Recognition: no theorem link
ERASE: Eliminating Redundant Visual Tokens via Adaptive Two-Stage Token Pruning
Pith reviewed 2026-05-12 04:09 UTC · model grok-4.3
The pith
A two-stage adaptive pruning method lets vision-language models drop 85% of vision tokens while keeping most accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
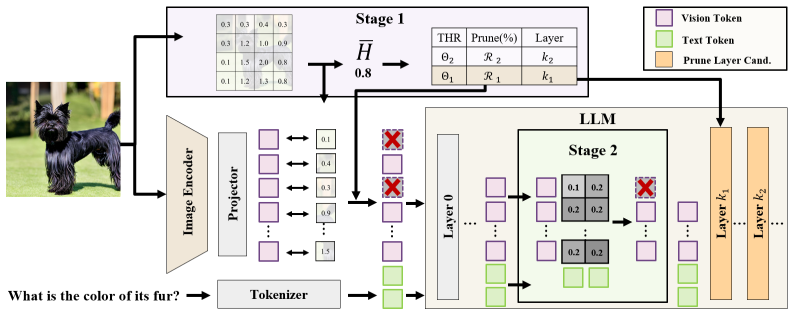
ERASE is a two-stage vision token pruning framework that identifies and retains salient tokens through pruning strategies adaptive to image complexity. The first stage applies semantic-feature pruning while the second stage uses an image-complexity estimate to set a dynamic pruning ratio, allowing the method to discard redundant visual tokens without the sharp accuracy losses typical of fixed-ratio or non-adaptive techniques.
What carries the argument
The two-stage adaptive token pruning framework that combines semantic feature selection with per-image complexity estimation to decide which vision tokens to keep or remove.
If this is right
- Vision-language models become usable at higher resolutions without proportional increases in compute.
- Pruning decisions improve when they are allowed to vary with the content of each individual image.
- The accuracy gap between pruned and full models narrows at aggressive pruning ratios.
- Overall token counts drop enough to support real-time or on-device multimodal inference.
Where Pith is reading between the lines
- Image complexity appears to be a useful signal for visual redundancy that earlier pruning methods did not exploit.
- The same two-stage idea could be tested on text-only large language models to prune less important context tokens.
- Integrating the pruning step directly into the model's training loop might further reduce information loss.
Load-bearing premise
The two-stage mechanism can reliably separate essential visual information from redundant tokens across many different kinds of images using only the model's existing semantic features and a complexity estimate.
What would settle it
Measure accuracy on a new test set containing many high-complexity or atypical images and check whether the retained accuracy at 85% pruning falls substantially below the 89.46% figure reported for standard benchmarks.
Figures






read the original abstract
Recent advancements in Vision-Language Models (VLMs) enable large language models (LLMs) to process high-resolution images, significantly improving real-world multimodal understanding. However, this capability introduces a large number of vision tokens, resulting in substantial computational overhead. To mitigate this issue, various vision token pruning methods have been proposed. Nevertheless, existing approaches predominantly rely on learned semantic features within the model to capture visual redundancy. Moreover, they lack adaptive mechanisms to adjust pruning strategies according to the complexity of the input image. In this paper, we propose ERASE, a two-stage vision token pruning framework that identifies and retains salient tokens through pruning strategies adaptive to image complexity. Experiment results demonstrate that ERASE significantly reduces vision tokens while preserving accuracy. For Qwen2.5-VL-7B, at a token pruning ratio of 85\%, ERASE retains 89.46% of the original model accuracy, whereas the best prior method retains only 78.1%. Our code is available at https://github.com/Tuna-Luna/ERASE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ERASE, a two-stage adaptive vision token pruning framework for VLMs. The first stage estimates image complexity and the second applies semantic-feature-based pruning to retain salient tokens. The central empirical claim is that ERASE reduces vision tokens substantially while preserving accuracy, specifically retaining 89.46% of original accuracy on Qwen2.5-VL-7B at an 85% pruning ratio versus 78.1% for the best prior method. Code is released at a public GitHub repository.
Significance. If the results hold under rigorous validation, the adaptive two-stage design offers a practical advance over purely semantic pruning methods for high-resolution VLMs, potentially lowering inference costs without proportional accuracy loss. The public code release is a clear strength that supports reproducibility and community follow-up. The work targets a timely efficiency bottleneck in multimodal models.
major comments (3)
- [§4] §4 (Experimental Results): The headline accuracy figures (89.46% retention at 85% pruning on Qwen2.5-VL-7B) are stated without reported standard deviations, number of runs, or explicit baseline implementations, making it impossible to assess whether the 11.36-point gap over prior methods is statistically reliable or reproducible.
