Recognition: 2 theorem links
· Lean TheoremEnhancing Healthcare Search Intent Recognition with Query Representation Learning and Session Context
Pith reviewed 2026-05-12 02:33 UTC · model grok-4.3
The pith
Clustering similar queries and a novel loss function improve healthcare search intent classification by better capturing multiple intents and session context.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that aggregating similar queries via clustering and employing a novel loss function designed to capture the multifaceted nature of health search queries results in improved query representations, which enhance the accuracy of session-based search intent classification models, as shown on two real-world search log datasets.
What carries the argument
The clustering of similar queries combined with a novel loss function for learning query representations, along with the concordance rate score to quantify intent ambiguity and misalignment.
If this is right
- Improved intrinsic clustering metrics for query representation learning.
- Enhanced accuracy in subsequent search intent classification tasks.
- More scalable and accurate learning procedure for handling ambiguous health queries.
- Effective incorporation of learned representations into contextual session-based classifiers.
Where Pith is reading between the lines
- Similar clustering and loss techniques might apply to search intent in other specialized domains like legal or technical queries.
- Reducing reliance on labeled data could make intent recognition more practical for smaller health platforms.
- Accounting for session misalignment could lead to more personalized health search experiences over time.
Load-bearing premise
That clustering similar queries and the novel loss function will reliably capture the multifaceted nature of health queries without introducing new biases.
What would settle it
Observing no improvement or a decrease in clustering metrics and intent classification accuracy on the TripClick dataset or a new health search log when applying the clustering and novel loss would falsify the central claim.
Figures




read the original abstract
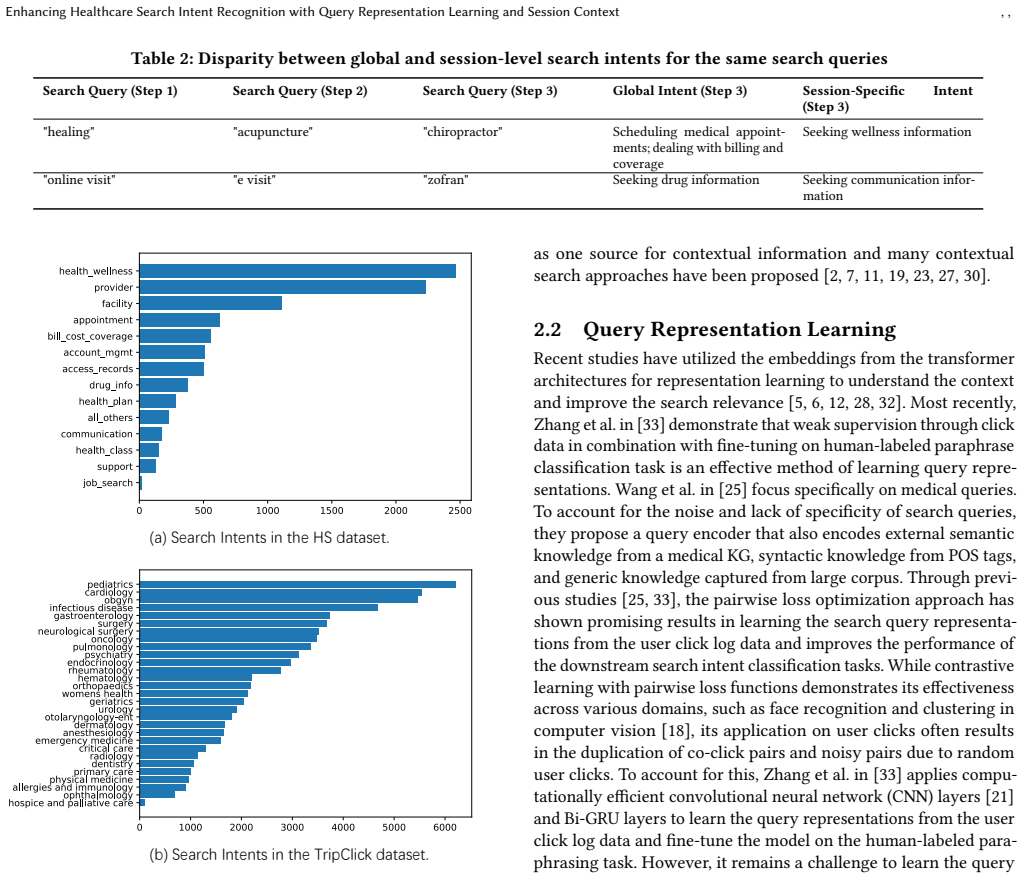
Classifying the intent behind healthcare search queries is crucial for improving the delivery of online healthcare information. The intricate nature of medical search queries, coupled with the limited availability of high-quality labeled data, presents substantial challenges for developing efficient classification models. Previous studies have exploited user interaction data, such as user clicks from search logs and employed pairwise loss functions to model co-click behavior for query representation learning. However, many health queries could have multiple intents, resulting in ambiguous or divergent click behavior. Furthermore, learning the single most popular intent of queries as inferred from global statistics based on the aggregate behavior of different users could potentially lead to disparity and performance drop when classifying the query intent within specific search sessions. To address these limitations, our work improves the query representation learning by aggregating similar queries via clustering, and introducing a novel loss function designed to capture the multifaceted nature of health search queries, resulting in a more scalable and accurate learning