Recognition: 2 theorem links
· Lean TheoremStructure from Strategic Interaction & Uncertainty: Risk Sensitive Games for Robust Preference Learning
Pith reviewed 2026-05-14 21:59 UTC · model grok-4.3
The pith
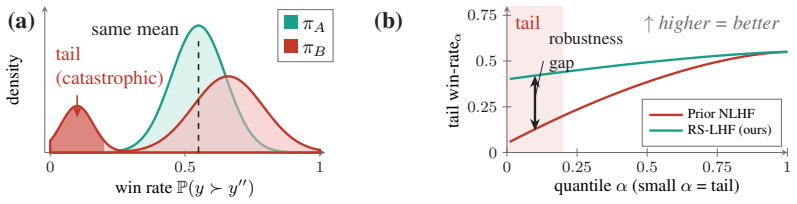
Risk-sensitive preference games produce policies robust across data strata while matching risk-neutral performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Players in a preference game optimize convex risk measures of pairwise losses; translation invariance keeps the game monotone, so self-play converges rapidly and produces policies whose performance holds across data strata.
What carries the argument
Risk-sensitive preference game in which each player minimizes a convex risk measure applied to its preference loss, with translation invariance of the risk measure preserving monotonicity for self-play convergence.
If this is right
- Risk-adjusted policies remain stable when the risk parameter is varied.
- Performance consistency holds across distinct data strata including prompts and safety-critical subsets.
- Sample-complexity bounds scale explicitly with the risk level while controlling both structural and statistical bias.
- The bias-corrected two-timescale extragradient method reaches the Stackelberg equilibrium even when data are scarce.
Where Pith is reading between the lines
- The same risk-sensitive structure could be used in other preference-driven settings such as recommendation or robotics control.
- Explicit risk control may reduce the frequency of rare but high-cost failures that average-based methods overlook.
- Testing the approach on larger models and real human feedback loops would reveal whether the low-sample advantages persist at scale.
Load-bearing premise
Many risk metrics are translation invariant, which is required to keep the game monotone so that self-play methods converge fast.
What would settle it
A concrete test would be to run the risk-sensitive self-play algorithm on a simple preference dataset and check whether the learned policy converges to a Stackelberg equilibrium whose empirical risk matches the theoretical bound; failure of convergence or systematic underperformance relative to the risk-neutral baseline on new strata would falsify the claim.
Figures
























read the original abstract
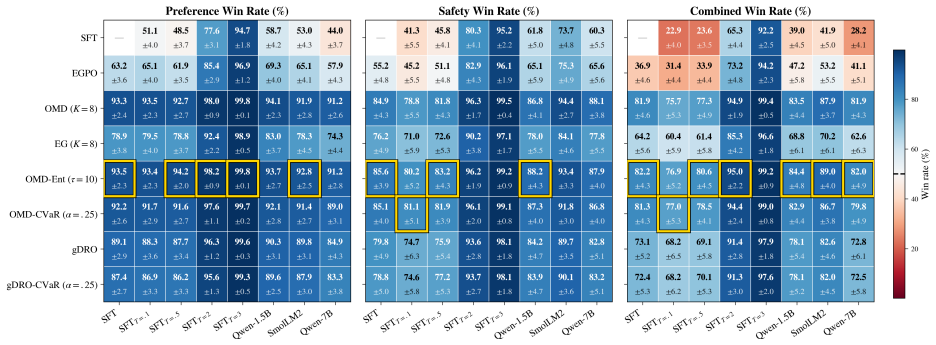
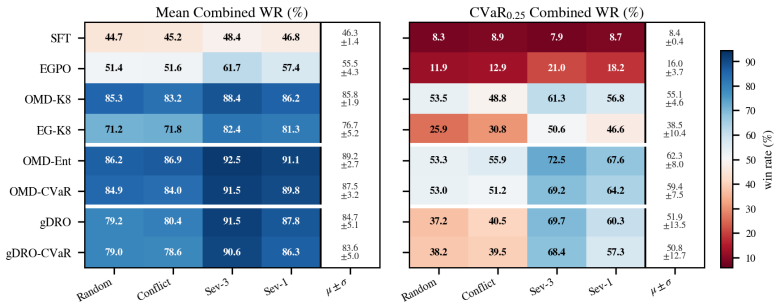
A growing line of work reframes preference-based fine-tuning of large language models game-theoretically: Nash Learning from Human Feedback (NLHF) recasts the problem as a zero-sum game over policies. However, optimization is over expected pairwise payoffs, thereby conflating policies with similar win rates but different tail behavior. As such, these methods are agnostic to where in the data distribution they succeed or fail: strong average performance can mask systematic failure across prompts, annotators, or safety-critical strata. We introduce risk-sensitive preference games, in which players optimize convex risk measures of their preference loss, exploiting structure in preference uncertainty. While risk-sensitivity generally breaks the zero-sum structure, we show that translation invariance of many risk metrics ensures that we retain monotonicity, yielding fast convergence of sample-efficient self-play methods. Furthermore, we establish algorithmic stability and offline sample complexity bounds that scale with risk, requiring simultaneous control of structural bias from nonlinear risk transformations, statistical bias in risk estimation, and concentration tailored to the risk-sensitive setting. To address statistical bias, we introduce a hierarchical game formulation and a two-timescale extragradient algorithm with bias correction that converges to the Stackelberg equilibrium and is especially effective in low-sample regimes. Empirically, risk-adjusted policies are robust across data strata, stable across risk choices, and match or exceed risk-neutral performance thereby achieving robustness without a performance tax.