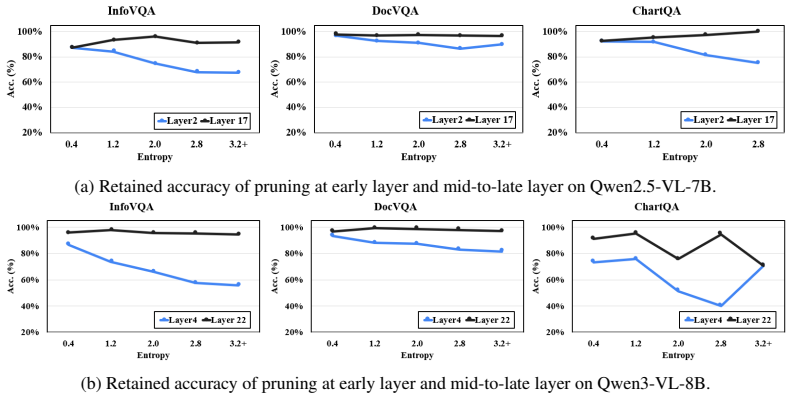
- [§3.2] §3.2 (Complexity Estimator): No ablation or per-image/per-complexity breakdown is provided to test whether the image-complexity estimator systematically under-prunes or over-prunes on dense scenes; the aggregate scalar result alone cannot confirm that the two-stage mechanism avoids the hypothesized information-loss failure mode.
- [Table 2] Table 2 (or equivalent comparison table): The reported retention percentages lack error bars, dataset-specific splits, or controls for input resolution, which are load-bearing for the claim that adaptation “reliably identifies salient tokens across diverse inputs.”
minor comments (2)
- [§3] The abstract and method sections use “learned semantic features” without a precise pointer to which layer or attention map is used; a short equation or pseudocode would clarify the second-stage pruning rule.
- Figure captions should explicitly state the pruning ratio and model variant shown, and the GitHub README should include exact commands to reproduce the Qwen2.5-VL-7B numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and detailed comments on our manuscript. We address each major point below and commit to revisions that strengthen the statistical reporting and validation of the adaptive components.
read point-by-point responses
-
Referee: [§4] The headline accuracy figures (89.46% retention at 85% pruning on Qwen2.5-VL-7B) are stated without reported standard deviations, number of runs, or explicit baseline implementations, making it impossible to assess whether the 11.36-point gap over prior methods is statistically reliable or reproducible.
Authors: We agree that the absence of standard deviations and run counts limits statistical assessment. In the revised manuscript we will report mean accuracy and standard deviation over three independent runs (different random seeds) for the Qwen2.5-VL-7B experiments at 85% pruning. Baselines were re-implemented from their official repositories using identical evaluation protocols and input resolutions; we will explicitly document these implementation details and hyper-parameters in the revised experimental section to confirm the controlled nature of the 11.36-point gap. revision: yes
-
Referee: [§3.2] No ablation or per-image/per-complexity breakdown is provided to test whether the image-complexity estimator systematically under-prunes or over-prunes on dense scenes; the aggregate scalar result alone cannot confirm that the two-stage mechanism avoids the hypothesized information-loss failure mode.
Authors: The current submission emphasizes end-to-end benchmark performance, but we recognize that a dedicated ablation would better validate the complexity estimator. We will add a new ablation table comparing ERASE with and without the complexity stage, plus qualitative per-image pruning visualizations on both simple and dense scenes (e.g., from COCO and TextVQA). These additions will directly illustrate adaptation behavior and address the potential information-loss concern. revision: yes
-
Referee: [Table 2] The reported retention percentages lack error bars, dataset-specific splits, or controls for input resolution, which are load-bearing for the claim that adaptation “reliably identifies salient tokens across diverse inputs.”
Authors: We will augment Table 2 with error bars derived from the same multi-run protocol. Dataset-specific retention numbers are already present in the appendix; we will cross-reference them explicitly in the main text. All experiments use the model’s native input resolution settings, which we will state clearly as a controlled variable. These changes will reinforce the reliability of the adaptive pruning claim. revision: yes
Circularity Check
No circularity: purely empirical method with external validation
full rationale
The paper describes an empirical two-stage token pruning framework for vision-language models, supported solely by experimental accuracy measurements on models such as Qwen2.5-VL-7B and an external GitHub code repository. No equations, derivations, fitted parameters presented as predictions, or load-bearing self-citations appear in the text. The central claim reduces to measured retention rates rather than any internal reduction to inputs by construction, satisfying the criteria for a self-contained empirical result.