procedure. Furthermore, we quantify the ambiguity of health queries and the misalignment between global search intents and those discerned from individual sessions, by introducing the concordance rate (CR) score, and demonstrate a simple and effective method for incorporating our learned query representation into contextual, session-based search intent classification. Our extensive experimental results and analysis on two real-world search log datasets, i.e., a Health Search (HS) dataset and the publicly available TripClick dataset, demonstrate that our approach not only improves the intrinsic clustering metrics for query representation learning but also enhances accuracy for subsequent search intent classification tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to improve healthcare search intent recognition by clustering similar queries for better representation learning and introducing a novel loss function to capture the multifaceted nature of health queries (addressing limitations of pairwise losses and global statistics). It introduces a concordance rate (CR) metric to quantify query ambiguity and misalignment between global and session-specific intents, then integrates the learned representations into contextual session-based classification. Experiments on the Health Search (HS) and TripClick datasets are reported to yield improved intrinsic clustering metrics and higher accuracy for intent classification.
Significance. If the claimed gains are substantiated with proper controls and validation, the work could advance query understanding in domain-specific search by tackling multi-intent ambiguity and session context, areas where global co-click models often fail. The CR metric provides a useful diagnostic for intent misalignment, and the two-dataset evaluation offers some grounding in real logs. However, the absence of detailed quantitative support in the current form limits the assessed contribution to the field.
major comments (3)
- [§5] §5 (experimental results): The abstract and results claim improvements in clustering metrics and classification accuracy on HS and TripClick, yet report no effect sizes, baseline comparisons (e.g., against standard pairwise losses or prior session models), or statistical significance tests. This directly undermines the central claim of enhancement, as the magnitude and reliability of gains cannot be assessed.
- [§3.2] §3.2 (novel loss function): The loss is positioned as key to modeling multifaceted health queries better than pairwise alternatives, but no mathematical formulation, pseudocode, or hyperparameter details (e.g., weighting terms) are provided. This is load-bearing, as the method's advantage over existing approaches cannot be evaluated or reproduced without it.
- [§4] §4 (method and datasets): No sensitivity analysis on clustering hyperparameters (e.g., cluster count) or loss weights is reported, and the HS/TripClick datasets lack demographic or temporal splits to test for population biases. This is critical because the clustering-plus-loss approach assumes reliable generalization to capture multi-intent queries without introducing new biases under distribution shift.
minor comments (2)
- [Abstract] Abstract: The summary of contributions could include at least one concrete metric or baseline to convey the scale of improvement, aiding quick assessment of novelty.
