Recognition: no theorem link
Evolving Knowledge Distillation for Lightweight Neural Machine Translation
Pith reviewed 2026-05-12 04:45 UTC · model grok-4.3
The pith
A progressive chain of larger teachers lets compact neural translators reach within 0.08 BLEU of full-size models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
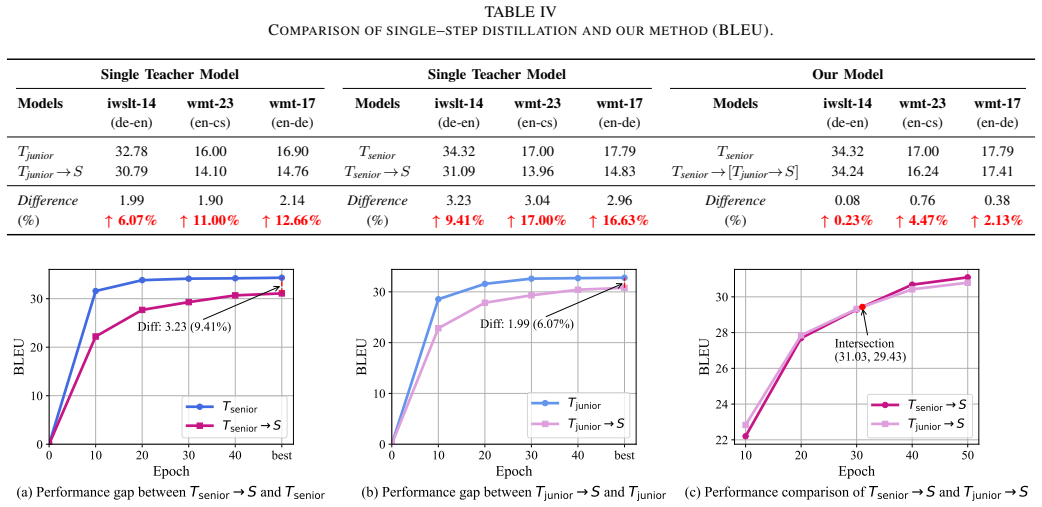
Evolving Knowledge Distillation trains a student model by exposing it successively to teachers of increasing capacity, thereby bridging the capacity gap that normally degrades distillation performance. On the IWSLT-14 benchmark the final student attains 34.24 BLEU, narrowing the gap to the strongest teacher (34.32 BLEU) to 0.08 points, and comparable narrowing occurs on the WMT-17 and WMT-23 sets.
What carries the argument
Evolving Knowledge Distillation (EKD), the framework that trains the student through a progressive sequence of teachers whose capacities increase step by step so that knowledge transfer remains effective across large size differences.
Load-bearing premise
A sequence of teachers with steadily growing capacities can be trained such that knowledge transfers reliably at each step without the schedule creating instability or requiring dataset-specific retuning.
What would settle it
On a fresh language pair, if the student shows no improvement at one or more stages or the final BLEU gap to the largest teacher remains several points wide, the claim that progressive teachers reliably close the capacity gap would be falsified.
Figures


read the original abstract
Recent advancements in Neural Machine Translation (NMT) have significantly improved translation quality. However, the increasing size and complexity of state-of-the-art models present significant challenges for deployment on resource-limited devices. Knowledge distillation (KD) is a promising approach for compressing models, but its effectiveness diminishes when there is a large capacity gap between teacher and student models. To address this issue, we propose Evolving Knowledge Distillation (EKD), a progressive training framework in which the student model learns from a sequence of teachers with gradually increasing capacities. Experiments on IWSLT-14, WMT-17, and WMT-23 benchmarks show that EKD leads to consistent improvements at each stage. On IWSLT-14, the final student achieves a BLEU score of 34.24, narrowing the gap to the strongest teacher (34.32 BLEU) to just 0.08 BLEU. Similar trends are observed on other datasets. These results demonstrate that EKD effectively bridges the capacity gap, enabling compact models to achieve performance close to that of much larger teacher models.Code and models are available at https://github.com/agi-content-generation/EKD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Evolving Knowledge Distillation (EKD), a progressive training framework for neural machine translation in which a student model is distilled sequentially from a sequence of teachers whose capacities increase gradually. The central empirical claim is that this schedule yields consistent per-stage BLEU gains and, on IWSLT-14, produces a final student model with 34.24 BLEU that narrows the gap to the strongest teacher (34.32 BLEU) to only 0.08 BLEU, with analogous trends on WMT-17 and WMT-23. Code and models are released.
