Recognition: 2 theorem links
· Lean TheoremTensor Product Representation Probes Reveal Shared Structure Across Linear Directions
Pith reviewed 2026-05-12 03:26 UTC · model grok-4.3
The pith
Linear directions for Othello board states decompose into tensor products of square and color embeddings
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
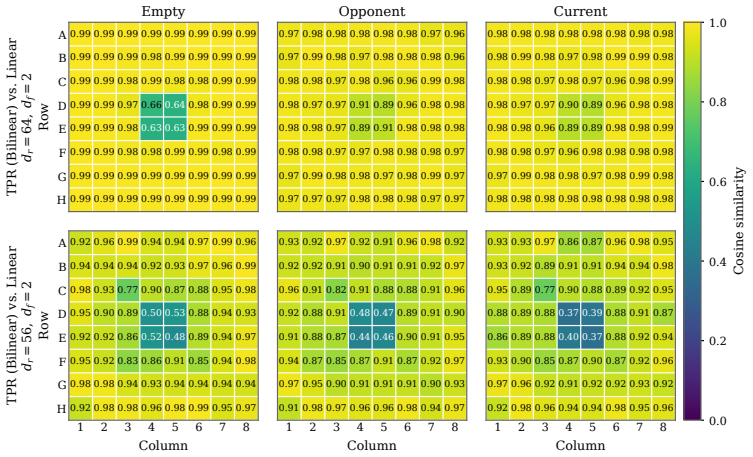
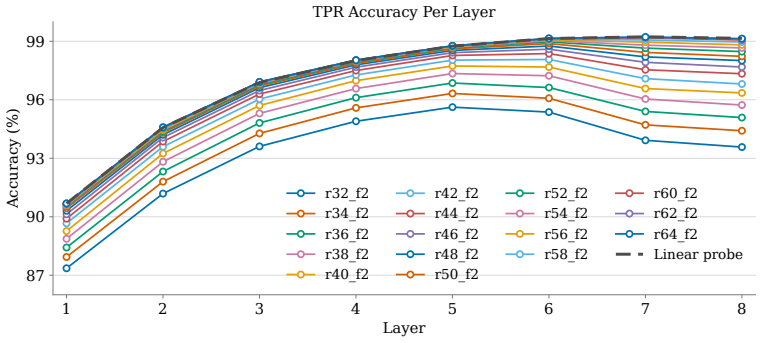
In a model trained on the board game Othello, board states are linearly decodable but also exhibit tensor product structure. Training TPR probes to recover shared structure among the linear probes produces a factorization into square-embeddings, color-embeddings, and a binding matrix. The TPR probe weights show geometric signatures matching the board layout. The linear probes can be recovered directly from the TPR parameters, indicating that directional representations may be projections of more structured underlying representations.
What carries the argument
Tensor product representation (TPR) probes, which decompose linear directions into square-embeddings and color-embeddings composed by a binding matrix.
If this is right
- The weights of the TPR probe contain geometric signatures that align with the structure of the Othello board.
- The original linear probes can be recovered directly from the parameters of the TPR probe.
- Directional representations in the model are projections of more structured underlying representations.
- This reveals shared structure across the linear directions for different board positions.
Where Pith is reading between the lines
- Similar TPR probe techniques could be used in language models to find structure in what appear to be isolated linear concepts.
- The factorization might enable more precise interventions by editing embeddings or the binding matrix separately.
- The success in a structured game domain suggests the method can test the limits of linear probing in other settings.
Load-bearing premise
That training the TPR probe on the linear probes extracts genuine shared underlying structure rather than imposing an artificial factorization.
What would settle it
If the linear probes reconstructed from the TPR probe parameters do not closely match the original linear probes in direction or accuracy on board state prediction, the claim of shared structure would fail.
