Recognition: 1 theorem link
· Lean TheoremGeneralized Boundary FDR Control under Arbitrary Dependence: An Approach on Closure Principle
Pith reviewed 2026-05-12 04:18 UTC · model grok-4.3
The pith
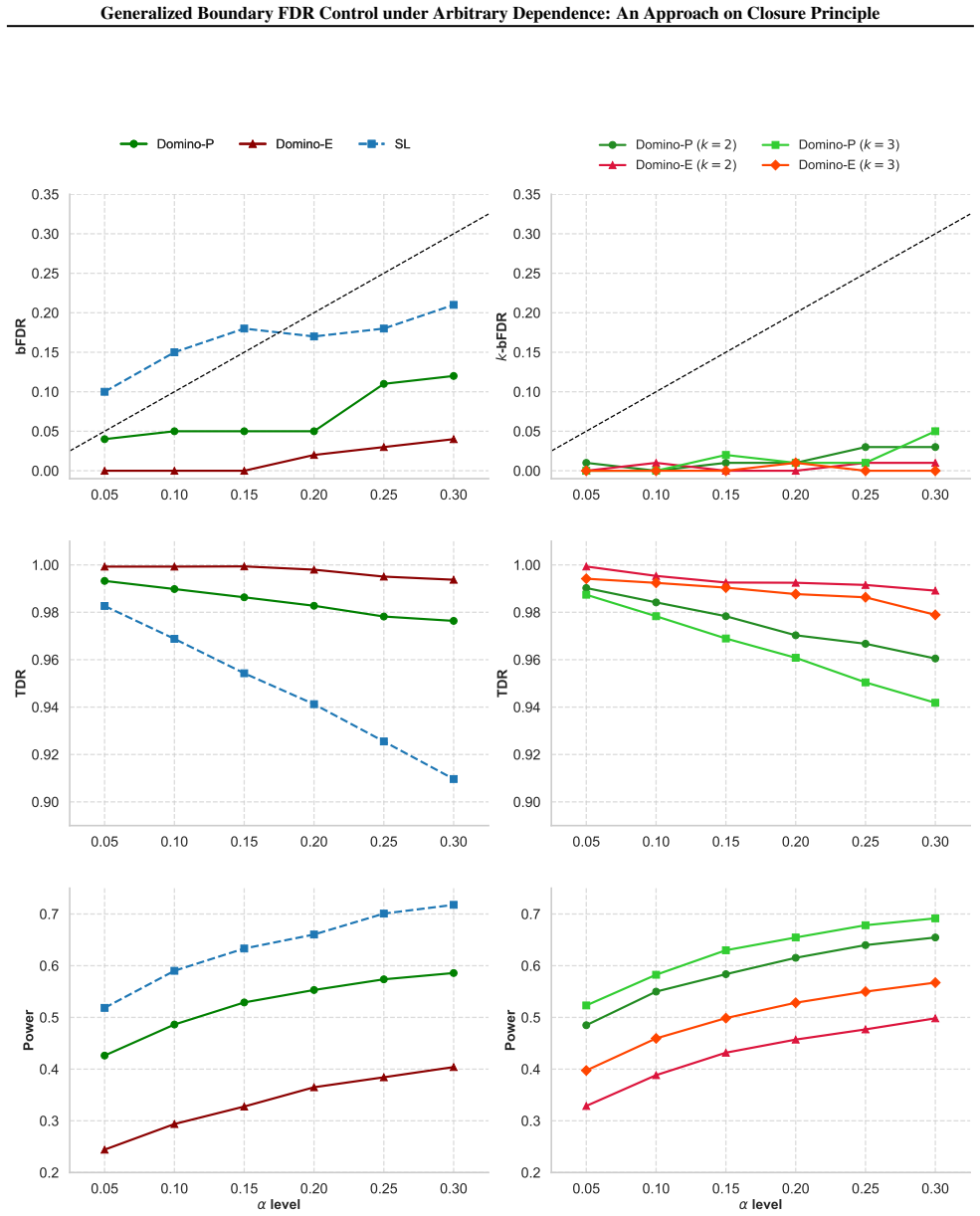
The Domino framework guarantees control of k-bFDR for the k least significant discoveries under arbitrary dependence using p-values or e-values.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By adapting the closure principle, the Domino algorithm enforces k-bFDR control under arbitrary dependence for both p-values and e-values; the procedure is theoretically valid, consistently meets the k-bFDR target in simulations, and yields rejection sets with greater practical significance in real-data analyses.
