Recognition: no theorem link
Chebyshev Center-Based Direction Selection for Multi-Objective Optimization and Training PINNs
Pith reviewed 2026-05-12 02:20 UTC · model grok-4.3
The pith
Selecting PINN update directions as the Chebyshev center in the dual cone unifies scale robustness and simultaneous descent under one geometric rule.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
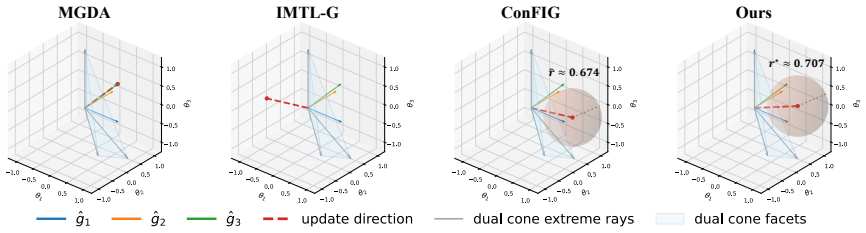
The authors show that the update direction is recovered by solving for the Chebyshev center of the dual cone, defined as the normalized point that maximizes the minimum distance to the cone facets. This choice automatically recovers scale robustness and simultaneous descent on all objectives. The resulting program admits an efficient dual formulation in much lower dimension and carries a convergence guarantee for nonconvex multi-objective losses. On several PINN benchmark problems the method exhibits strong empirical performance.
What carries the argument
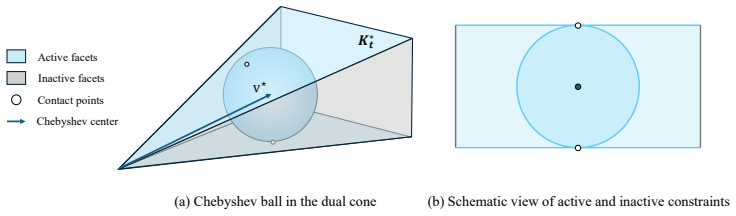
The Chebyshev center of the dual cone: the normalized direction inside the cone that maximizes the radius of the largest ball touching all facets, used to construct the parameter update.
If this is right
- The direction is automatically scale-invariant and descends on every loss term at once.
- The dual formulation reduces computational cost by working in a space whose dimension equals the number of loss terms rather than the model dimension.
- Convergence is guaranteed for nonconvex losses without additional regularity assumptions.
- Earlier direction-selection heuristics appear as special cases or approximations of the same geometric principle.
- The approach supplies a uniform basis for comparing and extending related multi-objective methods.
Where Pith is reading between the lines
- The same dual-cone construction could be applied directly to other multi-task learning settings that require balanced gradient steps.
- Warm-starting the dual solver from the previous iteration might further reduce per-step cost during long training runs.
- Extending the criterion to include local curvature information could produce faster practical convergence while preserving the geometric guarantees.
- The formulation invites systematic comparison with Pareto-front methods to see which geometric rule better matches practitioner needs.
Load-bearing premise
Maximizing the minimum distance to the facets of the dual cone is the single geometric criterion that automatically produces all the practically useful properties without extra constraints.
What would settle it
An experiment in which the computed direction either fails to produce descent on at least one loss term or loses scale robustness after rescaling the losses would falsify the central claim.
Figures

read the original abstract
Physics-informed neural networks (PINNs) are a promising approach for solving partial differential equations (PDEs). Their training, however, is often difficult because multiple loss terms induced by PDE residuals and boundary or initial conditions must be optimized simultaneously. To address this difficulty, existing approaches often construct update directions by explicitly enforcing particular desirable properties, such as scale robustness and simultaneous descent. While effective in many cases, such property-by-property designs can make it unclear which conditions are essential, what geometric principle determines the selected update direction, and how different methods are structurally related. In this work, we formulate update-direction selection for PINN training as a Chebyshev-center problem in the dual cone. The proposed formulation selects a normalized direction that maximizes the minimum distance to the cone facets. The resulting formulation admits an efficient dual problem in a much lower-dimensional space and yields a convergence guarantee in the nonconvex setting. It also recovers the key desirable properties targeted by existing approaches without imposing them separately; rather, they follow from the single geometric criterion underlying the formulation. This makes the selected direction interpretable through a single geometric rule and provides a unified basis for systematically comparing related direction-selection methods. Experiments on several PINN benchmarks further demonstrate strong empirical performance of the proposed method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates update-direction selection for multi-objective optimization and PINN training as a Chebyshev-center problem inside the dual cone of the loss gradients. It selects a normalized direction that maximizes the minimum distance to the cone facets, derives an efficient low-dimensional dual problem, proves a nonconvex convergence guarantee, and claims that scale robustness, simultaneous descent, and related properties emerge automatically from this single geometric rule rather than from explicit constraints.
