Recognition: 2 theorem links
· Lean TheoremVerifier-Free RL for LLMs via Intrinsic Gradient-Norm Reward
Pith reviewed 2026-05-12 04:16 UTC · model grok-4.3
The pith
VIGOR assigns higher rewards to LLM completions that induce smaller teacher-forced gradient norms under the current policy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VIGOR defines an intrinsic reward for each completion as a function of the l2 norm of the teacher-forced negative-log-likelihood gradients computed under the current policy parameters, with lower norms treated as preferable signals of alignment. The reward is made practical by scaling the norm by the square root of sequence length and by applying within-group ranking across sampled completions for the same prompt.
What carries the argument
The gradient-norm reward, which ranks completions inside each prompt group by the magnitude of their teacher-forced gradient vectors and converts those ranks into shaped rewards for the RL update.
Load-bearing premise
Completions that produce smaller l2 norms of teacher-forced gradients are systematically better for policy improvement and do not produce mode collapse or reward hacking.
What would settle it
Train the same base model with VIGOR and with RLIF on identical MATH data, then compare final accuracies on held-out math and code benchmarks; reversal of the reported gains or collapse of training stability would falsify the central claim.
Figures


read the original abstract
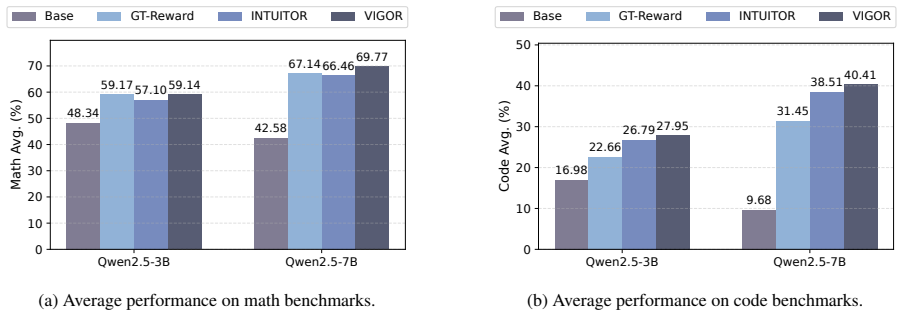
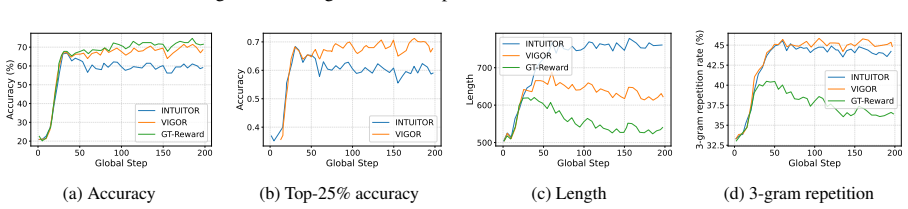
While Reinforcement Learning with Verifiable Rewards (RLVR) has recently emerged as a promising post-training paradigm for Large Language Models (LLMs), its dependency on the gold label or domain-specific verifiers limits its scalability to new tasks and domains. In this work, we propose Verifier-free Intrinsic Gradient-Norm Reward (VIGOR), a simple reward that uses only the policy model itself. Given a prompt, VIGOR samples a group of completions and assigns higher within-group rewards to outputs that induce smaller $\ell_2$ norms of the teacher-forced negative log-likelihood gradients under the current parameters. Intuitively, lower gradient norms suggest the completion aligns better with the current policy, serving as an intrinsic preference signal for policy optimization. To make this intrinsic signal practical for RL, we correct the systematic length bias of averaged token-level gradients with a $\sqrt{T}$ scaling, and apply group-wise rank shaping to stabilize reward scales across prompts. Across mathematical reasoning benchmarks, VIGOR outperforms the state-of-the-art Reinforcement Learning from Internal Feedback (RLIF) baseline, and it also exhibits cross-domain transfer to code benchmarks when trained only on math data. For instance, on Qwen2.5-7B-Base post-trained on MATH, VIGOR improves the average math accuracy by +3.31% and the average code accuracy by +1.91% over this baseline, while exhibiting more stable training dynamics. The code is available at https://github.com/ZJUSCL/VIGOR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Verifier-free Intrinsic Gradient-Norm Reward (VIGOR) for RL post-training of LLMs without external verifiers. For a prompt, it samples a group of completions and assigns higher rewards to those inducing smaller ℓ₂ norms of the teacher-forced NLL gradients w.r.t. current policy parameters; a √T length correction and group-wise rank shaping are applied to stabilize the signal. On Qwen2.5-7B-Base trained on MATH, VIGOR reports +3.31% average math accuracy and +1.91% average code accuracy over the RLIF baseline, together with more stable training dynamics.