What carries the argument
Domino, the closure-principle algorithm that constructs a rejection set whose k least significant members satisfy the k-bFDR bound.
If this is right
- k-bFDR is controlled for any fixed k and any dependence structure.
- The same algorithm applies unchanged to both p-value and e-value inputs.
- The resulting rejection sets contain fewer unreliable boundary discoveries than standard FDR methods.
- Theoretical validity follows from the closure construction without extra assumptions.
- Real-data rejection sets exhibit higher practical significance under k-bFDR control.
Where Pith is reading between the lines
- The approach could be combined with existing step-up or step-down procedures to trade off power and k-bFDR control in a single pass.
- If k-bFDR control is adopted, analysts in genomics or neuroimaging might re-examine previously reported marginal signals for robustness.
- Extensions that let k grow with the total number of tests would allow adaptive boundary control without re-deriving the closure rule.
- The framework suggests that other boundary-type error rates could be handled by similar closure arguments once they are expressed as properties of the ordered rejection set.
Load-bearing premise
The closure principle can be applied directly to produce a set that controls k-bFDR without any restrictions on how the test statistics depend on one another.
What would settle it
A Monte Carlo experiment with strongly dependent test statistics in which the empirical proportion of false k-bFDR events exceeds the nominal level would refute the guarantee.
Figures
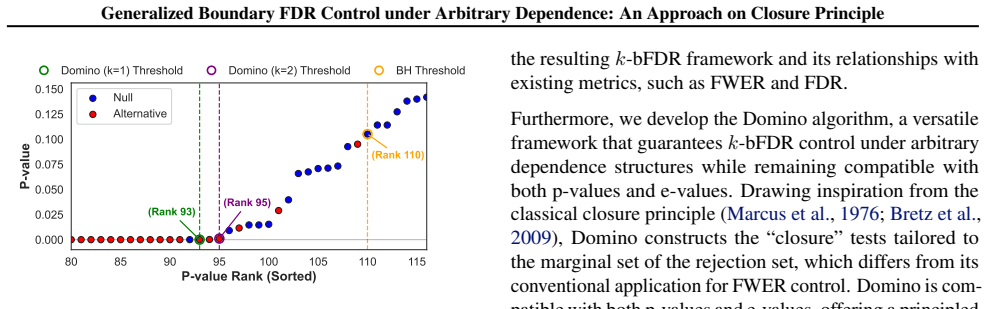
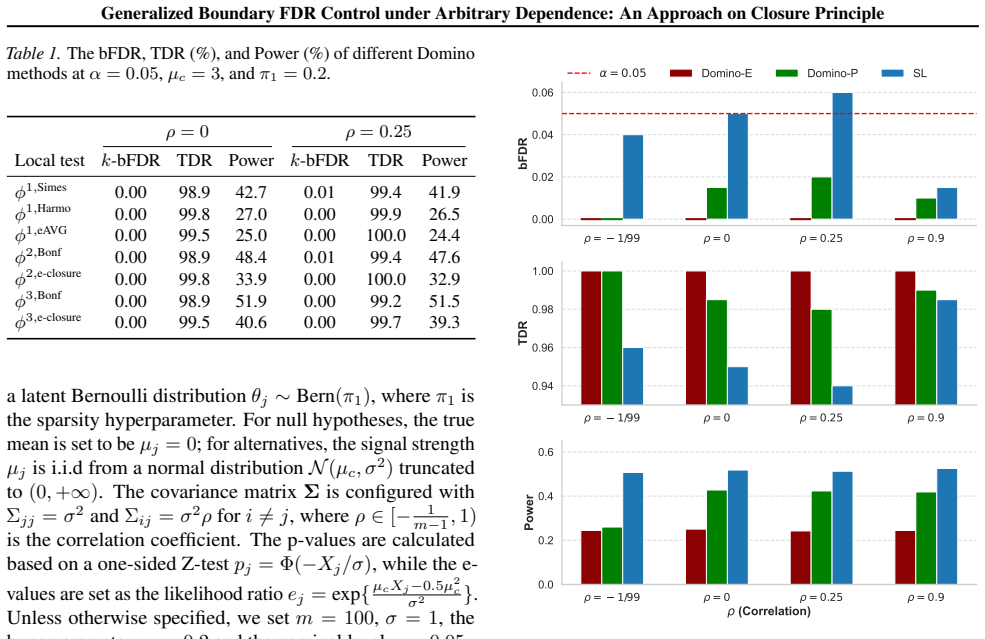
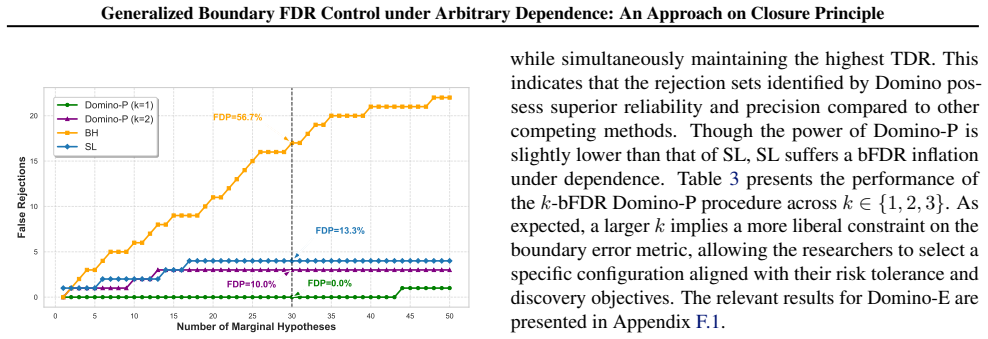
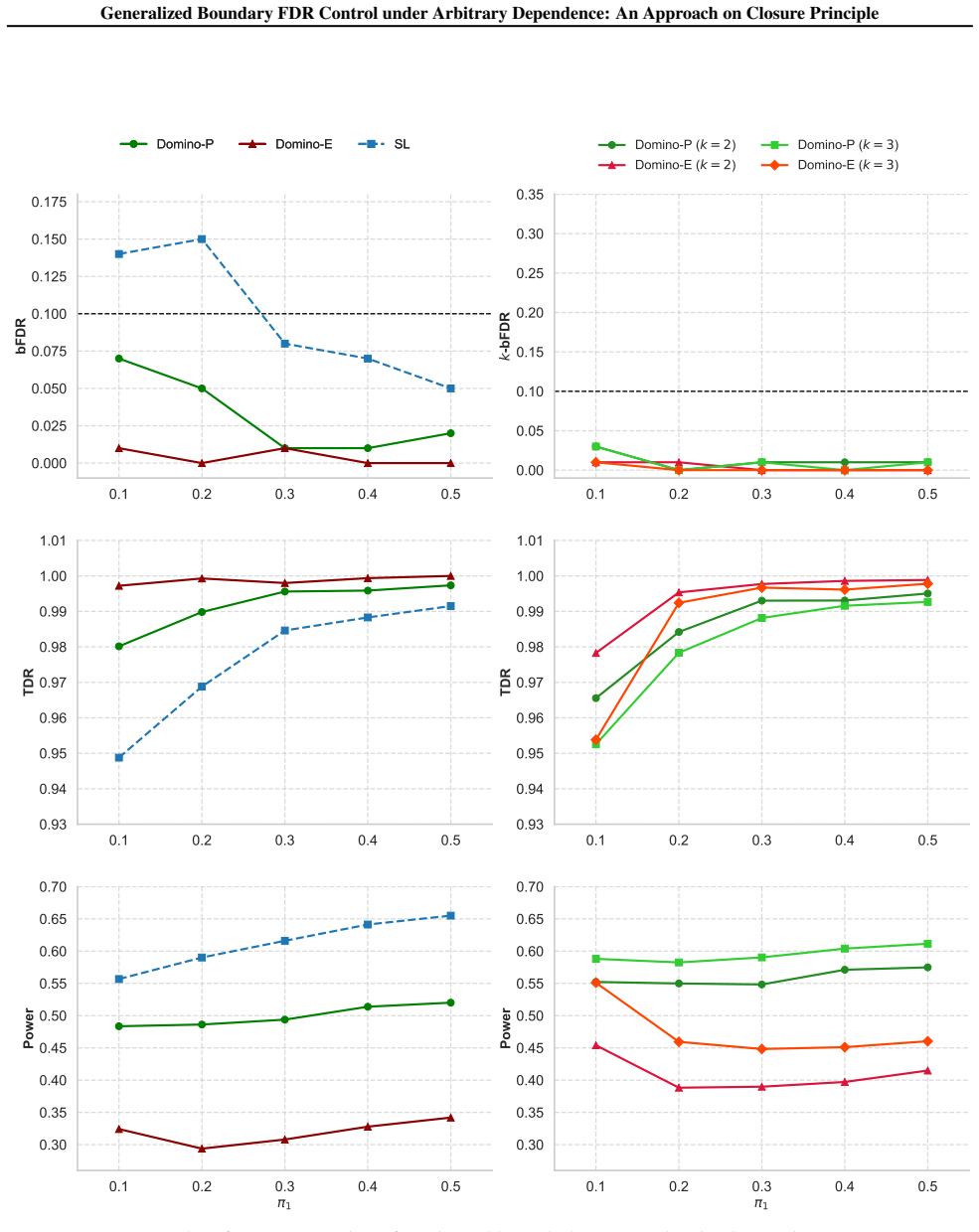

read the original abstract
False discovery rate (FDR) is a cornerstone of modern multiple testing. However, it often fails to guarantee the reliability of "marginal" discoveries that lie at the boundary of the rejection set, which are often crucial in high-precision applications. While recent works (Soloff et al., 2024; Xiang et al., 2025) introduced the boundary false discovery rate (bFDR) to control the error probability at the marginal discovery, their method relies on