Significance. If the central geometric claim holds, the work supplies a unified, interpretable basis for comparing direction-selection methods and removes the need for property-by-property engineering. The efficient dual formulation and nonconvex convergence result would be practically useful for PINN training and other multi-task settings.
major comments (3)
- [§3.2] §3.2, the dual-cone Chebyshev-center formulation: the manuscript must explicitly verify that the maximin-distance direction d satisfies ∇L_i · d < 0 for every individual loss gradient (simultaneous descent) and remains invariant under positive rescaling of any L_i. The skeptic note indicates this is not automatic when facets are built from un-normalized gradients; a short derivation or counter-example check is required to confirm no hidden normalization or post-processing is used.
- [Theorem 4.1] Theorem 4.1 (nonconvex convergence): the proof sketch relies on the selected direction being a strict descent direction for the vector of losses. If the geometric property in §3.2 does not guarantee simultaneous descent for all terms, the convergence argument does not go through; the theorem statement and its hypotheses must be tightened to match the actual properties delivered by the Chebyshev center.
- [§5] §5, experimental section: the reported benchmark gains are presented without ablation on the dual-cone construction versus explicit scale-normalization baselines. If the claimed automatic recovery of scale robustness is the key novelty, the tables should isolate whether removing any implicit normalization changes the performance gap.
minor comments (2)
- Notation for the dual cone and its facets is introduced without a small diagram; a one-sentence geometric illustration would help readers unfamiliar with cone duality.
- The abstract states 'yields a convergence guarantee in the nonconvex setting' but does not specify the precise assumptions (e.g., Lipschitz constants, bounded gradients). This should be stated explicitly in the abstract or introduction.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the geometric properties and strengthen the empirical support. We address each major comment below and will incorporate revisions to make the claims fully explicit.
read point-by-point responses
-
Referee: [§3.2] §3.2, the dual-cone Chebyshev-center formulation: the manuscript must explicitly verify that the maximin-distance direction d satisfies ∇L_i · d < 0 for every individual loss gradient (simultaneous descent) and remains invariant under positive rescaling of any L_i. The skeptic note indicates this is not automatic when facets are built from un-normalized gradients; a short derivation or counter-example check is required to confirm no hidden normalization or post-processing is used.
Authors: We agree that an explicit verification strengthens the presentation. By construction, the Chebyshev center lies in the strict interior of the dual cone, which is the set of directions d satisfying ∇L_i · d < 0 for all i (simultaneous descent). For scale invariance: positive rescaling of any gradient leaves the dual cone unchanged because the bounding hyperplanes are defined by the rays of the gradients; the maximin-distance point (normalized) is therefore identical. We will insert a short derivation and a one-line counter-example check (scaling a single gradient) in §3.2 to confirm no post-processing is used. revision: yes
-
Referee: [Theorem 4.1] Theorem 4.1 (nonconvex convergence): the proof sketch relies on the selected direction being a strict descent direction for the vector of losses. If the geometric property in §3.2 does not guarantee simultaneous descent for all terms, the convergence argument does not go through; the theorem statement and its hypotheses must be tightened to match the actual properties delivered by the Chebyshev center.
Authors: With the explicit verification added to §3.2, the direction is guaranteed to be a strict descent direction for every loss term. Consequently the hypotheses of Theorem 4.1 remain valid as stated. We will augment the proof sketch with a direct reference to the new derivation in §3.2 so that the logical chain is transparent. revision: partial
-
Referee: [§5] §5, experimental section: the reported benchmark gains are presented without ablation on the dual-cone construction versus explicit scale-normalization baselines. If the claimed automatic recovery of scale robustness is the key novelty, the tables should isolate whether removing any implicit normalization changes the performance gap.
Authors: We concur that an ablation isolating the geometric construction from explicit normalization is valuable. We will add a new table (or supplementary table) that compares (i) the proposed method, (ii) the same method with forced gradient normalization, and (iii) representative baselines that enforce scale robustness by hand. This will quantify whether the performance gap persists when normalization is removed, directly supporting the claim of automatic recovery. revision: yes
Circularity Check
No circularity: formulation derives properties from independent geometric criterion
full rationale
The paper defines the update direction via a new Chebyshev-center optimization in the dual cone that maximizes min-distance to facets, then states that scale robustness, simultaneous descent, and convergence follow directly from this single rule without separate enforcement. No self-citations appear as load-bearing premises, no parameters are fitted to data and relabeled as predictions, and no prior result by the same authors is invoked to force uniqueness or smuggle an ansatz. The derivation chain is therefore self-contained: the geometric program is stated, its dual is derived, and the claimed properties are asserted to be logical consequences rather than inputs renamed as outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The set of loss gradients defines a cone whose dual admits a well-defined Chebyshev center that corresponds to a useful update direction.
