Recognition: 2 theorem links
· Lean TheoremAttention Drift: What Autoregressive Speculative Decoding Models Learn
Pith reviewed 2026-05-12 02:11 UTC · model grok-4.3
The pith
Un-normalized residual paths in speculative decoding drafters cause hidden-state magnitudes to grow with chain depth, shifting attention away from the prompt.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
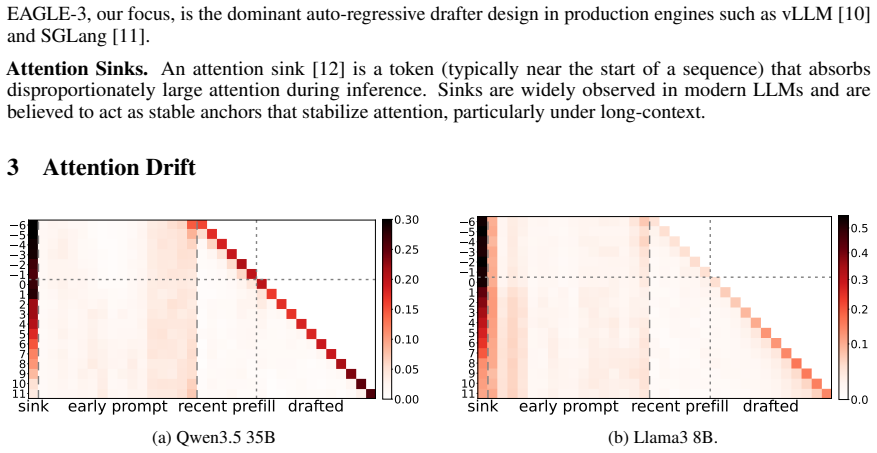
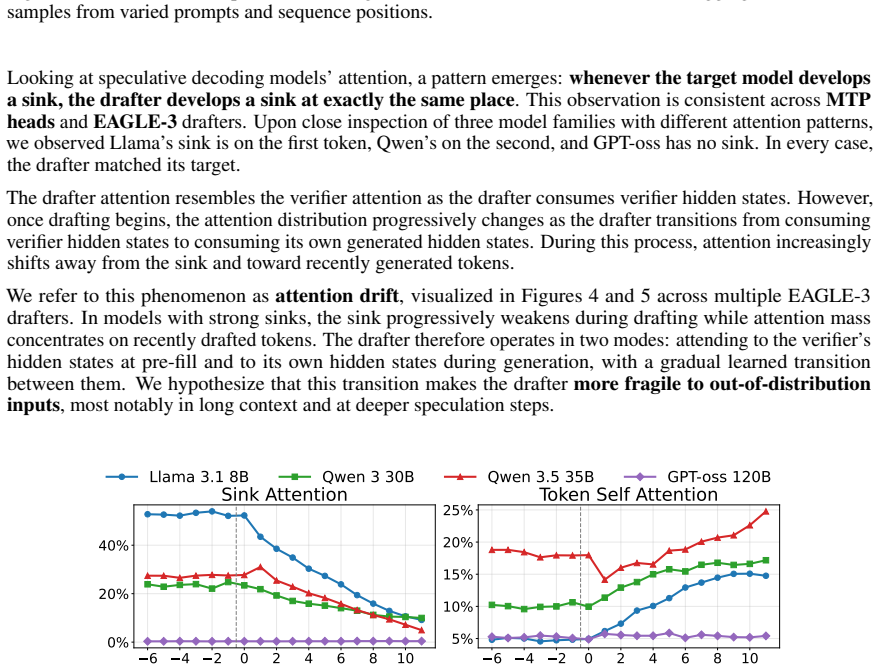
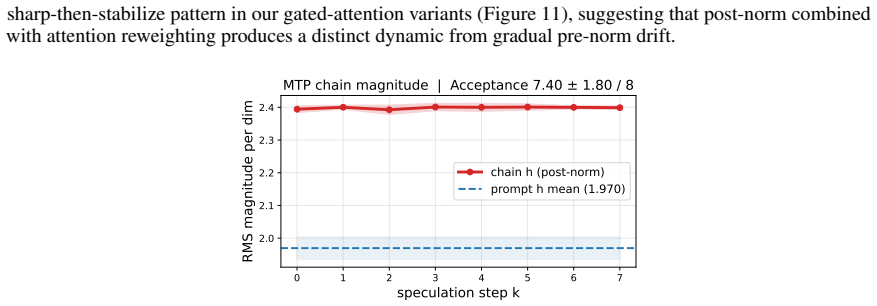
We identify a phenomenon called attention drift in which the drafter's attention progressively moves from the prompt onto its own recently-generated tokens as successive tokens are produced within a speculation chain. We trace this to the un-normalized residual path between chain steps: the drafter's hidden state magnitude grows monotonically with chain depth, which exhibits dynamics consistent with additional pre-norm transformer layers stacked on the target rather than as a standalone autoregressive predictor. In order to limit the growth, we propose post-norm on the drafter hidden states and per-hidden-state RMSNorm after capturing target hidden states. These changes improve acceptance长度.