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces risk-sensitive preference games for robust LLM preference learning, reframing NLHF as a game where players optimize convex risk measures of pairwise preference losses instead of expected payoffs. It claims that translation invariance of risk metrics preserves monotonicity despite breaking zero-sum structure, enabling fast convergence via self-play methods like extragradient; it further derives algorithmic stability and offline sample-complexity bounds scaling with risk, introduces a hierarchical Stackelberg formulation with two-timescale bias-corrected extragradient, and reports empirical robustness across data strata without average-performance loss.
Significance. If the monotonicity preservation and sample-complexity results hold, the work offers a principled route to risk-aware RLHF that addresses tail failures across prompts or annotators while retaining or improving average win rates. The bias-correction mechanism for low-sample regimes and the empirical stability across risk levels are concrete strengths; the focus on structural bias from nonlinear risk transformations is a timely contribution to game-theoretic preference optimization.
major comments (3)
- [Abstract and §3] Abstract and §3 (monotonicity claim): the central step asserts that translation invariance of convex risk measures preserves monotonicity when composed with the nonlinear pairwise preference operator (win-rate differences across strata), yet no explicit proof or counterexample check is provided; if monotonicity fails under this composition, the extragradient and two-timescale convergence arguments and all downstream sample-complexity bounds become unsupported.
- [§4] §4 (sample complexity): the stated bounds that 'scale with risk' are presented without explicit dependence on the risk parameter, concentration inequalities tailored to the risk-sensitive estimator, or full derivation of the structural-plus-statistical bias terms; this renders the scaling claim unverifiable from the given text.
- [Empirical section] Empirical section (Tables/Figures): robustness is reported across strata and risk levels, but no ablation isolates the effect of the monotonicity assumption or compares against regimes where the nonlinear composition might violate it, weakening the theory-practice link for the claimed 'no performance tax' result.
minor comments (2)
- [§2] Notation for the risk measure applied to the preference payoff matrix should be introduced with an explicit equation early in §2 to avoid ambiguity when the operator is later composed with the game value.
- [§4.2] The hierarchical game formulation in §4.2 would benefit from a diagram clarifying the leader-follower timing and the two-timescale updates.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments help clarify the presentation of our theoretical results. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (monotonicity claim): the central step asserts that translation invariance of convex risk measures preserves monotonicity when composed with the nonlinear pairwise preference operator (win-rate differences across strata), yet no explicit proof or counterexample check is provided; if monotonicity fails under this composition, the extragradient and two-timescale convergence arguments and all downstream sample-complexity bounds become unsupported.