- Notation: The definition and computation of the concordance rate (CR) score would benefit from an explicit equation or algorithm box for clarity when discussing global vs. session misalignment.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important areas for strengthening the empirical rigor and reproducibility of our work. We address each major comment point-by-point below and will revise the manuscript to incorporate additional details, analyses, and clarifications where feasible.
read point-by-point responses
-
Referee: [§5] §5 (experimental results): The abstract and results claim improvements in clustering metrics and classification accuracy on HS and TripClick, yet report no effect sizes, baseline comparisons (e.g., against standard pairwise losses or prior session models), or statistical significance tests. This directly undermines the central claim of enhancement, as the magnitude and reliability of gains cannot be assessed.
Authors: We agree that the current experimental reporting would be strengthened by explicit quantification of improvements. In the revised manuscript, we will add direct baseline comparisons against standard pairwise losses (such as contrastive or triplet losses) and relevant prior session-based models. We will also report effect sizes (e.g., absolute and relative improvements in NMI, ARI, and accuracy) along with statistical significance testing (e.g., paired t-tests or bootstrap resampling with p-values) to substantiate the claimed gains on both datasets. revision: yes
-
Referee: [§3.2] §3.2 (novel loss function): The loss is positioned as key to modeling multifaceted health queries better than pairwise alternatives, but no mathematical formulation, pseudocode, or hyperparameter details (e.g., weighting terms) are provided. This is load-bearing, as the method's advantage over existing approaches cannot be evaluated or reproduced without it.
Authors: The multi-intent loss is intended to address limitations of pairwise approaches for ambiguous health queries. While the high-level motivation appears in §3.2, we acknowledge that the explicit formulation is insufficient for full evaluation. We will include the complete mathematical definition of the loss (including all component terms and weighting hyperparameters), pseudocode for the optimization procedure, and the specific hyperparameter settings used in our experiments to enable reproduction and direct comparison. revision: yes
-
Referee: [§4] §4 (method and datasets): No sensitivity analysis on clustering hyperparameters (e.g., cluster count) or loss weights is reported, and the HS/TripClick datasets lack demographic or temporal splits to test for population biases. This is critical because the clustering-plus-loss approach assumes reliable generalization to capture multi-intent queries without introducing new biases under distribution shift.
Authors: We will add a sensitivity analysis subsection in the revised §4, systematically varying cluster count (e.g., k=10 to k=100) and loss weighting parameters while reporting impacts on clustering metrics and downstream classification accuracy. For the datasets, we will incorporate any available temporal information from TripClick for split-based analysis. The proprietary HS dataset does not contain demographic annotations, preventing demographic splits; we will explicitly discuss this limitation, potential population biases, and any feasible temporal or session-based checks for generalization. revision: partial
- Demographic splits on the proprietary HS dataset, as no such annotations are available in the underlying search logs.