Figures








read the original abstract
While researchers are finding concepts represented as linear directions in language models, a bag of linear directions fails to capture relational structure. To better understand this dichotomy, we study a model with known linear representations, but trained in a highly structured domain -- the board game Othello. While the model's internal board-state representation is linearly decodable, we find additional structure in the form of tensor product representations (TPRs). We train TPR probes to recover shared structure amongst the linear probes, yielding a factorization into square-embeddings, color-embeddings, and a binding matrix that composes them to construct the model's board-state representation. We find geometric signatures within the weights of our TPR probe that align with the structure of the board, but perhaps more importantly, that the linear probes can be recovered directly from the parameters of our TPR probe. Our findings suggest that directional representations may be projections of more structured underlying representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines an Othello-playing transformer model whose board-state representations are known to be linearly decodable. It introduces Tensor Product Representation (TPR) probes trained on the outputs of these linear probes to extract a shared factorization consisting of square-embeddings, color-embeddings, and a binding matrix. The authors report that the original linear probes can be exactly recovered from the learned TPR parameters and that the TPR weights exhibit geometric alignments with the physical board layout. They conclude that linear directions may be projections of more structured underlying representations.
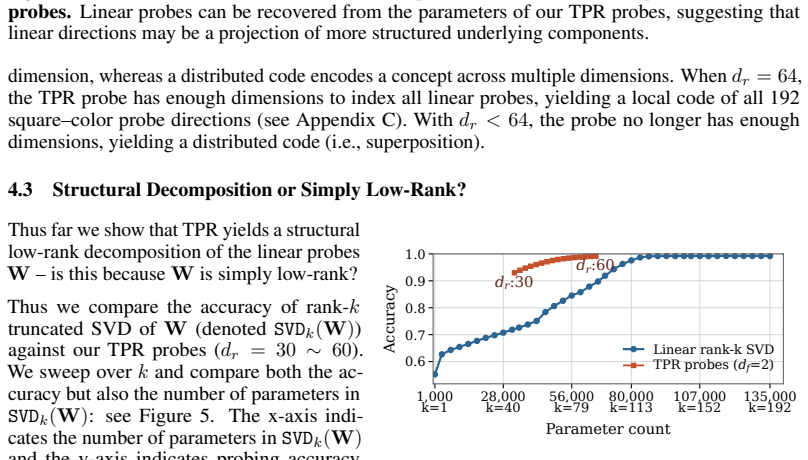
Significance. If the central claim is substantiated, the work offers a concrete method for moving beyond bag-of-directions analyses toward relational structure in model representations, using a controlled domain where ground-truth board geometry is available. The direct recoverability result and the reported geometric signatures are potentially useful contributions to mechanistic interpretability. However, the significance is currently limited by the absence of controls that would distinguish probe-imposed structure from model-intrinsic structure.
major comments (2)
- [Section 3.2] Section 3.2 (TPR probe training): The probe is optimized to reconstruct the linear-probe outputs via the tensor-product decomposition. Consequently, the reported recoverability of the linear probes from the TPR parameters (abstract and §4.1) is guaranteed by a successful fit and does not constitute independent evidence that the factorization reflects genuine shared structure inside the model rather than the inductive bias of the TPR architecture.
- [Section 4.3] Section 4.3 (geometric signatures): The alignment of embedding and binding-matrix weights with board geometry is presented as supporting evidence, yet no quantitative comparison to random embeddings, shuffled board targets, or alternative low-rank factorizations is provided. Without such baselines it remains possible that the observed geometry is a consequence of the Othello-specific probe targets rather than an intrinsic property of the model.
minor comments (2)
- [Abstract] The abstract and introduction would benefit from a concise statement of the quantitative metrics (e.g., reconstruction MSE, alignment scores) used to evaluate the TPR probe.
- [Section 3] Notation for the binding matrix and the two embedding sets should be introduced once and used consistently; occasional reuse of the same symbol for different quantities appears in §3.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our manuscript. We address each of the major comments point-by-point below and describe the revisions we plan to make to strengthen the paper.
read point-by-point responses
-
Referee: [Section 3.2] Section 3.2 (TPR probe training): The probe is optimized to reconstruct the linear-probe outputs via the tensor-product decomposition. Consequently, the reported recoverability of the linear probes from the TPR parameters (abstract and §4.1) is guaranteed by a successful fit and does not constitute independent evidence that the factorization reflects genuine shared structure inside the model rather than the inductive bias of the TPR architecture.
