Recognition: no theorem link
The Observable Wasserstein Distance
Pith reviewed 2026-05-12 04:22 UTC · model grok-4.3
The pith
Observable Wasserstein distances recover the true distance uniquely once the hierarchy order exceeds the metric covering dimension of the support.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We define the observable Wasserstein distance by restricting to 1-Lipschitz observables from the Polish metric space to the real line, pushing measures forward, and computing the Wasserstein distance on the resulting real-line distributions. A hierarchy of pseudo-metrics is obtained from a nested chain of observable subspaces. We establish an injectivity theorem that ties the metric covering dimension of the support to the minimal order guaranteeing unique recovery of the measure from its observable distances.
What carries the argument
Nested hierarchy of subspaces of 1-Lipschitz observables inducing pushforward Wasserstein pseudo-metrics that sharpen with each level.
If this is right
- The observable distance is always a lower bound on the true Wasserstein distance at every level of the hierarchy.
- Higher orders in the hierarchy produce strictly sharper lower bounds while remaining computable.
- For any measure with finite metric covering dimension, there exists a finite hierarchy order at which the observable distance equals the true Wasserstein distance.
- A discrete computational model exists for evaluating the hierarchy on finite grids.
- Numerical tests confirm that the approximations remain effective across different metric spaces and dataset sizes.
Where Pith is reading between the lines
- The same projection hierarchy may supply dimension-aware lower bounds for other optimal-transport quantities beyond Wasserstein distance.
- When data supports are known to lie on low-dimensional subsets, the method supplies a dimension-dependent stopping rule for how many observables to include.
- Adaptive selection of observables guided by local covering-dimension estimates could further reduce computation while preserving the injectivity guarantee.
Load-bearing premise
The chosen nested family of 1-Lipschitz observables must be rich enough relative to the covering dimension of the support so that the projections distinguish measures at some finite order.
What would settle it