Significance. If the progressive schedule is shown to be necessary rather than incidental, the work would offer a practical, reproducible recipe for compressing large NMT models to lightweight students while preserving most of the teacher's performance. The public release of code strengthens the contribution's utility for the community.
major comments (3)
- [Experiments / Results] The central claim that EKD 'effectively bridges the capacity gap' via progressive teachers rests on the untested assumption that the staged schedule is required. No ablation is reported that compares the final EKD student against a baseline that performs direct (or multi-step) distillation from the largest teacher using the same total compute budget; without this comparison the necessity of the progressive component remains unestablished.
- [§4 (Experimental Setup)] The manuscript provides no information on whether the same total training compute (or number of epochs) was allocated to the non-EKD student baselines. If the EKD students receive more total gradient steps across stages, the reported 0.08 BLEU gap on IWSLT-14 could be explained by compute rather than by the evolving-teacher mechanism.
- [§3 (Method)] Details are missing on how the number of stages, capacity increments, temperatures, and stage lengths were selected. If these choices require extensive per-dataset hyperparameter search, the method's practicality for new language pairs is reduced and the claim of 'consistent improvements at each stage' needs qualification.
minor comments (2)
- [Abstract] The abstract contains a missing space ('models.Code') and could more explicitly state the teacher and student model sizes used in the main experiments.
- [Tables / Figures] Figure captions and table footnotes should clarify whether BLEU scores are reported on the same test set splits and with identical tokenization for all compared systems.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We address the major comments point-by-point below, indicating planned revisions to strengthen the paper.
read point-by-point responses
-
Referee: The central claim that EKD 'effectively bridges the capacity gap' via progressive teachers rests on the untested assumption that the staged schedule is required. No ablation is reported that compares the final EKD student against a baseline that performs direct (or multi-step) distillation from the largest teacher using the same total compute budget; without this comparison the necessity of the progressive component remains unestablished.
Authors: We agree this ablation is necessary to establish the benefit of the progressive schedule. In the revised manuscript, we will add an experiment distilling directly from the largest teacher using the equivalent total compute budget as EKD and compare the resulting BLEU scores. revision: yes
-
Referee: The manuscript provides no information on whether the same total training compute (or number of epochs) was allocated to the non-EKD student baselines. If the EKD students receive more total gradient steps across stages, the reported 0.08 BLEU gap on IWSLT-14 could be explained by compute rather than by the evolving-teacher mechanism.
Authors: We will clarify in the revised §4 that all baselines were trained with the same per-stage compute as EKD stages, but we acknowledge the total compute differs. We will add a direct KD baseline trained for the full EKD compute budget to ensure fair comparison. revision: yes
-
Referee: Details are missing on how the number of stages, capacity increments, temperatures, and stage lengths were selected. If these choices require extensive per-dataset hyperparameter search, the method's practicality for new language pairs is reduced and the claim of 'consistent improvements at each stage' needs qualification.