What carries the argument
the un-normalized residual path between chain steps, which produces monotonic growth in hidden-state magnitude and drives attention drift
If this is right
- Acceptance length improves by up to 2× under template perturbation compared with pre-norm EAGLE3.
- Acceptance length improves by 1.18× on long-context tasks.
- Acceptance length improves by 1.10× across seven standard benchmarks spanning multi-turn chat, math, and coding.
- Shorter train-time-test depths generalize to longer drafting sequences at inference time.
Where Pith is reading between the lines
- Similar magnitude growth and drift may appear in other multi-step autoregressive predictors that reuse hidden states across steps.
- The same post-norm and per-hidden-state normalization pattern could be tested on drafter variants that use different base architectures.
- Stabilizing hidden-state scale might reduce the performance gap between short and long speculation chains in production systems.
- The drift mechanism suggests that residual handling should be examined in any model that performs repeated forward passes on accumulating self-generated context.
Load-bearing premise
The observed growth in hidden-state magnitude and resulting attention shift are caused by the un-normalized residual path rather than other unmeasured factors in drafter training or architecture.
What would settle it
An ablation in which hidden-state magnitudes are measured across increasing chain depths after the residual connections are removed or replaced, checking whether growth and attention shift disappear.
Figures















read the original abstract
Speculative decoding accelerates LLM inference by drafting future tokens with a small model, but drafter models degrade sharply under template perturbation and long-context inputs. We identify a previously-unreported phenomenon we call \textbf{attention drift}: as the drafter generates successive tokens within a speculation chain, attention progressively moves from the prompt onto its own recently-generated tokens. We observe this across both \emph{EAGLE3} drafters and \emph{MTP heads}, suggesting drift is a property of drafter designs. We trace this to the un-normalized residual path between chain steps: the drafter's hidden state magnitude grows monotonically with chain depth, which exhibits dynamics consistent with additional pre-norm transformer layers stacked on the target rather than as a standalone autoregressive predictor. In order to limit the growth, we propose two architectural changes: Post-norm on the drafter hidden states and per-hidden-state RMSNorm after capturing target hidden states. Our interventions improve acceptance length over the current leading model, pre-norm EAGLE3, by up to $2\times$ under template perturbation, $1.18\times$ on long-context tasks, and $1.10\times$ on seven standard benchmarks spanning multi-turn chat, math, and coding. Our changes also allow shorter train-time-test depths to generalize over longer drafting sequences.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that autoregressive drafter models in speculative decoding suffer from 'attention drift,' where attention shifts progressively from the prompt to recently generated tokens as speculation chain depth increases. This is attributed to monotonic growth in hidden-state magnitudes arising from an un-normalized residual path between chain steps, which mimics stacked pre-norm layers rather than a standalone predictor. The authors propose two fixes—post-norm on drafter hidden states and per-hidden-state RMSNorm after target capture—and report empirical gains in acceptance length over pre-norm EAGLE3: up to 2× under template perturbation, 1.18× on long-context tasks, and 1.10× on seven standard benchmarks, with better generalization from shorter training depths.
Significance. If the mechanistic diagnosis holds, the work supplies a concrete architectural explanation for drafter degradation under perturbation and long contexts, plus simple, low-overhead normalizations that deliver measurable acceptance-length improvements. The observation of drift across both EAGLE3 and MTP heads is a strength, as is the multi-task empirical evaluation. These elements could inform more stable drafter designs and reduce reliance on deeper or more expensive speculation chains.
major comments (2)
- [Diagnosis of attention drift (analysis section)] The central causal claim—that the un-normalized inter-step residual path is the primary driver of monotonic magnitude growth and attention drift—rests on observational correlation across EAGLE3 and MTP heads. No ablation is presented that normalizes only this residual connection while holding target-state capture, training objectives, and other residual paths fixed; without it, alternative explanations cannot be ruled out.
- [Experimental evaluation] Improvements are reported exclusively against the authors' own pre-norm EAGLE3 baseline. It is unclear whether the 1.10–2× gains persist against independently tuned strong baselines or whether post-hoc architectural choices in the proposed normalizations interact with training details not fully isolated in the experiments.
minor comments (2)
- [Abstract] The abstract refers to 'seven standard benchmarks' without naming them or providing a table reference; listing the tasks (e.g., multi-turn chat, math, coding) explicitly would improve reproducibility.
