Recognition: no theorem link
Adversarial Attacks Against MLLMs via Progressive Resolution Processing and Adaptive Feature Alignment
Pith reviewed 2026-05-12 04:15 UTC · model grok-4.3
The pith
Progressive resolution processing and adaptive feature alignment enable more transferable targeted attacks against black-box multimodal large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that its Progressive Resolution Processing and Adaptive Feature Alignment strategy produces adversarial examples with higher transfer success rates by starting optimization at low resolutions and increasing detail while using gradient consistency to pick intermediate layers from an ensemble of surrogate models for alignment, along with patch filtering to focus on correlated regions, resulting in better performance against both open and closed source multimodal large language models compared to previous targeted attack methods.
What carries the argument
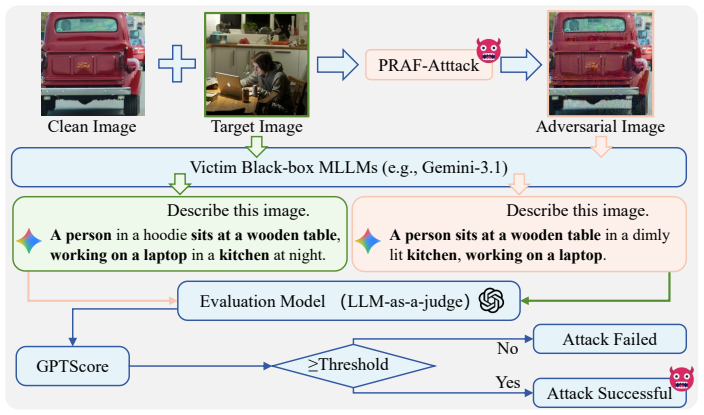
Progressive Resolution Processing and Adaptive Feature Alignment (PRAF-Attack), which uses gradient consistency across surrogate ensembles to select transferable intermediate layers and gradually refines optimization from coarse to fine image resolutions.
If this is right
- The method achieves higher transfer success than seven state-of-the-art targeted attack baselines on six open-source and six closed-source models.
- Progressive refinement from coarse to fine resolutions allows better exploitation of target information at multiple scales.
- Adaptive selection of intermediate layers and patch filtering produces more robust local alignments than final-layer global feature matching alone.
- The attack reduces dependence on fixed original-resolution target crops during optimization.
Where Pith is reading between the lines
- The emphasis on intermediate-layer consistency suggests that transferable attack signals are spread through the vision encoder hierarchy rather than limited to final outputs.
- Similar multi-scale refinement could be applied to evaluate robustness in other vision-language tasks beyond classification.
- Model developers may need to consider regularizing features at multiple depths to limit the effectiveness of cross-model attacks.
Load-bearing premise
That gradient consistency across surrogate models reliably identifies intermediate layers whose features transfer to unseen black-box multimodal large language models without the selection overfitting to the chosen surrogates.
What would settle it
Testing the generated adversarial examples on a fresh set of multimodal large language models not involved in surrogate training or layer selection and checking whether success rates still exceed those of the seven baseline methods.
Figures













read the original abstract
Adversarial perturbations can mislead Multimodal Large Language Models (MLLMs) recognize a benign image as a specific target object, posing serious risks in safety-critical scenarios such as autonomous driving and medical diagnosis. This makes transfer-based targeted attacks crucial for understanding and improving black-box MLLM robustness. Existing transfer-based targeted attack methods typically rely on the final global features of the surrogate encoder and anchor optimization to original-resolution target crops, leading to their limited transferability and robustness. To address these challenges, we propose Progressive Resolution Processing and Adaptive Feature Alignment (PRAF-Attack), a targeted transfer-based attack framework that integrates multi-scale global semantic guidance with robust intermediate-layer local alignment. Unlike prior methods that align only the surrogate encoder's final layer, we design an adaptive feature alignment strategy that leverages intermediate representations to enhance transferability. Specifically, we introduce an adaptive intermediate layer selection mechanism to identify transferable hierarchical features across surrogate ensembles via gradient consistency, along with an adaptive patch-level optimization strategy that preserves highly correlated local regions through efficient patch filtering. To overcome the reliance on fixed original-resolution target crops, we propose a progressive resolution processing strategy that gradually refines optimization from coarse to fine, enabling the attack to better exploit target information at multiple scales and achieve stronger transferability. We evaluate PRAF-Attack on a diverse suite of black-box MLLMs, including six open-source models and six closed-source commercial APIs. Compared with seven state-of-the-art targeted attack baselines, the proposed PRAF-Attack consistently achieves superior transferability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PRAF-Attack, a targeted transfer-based adversarial attack framework for Multimodal Large Language Models (MLLMs). It integrates progressive resolution processing (coarse-to-fine optimization across scales) with adaptive feature alignment that selects intermediate layers via gradient consistency across surrogate ensembles and applies patch-level filtering for local alignment. The central claim is that this yields consistently superior transferability to seven state-of-the-art baselines when evaluated on six open-source MLLMs and six closed-source commercial APIs.