Authors: We acknowledge the validity of this observation: successful reconstruction does imply recoverability by construction. Our contribution lies in demonstrating that the linear probes for Othello board states can be accurately decomposed into a shared tensor-product structure consisting of square embeddings, color embeddings, and a binding matrix. This decomposition is not arbitrary; it reveals a compositional organization that aligns with the game's rules. To address potential concerns regarding the TPR's inductive bias, we will include additional experiments in the revision comparing the TPR fit to other factorization techniques, such as non-negative matrix factorization or principal component analysis applied directly to the probe weights. We will also revise the abstract and Section 4.1 to emphasize that we are showing the linear directions admit such a factorization, providing evidence for shared structure among them. revision: partial
-
Referee: [Section 4.3] Section 4.3 (geometric signatures): The alignment of embedding and binding-matrix weights with board geometry is presented as supporting evidence, yet no quantitative comparison to random embeddings, shuffled board targets, or alternative low-rank factorizations is provided. Without such baselines it remains possible that the observed geometry is a consequence of the Othello-specific probe targets rather than an intrinsic property of the model.
Authors: We agree that quantitative baselines are necessary to substantiate the geometric signatures. In the revised version of the manuscript, we will add comparisons of the observed alignments against those from random embeddings, embeddings trained on shuffled board targets, and alternative low-rank decompositions. These controls will quantify whether the alignments with the physical board layout exceed what would be expected from the probe targets alone, thereby providing stronger evidence that the structure is intrinsic to the model's representations. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper trains TPR probes on existing linear probes for Othello board states to extract a factorization (square-embeddings, color-embeddings, binding matrix). Recovery of the original linear probes from TPR parameters is an outcome of this training but does not reduce the central claim to a tautology by construction, as the factorization introduces additional interpretable structure and the paper reports independent geometric signatures in the TPR weights that align with board geometry. No equations equate a prediction directly to fitted inputs, no load-bearing self-citations are used to justify uniqueness or ansatzes, and the overall argument remains self-contained against the model's known linear decodability without forcing the result from its inputs alone.
Axiom & Free-Parameter Ledger
free parameters (1)
- square-embeddings, color-embeddings, and binding matrix
axioms (1)
- domain assumption The model's internal board-state representation is linearly decodable
invented entities (1)
-
TPR probe
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanreality_from_one_distinction unclearWe train TPR probes to recover shared structure amongst the linear probes, yielding a factorization into square-embeddings, color-embeddings, and a binding matrix that composes them
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearlinear probes can be recovered directly from the parameters of our TPR probe
Reference graph
Works this paper leans on
-
[1]
Xiaoyan Bai, Itamar Pres, Yuntian Deng, Chenhao Tan, Stuart Shieber, Fernanda Viégas, Martin Wattenberg, and Andrew Lee. Why can’t transformers learn multiplication? reverse-engineering reveals long-range dependency pitfalls.arXiv preprint arXiv:2510.00184,
-
[2]
Temporal sparse autoencoders: Leveraging the sequential nature of language for interpretability
Usha Bhalla, Alex Oesterling, Claudio Mayrink Verdun, Himabindu Lakkaraju, and Flavio P Calmon. Temporal sparse autoencoders: Leveraging the sequential nature of language for interpretability. arXiv preprint arXiv:2511.05541,