Authors: We agree that an explicit statement would improve clarity. In §3 we establish monotonicity via the fact that translation-invariant convex risk measures (ρ(X+c)=ρ(X)+c) preserve order when applied to the preference loss operator, because the operator itself is monotone in the underlying payoffs and the risk measure is monotone. The proof proceeds by showing that if E[π1] ≽ E[π2] then ρ(ℓ(π1)) ≽ ρ(ℓ(π2)) for the shifted losses. We will add a dedicated lemma with the full proof in the main text and include a short counterexample verification for CVaR and entropic risk in the appendix of the revision. revision: yes
-
Referee: [§4] §4 (sample complexity): the stated bounds that 'scale with risk' are presented without explicit dependence on the risk parameter, concentration inequalities tailored to the risk-sensitive estimator, or full derivation of the structural-plus-statistical bias terms; this renders the scaling claim unverifiable from the given text.
Authors: The dependence on the risk parameter is encoded in the Lipschitz constant L_ρ of the risk measure and in the sub-Gaussian parameter of the risk estimator (see the Bernstein-type concentration in the proof of Theorem 4.1). Structural bias is bounded by the deviation between ρ and expectation, while statistical bias scales as O(1/√n) with an extra factor from the risk level. We will expand the statement of the bound in §4 to display the explicit dependence on the risk parameter and move the full derivation (including the tailored concentration inequality) to the appendix for verifiability. revision: yes
-
Referee: [Empirical section] Empirical section (Tables/Figures): robustness is reported across strata and risk levels, but no ablation isolates the effect of the monotonicity assumption or compares against regimes where the nonlinear composition might violate it, weakening the theory-practice link for the claimed 'no performance tax' result.
Authors: We acknowledge that an explicit ablation would tighten the theory-practice connection. In the revision we will add a controlled experiment that replaces the translation-invariant risk with a non-invariant surrogate (e.g., a shifted variance penalty) and reports the resulting degradation in both convergence speed and strata robustness, thereby isolating the role of the monotonicity-preserving property. revision: yes
Circularity Check
No significant circularity; derivation relies on standard convex analysis and extragradient convergence
full rationale
The paper's central claims rest on showing that translation invariance of convex risk measures preserves monotonicity of the preference game operator, allowing application of known extragradient and two-timescale analyses. This step is presented as a direct consequence of the definition of translation invariance applied to the risk-adjusted payoff, without reducing the result to a fitted parameter or self-citation chain. No equations equate a derived equilibrium or sample-complexity bound to an input by construction. The hierarchical formulation and bias-correction algorithm are introduced as new but build on external convergence theory rather than redefining the target quantities. The empirical robustness claims are presented as validation rather than part of the derivation chain. Overall the argument is self-contained against external benchmarks for risk measures and game-theoretic methods.
Axiom & Free-Parameter Ledger
free parameters (1)
- risk level parameter
axioms (1)
- domain assumption Translation invariance of convex risk measures preserves monotonicity in the game
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
translation invariance of many risk metrics ensures that we retain monotonicity, yielding fast convergence of sample-efficient self-play methods
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Journal of machine learning research , volume=
Stability and generalization , author=. Journal of machine learning research , volume=
-
[2]
ICLR (arXiv:2411.02306) , year=
On targeted manipulation and deception when optimizing LLMs for user feedback , author=. ICLR (arXiv:2411.02306) , year=
-
[3]
Advances in Neural Information Processing Systems , volume =
Training Language Models to Follow Instructions with Human Feedback , author =. Advances in Neural Information Processing Systems , volume =
-
[4]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback , author =. arXiv preprint arXiv:2204.05862 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Advances in Neural Information Processing Systems , volume =