restrictive assumptions such as independence or specific prior distributions. In this paper, we first propose $k$-bFDR, a novel generalization that controls the error probability of the $k$ least significant discoveries. We then provide a systematic investigation into the theoretical relationship between $k$-bFDR and existing error metrics. Furthermore, building upon the closure principle, we develop Domino, a unified framework that guarantees $k$-bFDR control under arbitrary dependence, applicable for both p-values and e-values. We prove the theoretical validity of the proposed Domino algorithm and demonstrate through extensive numerical experiments that it consistently achieves rigorous $k$-bFDR control while identifying trustworthy marginal discoveries. Analyses of real data reveal that $k$-bFDR control yields higher-quality rejection sets with greater practical significance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces k-bFDR as a generalization of boundary FDR that controls the error probability specifically for the k least significant (boundary) discoveries in the ordered rejection set. It develops the Domino algorithm by adapting the closure principle to guarantee k-bFDR control under arbitrary dependence structures, applicable to both p-values and e-values. The authors claim to prove the theoretical validity of Domino, demonstrate consistent control via numerical experiments, and show improved practical significance on real data compared to existing methods.
Significance. If the central validity proof holds without hidden dependence assumptions, the result would meaningfully extend boundary-error control beyond the independence or parametric restrictions in Soloff et al. (2024) and Xiang et al. (2025), offering a unified closure-based procedure for both p- and e-values. The explicit treatment of the k-boundary set and the systematic comparison to existing error rates are positive features.
major comments (2)