- [Proposed architectural changes] The precise formulation of 'per-hidden-state RMSNorm' is described only at a high level; adding an equation (e.g., in the methods section) would clarify its difference from standard RMSNorm and aid implementation.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting areas where our causal analysis and experimental comparisons can be strengthened. We address each major comment below and describe the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Diagnosis of attention drift (analysis section)] The central causal claim—that the un-normalized inter-step residual path is the primary driver of monotonic magnitude growth and attention drift—rests on observational correlation across EAGLE3 and MTP heads. No ablation is presented that normalizes only this residual connection while holding target-state capture, training objectives, and other residual paths fixed; without it, alternative explanations cannot be ruled out.
Authors: We agree that a more targeted ablation isolating normalization of only the inter-step residual path would provide stronger causal evidence. In the revised manuscript we will add an experiment that applies RMSNorm exclusively to the residual connection between successive drafter steps while freezing the target-state capture mechanism, training objective, and all other residual paths. This controlled variant will be compared directly to the original pre-norm EAGLE3 and to our full post-norm + per-state RMSNorm model, allowing us to quantify the contribution of the residual path to magnitude growth and attention drift. revision: yes
-
Referee: [Experimental evaluation] Improvements are reported exclusively against the authors' own pre-norm EAGLE3 baseline. It is unclear whether the 1.10–2× gains persist against independently tuned strong baselines or whether post-hoc architectural choices in the proposed normalizations interact with training details not fully isolated in the experiments.
Authors: We acknowledge the value of broader baseline comparisons. In revision we will expand the experimental section to include results against additional independently reported drafter architectures (e.g., Medusa-style heads and other recent MTP variants) using the same evaluation protocol. Regarding training interactions, we will clarify that the proposed normalizations are architectural modifications applied during both training and inference; we will report separate training runs for the normalized drafter and provide hyper-parameter details to show that the acceptance-length gains are not artifacts of mismatched training regimes. Full retraining of every external baseline with our exact normalization stack is computationally intensive, but we will note this limitation and focus on the most relevant strong baselines. revision: partial
Circularity Check
No circularity: empirical observations and benchmark improvements are independent of inputs
full rationale
The paper's core contribution is an empirical identification of attention drift via measurements of attention weights and hidden-state magnitudes across EAGLE3 and MTP drafters, followed by two proposed normalizations whose benefits are validated on external benchmarks (template perturbation, long-context, and seven standard tasks). No equations, fitted parameters, or predictions are presented that reduce to the inputs by construction. The attribution to the residual path is observational rather than derived from a closed-form model that assumes the conclusion. Comparisons use the established pre-norm EAGLE3 as an external baseline, not a self-referential fit. The work is therefore self-contained against external benchmarks with no load-bearing self-citation chains or self-definitional steps.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe trace this to the unnormalized residual path between chain steps: the drafter’s hidden state magnitude grows monotonically with chain depth
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclearpost-norm on the drafter hidden states and per-hidden-state RMSNorm
Reference graph
Works this paper leans on
-
[1]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. InInternational Conference on Machine Learning, pages 19274–19286. PMLR, 2023
work page 2023
-
[2]
Accelerating Large Language Model Decoding with Speculative Sampling
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. Accelerating large language model decoding with speculative sampling.arXiv preprint arXiv:2302.01318, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Duoattention: Efficient long-context LLM inference with retrieval and streaming heads
Guangxuan Xiao, Jiaming Tang, Jingwei Zuo, junxian guo, Shang Yang, Haotian Tang, Yao Fu, and Song Han. Duoattention: Efficient long-context LLM inference with retrieval and streaming heads. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview. net/forum?id=cFu7ze7xUm
work page 2025
-
[4]
Longspec: Long-context lossless speculative decoding with efficient drafting and verification
Penghui Yang, Cunxiao Du, Fengzhuo Zhang, Haonan Wang, Tianyu Pang, Chao Du, and Bo An. Longspec: Long-context lossless speculative decoding with efficient drafting and verification. InES- FoMo III: 3rd Workshop on Efficient Systems for Foundation Models, 2025. URLhttps://openreview. net/forum?id=GFN9PWbfHs
work page 2025
-
[5]
EAGLE-3: Scaling up inference acceleration of large language models via training-time test
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. EAGLE-3: Scaling up inference acceleration of large language models via training-time test. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps://openreview.net/forum?id=4exx1hUffq
work page 2026
-
[6]
Better & faster large language models via multi-token prediction
Fabian Gloeckle, Badr Youbi Idrissi, Baptiste Rozière, David Lopez-Paz, and Gabriel Synnaeve. Better & faster large language models via multi-token prediction. In Ruslan Salakhutdinov, Zico Kolter, Katherine A. Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors, Forty-first International Conference on Machine Learning, I...