Significance. If the core assumption holds, VIGOR would provide a scalable, verifier-free RL signal usable across arbitrary domains, removing the need for gold labels or domain-specific checkers. The reported cross-domain transfer from math-only training to code benchmarks and the emphasis on training stability would be practically valuable for broadening LLM post-training.
major comments (3)
- [§3 (Method)] The central claim rests on the unverified assumption that completions with smaller teacher-forced gradient norms are systematically preferable for policy improvement. No section provides a theoretical argument or empirical correlation (e.g., scatter plots of norm vs. downstream accuracy or human preference) showing that the signal drives capability gains rather than simply reinforcing high-likelihood modes already well-fit by the current policy.
- [§4 (Experiments)] The experimental results cite concrete gains (+3.31% math, +1.91% code) but the abstract and available text give no details on number of runs, statistical significance, exact RLIF baseline implementation, or ablations isolating the length correction and rank shaping. Without these, it is impossible to assess whether the reported improvements are robust or attributable to the proposed reward.
- [§3.1 (Reward Definition)] The reward is defined directly from the policy's own gradients on its own samples, yet the update remains a standard policy-gradient step. It is unclear whether the intrinsic loop introduces any new optimization dynamics beyond what a length-normalized log-probability reward would achieve; an explicit comparison or derivation showing the difference would be needed.
minor comments (2)
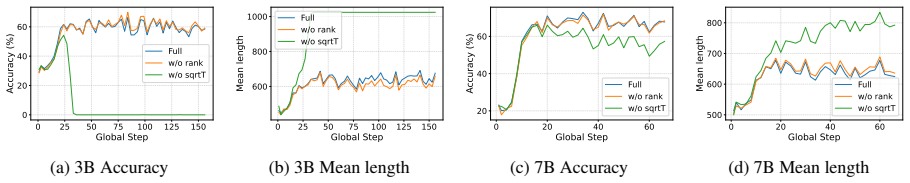
- [§3.1] Notation for the gradient norm (ℓ₂ of teacher-forced NLL) and the exact form of the √T correction should be written as an explicit equation rather than described in prose.
- [Abstract] The GitHub link is provided but no mention is made of whether the released code reproduces the exact training curves and numbers reported in the paper.
Simulated Author's Rebuttal
We thank the referee for their insightful comments. We address each major comment point by point below, providing clarifications and committing to revisions that strengthen the presentation of VIGOR without altering its core claims.
read point-by-point responses
-
Referee: [§3 (Method)] The central claim rests on the unverified assumption that completions with smaller teacher-forced gradient norms are systematically preferable for policy improvement. No section provides a theoretical argument or empirical correlation (e.g., scatter plots of norm vs. downstream accuracy or human preference) showing that the signal drives capability gains rather than simply reinforcing high-likelihood modes already well-fit by the current policy.
Authors: We agree that the current manuscript presents the reward primarily through intuition and does not include direct empirical correlations between gradient norms and capability metrics. In the revision we will add scatter plots and correlation analyses relating gradient-norm values to downstream accuracy and preference signals, thereby providing evidence that the reward favors completions that improve performance rather than merely reinforcing already high-likelihood modes. revision: yes
-
Referee: [§4 (Experiments)] The experimental results cite concrete gains (+3.31% math, +1.91% code) but the abstract and available text give no details on number of runs, statistical significance, exact RLIF baseline implementation, or ablations isolating the length correction and rank shaping. Without these, it is impossible to assess whether the reported improvements are robust or attributable to the proposed reward.
Authors: We acknowledge that the manuscript lacks these reproducibility details. The revised version will report the number of independent runs, include statistical significance tests with confidence intervals, provide the precise RLIF baseline implementation, and add ablations that isolate the √T length correction and group-wise rank shaping to demonstrate their individual contributions to the observed gains. revision: yes
-
Referee: [§3.1 (Reward Definition)] The reward is defined directly from the policy's own gradients on its own samples, yet the update remains a standard policy-gradient step. It is unclear whether the intrinsic loop introduces any new optimization dynamics beyond what a length-normalized log-probability reward would achieve; an explicit comparison or derivation showing the difference would be needed.