Authors: We will add details in §3 explaining our choices: stages correspond to available teacher sizes with gradual increases; temperatures are set to 2.0 following standard KD; stage lengths are fixed to 15 epochs based on validation convergence. We will also include a brief sensitivity analysis showing robustness, supporting practicality without extensive search. revision: partial
Circularity Check
No circularity: purely empirical proposal with no derivation chain
full rationale
The paper introduces EKD as a progressive KD framework in which a student model is trained sequentially on teachers of increasing capacity, reporting final BLEU scores (e.g., 34.24 on IWSLT-14) that close the gap to the largest teacher. No equations, uniqueness theorems, or fitted parameters are defined such that any reported performance metric reduces to those quantities by construction. The central claim rests on experimental outcomes rather than a self-referential derivation; prior KD literature is cited only as background, not as load-bearing self-citation that substitutes for verification. The work is therefore self-contained as an empirical method proposal.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of distillation stages and capacity increments
axioms (1)
- standard math Standard SGD-based optimization converges to useful local minima for each successive teacher-student pair.
Reference graph
Works this paper leans on
-
[1]
Neural machine translation by jointly learning to align and translate,
D. Bahdanau, K. H. Cho, and Y . Bengio, “Neural machine translation by jointly learning to align and translate,” in3rd International Conference on Learning Representations, ICLR 2015, 2015
work page 2015
-
[2]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[3]
Beyond english- centric multilingual machine translation,
A. Fan, S. Bhosale, H. Schwenk, Z. Ma, A. El-Kishky, S. Goyal, M. Baines, O. Celebi, G. Wenzek, V . Chaudharyet al., “Beyond english- centric multilingual machine translation,”Journal of Machine Learning Research, vol. 22, no. 107, pp. 1–48, 2021
work page 2021
-
[4]
Y . Koishekenov, A. B ´erard, and V . Nikoulina, “Memory-efficient nllb- 200: Language-specific expert pruning of a massively multilingual ma- chine translation model,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023, pp. 3567–3585
work page 2023
-
[5]
H. Geoffrey, “V o amd dean jeff,”,” inDistilling the knowledge in a neural network, ” NIPS 2014 Deep Learning Workshop, 2014
work page 2014
-
[6]
Knowledge distillation: A survey,
J. Gou and et al., “Knowledge distillation: A survey,”IJCV, vol. 129, no. 6, pp. 1789–1819, 2021
work page 2021
-
[7]
Continual learning with knowl- edge distillation: A survey,
S. Li, T. Su, X. Zhang, and Z. Wang, “Continual learning with knowl- edge distillation: A survey,”IEEE Transactions on Neural Networks and Learning Systems, 2024
work page 2024
-
[8]
Sentence- level or token-level? a comprehensive study on knowledge distillation,
J. Wei, L. Sun, Y . Leng, X. Tan, B. Yu, and R. Guo, “Sentence- level or token-level? a comprehensive study on knowledge distillation,” inProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, 2024, pp. 6531–6540
work page 2024
-
[9]
Lifting the curse of capacity gap in distilling language models,
C. Zhang, Y . Yang, J. Liu, J. Wang, Y . Xian, B. Wang, and D. Song, “Lifting the curse of capacity gap in distilling language models,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023, pp. 4535– 4553
work page 2023
-
[10]
On the efficacy of knowledge distillation,
J. H. Cho and B. Hariharan, “On the efficacy of knowledge distillation,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 4794–4802
work page 2019
-
[11]
Improved knowledge distillation via teacher assis- tant,
S. I. Mirzadeh, M. Farajtabar, A. Li, N. Levine, A. Matsukawa, and H. Ghasemzadeh, “Improved knowledge distillation via teacher assis- tant,” inProceedings of the AAAI conference on artificial intelligence, vol. 34, no. 04, 2020, pp. 5191–5198