Significance. If the reported gains survive rigorous ablation and statistical controls, the work would usefully advance empirical understanding of MLLM robustness by showing that multi-scale progressive optimization and adaptive intermediate-layer alignment can improve black-box transfer over final-layer-only baselines. The breadth of evaluation (open- and closed-source targets) is a positive feature.
major comments (2)
- [Method (adaptive intermediate layer selection and feature alignment)] The adaptive intermediate-layer selection mechanism (gradient consistency across surrogates) is load-bearing for the transferability claim. The manuscript does not describe any held-out validation procedure (e.g., layer selection performed on a subset of surrogates and transfer tested on the remaining surrogates or on a separate validation set of black-box models). Without this, it remains possible that the selected layers capture surrogate-specific correlations rather than universally transferable hierarchical features.
- [Experiments and results] The abstract and experimental section assert consistent superiority over seven baselines, yet no ablation results isolating the contribution of progressive resolution processing versus adaptive alignment are referenced, nor are statistical controls (confidence intervals, multiple random seeds, or significance tests) reported for the transfer success rates. This makes it impossible to determine whether the observed gains exceed what could arise from hyper-parameter tuning or surrogate choice.
minor comments (2)
- [Method] Notation for the gradient-consistency metric and the patch-filtering threshold should be defined explicitly with equations rather than prose descriptions.
- [Figures] Figure captions should state the exact transfer success metric (e.g., target-class accuracy or attack success rate) and the number of trials per model.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our work. We address the major comments point by point below. We will revise the manuscript to incorporate additional analyses and clarifications to strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Method (adaptive intermediate layer selection and feature alignment)] The adaptive intermediate-layer selection mechanism (gradient consistency across surrogates) is load-bearing for the transferability claim. The manuscript does not describe any held-out validation procedure (e.g., layer selection performed on a subset of surrogates and transfer tested on the remaining surrogates or on a separate validation set of black-box models). Without this, it remains possible that the selected layers capture surrogate-specific correlations rather than universally transferable hierarchical features.
Authors: We agree that demonstrating the generalizability of the layer selection is important. Our adaptive selection relies on gradient consistency computed across the surrogate ensemble, which is intended to highlight layers with stable, transferable signals rather than model-specific artifacts. The strong performance on a wide range of black-box targets, including commercial APIs not used in surrogate selection, provides supporting evidence. Nevertheless, to directly address this concern, we will add a held-out validation experiment in the revised manuscript, where layer selection is performed using only a subset of surrogates and transferability is evaluated on the remaining surrogates as well as the black-box models. revision: partial
-
Referee: [Experiments and results] The abstract and experimental section assert consistent superiority over seven baselines, yet no ablation results isolating the contribution of progressive resolution processing versus adaptive alignment are referenced, nor are statistical controls (confidence intervals, multiple random seeds, or significance tests) reported for the transfer success rates. This makes it impossible to determine whether the observed gains exceed what could arise from hyper-parameter tuning or surrogate choice.