- [§3] §3 (Domino algorithm and closure adaptation): The mapping from closed tests to k-bFDR control is not derived explicitly. The closure principle guarantees FWER control by rejecting only when all supersets are rejected, but k-bFDR concerns the marginal error probability on the k-th ordered statistic; under arbitrary (including negative) dependence the joint distribution of order statistics need not preserve the required monotonicity, so the bound P(k-boundary error) ≤ α may fail. The manuscript must supply the key steps showing how the closed-test rejection set directly implies the k-bFDR inequality without additional assumptions on the dependence structure.
- [Theorem 1] Theorem 1 (or equivalent validity statement): The proof sketch asserts validity for both p-values and e-values under arbitrary dependence, yet the provided derivation appears to rely only on marginal validity or union-bound arguments. A concrete counter-example or explicit calculation under negative dependence (e.g., equicorrelated Gaussian with ρ < 0) should be added to confirm that the k-order control is preserved.
minor comments (2)
- [Definition 2] Notation for the k-boundary set (Definition 2) should be clarified with an explicit indicator function rather than verbal description to avoid ambiguity when k > 1.
- [Numerical experiments] The simulation section reports empirical k-bFDR but does not tabulate the realized dependence structures (e.g., correlation matrices or copula parameters) used to generate the negative-dependence cases; this makes reproducibility of the “arbitrary dependence” claim difficult.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review of our manuscript. The comments raise important points about the explicitness of the derivation and the need for verification under negative dependence. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [§3] §3 (Domino algorithm and closure adaptation): The mapping from closed tests to k-bFDR control is not derived explicitly. The closure principle guarantees FWER control by rejecting only when all supersets are rejected, but k-bFDR concerns the marginal error probability on the k-th ordered statistic; under arbitrary (including negative) dependence the joint distribution of order statistics need not preserve the required monotonicity, so the bound P(k-boundary error) ≤ α may fail. The manuscript must supply the key steps showing how the closed-test rejection set directly implies the k-bFDR inequality without additional assumptions on the dependence structure.