Two distinct probability measures whose supports have the same finite covering dimension d but whose observable Wasserstein distances remain strictly less than the true Wasserstein distance at every hierarchy order predicted to guarantee injectivity.
Figures

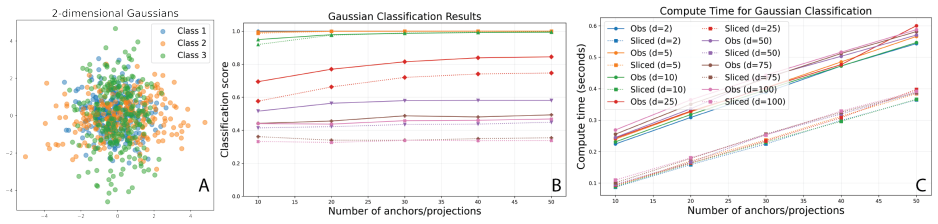
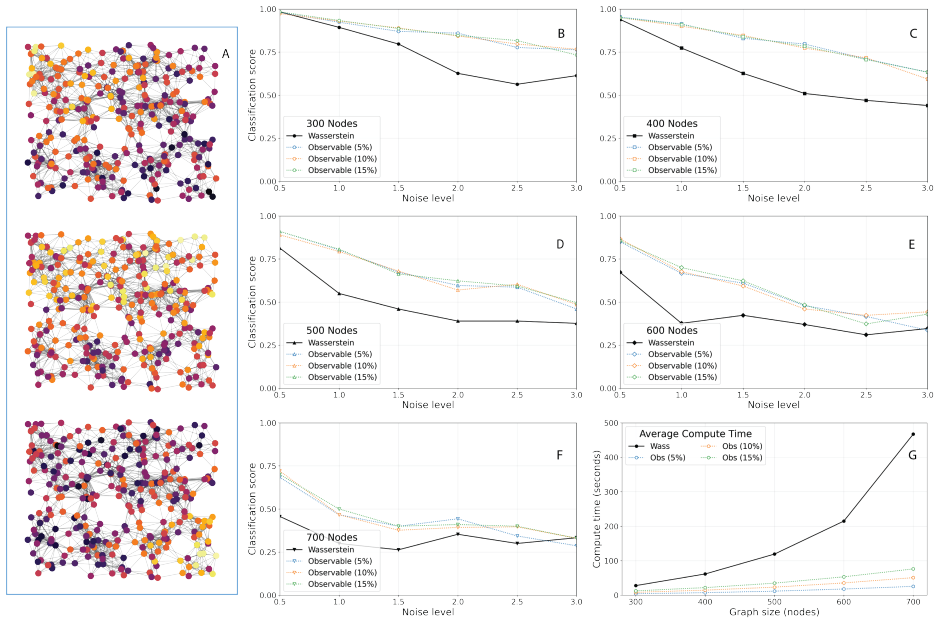
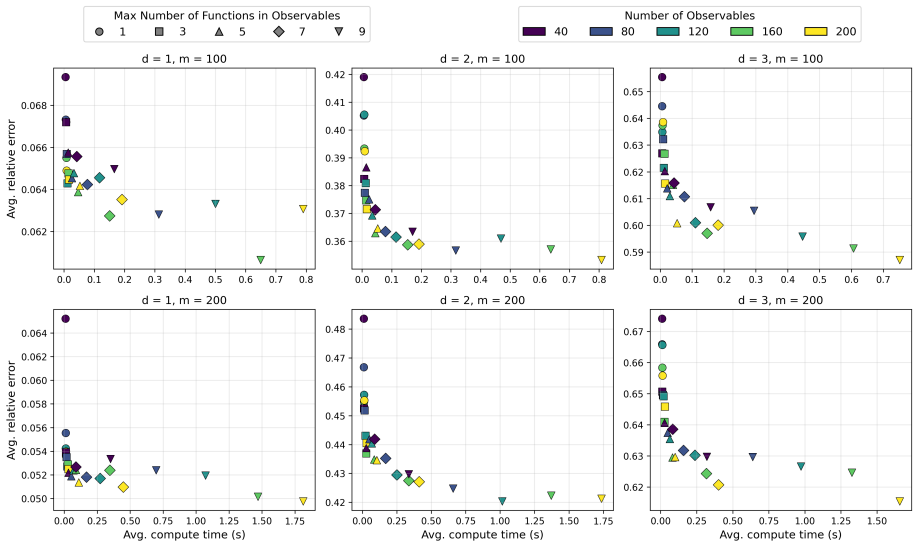
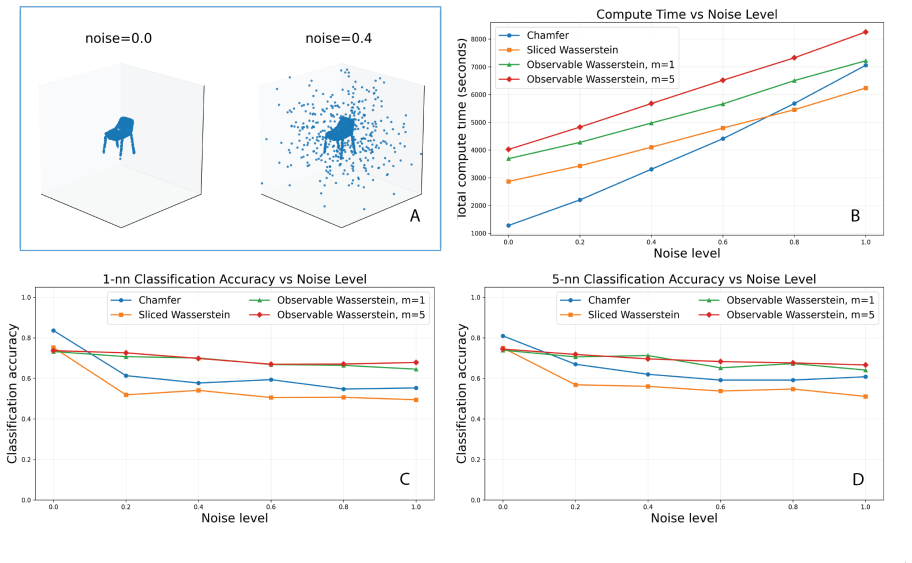


read the original abstract
We introduce the observable Wasserstein distance, a framework for deriving lower bounds on the Wasserstein distance between probability measures on Polish metric spaces, designed to bypass the computational intractability of exact optimal transport in large-scale, non-Euclidean datasets. Analogous to the sliced Wasserstein distance in $\mathbb{R}^d$, our approach projects measures onto the real line via 1-Lipschitz observables and computes the Wasserstein distances between the resulting pushforward distributions. We define a hierarchy of pseudo-metrics by restricting observables to a nested chain of subspaces. A central theoretical contribution is an injectivity result linking the metric covering dimension of the support of a measure to the specific order in the hierarchy that guarantees unique recovery. This serves as a metric-space analogue to the Cram\'{e}r-Wold Device for Euclidean distributions. We demonstrate that this hierarchy offers a tunable trade-off between sharpness as a lower bound on the Wasserstein distance and computational efficiency. We also present a discrete computational model for finite grids and numerical experiments validating the efficacy and utility of these approximations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the observable Wasserstein distance, a pseudo-metric on probability measures supported on Polish metric spaces obtained by pushing forward via 1-Lipschitz observables to the real line and taking the 1-Wasserstein distance of the resulting measures on R. A nested hierarchy of observable subspaces is defined, and the central result is an injectivity theorem asserting that if the metric covering dimension of the support is finite, then sufficiently high levels of the hierarchy separate measures (a metric-space analogue of the Cramér-Wold theorem). The work also supplies a discrete computational scheme on finite grids together with numerical illustrations of the trade-off between approximation quality and cost.