work page 2020
-
[12]
P. Han, X. Huang, Y . Fang, and G. Han, “Rethinking knowledge distil- lation in collaborative machine learning: Memory, knowledge, and their interactions,”IEEE Transactions on Network Science and Engineering, 2025
work page 2025
-
[13]
Implicit feature alignment for knowledge distillation,
D. Chen, M. Wang, X. Zhang, T. Liang, and Z. Luo, “Implicit feature alignment for knowledge distillation,” in2022 IEEE 34th International Conference on Tools with Artificial Intelligence (ICTAI), 2022, pp. 402– 408
work page 2022
-
[14]
L. Fang, X. Yu, J. Cai, Y . Chen, S. Wu, Z. Liu, Z. Yang, H. Lu, X. Gong, Y . Liuet al., “Knowledge distillation and dataset distillation of large language models: Emerging trends, challenges, and future directions,” arXiv preprint arXiv:2504.14772, 2025
-
[15]
A. Galiano-Jim ´enez, J. A. P ´erez-Ortiz, F. S ´anchez-Mart´ınez, and V . M. S´anchez-Cartagena, “Beyond the mode: Sequence-level distillation of multilingual translation models for low-resource language pairs,” in Findings of the Association for Computational Linguistics: NAACL 2025, 2025, pp. 6661–6676
work page 2025
-
[16]
Feature structure distillation with centered kernel alignment in bert transferring,
H.-J. Jung, D. Kim, S.-H. Na, and K. Kim, “Feature structure distillation with centered kernel alignment in bert transferring,”Expert Systems with Applications, vol. 234, p. 120980, 2023
work page 2023
-
[17]
Sequence-level knowledge distillation,
Y . Kim and A. M. Rush, “Sequence-level knowledge distillation,” in Proceedings of the 2016 conference on empirical methods in natural language processing, 2016, pp. 1317–1327
work page 2016
-
[18]
Vidlankd: Improving lan- guage understanding via video-distilled knowledge transfer,
Z. Tang, J. Cho, H. Tan, and M. Bansal, “Vidlankd: Improving lan- guage understanding via video-distilled knowledge transfer,”Advances in Neural Information Processing Systems, vol. 34, pp. 24 468–24 481, 2021
work page 2021
-
[19]
Document-level relation extrac- tion with adaptive focal loss and knowledge distillation,
Q. Tan, R. He, L. Bing, and H. T. Ng, “Document-level relation extrac- tion with adaptive focal loss and knowledge distillation,” inFindings of the Association for Computational Linguistics: ACL 2022, 2022, pp. 1672–1681
work page 2022
-
[20]
Structure- level knowledge distillation for multilingual sequence labeling,
X. Wang, Y . Jiang, N. Bach, T. Wang, F. Huang, and K. Tu, “Structure- level knowledge distillation for multilingual sequence labeling,” in Proceedings of the 58th Annual Meeting of the Association for Com- putational Linguistics, 2020, pp. 3317–3330
work page 2020
-
[21]
Selective knowledge distillation for neural machine translation,
F. Wang, J. Yan, F. Meng, and J. Zhou, “Selective knowledge distillation for neural machine translation,”arXiv preprint arXiv:2105.12967, 2021
-
[22]
Aligndistil: Token-level language model alignment as adaptive policy distillation,
S. Zhang, X. Zhang, T. Zhang, B. Hu, Y . Chen, and J. Xu, “Aligndistil: Token-level language model alignment as adaptive policy distillation,” arXiv preprint arXiv:2503.02832, 2025
-
[23]
T. Furlanello, Z. Lipton, M. Tschannen, L. Itti, and A. Anandkumar, “Born again neural networks,” inInternational conference on machine learning. PMLR, 2018, pp. 1607–1616
work page 2018
-
[24]
Z. Jia, H. Liang, Y . Liu, H. Wang, and T. Jiang, “Distillsleepnet: Heterogeneous multi-level knowledge distillation via teacher assistant for sleep staging,”IEEE Transactions on Big Data, 2024
work page 2024
-
[25]
Densely guided knowledge distillation using multiple teacher assistants,
W. Son, J. Na, J. Choi, and W. Hwang, “Densely guided knowledge distillation using multiple teacher assistants,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 9395–9404
work page 2021
-
[26]
Amd: Automatic multi-step distillation of large-scale vision models,