Axiom & Free-Parameter Ledger
free parameters (2)
- pruning ratio =
85%
- complexity thresholds
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024
work page 2024
-
[3]
Zichen Wen, Yifeng Gao, Shaobo Wang, Junyuan Zhang, Qintong Zhang, Weijia Li, Conghui He, and Linfeng Zhang. Stop looking for “important tokens” in multimodal language models: Duplication matters more. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 9972–9991, 2025
work page 2025
-
[4]
Beyond attention or similarity: Maximizing conditional diversity for token pruning in MLLMs
Qizhe Zhang, Mengzhen Liu, Lichen Li, Ming Lu, Yuan Zhang, Junwen Pan, Qi She, and Shanghang Zhang. Beyond attention or similarity: Maximizing conditional diversity for token pruning in MLLMs. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=BLLixcuZgl
work page 2025
-
[5]
Zhengyao Fang, Pengyuan Lyu, Chengquan Zhang, Guangming Lu, Jun Yu, and Wenjie Pei. Prune redundancy, preserve essence: Vision token compression in vlms via synergistic importance-diversity. InInternational Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=i36E5Ezm0H
work page 2026
-
[6]
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. InEuropean Conference on Computer Vision, pages 19–35. Springer, 2024
work page 2024
-
[7]
IVC-prune: Revealing the implicit visual coordinates in LVLMs for vision token pruning
Zhichao Sun, Yidong Ma, Gang Liu, Nemo Chen, Xu Tang, Yao Hu, and Yongchao Xu. IVC-prune: Revealing the implicit visual coordinates in LVLMs for vision token pruning. In The Fourteenth International Conference on Learning Representations, 2026. URL https: //openreview.net/forum?id=46LbXtFgBm
work page 2026
-
[8]
Divprune: Diversity-based visual token pruning for large multimodal models
Saeed Ranjbar Alvar, Gursimran Singh, Mohammad Akbari, and Yong Zhang. Divprune: Diversity-based visual token pruning for large multimodal models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 9392–9401, 2025
work page 2025
-
[9]
Ce Zhang, Kaixin Ma, Tianqing Fang, Wenhao Yu, Hongming Zhang, Zhisong Zhang, Haitao Mi, and Dong Yu. VScan: Rethinking visual token reduction for efficient large vision-language models.Transactions on Machine Learning Research, 2026. ISSN 2835-8856. URL https: //openreview.net/forum?id=KZYhyilFnt
work page 2026
-
[10]
Nüwa: Mending the spatial integrity torn by VLM token pruning
Yihong Huang, Fei Ma, Yihua Shao, Jingcai Guo, Zitong YU, Laizhong Cui, and Qi Tian. Nüwa: Mending the spatial integrity torn by VLM token pruning. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[11]
iLLaV A: An image is worth fewer than 1/3 input tokens in large multimodal models
Lianyu Hu, Liqing Gao, Fanhua Shang, Liang Wan, and Wei Feng. iLLaV A: An image is worth fewer than 1/3 input tokens in large multimodal models. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum? id=svKk3PkjZn
work page 2026
-
[12]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
work page 2023
-
[13]
Deepseek-vl: towards real-world vision-language under- standing, 2024
Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Hao Yang, et al. Deepseek-vl: towards real-world vision-language under- standing, 2024
work page 2024
-
[14]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 10
work page 2021
-
[15]
Llava-next: Improved reasoning, ocr, and world knowledge, January 2024
Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Improved reasoning, ocr, and world knowledge, January 2024. URL https: //llava-vl.github.io/blog/2024-01-30-llava-next/
work page 2024
-
[16]
Deepseek-vl2: Mixture-of-experts vision- language models for advanced multimodal understanding, 2024
Zhiyu Wu, Xiaokang Chen, Zizheng Pan, Xingchao Liu, Wen Liu, Damai Dai, Huazuo Gao, Yiyang Ma, Chengyue Wu, Bingxuan Wang, et al. Deepseek-vl2: Mixture-of-experts vision- language models for advanced multimodal understanding, 2024
work page 2024
-
[17]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Visionzip: Longer is better but not necessary in vision language models
Senqiao Yang, Yukang Chen, Zhuotao Tian, Chengyao Wang, Jingyao Li, Bei Yu, and Jiaya Jia. Visionzip: Longer is better but not necessary in vision language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19792–19802, 2025
work page 2025
-
[20]
Conical visual concentration for efficient large vision-language models
Long Xing, Qidong Huang, Xiaoyi Dong, Jiajie Lu, Pan Zhang, Yuhang Zang, Yuhang Cao, Conghui He, Jiaqi Wang, Feng Wu, et al. Conical visual concentration for efficient large vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14593–14603, 2025
work page 2025
-
[21]
Xuyang Liu, Ziming Wang, Junjie Chen, Yuhang Han, Yingyao Wang, Jiale Yuan, Jun Song, Siteng Huang, and Honggang Chen. Global compression commander: Plug-and-play inference acceleration for high-resolution large vision-language models. InProceedings of the AAAI Conference on Artificial Intelligence, pages 7350–7358, 2026
