Science (FOCS), pages 464–473, 2014
work page 2014
-
[8]
Private stochastic convex optimization with optimal rates
Raef Bassily, Vitaly Feldman, Kunal Talwar, and Abhradeep Thakurta. Private stochastic convex optimization with optimal rates. InAdvances in Neural Information Processing Systems 32 (NeurIPS), 2019
work page 2019
-
[9]
Concentrated differential privacy: Simplifications, extensions, and lower bounds
Mark Bun and Thomas Steinke. Concentrated differential privacy: Simplifications, extensions, and lower bounds. InTheory of Cryptography Conference (TCC), pages 635–658, 2016
work page 2016
-
[10]
Linear models of dissipation whose q is almost frequency independent—ii
Michele Caputo. Linear models of dissipation whose q is almost frequency independent—ii. Geophysical Journal International, 13(5):529–539, 1967
work page 1967
-
[11]
Kamalika Chaudhuri, Claire Monteleoni, and Anand D. Sarwate. Differentially private empirical risk minimization.Journal of Machine Learning Research, 12:1069–1109, 2011
work page 2011
- [12]
-
[13]
Jinshuo Dong, Aaron Roth, and Weijie J. Su. Gaussian differential privacy.Journal of the Royal Statistical Society: Series B, 84(1):3–37, 2022
work page 2022
-
[14]
Cynthia Dwork and Aaron Roth.The Algorithmic Foundations of Differential Privacy. Now Publishers, 2014
work page 2014
-
[15]
Calibrating noise to sensitivity in private data analysis
Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam Smith. Calibrating noise to sensitivity in private data analysis. InTheory of Cryptography Conference (TCC), pages 265–284, 2006
work page 2006
-
[16]
Individual privacy accounting via a rényi filter
Vitaly Feldman and Tijana Zrnic. Individual privacy accounting via a rényi filter. InAdvances in Neural Information Processing Systems 34 (NeurIPS), pages 15798–15810, 2021
work page 2021
-
[17]
Brendan McMahan, Shuang Song, Om Thakkar, Abhradeep Thakurta, and Zheng Xu
Peter Kairouz, H. Brendan McMahan, Shuang Song, Om Thakkar, Abhradeep Thakurta, and Zheng Xu. Practical and private (deep) learning without sampling or shuffling. InProceedings of the 38th International Conference on Machine Learning (ICML), pages 5213–5225, 2021
work page 2021
-
[18]
Lee, Kobbi Nissim, Sofya Raskhodnikova, and Adam Smith
Shiva Prasad Kasiviswanathan, Homin K. Lee, Kobbi Nissim, Sofya Raskhodnikova, and Adam Smith. What can we learn privately?SIAM Journal on Computing, 40(3):793–826, 2011
work page 2011
-
[19]
Anatoly A. Kilbas, Hari M. Srivastava, and Juan J. Trujillo.Theory and Applications of Fractional Differential Equations. Elsevier, 2006
work page 2006
- [20]
-
[21]
Brendan McMahan, Daniel Ramage, Kunal Talwar, and Li Zhang
H. Brendan McMahan, Daniel Ramage, Kunal Talwar, and Li Zhang. Learning differentially private recurrent language models. InInternational Conference on Learning Representations (ICLR), 2018. 10
work page 2018
-
[22]
Kenneth S. Miller and Bertram Ross.An Introduction to the Fractional Calculus and Fractional Differential Equations. Wiley, 1993
work page 1993
-
[23]
Ilya Mironov. Rényi differential privacy. In2017 IEEE 30th Computer Security Foundations Symposium (CSF), pages 263–275. IEEE, 2017. doi: 10.1109/CSF.2017.11
-
[24]
Keith B. Oldham and Jerome Spanier.The Fractional Calculus: Theory and Applications of Differentiation and Integration to Arbitrary Order. Academic Press, 1974
work page 1974
-
[25]
Semi- supervised knowledge transfer for deep learning from private training data
Nicolas Papernot, Martín Abadi, Úlfar Erlingsson, Ian Goodfellow, and Kunal Talwar. Semi- supervised knowledge transfer for deep learning from private training data. InInternational Conference on Learning Representations (ICLR), 2017
work page 2017
-
[26]
Scalable private learning with PATE
Nicolas Papernot, Shuang Song, Ilya Mironov, Ananth Raghunathan, Kunal Talwar, and Úlfar Erlingsson. Scalable private learning with PATE. InInternational Conference on Learning Representations (ICLR), 2018
work page 2018
-
[27]
Differentially private sharpness-aware training
Jongjin Park et al. Differentially private sharpness-aware training. InInternational Conference on Machine Learning (ICML), 2023
work page 2023
-
[28]
NhatHai Phan, Xiaoqian Wu, and Dejing Dou. Preserving differential privacy in convolutional deep belief networks.Machine Learning, 106:1681–1704, 2017
work page 2017
-
[29]
Igor Podlubny.Fractional Differential Equations. Academic Press, 1998
work page 1998
-
[30]
Stefan G. Samko, Anatoly A. Kilbas, and Oleg I. Marichev.Fractional Integrals and Derivatives: Theory and Applications. Gordon and Breach, 1993
work page 1993
-
[31]
Convolutional neural networks with fractional order gradient method.Neurocomputing, 408:19–29, 2020
Dongming Sheng, Yongguang Wei, YangQuan Chen, and Yuesheng Wang. Convolutional neural networks with fractional order gradient method.Neurocomputing, 408:19–29, 2020
work page 2020
-
[32]
Shuang Song, Kamalika Chaudhuri, and Anand D. Sarwate. Stochastic gradient descent with differentially private updates. In2013 IEEE Global Conference on Signal and Information Processing (GlobalSIP), pages 245–248, 2013
work page 2013
-
[33]
DP-AdamBC: Your DP-Adam is actually DP-SGD (unless you apply bias correction)
Qingyuan Tang, Fedor Shpilevskiy, and Mathias Lécuyer. DP-AdamBC: Your DP-Adam is actually DP-SGD (unless you apply bias correction). InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, 2024
work page 2024
-
[34]
Subsampled rényi differential privacy and analytical moments accountant
Yu-Xiang Wang, Borja Balle, and Shiva Prasad Kasiviswanathan. Subsampled rényi differential privacy and analytical moments accountant. InProceedings of the 22nd International Conference on Artificial Intelligence and Statistics (AISTATS), volume 89 ofProceedings of Machine Learning Research, pages 1226–1235, 2019
work page 2019
-
[35]
Dpis: An enhanced mechanism for differentially private sgd with importance sampling
Jianxin Wei, Ergute Bao, Xiaokui Xiao, and Yin Yang. Dpis: An enhanced mechanism for differentially private sgd with importance sampling. InProceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, pages 2885–2899, 2022. doi: 10.1145/3548606.3560562
-
[36]
Design of generalized fractional order gradient descent method.arXiv preprint arXiv:1901.05294, 2018
Yongguang Wei, Yuqing Kang, Weijie Yin, and Yuesheng Wang. Design of generalized fractional order gradient descent method.arXiv preprint arXiv:1901.05294, 2018
-
[37]
R. Yang. DP-Adam-AC: Privacy-preserving fine-tuning of localizable language models using adam optimization with adaptive clipping.arXiv preprint arXiv:2510.05288, 2025. 11 Appendix Overview This appendix provides additional experimental evidence and theoretical analysis supporting the main paper. To improve readability and navigation, the supplementary ma...
-
[38]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board approvals, or an equivalent approval/review based on the requirements of your country or instit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.