Reference graph
Works this paper leans on
-
[1]
Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational physics, 378:686–707, 2019
work page 2019
-
[2]
Physics-informed machine learning.Nature Reviews Physics, 3(6):422–440, 2021
George Em Karniadakis, Ioannis G Kevrekidis, Lu Lu, Paris Perdikaris, Sifan Wang, and Liu Yang. Physics-informed machine learning.Nature Reviews Physics, 3(6):422–440, 2021
work page 2021
-
[3]
Aditi Krishnapriyan, Amir Gholami, Shandian Zhe, Robert Kirby, and Michael W Mahoney. Characterizing possible failure modes in physics-informed neural networks.Advances in neural information processing systems, 34:26548–26560, 2021
work page 2021
-
[4]
Salvatore Cuomo, Vincenzo Schiano Di Cola, Fabio Giampaolo, Gianluigi Rozza, Maziar Raissi, and Francesco Piccialli. Scientific machine learning through physics–informed neural networks: Where we are and what’s next.Journal of Scientific Computing, 92(3):88, 2022
work page 2022
-
[5]
Chenxi Wu, Min Zhu, Qinyang Tan, Yadhu Kartha, and Lu Lu. A comprehensive study of non-adaptive and residual-based adaptive sampling for physics-informed neural networks. Computer Methods in Applied Mechanics and Engineering, 403:115671, 2023
work page 2023
-
[6]
Sifan Wang, Hanwen Wang, and Paris Perdikaris. On the eigenvector bias of fourier feature networks: From regression to solving multi-scale pdes with physics-informed neural networks. Computer Methods in Applied Mechanics and Engineering, 384:113938, 2021
work page 2021
-
[7]
Sifan Wang, Yujun Teng, and Paris Perdikaris. Understanding and mitigating gradient flow pathologies in physics-informed neural networks.SIAM Journal on Scientific Computing, 43 (5):A3055–A3081, 2021
work page 2021
-
[8]
Mohammad Amin Nabian, Rini Jasmine Gladstone, and Hadi Meidani. Efficient training of physics-informed neural networks via importance sampling.Computer-Aided Civil and Infrastructure Engineering, 36(8):962–977, 2021. 12
work page 2021
-
[9]
Kejun Tang, Xiaoliang Wan, and Chao Yang. Das-pinns: A deep adaptive sampling method for solving high-dimensional partial differential equations.Journal of Computational Physics, 476:111868, 2023
work page 2023
-
[10]
Zhiwei Gao, Liang Yan, and Tao Zhou. Failure-informed adaptive sampling for pinns.SIAM Journal on Scientific Computing, 45(4):A1971–A1994, 2023
work page 2023
-
[11]
Ameya D Jagtap and George Em Karniadakis. Extended physics-informed neural networks (xpinns): A generalized space-time domain decomposition based deep learning framework for nonlinear partial differential equations.Communications in Computational Physics, 28(5), 2020
work page 2020
-
[12]
Junwoo Cho, Seungtae Nam, Hyunmo Yang, Seok-Bae Yun, Youngjoon Hong, and Eunbyung Park. Separable physics-informed neural networks.Advances in Neural Information Processing Systems, 36:23761–23788, 2023
work page 2023
-
[13]
Zhiyuan Zhao, Xueying Ding, and B. Aditya Prakash. PINNsformer: A transformer-based framework for physics-informed neural networks. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=DO2WFXU1Be
work page 2024
-
[14]
Sifan Wang, Xinling Yu, and Paris Perdikaris. When and why pinns fail to train: A neural tangent kernel perspective.Journal of Computational Physics, 449:110768, 2022
work page 2022
-
[15]
Rafael Bischof and Michael A Kraus. Multi-objective loss balancing for physics-informed deep learning.Computer Methods in Applied Mechanics and Engineering, 439:117914, 2025
work page 2025
-
[16]
Youngsik Hwang and Dong-Young Lim. Dual cone gradient descent for training physics-informed neural networks.Advances in Neural Information Processing Systems, 37:98563–98595, 2024
work page 2024
-
[17]
ConFIG: Towards conflict-free training of physics informed neural networks
Qiang Liu, Mengyu Chu, and Nils Thuerey. ConFIG: Towards conflict-free training of physics informed neural networks. InThe Thirteenth International Conference on Learning Represen- tations, 2025. URLhttps://openreview.net/forum?id=APojAzJQiq
work page 2025
-
[18]