Authors: We agree that the connection between the closed-test rejection set and the k-bFDR bound can be made more explicit. The proof in Theorem 1 proceeds by showing that the event of a k-boundary error (i.e., at least one false discovery among the k least significant rejections) is contained in the event that at least one relevant closed hypothesis is falsely rejected. Because the Domino procedure rejects a hypothesis only when all its supersets are rejected, this containment holds by construction of the closed family. The resulting probability is therefore bounded by α via the FWER control of the closed tests. This argument relies solely on the definition of the closed testing procedure and does not invoke any dependence assumptions or monotonicity of order statistics beyond the ordering of the rejection set itself. In the revised manuscript we will insert a dedicated subsection in §3 that spells out these intermediate steps, including the explicit containment argument and why it remains valid for arbitrary (including negative) dependence. revision: yes
-
Referee: [Theorem 1] Theorem 1 (or equivalent validity statement): The proof sketch asserts validity for both p-values and e-values under arbitrary dependence, yet the provided derivation appears to rely only on marginal validity or union-bound arguments. A concrete counter-example or explicit calculation under negative dependence (e.g., equicorrelated Gaussian with ρ < 0) should be added to confirm that the k-order control is preserved.
Authors: The proof of Theorem 1 is not based on marginal validity or a simple union bound; it uses the exhaustive intersection property of the closed testing procedure, which controls the probability of any false rejection within the closed family at level α regardless of the dependence structure among the test statistics. This directly implies the k-bFDR bound for both p-values and e-values. Nevertheless, to make the robustness under negative dependence fully transparent, we will add a new numerical illustration in the revised version. Specifically, we will report results for equicorrelated Gaussian test statistics with ρ = −0.5 (and other negative values), showing that the empirical k-bFDR of Domino remains below the nominal α while the procedure still produces non-empty rejection sets. This example will be placed alongside the existing positive-dependence and independence simulations. revision: yes
Circularity Check
No circularity: derivation builds on external closure principle with independent proof claim
full rationale
The paper adapts the standard closure principle (from prior literature such as Marcus et al.) to define the Domino algorithm for k-bFDR control. The abstract and description present a new theoretical proof of validity under arbitrary dependence for both p-values and e-values, without any quoted reduction of the k-bFDR bound to a fitted parameter, self-defined quantity, or self-citation chain. No equations or steps in the provided material equate the claimed control result to its inputs by construction. The central validity argument is treated as an independent derivation rather than a renaming or smuggling of an ansatz. This is the expected non-finding for a paper whose load-bearing step is an external principle plus a stated proof.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Closure principle from multiple testing theory
invented entities (2)
-
k-bFDR
no independent evidence
-
Domino algorithm
no independent evidence
Reference graph
Works this paper leans on
-
[1]
The Annals of Statistics , volume=
The edge of discovery: Controlling the local false discovery rate at the margin , author=. The Annals of Statistics , volume=. 2024 , publisher=
work page 2024
-
[2]
Journal of the Royal statistical society: series B (Methodological) , volume=
Controlling the false discovery rate: a practical and powerful approach to multiple testing , author=. Journal of the Royal statistical society: series B (Methodological) , volume=. 1995 , publisher=
work page 1995
-
[3]
The Annals of Statistics , volume=
Generalizations of the familywise error rate , author=. The Annals of Statistics , volume=
-
[4]
A frequentist local false discovery rate , author=. Biometrika , pages=. 2025 , publisher=
work page 2025
-
[5]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
False discovery rate control with e-values , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2022 , publisher=
work page 2022
-
[6]
The Annals of Statistics , volume=
E-values: Calibration, combination and applications , author=. The Annals of Statistics , volume=. 2021 , publisher=
work page 2021
-
[7]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Derandomised knockoffs: leveraging e-values for false discovery rate control , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2024 , publisher=
work page 2024
-
[8]
A note on e-values and multiple testing , author=. Biometrika , volume=. 2025 , publisher=
work page 2025
-
[9]
arXiv preprint arXiv:2501.09015 , year=
Family-wise error rate control with e-values , author=. arXiv preprint arXiv:2501.09015 , year=
-
[10]
International Conference on Artificial Intelligence and Statistics , pages=
Online multiple testing with e-values , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2024 , organization=