Significance. If the injectivity theorem is correct, the construction supplies a dimension-dependent, computationally scalable family of lower bounds for Wasserstein distances that extends sliced-Wasserstein ideas beyond Euclidean space while retaining a clear theoretical guarantee. The link between covering dimension and the required hierarchy depth is a substantive contribution to the interface of optimal transport and dimension theory; the discrete model further indicates practical utility for large non-Euclidean data sets.
major comments (2)
- §3, Theorem 3.4 (injectivity): the argument that the k-th level of the observable hierarchy separates measures whenever the covering dimension is at most k relies on a density claim for 1-Lipschitz functions; the manuscript does not supply the explicit approximation argument or address whether the nested subspaces remain sufficiently rich after restriction to a given Polish space, which is load-bearing for the uniqueness statement.
- §5, numerical validation: the discrete model on finite grids is described, yet no quantitative comparison (e.g., relative error versus exact W1 on small instances or convergence rates as grid size grows) is reported; without such controls the claim that the hierarchy furnishes a tunable lower bound cannot be assessed from the experiments alone.
minor comments (3)
- The introduction cites sliced Wasserstein but omits several recent works on projection-based OT distances in metric spaces; adding these references would clarify the precise novelty.
- Notation for the observable subspaces (e.g., the indexing of the nested chain) is introduced without a compact summary table; a small diagram or table in §2 would improve readability.
- A few typographical inconsistencies appear in the statement of the Kantorovich–Rubinstein duality used for the full 1-Lipschitz case; these are minor but should be aligned with standard references.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on our manuscript. We address each major comment below and describe the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: §3, Theorem 3.4 (injectivity): the argument that the k-th level of the observable hierarchy separates measures whenever the covering dimension is at most k relies on a density claim for 1-Lipschitz functions; the manuscript does not supply the explicit approximation argument or address whether the nested subspaces remain sufficiently rich after restriction to a given Polish space, which is load-bearing for the uniqueness statement.
Authors: We agree that the proof of Theorem 3.4 would be strengthened by an explicit approximation argument. In the revised manuscript we will add a detailed lemma (with proof) establishing that 1-Lipschitz functions are dense in the relevant sense on the support of any probability measure on a Polish metric space, and we will verify that the nested observable subspaces remain sufficiently rich after restriction to this support. This addition will be placed in an appendix or expanded section of §3 so that the injectivity statement is fully justified. revision: yes
-
Referee: §5, numerical validation: the discrete model on finite grids is described, yet no quantitative comparison (e.g., relative error versus exact W1 on small instances or convergence rates as grid size grows) is reported; without such controls the claim that the hierarchy furnishes a tunable lower bound cannot be assessed from the experiments alone.