Circularity Check
No significant circularity in empirical query representation learning
full rationale
The paper presents an empirical ML approach: clustering similar queries, a novel loss function to capture multi-intent health queries, the new CR metric to quantify global-vs-session misalignment, and a practical method to inject the learned representations into session-based classifiers. All performance claims are validated via experiments on two external real-world search-log datasets (HS and TripClick) using standard intrinsic clustering metrics and downstream classification accuracy. No derivation reduces by construction to fitted parameters, no self-citation chain supplies the central result, and no known empirical pattern is merely renamed. The method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- clustering hyperparameters
axioms (2)
- domain assumption Similar queries share intents that can be aggregated via clustering without losing critical session-specific signals
- ad hoc to paper The new loss function captures the multifaceted nature of health queries better than existing pairwise losses
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
novel multiset loss function ... l_multiset = -log(l_intra / l_inter) ... cosine similarity between query embeddings and centroid of document set embeddings
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
clustering similar queries via clustering ... concordance rate (CR) score
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Eugene Agichtein, Eric Brill, and Susan Dumais. 2006. Improving web search rank- ing by incorporating user behavior information. InProceedings of the 29th annual international ACM SIGIR conference on Research and development in information retrieval. 19–26
work page 2006
-
[2]
Paul N Bennett, Ryen W White, Wei Chu, Susan T Dumais, Peter Bailey, Fedor Borisyuk, and Xiaoyuan Cui. 2012. Modeling the impact of short-and long-term behavior on search personalization. InProceedings of the 35th international ACM SIGIR conference on Research and development in information retrieval. 185–194
work page 2012
-
[3]
Andrei Broder. 2002. A taxonomy of web search. InACM Sigir forum, Vol. 36. ACM New York, NY, USA, 3–10
work page 2002
-
[4]
Andrei Z Broder, Marcus Fontoura, Evgeniy Gabrilovich, Amruta Joshi, Vanja Josifovski, and Tong Zhang. 2007. Robust classification of rare queries using web knowledge. InProceedings of the 30th annual international ACM SIGIR conference on Research and development in information retrieval. 231–238
work page 2007
-
[5]
Daniel Cer, Yinfei Yang, Sheng-yi Kong, Nan Hua, Nicole Limtiaco, Rhomni St John, Noah Constant, Mario Guajardo-Cespedes, Steve Yuan, Chris Tar, et al
-
[6]
Universal sentence encoder.arXiv preprint arXiv:1803.11175(2018)
work page Pith review arXiv 2018
-
[7]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding.arXiv preprint arXiv:1810.04805(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
Helia Hashemi, Hamed Zamani, and W Bruce Croft. 2020. Guided transformer: Leveraging multiple external sources for representation learning in conversa- tional search. InProceedings of the 43rd international acm sigir conference on research and development in information retrieval. 1131–1140
work page 2020
-
[9]
Helia Hashemi, Hamed Zamani, and W Bruce Croft. 2021. Learning multiple intent representations for search queries. InProceedings of the 30th ACM Interna- tional Conference on Information & Knowledge Management. 669–679
work page 2021
-
[10]
Jian Hu, Gang Wang, Fred Lochovsky, Jian-tao Sun, and Zheng Chen. 2009. Understanding user’s query intent with wikipedia. InProceedings of the 18th international conference on World wide web. 471–480
work page 2009
-
[11]
Bernard J Jansen, Danielle L Booth, and Amanda Spink. 2007. Determining the user intent of web search engine queries. InProceedings of the 16th international conference on World Wide Web. 1149–1150
work page 2007
-
[12]
Weize Kong, Rui Li, Jie Luo, Aston Zhang, Yi Chang, and James Allan. 2015. Predicting search intent based on pre-search context. InProceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval. 503–512
work page 2015
-
[13]
Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. 2020. BioBERT: a pre-trained biomedical language representation model for biomedical text mining.Bioinformatics36, 4 (2020), 1234–1240
work page 2020
-
[14]