work page 2024
-
[11]
arXiv preprint arXiv:2601.02610 , year=
Conformal novelty detection with false discovery rate control at the boundary , author=. arXiv preprint arXiv:2601.02610 , year=
-
[12]
On closed testing procedures with special reference to ordered analysis of variance , author=. Biometrika , volume=. 1976 , publisher=
work page 1976
-
[13]
arXiv preprint arXiv:2509.02517 , year=
Bringing closure to false discovery rate control: A general principle for multiple testing , author=. arXiv preprint arXiv:2509.02517 , year=
-
[14]
Statistics in medicine , volume=
A graphical approach to sequentially rejective multiple test procedures , author=. Statistics in medicine , volume=. 2009 , publisher=
work page 2009
-
[15]
The Annals of Statistics , volume=
The online closure principle , author=. The Annals of Statistics , volume=. 2024 , publisher=
work page 2024
-
[16]
arXiv preprint arXiv:2407.20683 , year=
An online generalization of the (e-) Benjamini-Hochberg procedure , author=. arXiv preprint arXiv:2407.20683 , year=
-
[17]
An improved Bonferroni procedure for multiple tests of significance , author=. Biometrika , volume=. 1986 , publisher=
work page 1986
-
[18]
Combining p-values via averaging , author=. Biometrika , volume=. 2020 , publisher=
work page 2020
-
[19]
Journal of the American Statistical Association , volume=
Cauchy combination test: a powerful test with analytic p-value calculation under arbitrary dependency structures , author=. Journal of the American Statistical Association , volume=. 2020 , publisher=
work page 2020
-
[20]
The Annals of Statistics , volume=
The control of the false discovery rate in multiple testing under dependency , author=. The Annals of Statistics , volume=. 2001 , publisher=
work page 2001
-
[21]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
A direct approach to false discovery rates , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2002 , publisher=
work page 2002
-
[22]
Journal of the American Statistical Association , volume=
Oracle and adaptive compound decision rules for false discovery rate control , author=. Journal of the American Statistical Association , volume=. 2007 , publisher=
work page 2007
-
[23]
Electronic Journal of Statistics , volume=
On stepwise control of the generalized familywise error rate , author=. Electronic Journal of Statistics , volume=
-
[24]
The Annals of Statistics , volume=
Generalizing Simes' test and Hochberg's stepup procedure , author=. The Annals of Statistics , volume=
-
[25]
Teoria statistica delle classi e calcolo delle probabilit\`
Bonferroni, Carlo , journal=. Teoria statistica delle classi e calcolo delle probabilit\`
-
[26]
Journal of the American statistical association , volume=
Multiple comparisons among means , author=. Journal of the American statistical association , volume=. 1961 , publisher=
work page 1961
-
[27]
Scandinavian journal of statistics , volume=
A Simple Sequentially Rejective Multiple Test Procedure , author=. Scandinavian journal of statistics , volume=. 1979 , publisher=
work page 1979
-
[28]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
-investing: a procedure for sequential control of expected false discoveries , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2008 , publisher=
work page 2008
-
[29]
The Annals of Statistics , volume=
The positive false discovery rate: a Bayesian interpretation and the q-value , author=. The Annals of Statistics , volume=. 2003 , publisher=
work page 2003
-
[30]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Operating characteristics and extensions of the false discovery rate procedure , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2002 , publisher=
work page 2002
-
[31]
The Annals of Statistics , volume=
A stochastic process approach to false discovery control , author=. The Annals of Statistics , volume=
-
[32]
Journal of the American Statistical Association , volume=
Exceedance control of the false discovery proportion , author=. Journal of the American Statistical Association , volume=. 2006 , publisher=
work page 2006
-
[33]
Journal of Business & Economic Statistics , volume=
An empirical bayes approach to controlling the false discovery exceedance , author=. Journal of Business & Economic Statistics , volume=. 2024 , publisher=
work page 2024
-
[34]
Multiple Testing for Exploratory Research , author=. Statistical Science , volume=
-
[35]
Discovery and saturation analysis of cancer genes across 21 tumour types , author=. Nature , volume=. 2014 , publisher=
work page 2014
-
[36]
Defining a cancer dependency map , author=. Cell , volume=. 2017 , publisher=
work page 2017
-
[37]
The Annals of Statistics , volume=
On the existence of powerful p-values and e-values for composite hypotheses , author=. The Annals of Statistics , volume=. 2024 , publisher=
work page 2024
-
[38]
Pathology-Research and Practice , volume=
Gene expression patterns distinguish breast carcinomas from normal breast tissues: the Malaysian context , author=. Pathology-Research and Practice , volume=. 2010 , publisher=
work page 2010
-
[39]
Nucleic acids research , volume=
Enrichr: a comprehensive gene set enrichment analysis web server 2016 update , author=. Nucleic acids research , volume=. 2016 , publisher=
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.