Authors: We acknowledge that the current manuscript lacks explicit ablations separating the two main components and does not include statistical significance testing. In the revision, we will include comprehensive ablation studies that isolate the effects of progressive resolution processing and adaptive feature alignment. We will also rerun key experiments with multiple random seeds, report confidence intervals, and apply appropriate statistical tests (e.g., paired t-tests) to verify that the improvements are statistically significant and not due to random variation or hyperparameter choices. revision: yes
Circularity Check
No significant circularity in derivation or claims
full rationale
The paper presents an empirical engineering contribution: a targeted attack framework (PRAF-Attack) whose components—progressive resolution processing, adaptive intermediate-layer selection via gradient consistency on surrogates, and patch-level alignment—are design choices whose performance is measured by direct transfer experiments on held-out black-box MLLMs. No equations, fitted parameters, or predictions are defined in terms of the reported transferability gains themselves, and no load-bearing self-citations or uniqueness theorems are invoked to force the result. The central claim of superior transferability therefore rests on external experimental comparison rather than any self-referential reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Intermediate-layer features selected by gradient consistency transfer across MLLM architectures
- domain assumption Multi-scale progressive optimization captures transferable semantic information better than single-resolution alignment
Reference graph
Works this paper leans on
-
[1]
Minigpt-4: Enhancing vision-language under- standing with advanced large language models
Deyao Zhu, Jun Chen, Xiaoqian Shen, et al. Minigpt-4: Enhancing vision-language under- standing with advanced large language models. InInternational Conference on Learning Representations, 2024
work page 2024
-
[2]
Instructblip: Towards general-purpose vision- language models with instruction tuning
Wenliang Dai, Junnan Li, Dongxu Li, et al. Instructblip: Towards general-purpose vision- language models with instruction tuning. InAdvances in Neural Information Processing Systems, 2023
work page 2023
-
[3]
One transformer fits all distributions in multi-modal diffusion at scale
Fan Bao, Shen Nie, Kaiwen Xue, et al. One transformer fits all distributions in multi-modal diffusion at scale. InInternational Conference on Machine Learning, pages 1692–1717, 2023
work page 2023
-
[4]
Bottom-up and top-down attention for image captioning and visual question answering
Peter Anderson, Xiaodong He, Chris Buehler, et al. Bottom-up and top-down attention for image captioning and visual question answering. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6077–6086, 2018
work page 2018
-
[5]
VQA: visual question answering
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, et al. VQA: visual question answering. In IEEE International Conference on Computer Vision, pages 2425–2433, 2015
work page 2015
- [6]
-
[7]
Shiye Lei, Hao Chen, Sen Zhang, et al. Image captions are natural prompts for training data synthesis.International Journal of Computer Vision, 133(8):5435–5454, 2025
work page 2025
-
[8]
Vima: General robot manipulation with multimodal prompts
Yunfan Jiang, Agrim Gupta, Zichen Zhang, et al. Vima: General robot manipulation with multimodal prompts. InInternational Conference on Machine Learning, 2023
work page 2023
-
[9]
Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, et al. Palm-e: An embodied multimodal language model. InInternational Conference on Machine Learning, pages 8469–8488, 2023
work page 2023
-
[10]
Xiaojun Jia, Jie Liao, Qi Guo, et al. Omnisafebench-mm: A unified benchmark and toolbox for multimodal jailbreak attack-defense evaluation.arXiv preprint arXiv:2512.06589, 2025
-
[11]
Mm-safetybench: A benchmark for safety evaluation of multimodal large language models
Xin Liu, Yichen Zhu, Jindong Gu, et al. Mm-safetybench: A benchmark for safety evaluation of multimodal large language models. InEuropean Conference on Computer Vision, pages 386–403, 2024
work page 2024
-
[12]
Analyzing leakage of personally identifiable information in language models
Nils Lukas, Ahmed Salem, Robert Sim, et al. Analyzing leakage of personally identifiable information in language models. InIEEE Symposium on Security and Privacy, pages 346–363, 2023
work page 2023
-
[13]
Tiejin Chen, Pingzhi Li, Kaixiong Zhou, et al. Unveiling privacy risks in multi-modal large language models: Task-specific vulnerabilities and mitigation challenges. InFindings of the Association for Computational Linguistics, pages 4573–4586, 2025
work page 2025
-
[14]
Tianrui Guan, Fuxiao Liu, Xiyang Wu, et al. Hallusionbench: An advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14375–14385, 2024