work page 2024
-
[7]
EAGLE: speculative sampling requires rethinking feature uncertainty
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. EAGLE: speculative sampling requires rethinking feature uncertainty. In Ruslan Salakhutdinov, Zico Kolter, Katherine A. Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27...
work page 2024
-
[8]
Eagle-2: Faster inference of language models with dynamic draft trees
Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle-2: Faster inference of language models with dynamic draft trees. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 7421–7432, 2024
work page 2024
-
[9]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
work page 2017
-
[10]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
work page 2023
-
[11]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody H Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. Sglang: Efficient execution of structured language model programs.Advances in neural information processing systems, 37:62557–62583, 2024
work page 2024
-
[12]
Efficient streaming language models with attention sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=NG7sS51zVF. 14
work page 2024
-
[13]
Judging llm-as-a-judge with mt-bench and chatbot arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in neural information processing systems, 36:46595–46623, 2023
work page 2023
-
[14]
arXiv preprint arXiv:2603.15031 (2026)
Kimi Team, Guangyu Chen, Yu Zhang, Jianlin Su, Weixin Xu, Siyuan Pan, Yaoyu Wang, Yucheng Wang, Guanduo Chen, Bohong Yin, et al. Attention residuals.arXiv preprint arXiv:2603.15031, 2026
-
[15]
Ranajoy Sadhukhan, Jian Chen, Zhuoming Chen, Vashisth Tiwari, Ruihang Lai, Jinyuan Shi, Ian En-Hsu Yen, Avner May, Tianqi Chen, and Beidi Chen. Magicdec: Breaking the latency-throughput tradeoff for long context generation with speculative decoding. InICLR, 2025. URL https://openreview.net/ forum?id=CS2JWaziYr
work page 2025
-
[16]
Longbench: A bilingual, multitask benchmark for long context understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, et al. Longbench: A bilingual, multitask benchmark for long context understanding. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), pages 3119–3137, 2024
work page 2024
-
[17]
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D. Lee, Deming Chen, and Tri Dao. Medusa: Simple LLM inference acceleration framework with multiple decoding heads. InForty-first International Conference on Machine Learning, 2024. URL https://openreview.net/forum?id= PEpbUobfJv
work page 2024
-
[18]
Hydra: Sequentially-dependent draft heads for medusa decoding
Zachary Ankner, Rishab Parthasarathy, Aniruddha Nrusimha, Christopher Rinard, Jonathan Ragan- Kelley, and William Brandon. Hydra: Sequentially-dependent draft heads for medusa decoding. InFirst Conference on Language Modeling, 2024. URL https://openreview.net/forum?id=FbhjirzvJG
work page 2024
-
[19]
Dflash: Block diffusion for flash speculative decoding
Jian Chen, Yesheng Liang, and Zhijian Liu. Dflash: Block diffusion for flash speculative decoding.arXiv preprint arXiv:2602.06036, 2026
-
[20]
Gated at- tention for large language models: Non-linearity, sparsity, and attention-sink-free
Zihan Qiu, Zekun Wang, Bo Zheng, Zeyu Huang, Kaiyue Wen, Songlin Yang, Rui Men, Le Yu, Fei Huang, Suozhi Huang, Dayiheng Liu, Jingren Zhou, and Junyang Lin. Gated at- tention for large language models: Non-linearity, sparsity, and attention-sink-free. In D. Bel- grave, C. Zhang, H. Lin, R. Pascanu, P. Koniusz, M. Ghassemi, and N. Chen, editors,Ad- vances ...
work page 2025
-
[21]
On layer normalization in the transformer architecture
Ruibin Xiong, Yunchang Yang, Di He, Kai Zheng, Shuxin Zheng, Chen Xing, Huishuai Zhang, Yanyan Lan, Liwei Wang, and Tieyan Liu. On layer normalization in the transformer architecture. InInternational conference on machine learning, pages 10524–10533. PMLR, 2020
work page 2020
-
[22]
On the role of attention masks and layernorm in transformers
Xinyi Wu, Amir Ajorlou, Yifei Wang, Stefanie Jegelka, and Ali Jadbabaie. On the role of attention masks and layernorm in transformers. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URLhttps://openreview.net/forum?id=lIH6oCdppg. 15 A Gated attention In the gated attention variant of our models, we add an optional per...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.