Deep Reinforcement Learning from Human Preferences , author =. Advances in Neural Information Processing Systems , volume =
-
[6]
Advances in Neural Information Processing Systems , volume =
Learning to Summarize with Human Feedback , author =. Advances in Neural Information Processing Systems , volume =
-
[7]
Fine-Tuning Language Models from Human Preferences
Fine-Tuning Language Models from Human Preferences , author =. arXiv preprint arXiv:1909.08593 , year =
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[8]
Stochastic Finance: An Introduction in Discrete Time , author =. 2016 , publisher =
work page 2016
- [9]
- [10]
-
[11]
On Targeted Manipulation and Deception when Optimizing
Williams, Marcus and Carroll, Micah and Narang, Adhyyan and Weisser, Constantin and Murphy, Brendan and Dragan, Anca , booktitle =. On Targeted Manipulation and Deception when Optimizing
-
[12]
SIAM Journal on Optimization , volume=
Prox-method with rate of convergence O (1/t) for variational inequalities with Lipschitz continuous monotone operators and smooth convex-concave saddle point problems , author=. SIAM Journal on Optimization , volume=. 2004 , publisher=
work page 2004
-
[13]
Solving variational inequalities with stochastic mirror-prox algorithm , author=. Stochastic Systems , volume=. 2011 , publisher=
work page 2011
-
[14]
On the Coherence of Expected Shortfall , volume =
Acerbi, Carlo and Tasche, Dirk , year =. On the Coherence of Expected Shortfall , volume =. Journal of Banking & Finance , doi =
-
[15]
Journal of Computational and Applied Mathematics , volume=
On linear convergence of iterative methods for the variational inequality problem , author=. Journal of Computational and Applied Mathematics , volume=. 1995 , publisher=
work page 1995
-
[16]
The 22nd International Conference on Artificial Intelligence and Statistics , pages=
Risk-sensitive generative adversarial imitation learning , author=. The 22nd International Conference on Artificial Intelligence and Statistics , pages=. 2019 , organization=
work page 2019
-
[17]
Extragradient method for finding saddle points and other problems , author=. Matekon , volume=. 1977 , publisher=
work page 1977
-
[18]
Econometrica: Journal of the Econometric Society , pages=
Existence and uniqueness of equilibrium points for concave n-person games , author=. Econometrica: Journal of the Econometric Society , pages=. 1965 , publisher=
work page 1965
-
[19]
Mathematische Annalen , year =
von Neumann, John , title =. Mathematische Annalen , year =. doi:10.1007/BF01448847 , url =
-
[20]
International Conference on Artificial Intelligence and Statistics , pages=
A general theoretical paradigm to understand learning from human preferences , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2024 , organization=
work page 2024
-
[21]
Forty-first International Conference on Machine Learning , year=
Nash learning from human feedback , author=. Forty-first International Conference on Machine Learning , year=
-
[22]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Calandriello, Daniele and Guo, Zhaohan Daniel and Munos, Remi and Rowland, Mark and Tang, Yunhao and Pires, Bernardo Avila and Richemond, Pierre Harvey and Le Lan, Charline and Valko, Michal and Liu, Tianqi and Joshi, Rishabh and Zheng, Zeyu and Piot, Bilal , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024...
work page 2024
-
[23]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Swamy, Gokul and Dann, Christoph and Kidambi, Rahul and Wu, Zhiwei Steven and Agarwal, Alekh , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
work page 2024
-
[24]
Multi-turn Reinforcement Learning with Preference Human Feedback , url =
Shani, Lior and Rosenberg, Aviv and Cassel, Asaf and Lang, Oran and Calandriello, Daniele and Zipori, Avital and Noga, Hila and Keller, Orgad and Piot, Bilal and Szpektor, Idan and Hassidim, Avinatan and Matias, Yossi and Munos, R\'. Multi-turn Reinforcement Learning with Preference Human Feedback , url =. Advances in Neural Information Processing Systems , doi =
-
[25]
The Thirteenth International Conference on Learning Representations , year=
Magnetic Preference Optimization: Achieving Last-iterate Convergence for Language Model Alignment , author=. The Thirteenth International Conference on Learning Representations , year=
-
[26]
Iterative Nash Policy Optimization: Aligning
Yuheng Zhang and Dian Yu and Baolin Peng and Linfeng Song and Ye Tian and Mingyue Huo and Nan Jiang and Haitao Mi and Dong Yu , booktitle=. Iterative Nash Policy Optimization: Aligning. 2025 , url=