C. Han, Q. Wang, S. A. Dianat, M. Rabbani, R. M. Rao, Y . Fang, Q. Guan, L. Huang, and D. Liu, “Amd: Automatic multi-step distillation of large-scale vision models,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 431–450
work page 2024
-
[27]
B. Lv, X. Liu, K. Wei, P. Luo, and Y . Yu, “Taekd: Teacher assistant enhanced knowledge distillation for closed-source multilingual neural machine translation,” inProceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), 2024, pp. 15 530–15 541
work page 2024
-
[28]
Multilingual neural machine translation with language clustering,
X. Tan, J. Chen, D. He, Y . Xia, T. Qin, and T.-Y . Liu, “Multilingual neural machine translation with language clustering,”arXiv preprint arXiv:1908.09324, 2019
-
[29]
Efficient knowledge distillation of teacher model to multiple student models,
G. Thrivikram, V . Ganesh, T. Sethuraman, and S. K. Perepu, “Efficient knowledge distillation of teacher model to multiple student models,” in2021 IEEE International Conference on Industry 4.0, Artificial Intelligence, and Communications Technology (IAICT). IEEE, 2021, pp. 173–179
work page 2021
-
[30]
F. Saleh, W. Buntine, and G. Haffari, “Collective wisdom: Improving low-resource neural machine translation using adaptive knowledge dis- tillation,”arXiv preprint arXiv:2010.05445, 2020
-
[31]
Adaptive multi-teacher knowledge distillation with meta-learning,
H. Zhang, D. Chen, and C. Wang, “Adaptive multi-teacher knowledge distillation with meta-learning,” in2023 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 2023, pp. 1943–1948
work page 2023
-
[32]
Learning lightweight object detectors via multi-teacher progressive distillation,
S. Cao, M. Li, J. Hays, D. Ramanan, Y .-X. Wang, and L. Gui, “Learning lightweight object detectors via multi-teacher progressive distillation,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 3577–3598
work page 2023
-
[33]
Towards understanding and improving knowledge distillation for neural machine translation,
S. Zhang, Y . Liang, S. Wang, Y . Chen, W. Han, J. Liu, and J. Xu, “Towards understanding and improving knowledge distillation for neural machine translation,” inFindings of the Association for Computational Linguistics: ACL 2023, 2023, pp. 8062–8079
work page 2023
-
[34]
Neural machine translation of rare words,
R. Sennrich, B. Haddow, and A. Birch, “Neural machine translation of rare words,”arXiv, vol. 1508, 2016
work page 2016
-
[35]
Understanding knowledge dis- tillation in non-autoregressive machine translation,
C. Zhou, G. Neubig, and J. Gu, “Understanding knowledge dis- tillation in non-autoregressive machine translation,”arXiv preprint arXiv:1911.02727, 2019
-
[36]
Pre-training distillation for large language models: A design space exploration, 2024
H. Peng, X. Lv, Y . Bai, Z. Yao, J. Zhang, L. Hou, and J. Li, “Pre-training distillation for large language models: A design space exploration,” arXiv preprint arXiv:2410.16215, 2024
-
[37]
Fairseq: A fast, extensible toolkit for sequence modeling,
M. Ott, S. Edunov, A. Baevski, A. Fan, S. Gross, N. Ng, D. Grangier, and M. Auli, “Fairseq: A fast, extensible toolkit for sequence modeling,” NAACL HLT 2019, p. 48, 2019
work page 2019
-
[38]
Bleu: a method for automatic evaluation of machine translation,
K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “Bleu: a method for automatic evaluation of machine translation,” inProceedings of the 40th annual meeting of the Association for Computational Linguistics, 2002, pp. 311–318
work page 2002
-
[39]
COMET: A neural framework for MT evaluation,
R. Rei, C. Stewart, A. C. Farinha, and A. Lavie, “COMET: A neural framework for MT evaluation,” inProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), B. Webber, T. Cohn, Y . He, and Y . Liu, Eds. Online: Association for Computational Linguistics, Nov. 2020, pp. 2685–2702. [Online]. Available: https://aclantholog...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.