work page 2026
-
[22]
Qizhe Zhang, Aosong Cheng, Ming Lu, Zhiyong Zhuo, MinQi Wang, Jiajun Cao, Shaobo Guo, Qi She, and Shanghang Zhang. [cls] attention is all you need for training-free visual token pruning: Make vlm inference faster.arXiv preprint arXiv:2412.01818, 2024
-
[23]
FlashAttention-2: Faster attention with better parallelism and work partitioning
Tri Dao. FlashAttention-2: Faster attention with better parallelism and work partitioning. In International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[24]
Donald R Jones, Matthias Schonlau, and William J Welch. Efficient global optimization of expensive black-box functions.Journal of Global optimization, 13(4):455–492, 1998
work page 1998
-
[25]
Qiong Wu, Wenhao Lin, Yiyi Zhou, Weihao Ye, Zhanpeng Zen, Xiaoshuai Sun, and Rongrong Ji. Accelerating multimodal large language models via dynamic visual-token exit and the empirical findings. InAdvances in Neural Information Processing Systems, 2025
work page 2025
-
[26]
Vision function layer in multimodal llms
Cheng Shi, Yizhou Yu, and Sibei Yang. Vision function layer in multimodal llms. InAdvances in Neural Information Processing Systems, 2025
work page 2025
-
[27]
Towards vqa models that can read
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8317–8326, 2019
work page 2019
-
[28]
Yuliang Liu, Zhang Li, Mingxin Huang, Biao Yang, Wenwen Yu, Chunyuan Li, Xu-Cheng Yin, Cheng-Lin Liu, Lianwen Jin, and Xiang Bai. Ocrbench: on the hidden mystery of ocr in large multimodal models.Science China Information Sciences, 67(12):220102, 2024
work page 2024
-
[29]
Chartqa: A benchmark for question answering about charts with visual and logical reasoning
Ahmed Masry, Xuan Long Do, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. Chartqa: A benchmark for question answering about charts with visual and logical reasoning. InFindings of the association for computational linguistics: ACL 2022, pages 2263–2279, 2022
work page 2022
-
[30]
Docvqa: A dataset for vqa on document images
Minesh Mathew, Dimosthenis Karatzas, and CV Jawahar. Docvqa: A dataset for vqa on document images. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 2200–2209, 2021. 11
work page 2021
-
[31]
Minesh Mathew, Viraj Bagal, Rubèn Tito, Dimosthenis Karatzas, Ernest Valveny, and CV Jawa- har. Infographicvqa. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 1697–1706, 2022
work page 2022
-
[32]
Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. InInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[33]
Wenbin Wang, Liang Ding, Minyan Zeng, Xiabin Zhou, Li Shen, Yong Luo, Wei Yu, and Dacheng Tao. Divide, conquer and combine: A training-free framework for high-resolution image perception in multimodal large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 7907–7915, 2025
work page 2025
-
[34]
V?: Guided visual search as a core mechanism in multimodal llms
Penghao Wu and Saining Xie. V?: Guided visual search as a core mechanism in multimodal llms. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13084–13094, 2024
work page 2024
-
[35]
xAI Corp. Grok-1.5 vision preview: Connecting the digital and physical worlds with our first multimodal model.https://x.ai/blog/grok-1.5v, 2024
work page 2024
-
[36]
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, et al. Are we on the right way for evaluating large vision- language models?Advances in Neural Information Processing Systems, 37:27056–27087, 2024
work page 2024
-
[37]
Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering.Conference on Computer Vision and Pattern Recognition (CVPR), 2019
work page 2019
-
[38]
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vision, pages 216–233. Springer, 2024
work page 2024
-
[39]
Blink: Multimodal large language models can see but not perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive. InEuropean Conference on Computer Vision, pages 148–166. Springer, 2024
work page 2024
-
[40]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Chaoyou Fu, Haojia Lin, Xiong Wang, Yi-Fan Zhang, Yunhang Shen, Xiaoyu Liu, Yangze Li, Zuwei Long, Heting Gao, Ke Li, et al. Vita-1.5: Towards gpt-4o level real-time vision and speech interaction.arXiv preprint arXiv:2501.01957, 2025
-
[42]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023. 12 A Detailed experimental settings A.1 Implementation details Comparison methodsWe configured all baselines following their offic...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
To compensate for this portion of simple images, the algorithm conservatively lowers the Stage 1 pruning ratio (30.17%). While this maximizes Stage 2 efficiency, it overly restricts the model’s deep multimodal reasoning, ultimately dropping accuracy to 77.72%. While an overly accuracy-centric reward (v2, α= 0.85 ) is intended to discourage token reduction...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.