Authors: We accept this observation. In the revised version of §5 we will augment the numerical experiments with quantitative controls: on small grids where exact W1 is computable we will report relative errors between the observable distances and the true W1; we will also include plots and tables showing the observed convergence behavior as grid resolution increases. These additions will make the trade-off between approximation quality and cost explicit and allow readers to assess the practical utility of the hierarchy. revision: yes
Circularity Check
No significant circularity; new distance and injectivity result are independently derived
full rationale
The paper introduces the observable Wasserstein distance as a new pseudo-metric constructed from pushforwards under 1-Lipschitz observables, then defines a nested hierarchy of such pseudo-metrics. The central injectivity theorem links the order in this hierarchy to the metric covering dimension of the measure support, serving as a metric-space version of the Cramér-Wold theorem. This derivation relies on standard facts from optimal transport (Kantorovich-Rubinstein duality) and metric dimension theory without reducing any claimed prediction or uniqueness result to a fitted parameter, self-referential definition, or load-bearing self-citation. The construction is self-contained against external benchmarks and does not rename known empirical patterns as novel unifications.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math The underlying space is a Polish metric space (complete separable metric space).
- domain assumption 1-Lipschitz observables exist and can be restricted to nested subspaces.
invented entities (1)
-
Observable Wasserstein distance
no independent evidence
Reference graph
Works this paper leans on
-
[1]
P. Achlioptas, O. Diamanti, I. Mitliagkas, and L. Guibas. Learning representations and gen- erative models for 3D point clouds. InInternational Conference on Machine Learning, pages 40–49. PMLR, 2018
work page 2018
- [2]
- [3]
-
[4]
E. Bayraktar and G. Guo. Strong equivalence between metrics of Wasserstein type.Electronic Communications in Probability, 26, 2021
work page 2021
-
[5]
N. Bonneel, M. van de Panne, S. Paris, and W. Heidrich. Sliced Wasserstein discrepancies for color transfer and image comparison. InIEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1085–1092. IEEE, 2013
work page 2013
-
[6]
Bonnotte.Unidimensional and evolution methods for optimal transportation
N. Bonnotte.Unidimensional and evolution methods for optimal transportation. PhD thesis, Universit´ e Paris Sud-Paris XI; Scuola normale superiore (Pise, Italie), 2013
work page 2013
- [7]
-
[8]
G. Carlier, A. Figalli, Q. M´ erigot, and Y. Wang. Sharp comparisons between sliced and standard 1-Wasserstein distances.arXiv:2510.16465, 2025
-
[9]
P. Cl´ ement and W. Desch. An elementary proof of the triangle inequality for the Wasserstein metric.Proceedings of the American Mathematical Society, 136(1):295–302, 2008
work page 2008
-
[10]
H. Cram´ er and H. Wold. Some theorems on distribution functions.Journal of the London Mathematical Society, 11(4):290–294, 1936
work page 1936
-
[11]
M. Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport. InAdvances in Neural Information Processing Systems 26, pages 2292–2300. Curran Associates, Inc., 2013. 27
work page 2013
-
[12]
H. Deng, T. Birdal, and S. Ilic. PPF-Foldnet: Unsupervised learning of rotation invariant 3D local descriptors. InProceedings of the European Conference on Computer Vision (ECCV), pages 602–618, 2018
work page 2018
-
[13]
C. Duan, S. Chen, and J. Kovacevic. 3D point cloud denoising via deep neural network based local surface estimation. InICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 8553–8557. IEEE, 2019
work page 2019
-
[14]
R. M. Dudley. Weak convergence of probabilities on nonseparable metric spaces and empirical measures on Euclidean spaces.Illinois Journal of Mathematics, 10(1):109–126, 1966
work page 1966
-
[15]
R. M. Dudley. Speeds of convergence of the multidimensional central limit theorem.Annals of Mathematical Statistics, 40(3):1041–1059, 1968
work page 1968
-
[16]
R. M. Dudley.Real Analysis and Probability, volume 74 ofCambridge Studies in Advanced Mathematics. Cambridge University Press, Cambridge, UK, revised edition, 2002
work page 2002
-
[17]