-
[3]
Bart Bussmann, Noa Nabeshima, Adam Karvonen, and Neel Nanda. Learning multi-level features with matryoshka sparse autoencoders.arXiv preprint arXiv:2503.17547,
-
[4]
Yida Chen, Aoyu Wu, Trevor DePodesta, Catherine Yeh, Kenneth Li, Nicholas Castillo Marin, Oam Patel, Jan Riecke, Shivam Raval, Olivia Seow, et al. Designing a dashboard for transparency and control of conversational ai.arXiv preprint arXiv:2406.07882,
-
[5]
arXiv preprint arXiv:2506.03093 , year=
Valérie Costa, Thomas Fel, Ekdeep Singh Lubana, Bahareh Tolooshams, and Demba Ba. From flat to hierarchical: Extracting sparse representations with matching pursuit.arXiv preprint arXiv:2506.03093,
-
[6]
arXiv preprint arXiv:2405.14860 , year=
Joshua Engels, Eric J Michaud, Isaac Liao, Wes Gurnee, and Max Tegmark. Not all language model features are one-dimensionally linear.arXiv preprint arXiv:2405.14860,
- [7]
-
[8]
Tensor product generation networks for deep nlp modeling
Qiuyuan Huang, Paul Smolensky, Xiaodong He, Li Deng, and Dapeng Wu. Tensor product generation networks for deep nlp modeling. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 1263–1273,
work page 2018
-
[9]
Yichen Jiang, Asli Celikyilmaz, Paul Smolensky, Paul Soulos, Sudha Rao, Hamid Palangi, Roland Fernandez, Caitlin Smith, Mohit Bansal, and Jianfeng Gao. Enriching transformers with struc- tured tensor-product representations for abstractive summarization. In Kristina Toutanova, Anna Rumshisky, Luke Zettlemoyer, Dilek Hakkani-Tur, Iz Beltagy, Steven Bethard...
work page 2021
-
[10]
doi: 10.18653/ v1/2021.naacl-main.381
Association for Computational Linguistics. doi: 10.18653/ v1/2021.naacl-main.381. URLhttps://aclanthology.org/2021.naacl-main.381/. Subhash Kantamneni and Max Tegmark. Language models use trigonometry to do addition.arXiv preprint arXiv:2502.00873,
-
[11]
10 Andrew Lee, Xiaoyan Bai, Itamar Pres, Martin Wattenberg, Jonathan K Kummerfeld, and Rada Mihalcea. A mechanistic understanding of alignment algorithms: A case study on dpo and toxicity. arXiv preprint arXiv:2401.01967,
-
[12]
Andrew Lee, Lihao Sun, Chris Wendler, Fernanda Viégas, and Martin Wattenberg. The geometry of self-verification in a task-specific reasoning model.arXiv preprint arXiv:2504.14379, 2025a. Andrew Lee, Melanie Weber, Fernanda Viégas, and Martin Wattenberg. Shared global and local geometry of language model embeddings.arXiv preprint arXiv:2503.21073, 2025b. A...
-
[13]
arXiv preprint arXiv:2210.13382 , year=
Kenneth Li, Aspen K Hopkins, David Bau, Fernanda Viegas, Hanspeter Pfister, and Martin Watten- berg. Emergent world representations: Exploring a sequence model trained on a synthetic task. arXiv preprint arXiv:2210.13382,
-
[14]
Learning a generative meta-model of llm activations.arXiv preprint arXiv:2602.06964,
Grace Luo, Jiahai Feng, Trevor Darrell, Alec Radford, and Jacob Steinhardt. Learning a generative meta-model of llm activations.arXiv preprint arXiv:2602.06964,
-
[15]
The origins of representation manifolds in large language models.arXiv preprint arXiv:2505.18235,
Alexander Modell, Patrick Rubin-Delanchy, and Nick Whiteley. The origins of representation manifolds in large language models.arXiv preprint arXiv:2505.18235,
-
[16]
Mark Muchane, Sean Richardson, Kiho Park, and Victor Veitch. Incorporating hierarchical semantics in sparse autoencoder architectures.arXiv preprint arXiv:2506.01197,
-
[17]
Aaron Mueller, Andrew Lee, Shruti Joshi, Ekdeep Singh Lubana, Dhanya Sridhar, and Patrik Reizinger. From isolation to entanglement: When do interpretability methods identify and disen- tangle known concepts?arXiv preprint arXiv:2512.15134,
-
[18]
URL https://arxiv.org/abs/ 2309.00941. Core Francisco Park, Andrew Lee, Ekdeep Singh Lubana, Yongyi Yang, Maya Okawa, Kento Nishi, Martin Wattenberg, and Hidenori Tanaka. Iclr: In-context learning of representations.arXiv preprint arXiv:2501.00070, 2024a. Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geometry of...