work page 2025
-
[27]
Zhou, Runlong and Fazel, Maryam and Du, Simon S , journal=
-
[28]
Safety Alignment of LMs via Non-cooperative Games , author=. 2026 , eprint=
work page 2026
-
[29]
Proximal Point Nash Learning from Human Feedback , author=. 2026 , eprint=
work page 2026
-
[30]
Ralph Allan Bradley and Milton E. Terry , journal =. Rank Analysis of Incomplete Block Designs: I. The Method of Paired Comparisons , urldate =
- [31]
-
[32]
Fine-Tuning Language Models from Human Preferences , author=. 2020 , eprint=
work page 2020
-
[33]
and Leike, Jan and Brown, Tom B
Christiano, Paul F. and Leike, Jan and Brown, Tom B. and Martic, Miljan and Legg, Shane and Amodei, Dario , title =. Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =. 2017 , isbn =
work page 2017
-
[34]
Korpelevich, G. M. , title=. Matecon , volume=
-
[35]
International Conference on Machine Learning , pages=
An investigation of why overparameterization exacerbates spurious correlations , author=. International Conference on Machine Learning , pages=. 2020 , organization=
work page 2020
-
[36]
International Conference on Machine Learning , pages=
Fairness without demographics in repeated loss minimization , author=. International Conference on Machine Learning , pages=. 2018 , organization=
work page 2018
-
[37]
Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization , author=. arXiv preprint arXiv:1911.08731 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[38]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , url =
Rafailov, Rafael and Sharma, Archit and Mitchell, Eric and Manning, Christopher D and Ermon, Stefano and Finn, Chelsea , booktitle =. Direct Preference Optimization: Your Language Model is Secretly a Reward Model , url =
-
[39]
Mathematics of Operations Research , volume=
Strongly regular generalized equations , author=. Mathematics of Operations Research , volume=. 1980 , publisher=
work page 1980
-
[40]
International Conference on Machine Learning , pages=
Performative prediction , author=. International Conference on Machine Learning , pages=. 2020 , organization=
work page 2020
-
[41]
Journal of Machine Learning Research , volume=
Multiplayer performative prediction: Learning in decision-dependent games , author=. Journal of Machine Learning Research , volume=
-
[42]
Advances in Neural Information Processing Systems , volume=
Stability and deviation optimal risk bounds with convergence rate O (1/n) , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
Conference on Learning Theory , pages=
Sharper bounds for uniformly stable algorithms , author=. Conference on Learning Theory , pages=. 2020 , organization=
work page 2020
-
[44]
Mathematical Programming , volume=
Robinson’s implicit function theorem and its extensions , author=. Mathematical Programming , volume=. 2009 , publisher=
work page 2009
-
[45]
Back to Basics: Revisiting REINFORCE -Style Optimization for Learning from Human Feedback in LLM s
Ahmadian, Arash and Cremer, Chris and Gall. Back to Basics: Revisiting REINFORCE -Style Optimization for Learning from Human Feedback in LLM s. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.662
-
[46]
Available at Optimization Online , volume=
Kullback-Leibler divergence constrained distributionally robust optimization , author=. Available at Optimization Online , volume=
-
[47]
Beyond Pessimism: Offline Learning in KL-regularized Games
Beyond Pessimism: Offline Learning in KL-regularized Games , author=. arXiv preprint arXiv:2604.06738 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
work page 2024
- [49]
-
[50]
arXiv preprint arXiv:2104.01627 , year=
Finite-time convergence rates of nonlinear two-time-scale stochastic approximation under Markovian noise , author=. arXiv preprint arXiv:2104.01627 , year=
-
[51]
arXiv preprint arXiv , volume=
Train faster, generalize better: Stability of stochastic gradient descent , author=. arXiv preprint arXiv , volume=
-
[52]
arXiv preprint arXiv:2403.08635 , year=
Human alignment of large language models through online preference optimisation , author=. arXiv preprint arXiv:2403.08635 , year=
-
[53]
arXiv preprint arXiv:2407.00617 , year=
Iterative nash policy optimization: Aligning llms with general preferences via no-regret learning , author=. arXiv preprint arXiv:2407.00617 , year=
-
[54]
Magnetic Preference Optimization: Achieving Last-iterate Convergence for Language Model Alignment , author=. 2025 , eprint=
work page 2025
-
[55]
arXiv preprint arXiv:2110.04185 , year=