H. Fan, H. Su, and L. J. Guibas. A point set generation network for 3D object reconstruction from a single image. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 605–613, 2017
work page 2017
-
[18]
R. Fortet and E. Mourier. Contribution ` a la th´ eorie des variables al´ eatoires.Journal de Math´ ematiques Pures et Appliqu´ ees, 32:1–119, 1953
work page 1953
-
[19]
M. G´ omez, G. Ma, T. Needham, and B. Wang. Metrics for parametric families of networks. arXiv preprint arXiv:2509.22549, 2025
-
[20]
R. L. Graham, D. E. Knuth, and O. Patashnik.Concrete Mathematics: A Foundation for Computer Science. Addison-Wesley, Reading, MA, 2nd edition, 1994
work page 1994
-
[21]
A. Hagberg, P. J. Swart, and D. A. Schult. Exploring network structure, dynamics, and function using NetworkX. Technical report, Los Alamos National Laboratory (LANL), 2007
work page 2007
-
[22]
P. Hermosilla, T. Ritschel, and T. Ropinski. Total denoising: Unsupervised learning of 3D point cloud cleaning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 52–60, 2019
work page 2019
-
[23]
L. V. Kantorovich. On the translocation of masses.Doklady Akademii Nauk SSSR, 37:199–201,
-
[24]
Translated in: Management Science, 5(1), 1–4, 1958
work page 1958
-
[25]
T. Lin, N. Ho, and M. Jordan. On the efficiency of low-rank optimal transport. InAdvances in Neural Information Processing Systems 32, pages 10866–10876. Curran Associates, Inc., 2019
work page 2019
-
[26]
T. Lin, Z. Zheng, E. Chen, M. Cuturi, and M. I. Jordan. On projection robust optimal transport: Sample complexity and model misspecification. InInternational Conference on Artificial Intelligence and Statistics, pages 262–270. PMLR, 2021
work page 2021
- [27]
-
[28]
Monge.M´ emoire sur la th´ eorie des d´ eblais et des remblais
G. Monge.M´ emoire sur la th´ eorie des d´ eblais et des remblais. Histoire de l’Acad´ emie Royale des Sciences de Paris. Imprimerie Royale, Paris, 1781. English translation available in:Math- ematics and the Physical World, J. Morris, 1959, orOptimal Transport: Old and New, Villani, 2009 (Appendix). 28
work page 1959
-
[29]
T. Nguyen, Q.-H. Pham, T. Le, T. Pham, N. Ho, and B.-S. Hua. Point-set distances for learning representations of 3D point clouds. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10478–10487, 2021
work page 2021
-
[30]
S. Nietert, Z. Goldfeld, and R. Cummings. Outlier-robust optimal transport: Duality, struc- ture, and statistical analysis. InInternational Conference on Artificial Intelligence and Statis- tics, pages 11691–11719. PMLR, 2022
work page 2022
-
[31]
S. Nietert, Z. Goldfeld, R. Sadhu, and K. Kato. Statistical, robustness, and computational guarantees for sliced wasserstein distances.Advances in Neural Information Processing Sys- tems, 35:28179–28193, 2022
work page 2022
-
[32]
Penrose.Random Geometric Graphs, volume 5 ofOxford Studies in Probability
M. Penrose.Random Geometric Graphs, volume 5 ofOxford Studies in Probability. Oxford University Press, Oxford, UK, 2003
work page 2003
-
[33]
C. R. Qi, H. Su, K. Mo, and L. J. Guibas. Pointnet: Deep learning on point sets for 3D classification and segmentation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 652–660, 2017
work page 2017
- [34]
-
[35]
M. I. Rubinstein. On the translocation of masses.Doklady Akademii Nauk SSSR, 122:212–215, 1958
work page 1958
-
[36]
M. Scetbon, M. Cuturi, and G. Peyr´ e. Low-rank entropic optimal transport. InInternational Conference on Machine Learning, pages 9366–9376. PMLR, 2021
work page 2021
-
[37]
Villani.Optimal Transport: Old and New, volume 338 ofGrundlehren der mathematischen Wissenschaften
C. Villani.Optimal Transport: Old and New, volume 338 ofGrundlehren der mathematischen Wissenschaften. Springer, Berlin, Heidelberg, 2009
work page 2009
-
[38]
T. Wu, L. Pan, J. Zhang, T. Wang, Z. Liu, and D. Lin. Density-aware Chamfer distance as a comprehensive metric for point cloud completion. InProceedings of the 35th International Conference on Neural Information Processing Systems, pages 29088–29100, 2021
work page 2021
-
[39]
Z. Wu, S. Song, A. Khosla, F. Yu, L. Zhang, X. Tang, and J. Xiao. 3D Shapenets: A deep representation for volumetric shapes. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1912–1920, 2015
work page 1912
-
[40]
W. Yuan, T. Khot, D. Held, C. Mertz, and M. Hebert. PCN: Point Completion Network. In 2018 International Conference on 3D Vision (3DV), pages 728–737. IEEE, 2018. 29
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.