-
[19]
Taewon Park, Inchul Choi, and Minho Lee. Attention-based iterative decomposition for tensor product representation.arXiv preprint arXiv:2406.01012, 2024b. Raphaël Sarfati, Eric Bigelow, Daniel Wurgaft, Jack Merullo, Atticus Geiger, Owen Lewis, Tom McGrath, and Ekdeep Singh Lubana. The shape of beliefs: Geometry, dynamics, and interventions along represent...
-
[20]
Imanol Schlag, Paul Smolensky, Roland Fernandez, Nebojsa Jojic, Jürgen Schmidhuber, and Jianfeng Gao. Enhancing the transformer with explicit relational encoding for math problem solving.arXiv preprint arXiv:1910.06611,
-
[21]
Transformers learn factored representations.arXiv preprint arXiv:2602.02385,
Adam Shai, Loren Amdahl-Culleton, Casper L Christensen, Henry R Bigelow, Fernando E Rosas, Alexander B Boyd, Eric A Alt, Kyle J Ray, and Paul M Riechers. Transformers learn factored representations.arXiv preprint arXiv:2602.02385,
-
[22]
Valence-Arousal Subspace in LLMs: Circular Emotion Geometry and Multi-Behavioral Control
Lihao Sun, Lewen Yan, Xiaoya Lu, Andrew Lee, Jie Zhang, and Jing Shao. Valence-arousal subspace in llms: Circular emotion geometry and multi-behavioral control.arXiv preprint arXiv:2604.03147,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Shuai Tang, Paul Smolensky, and Virginia de Sa. Learning distributed representations of symbolic structure using binding and unbinding operations.arXiv preprint arXiv:1810.12456,
-
[24]
URL https://api. semanticscholar.org/CorpusID:70175501. Curt Tigges, Oskar John Hollinsworth, Atticus Geiger, and Neel Nanda. Linear representations of sentiment in large language models.arXiv preprint arXiv:2310.15154,
-
[25]
Martin Wattenberg and Fernanda B Viégas. Relational composition in neural networks: A survey and call to action.arXiv preprint arXiv:2407.14662,
-
[26]
Neural manifold geome- try encodes feature fields
Julian Yocum, Cameron Allen, Bruno Olshausen, and Stuart Russell. Neural manifold geome- try encodes feature fields. InNeurIPS 2025 Workshop on Symmetry and Geometry in Neural Representations,
work page 2025
-
[27]
URLhttps://openreview.net/forum?id=MwU86qfCTW. 12 (a) Digits as Directions (b) Digits Form a Pentagonal Prism 0 1 2 4 5 6 7 8 9 3 0 1 2 4 5 6 7 8 9 3 Figure 8: Representations of digits in a Transformer trained on multi-digit multiplication may appear as linear directions, but a closer look reveals structure in the form of a pentagonal prism [Bai et al., ...
work page 2025
-
[28]
show that RNN hidden-states can be reconstructed using Tensor Product Decomposition Networks. Feature geometry.In recent years, a large body of interpretability work have found numerous concepts that are encoded as linear directions, and that these representations often generalize across models [Lee et al., 2025b]. Examples include sentiment [Tigges et al...
work page 2023
-
[29]
similarly show that features such as word count and token position can lie on manifolds that are aligned to produce high attention scores. Taken together, these works suggest that linear probes may sometimes only recover local readouts of a richer underlying structure. A good example might be of Bai et al. [2025], who study a toy Transformer trained on mu...
work page 2025
-
[30]
build on this idea to recover a manifold of “posterior beliefs”: by training a family of linear probes across different latent parameter settings of a controlled in-context learning task, and by “tiling” the linear probes together, they are able to recover a manifold over inferred latent parameter values, similarly suggesting that linear readouts stem fro...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.