work page 2024
-
[15]
Daizong Liu, Mingyu Yang, Xiaoye Qu, et al. A survey of attacks on large vision-language models: Resources, advances, and future trends.IEEE Transactions on Neural Networks and Learning Systems, 36(11):19525–19545, 2025
work page 2025
-
[16]
On evaluating adversarial robustness of large vision-language models
Yunqing Zhao, Tianyu Pang, Chao Du, et al. On evaluating adversarial robustness of large vision-language models. InAdvances in Neural Information Processing Systems, volume 36, pages 54111–54138, 2023
work page 2023
-
[17]
Ziang Guo, Zakhar Yagudin, Artem Lykov, et al. Vlm-auto: Vlm-based autonomous driving assistant with human-like behavior and understanding for complex road scenes. InInternational Conference on F oundation and Large Language Models, pages 501–507, 2024
work page 2024
-
[18]
Erfei Cui, Wenhai Wang, Zhiqi Li, et al. Drivemlm: aligning multi-modal large language models with behavioral planning states for autonomous driving.Visual Intelligence, 3(1), 2025
work page 2025
-
[19]
Mihalj Bakator and Dragica Radosav. Deep learning and medical diagnosis: A review of literature.Multimodal Technologies and Interaction, 2(3):47, 2018. 10
work page 2018
-
[20]
Peng Xie, Yequan Bie, Jianda Mao, et al. Chain of attack: On the robustness of vision-language models against transfer-based adversarial attacks. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14679–14689, 2025
work page 2025
-
[21]
Anyattack: Towards large-scale self-supervised adversarial attacks on vision-language models
Jiaming Zhang, Junhong Ye, Xingjun Ma, et al. Anyattack: Towards large-scale self-supervised adversarial attacks on vision-language models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19900–19909, 2025
work page 2025
-
[22]
Qi Guo, Shanmin Pang, Xiaojun Jia, et al. Efficient generation of targeted and transferable adversarial examples for vision-language models via diffusion models.IEEE Transactions on Information F orensics and Security, 20:1333–1348, 2025
work page 2025
-
[23]
Zhaoyi Li, Xiaohan Zhao, Dong-Dong Wu, et al. A frustratingly simple yet highly effective attack baseline: Over 90% success rate against the strong black-box models of gpt-4.5/4o/o1. arXiv preprint arXiv:2503.10635, 2025
-
[24]
Xiaohan Zhao, Zhaoyi Li, Yaxin Luo, et al. Pushing the frontier of black-box LVLM attacks via fine-grained detail targeting.arXiv preprint arXiv:2602.17645, 2026
-
[25]
Yuanbo Li, Tianyang Xu, Cong Hu, et al. Multi-paradigm collaborative adversarial attack against multi-modal large language models.arXiv preprint arXiv:2603.04846, 2026
-
[26]
Xiaojun Jia, Sensen Gao, Simeng Qin, et al. Adversarial attacks against closed-source mllms via feature optimal alignment.arXiv preprint arXiv:2505.21494, 2025
-
[27]
Junnan Li, Dongxu Li, Silvio Savarese, et al. BLIP-2: bootstrapping language-image pre- training with frozen image encoders and large language models. InInternational Conference on Machine Learning, pages 19730–19742, 2023
work page 2023
-
[28]
Haotian Liu, Chunyuan Li, Qingyang Wu, et al. Visual instruction tuning. InAdvances in Neural Information Processing Systems, 2023
work page 2023
-
[29]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Josh Achiam, Steven Adler, Sandhini Agarwal, et al. GPT-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, et al. Gemini: A family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Goodfellow, Jonathon Shlens, and Christian Szegedy
Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adver- sarial examples. InInternational Conference on Learning Representations, 2015
work page 2015
-
[33]
Towards deep learning models resistant to adversarial attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, et al. Towards deep learning models resistant to adversarial attacks. InInternational Conference on Learning Representations, 2018
work page 2018
-
[34]
Towards evaluating the robustness of neural networks
Nicholas Carlini and David Wagner. Towards evaluating the robustness of neural networks. In IEEE Symposium on Security and Privacy, pages 39–57, 2017
work page 2017
-
[35]
Boosting adversarial transferability through aug- mentation in hypothesis space
Yu Guo, Weiquan Liu, Qingshan Xu, et al. Boosting adversarial transferability through aug- mentation in hypothesis space. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19175–19185, 2025
work page 2025
-
[36]
Improving transferability of adversarial examples with input diversity
Cihang Xie, Zhishuai Zhang, Yuyin Zhou, et al. Improving transferability of adversarial examples with input diversity. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2730–2739, 2019
work page 2019
-
[37]
Transferable multimodal attack on vision-language pre-training models
Haodi Wang, Kai Dong, Zhilei Zhu, et al. Transferable multimodal attack on vision-language pre-training models. InIEEE Symposium on Security and Privacy, pages 1722–1740, 2024