Dohyun Bu, Yujung Byun, and Jong-Seok Lee. Harmonized cone for feasible and non-conflict directions in training physics-informed neural networks. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id= PRYl1mO1go
work page 2026
-
[19]
Towards impartial multi-task learning
Liyang Liu, Yi Li, Zhanghui Kuang, Jing-Hao Xue, Yimin Chen, Wenming Yang, Qingmin Liao, and Wayne Zhang. Towards impartial multi-task learning. InInternational conference on learning representations, 2021
work page 2021
-
[20]
Ozan Sener and Vladlen Koltun. Multi-task learning as multi-objective optimization.Advances in neural information processing systems, 31, 2018
work page 2018
-
[21]
Gradient- adaptive policy optimization: Towards multi-objective alignment of large language models
Chengao Li, Hanyu Zhang, Yunkun Xu, Hongyan Xue, Xiang Ao, and Qing He. Gradient- adaptive policy optimization: Towards multi-objective alignment of large language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11214–11232, 2025. 13
work page 2025
-
[22]
Steepest descent methods for multicriteria optimization
Jörg Fliege and Benar Fux Svaiter. Steepest descent methods for multicriteria optimization. Mathematical methods of operations research, 51(3):479–494, 2000
work page 2000
-
[23]
Tianhe Yu, Saurabh Kumar, Abhishek Gupta, Sergey Levine, Karol Hausman, and Chelsea Finn. Gradient surgery for multi-task learning.Advances in neural information processing systems, 33:5824–5836, 2020
work page 2020
-
[24]
Bo Liu, Xingchao Liu, Xiaojie Jin, Peter Stone, and Qiang Liu. Conflict-averse gradient descent for multi-task learning.Advances in neural information processing systems, 34:18878–18890, 2021
work page 2021
-
[25]
Gradient-adaptive pareto optimization for constrained reinforcement learning
Zixian Zhou, Mengda Huang, Feiyang Pan, Jia He, Xiang Ao, Dandan Tu, and Qing He. Gradient-adaptive pareto optimization for constrained reinforcement learning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 11443–11451, 2023
work page 2023
-
[26]
Xiaoyuan Zhang, Xi Lin, and Qingfu Zhang. Pmgda: A preference-based multiple gradient descent algorithm.IEEE Transactions on Emerging Topics in Computational Intelligence, 2025
work page 2025
-
[27]
Reward-free alignment for conflicting objectives.arXiv preprint arXiv:2602.02495, 2026
Peter L Chen, Xiaopeng Li, Xi Chen, and Tianyi Lin. Reward-free alignment for conflicting objectives.arXiv preprint arXiv:2602.02495, 2026
-
[28]
Jiachen Yao, Chang Su, Zhongkai Hao, Songming Liu, Hang Su, and Jun Zhu. Multiadam: Parameter-wise scale-invariant optimizer for multiscale training of physics-informed neural networks. InInternational conference on machine learning, pages 39702–39721. PMLR, 2023
work page 2023
-
[29]
Dmitry Bylinkin, Mikhail Aleksandrov, Savelii Chezhegov, and Aleksandr Beznosikov. En- hancing stability of physics-informed neural network training through saddle-point reformula- tion. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=EQNp3sFrY3
work page 2026
-
[30]
Cambridge university press, 2004
Stephen Boyd and Lieven Vandenberghe.Convex optimization. Cambridge university press, 2004
work page 2004
-
[31]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[32]
Zhongkai Hao, Jiachen Yao, Chang Su, Hang Su, Ziao Wang, Fanzhi Lu, Zeyu Xia, Yichi Zhang, Songming Liu, Lu Lu, et al. Pinnacle: A comprehensive benchmark of physics-informed neural networks for solving pdes.Advances in Neural Information Processing Systems, 37: 76721–76774, 2024
work page 2024
-
[33]
Understanding the difficulty of training deep feedforward neuralnetworks
Xavier Glorot and Yoshua Bengio. Understanding the difficulty of training deep feedforward neuralnetworks. InProceedings of the thirteenth international conference on artificial intelligence and statistics, pages 249–256. JMLR Workshop and Conference Proceedings, 2010. 14 A Additional detail and proofs for section 3 A.1 Proof of proposition 3.2 Recall the...
work page 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.