Eric Nalisnick, Bhaskar Mitra, Nick Craswell, and Rich Caruana. 2016. Improv- ing document ranking with dual word embeddings. InProceedings of the 25th International Conference Companion on World Wide Web. 83–84
work page 2016
-
[15]
Diego Ortiz, José G Moreno, Gilles Hubert, Karen Pinel-Sauvagnat, and Lynda Tamine. 2022. Exploring the Value of Multi-View Learning for Session-Aware Query Representation. InAnnual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL 2022). ACL: Association for Computational Linguistics, 304–315
work page 2022
-
[16]
Matt Post and Shane Bergsma. 2013. Explicit and implicit syntactic features for text classification. Inproceedings of the 51st Annual Meeting of the Association for Computational Linguistics. 866–872
work page 2013
-
[17]
Mahmudur Rahman. 2013. Search engines going beyond keyword search: a survey.Int. J. Comput. Appl75, 17 (2013), 1–8
work page 2013
-
[18]
Navid Rekabsaz, Oleg Lesota, Markus Schedl, Jon Brassey, and Carsten Eickhoff
-
[19]
Tripclick: the log files of a large health web search engine. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2507–2513
-
[20]
Florian Schroff, Dmitry Kalenichenko, and James Philbin. 2015. Facenet: A unified embedding for face recognition and clustering. InProceedings of the IEEE conference on computer vision and pattern recognition. 815–823
work page 2015
-
[21]
Procheta Sen, Debasis Ganguly, and Gareth JF Jones. 2021. I know what you need: Investigating document retrieval effectiveness with partial session contexts. ACM Transactions on Information Systems (TOIS)40, 3 (2021), 1–30
work page 2021
-
[22]
Dou Shen, Jian-Tao Sun, Qiang Yang, and Zheng Chen. 2006. Building bridges for web query classification. InProceedings of the 29th annual international ACM SIGIR conference on Research and development in information retrieval. 131–138
work page 2006
-
[23]
Yelong Shen, Xiaodong He, Jianfeng Gao, Li Deng, and Grégoire Mesnil. 2014. Learning semantic representations using convolutional neural networks for web search. InProceedings of the 23rd international conference on world wide web. 373–374
work page 2014
- [24]
-
[25]
Tung Vuong and Tuukka Ruotsalo. 2024. Predicting Representations of Infor- mation Needs from Digital Activity Context.ACM Transactions on Information Systems(2024)
work page 2024
-
[26]
Jin Wang, Zhongyuan Wang, Dawei Zhang, and Jun Yan. 2017. Combining Knowl- edge with Deep Convolutional Neural Networks for Short Text Classification.. In IJCAI, Vol. 350. 3172077–3172295
work page 2017
-
[27]
Yaqing Wang, Song Wang, Yanyan Li, and Dejing Dou. 2022. Recognizing medical search query intent by few-shot learning. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 502–512
work page 2022
-
[28]
Zhongyuan Wang, Kejun Zhao, Haixun Wang, Xiaofeng Meng, and Ji-Rong Wen
- [29]
-
[30]
Ryen W White, Paul N Bennett, and Susan T Dumais. 2010. Predicting short-term interests using activity-based search context. InProceedings of the 19th ACM international conference on Information and knowledge management. 1009–1018
work page 2010
-
[31]
Chenyan Xiong, Zhuyun Dai, Jamie Callan, Zhiyuan Liu, and Russell Power. 2017. End-to-end neural ad-hoc ranking with kernel pooling. InProceedings of the 40th International ACM SIGIR conference on research and development in information retrieval. 55–64
work page 2017
-
[32]
Xiaoxin Yin and Sarthak Shah. 2010. Building taxonomy of web search intents for name entity queries. InProceedings of the 19th international conference on World wide web. 1001–1010
work page 2010
-
[33]
Chunyuan Yuan, Yiming Qiu, Mingming Li, Haiqing Hu, Songlin Wang, and Sulong Xu. 2023. A Multi-Granularity Matching Attention Network for Query Intent Classification in E-commerce Retrieval. InCompanion Proceedings of the ACM Web Conference 2023. 416–420. , , Sahijwani et al
work page 2023
-
[34]
Hamed Zamani, Michael Bendersky, Xuanhui Wang, and Mingyang Zhang. 2017. Situational context for ranking in personal search. InProceedings of the 26th International Conference on World Wide Web. 1531–1540
work page 2017
-
[35]
Hamed Zamani and W Bruce Croft. 2017. Relevance-based word embedding. InProceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval. 505–514
work page 2017
-
[36]
Hongfei Zhang, Xia Song, Chenyan Xiong, Corby Rosset, Paul N Bennett, Nick Craswell, and Saurabh Tiwary. 2019. Generic intent representation in web search. InProceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval. 65–74. Enhancing Healthcare Search Intent Recognition with Query Representation Learni...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.