work page 2024
-
[38]
On the robustness of large multimodal models against image adversarial attacks
Xuanming Cui, Alejandro Aparcedo, Young Kyun Jang, et al. On the robustness of large multimodal models against image adversarial attacks. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24625–24634, 2024
work page 2024
-
[39]
Yubo Wang, Chaohu Liu, Yanqiu Qu, et al. Break the visual perception: Adversarial attacks tar- geting encoded visual tokens of large vision-language models. InACM International Conference on Multimedia, pages 1072–1081, 2024
work page 2024
-
[40]
Haobo Wang, Weiqi Luo, Xiaohua Xie, et al. Adv-inversion: Stealthy adversarial attacks via gan-inversion for facial privacy protection.IEEE Transactions on Information F orensics and Security, 20:11892–11906, 2025. 11
work page 2025
-
[41]
Admix: Enhancing the transferability of adversarial attacks
Xiaosen Wang, Xuanran He, Jingdong Wang, et al. Admix: Enhancing the transferability of adversarial attacks. InIEEE/CVF International Conference on Computer Vision, pages 16138–16147, 2021
work page 2021
-
[42]
Alexey Kurakin, Ian J. Goodfellow, and Samy Bengio. Adversarial examples in the physical world. InInternational Conference on Learning Representations, 2017
work page 2017
-
[43]
Towards adversarial attack on vision-language pre- training models
Jiaming Zhang, Qi Yi, and Jitao Sang. Towards adversarial attack on vision-language pre- training models. InACM International Conference on Multimedia, pages 5005–5013, 2022
work page 2022
-
[44]
Dong Lu, Zhiqiang Wang, Teng Wang, et al. Set-level guidance attack: Boosting adversarial transferability of vision-language pre-training models. InIEEE/CVF International Conference on Computer Vision, pages 102–111, 2023
work page 2023
-
[45]
Hao Fang, Jiawei Kong, Wenbo Yu, et al. One perturbation is enough: On generating uni- versal adversarial perturbations against vision-language pre-training models. InIEEE/CVF International Conference on Computer Vision, pages 4090–4100, 2025
work page 2025
-
[46]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, et al. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning, pages 8748–8763, 2021
work page 2021
-
[47]
URL https://nips.cc/Conferences/2017/ CompetitionTrack
NIPS 2017 Competition Track, 2017. URL https://nips.cc/Conferences/2017/ CompetitionTrack
work page 2017
-
[48]
Microsoft COCO: common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, et al. Microsoft COCO: common objects in context. InEuropean Conference on Computer Vision, pages 740–755, 2014
work page 2014
-
[49]
Vlmevalkit: An open-source toolkit for evaluating large multi-modality models
Haodong Duan, Junming Yang, Yuxuan Qiao, et al. Vlmevalkit: An open-source toolkit for evaluating large multi-modality models. InACM International Conference on Multimedia, pages 11198–11201, 2024
work page 2024
-
[50]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, et al. Dinov2: Learning robust visual features without supervision.Transactions on Machine Learning Research, 2024
work page 2024
-
[51]
Gintare Karolina Dziugaite, Zoubin Ghahramani, and Daniel M. Roy. A study of the effect of JPG compression on adversarial images.arXiv preprint arXiv:1608.00853, 2016
work page Pith review arXiv 2016
-
[52]
Diffusion models for adversarial purification
Weili Nie, Brandon Guo, Yujia Huang, et al. Diffusion models for adversarial purification. In International Conference on Machine Learning, pages 16805–16827, 2022. 12 A Evaluation Prompt for LLM-as-a-Judge As illustrated in the overall pipeline of our framework, we employ an LLM-as-a-judge mechanism to quantitatively evaluate the targeted transferability...
work page 2022
-
[53]
**Main Subject Consistency:** If both descriptions refer to the same key subject or object (e.g., a person, food, an event), they should receive a higher similarity score
-
[54]
**Relevant Description:** If the descriptions are related to the same context or topic, they should also contribute to a higher similarity score
-
[55]
Focus on **whether both descriptions fundamentally describe the same thing.**
**Ignore Fine-Grained Details:** Do not penalize differences in **phrasing, sentence struc- ture, or minor variations in detail**. Focus on **whether both descriptions fundamentally describe the same thing.**
-
[56]
**Partial Matches:** If one description contains extra information but does not contradict the other, they should still have a high similarity score
-
[57]
**Similarity Score Range:** • **1.0**: Nearly identical in meaning. • **0.8-0.9**: Same subject, with highly related descriptions. • **0.7-0.8**: Same subject, core meaning aligned, even if some details differ. • **0.5-0.7**: Same subject but different perspectives or missing details. • **0.3-0.5**: Related but not highly similar (same general theme but d...
work page 1998
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.