Authors: The gradient-norm reward is not equivalent to length-normalized log-probability because the ℓ₂ norm quantifies the sensitivity of the loss surface to the sampled completion, which can select for completions that are both high-likelihood and locally stable under parameter perturbations. We will insert a short derivation and explicit comparison in §3.1 of the revision to clarify how this produces distinct optimization dynamics from a pure log-probability reward. revision: yes
Circularity Check
No significant circularity: VIGOR reward is a novel heuristic independent of the update rule
full rationale
The paper defines VIGOR explicitly as a within-group ranking reward based on the ℓ₂ norm of teacher-forced NLL gradients computed on the current policy's own samples, then applies this scalar reward inside a standard policy-gradient update (e.g., PPO-style). No equation equates the reward construction to the policy improvement step itself, nor does any derivation claim that the accuracy gains follow by algebraic necessity from the norm definition. The length correction (√T) and rank shaping are post-hoc normalizations, not tautological redefinitions. No load-bearing self-citation, uniqueness theorem, or ansatz smuggling is present in the abstract or described method; the central claim rests on empirical comparison to RLIF rather than on a closed mathematical loop. The derivation chain therefore remains self-contained as the proposal and validation of an extrinsic-to-the-update heuristic.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Lower l2 norms of teacher-forced NLL gradients indicate completions that align better with the current policy and are therefore preferable for optimization.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
assigns higher within-group rewards to outputs that induce smaller ℓ₂ norms of the teacher-forced negative log-likelihood gradients under the current parameters
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
correct the systematic length bias of averaged token-level gradients with a √T scaling, and apply group-wise rank shaping
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. 2023 , eprint=
work page 2023
-
[2]
Co-Evolving LLM Coder and Unit Tester via Reinforcement Learning , author=. 2025 , eprint=
work page 2025
-
[3]
No Free Lunch: Rethinking Internal Feedback for LLM Reasoning , author=. 2025 , eprint=
work page 2025
- [4]
-
[5]
Step-KTO: Optimizing Mathematical Reasoning through Stepwise Binary Feedback , author=. 2025 , eprint=
work page 2025
-
[6]
MiMo: Unlocking the Reasoning Potential of Language Model -- From Pretraining to Posttraining , author=. 2025 , eprint=
work page 2025
- [7]
-
[8]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale , author=. 2025 , eprint=
work page 2025
-
[9]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. 2025 , eprint=
work page 2025
-
[10]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
work page 2024
- [11]
- [12]
-
[13]
The Unreasonable Effectiveness of Entropy Minimization in LLM Reasoning , author=. 2025 , eprint=
work page 2025
-
[14]
Maximizing Confidence Alone Improves Reasoning , author=. 2025 , eprint=
work page 2025
-
[15]
Right Question is Already Half the Answer: Fully Unsupervised LLM Reasoning Incentivization , author=. 2025 , eprint=
work page 2025
-
[16]
Co-rewarding: Stable Self-supervised RL for Eliciting Reasoning in Large Language Models , author=. 2025 , eprint=
work page 2025
- [17]
-
[18]
Open R1: A fully open reproduction of DeepSeek-R1 , url =
-
[19]
Jia Li and Edward Beeching and Lewis Tunstall and Ben Lipkin and Roman Soletskyi and Shengyi Costa Huang and Kashif Rasul and Longhui Yu and Albert Jiang and Ziju Shen and Zihan Qin and Bin Dong and Li Zhou and Yann Fleureau and Guillaume Lample and Stanislas Polu , title =. GitHub repository , url =. 2024 , publisher =
work page 2024
-
[20]
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
work page 2021
-
[21]
The Twelfth International Conference on Learning Representations , year=
Let's Verify Step by Step , author=. The Twelfth International Conference on Learning Representations , year=
-
[22]
The Thirteenth International Conference on Learning Representations , year=
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code , author=. The Thirteenth International Conference on Learning Representations , year=
-
[23]
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark , author=. 2024 , eprint=
work page 2024
-
[24]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators , author=. 2025 , eprint=
work page 2025
-
[25]
Instruction-Following Evaluation for Large Language Models , author=. 2023 , eprint=
work page 2023
-
[26]
Alex Gu and Baptiste Roziere and Hugh James Leather and Armando Solar-Lezama and Gabriel Synnaeve and Sida Wang , booktitle=. 2024 , url=
work page 2024
- [27]
-
[28]
Measuring Mathematical Problem Solving With the MATH Dataset , author=. 2021 , eprint=
work page 2021
-
[29]
Li, Yujia and Choi, David and Chung, Junyoung and Kushman, Nate and Schrittwieser, Julian and Leblond, Rémi and Eccles, Tom and Keeling, James and Gimeno, Felix and Dal Lago, Agustin and Hubert, Thomas and Choy, Peter and de Masson d’Autume, Cyprien and Babuschkin, Igor and Chen, Xinyun and Huang, Po-Sen and Welbl, Johannes and Gowal, Sven and Cherepanov,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.