Cen, Shicong and Wei, Yuting and Chi, Yuejie , title=. arXiv preprint arXiv:2110.04185 , year=
-
[56]
Journal of banking & finance , volume=
Conditional value-at-risk for general loss distributions , author=. Journal of banking & finance , volume=. 2002 , publisher=
work page 2002
-
[57]
Proceedings of the 3rd Conference on Learning for Dynamics and Control , pages =
Nonlinear Two-Time-Scale Stochastic Approximation: Convergence and Finite-Time Performance , author =. Proceedings of the 3rd Conference on Learning for Dynamics and Control , pages =. 2021 , editor =
work page 2021
-
[58]
Implicit functions and solution mappings , author=. 2009 , publisher=
work page 2009
-
[59]
Ye, Chenlu and Xiong, Wei and Zhang, Yuheng and Dong, Hanze and Jiang, Nan and Zhang, Tong , title =. Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
work page 2024
-
[60]
Finance and stochastics , volume=
Convex measures of risk and trading constraints , author=. Finance and stochastics , volume=. 2002 , publisher=
work page 2002
-
[61]
Mathematical Finance , volume =
Artzner, Philippe and Delbaen, Freddy and Eber, Jean-Marc and Heath, David , title =. Mathematical Finance , volume =. doi:https://doi.org/10.1111/1467-9965.00068 , url =. https://onlinelibrary.wiley.com/doi/pdf/10.1111/1467-9965.00068 , year =
-
[62]
Robust Policy Optimization to Prevent Catastrophic Forgetting , author=. 2026 , eprint=
work page 2026
-
[63]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Ethayarajh, Kawin and Xu, Winnie and Muennighoff, Niklas and Jurafsky, Dan and Kiela, Douwe , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
work page 2024
-
[64]
The Thirteenth International Conference on Learning Representations , year=
Tractable multi-agent reinforcement learning through behavioral economics , author=. The Thirteenth International Conference on Learning Representations , year=
-
[65]
Training Generalizable Collaborative Agents via Strategic Risk Aversion , author=. 2026 , eprint=
work page 2026
-
[66]
Strategically Robust Multi-Agent Reinforcement Learning with Linear Function Approximation , author=. 2026 , eprint=
work page 2026
-
[67]
Quantal Response Equilibria for Normal Form Games , journal =. 1995 , issn =. doi:https://doi.org/10.1006/game.1995.1023 , url =
-
[68]
Hardt, Moritz and Recht, Benjamin and Singer, Yoram , title =. Proceedings of the 33rd International Conference on International Conference on Machine Learning - Volume 48 , pages =. 2016 , publisher =
work page 2016
-
[69]
arXiv preprint arXiv:2406.15513 , year=
PKU-SafeRLHF: Towards Multi-Level Safety Alignment for LLMs with Human Preference , author=. arXiv preprint arXiv:2406.15513 , year=
-
[70]
Llama 2: Open Foundation and Fine-Tuned Chat Models , author=. 2023 , eprint=
work page 2023
-
[71]
Ronald A. Howard and James E. Matheson , journal =. Risk-Sensitive Markov Decision Processes , urldate =
- [72]
-
[73]
Machine Learning Proceedings 1994 , publisher =
Consideration of Risk in Reinforcement Learning , editor =. Machine Learning Proceedings 1994 , publisher =. 1994 , isbn =. doi:https://doi.org/10.1016/B978-1-55860-335-6.50021-0 , url =
-
[74]
and Sommer, Tobias and Obermayer, Klaus , title =
Shen, Yun and Tobia, Michael J. and Sommer, Tobias and Obermayer, Klaus , title =. Neural Computation , volume =. 2014 , month =. doi:10.1162/NECO_a_00600 , url =
-
[75]
Risk-averse dynamic programming for Markov decision processes , year =
Ruszczy\'. Risk-averse dynamic programming for Markov decision processes , year =. Math. Program. , month = oct, pages =
-
[76]
Risk sensitive control of Markov processes in countable state space , year =
Hern\'. Risk sensitive control of Markov processes in countable state space , year =. doi:10.1016/S0167-6911(96)00051-5 , journal =
-
[77]
Ratliff, Lillian J. and Mazumdar, Eric , journal=. Inverse Risk-Sensitive Reinforcement Learning , year=
-
[78]
Singh, Sumeet and Lacotte, Jonathan and Majumdar, Anirudha and Pavone, Marco , title =. Int. J. Rob. Res. , month = dec, pages =. 2018 , issue_date =. doi:10.1177/0278364918772017 , abstract =
-
[79]
Risk-Sensitive Generative Adversarial Imitation Learning
Jonathan Lacotte and Yinlam Chow and Mohammad Ghavamzadeh and Marco Pavone , title =. CoRR , volume =. 2018 , url =. 1808.04468 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[80]
Robotics: Science and Systems , year=
Risk-sensitive Inverse Reinforcement Learning via Coherent Risk Models , author=. Robotics: Science and Systems , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.