Recognition: no theorem link
MUSDA: Multi-source Multi-modality Unsupervised Domain Adaptive 3D Object Detection for Autonomous Driving
Pith reviewed 2026-05-12 03:31 UTC · model grok-4.3
The pith
A framework aligns camera and LiDAR features from multiple labeled sources and fuses their predictions to adapt 3D object detectors to an unlabeled target domain.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
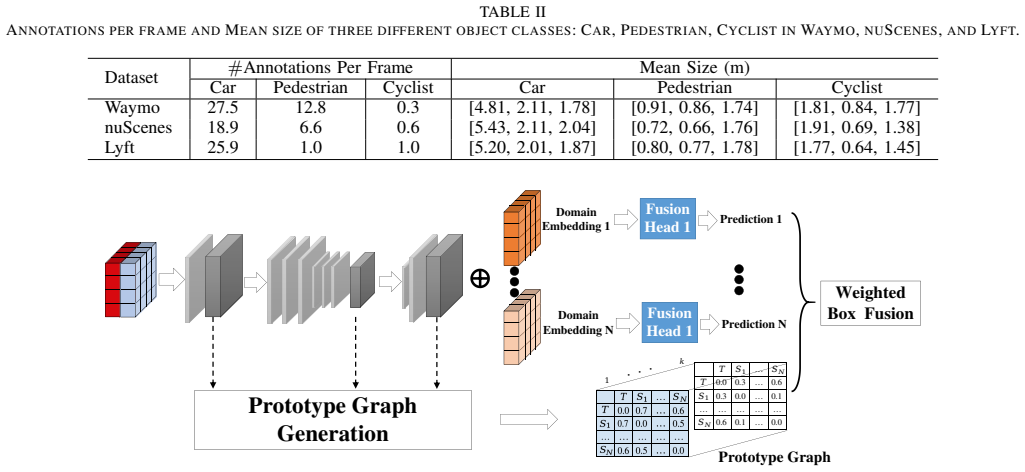
The central claim is that hierarchical spatially-conditioned domain classifiers can jointly align camera and LiDAR features at two distinct levels for each source-target domain pair, and that a prototype graph weighted fusion strategy can then aggregate predictions from multiple source detection heads to yield effective unsupervised domain adaptation for 3D object detection.
What carries the argument
Hierarchical spatially-conditioned domain classifiers that perform multi-level feature alignment for each modality and source-target pair, together with prototype graph weighted fusion that uses inter-domain prototype relations to combine multi-source outputs.
Load-bearing premise
The hierarchical classifiers can align camera and LiDAR features across domains without any target labels, and the prototype graph fusion step meaningfully improves the combined predictions.
What would settle it
Measure whether detection average precision on a new target domain drops below single-source baselines when the domain shift involves extreme conditions such as heavy rain or night driving that the source data do not contain.
Figures


read the original abstract
With the advancement of autonomous driving, numerous annotated multi-modality datasets have become available. This presents an opportunity to develop domain-adaptive 3D object detectors for new environments without relying on labor-intensive manual annotations. However, traditional domain adaptation methods typically focus on a single source domain or a single modality, limiting their effectiveness in multi-source, multi-modality scenarios. In this paper, we propose a novel framework for multi-source, multi-modality unsupervised domain adaptation in 3D object detection for autonomous driving. Given multiple labeled source domains and one unlabeled target domain, our framework first introduces hierarchical spatially-conditioned (HSC) domain classifiers, which jointly align features from both camera and LiDAR modalities at two distinct levels for each source-target domain pair. To effectively leverage information from multiple source domains, we construct a prototype graph between each pair of domains. Based on this, we develop a prototype graph weighted (PGW) multi-source fusion strategy to aggregate predictions from multiple source detection heads. Experimental results on three widely used 3D object detection datasets - Waymo, nuScenes, and Lyft - demonstrate that our proposed framework effectively integrates information across both modalities and source domains, consistently outperforming state-of-the-art methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MUSDA, a multi-source multi-modality unsupervised domain adaptation framework for 3D object detection in autonomous driving. It introduces hierarchical spatially-conditioned (HSC) domain classifiers to jointly align camera and LiDAR features at two levels for each source-target pair, and a prototype graph weighted (PGW) fusion strategy that constructs graphs between domain pairs to aggregate predictions from multiple source detection heads. The central claim is that this integrates information across modalities and sources, consistently outperforming state-of-the-art methods on the Waymo, nuScenes, and Lyft datasets.
Significance. If the empirical results and ablations hold, the work would address a practically relevant gap in adapting 3D detectors to new environments without target labels, extending single-source/single-modality UDA to multi-source multi-modality settings. The use of spatially-conditioned classifiers and graph-based fusion on prototypes offers a plausible way to leverage multiple labeled sources, but the significance is difficult to assess given the complete absence of quantitative results, error bars, or ablation tables in the abstract and the lack of verification for the key assumptions.
major comments (2)
- Abstract: the claim of consistent outperformance on Waymo, nuScenes, and Lyft is stated without any numerical results, tables, ablation studies, or implementation details. This leaves the central empirical claim without visible support, which is load-bearing for the contribution.
- Description of HSC domain classifiers and PGW fusion: both components depend on the quality of unlabelled target-domain prototypes (for adversarial alignment in HSC and for computing cross-domain weights in PGW). No experiment isolates whether PGW gains survive when prototypes are replaced by uniform or random weights, nor is there analysis showing that HSC alignment remains reliable when initial target features or pseudo-labels are noisy. This directly affects the weakest assumption identified in the stress-test.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and outline the revisions we will make to strengthen the presentation of our empirical claims and methodological assumptions.
read point-by-point responses
-
Referee: Abstract: the claim of consistent outperformance on Waymo, nuScenes, and Lyft is stated without any numerical results, tables, ablation studies, or implementation details. This leaves the central empirical claim without visible support, which is load-bearing for the contribution.
Authors: We agree that the abstract would benefit from explicit numerical support for the outperformance claim. In the revised manuscript we will add concise quantitative highlights (e.g., mAP gains on each dataset relative to the strongest single-source and multi-source baselines) while preserving the abstract's length. The full tables, ablation studies, and implementation details already appear in Sections 4 and 5; the abstract revision will simply make the central result visible at a glance. revision: yes
-
Referee: Description of HSC domain classifiers and PGW fusion: both components depend on the quality of unlabelled target-domain prototypes (for adversarial alignment in HSC and for computing cross-domain weights in PGW). No experiment isolates whether PGW gains survive when prototypes are replaced by uniform or random weights, nor is there analysis showing that HSC alignment remains reliable when initial target features or pseudo-labels are noisy. This directly affects the weakest assumption identified in the stress-test.
Authors: We acknowledge that an explicit sensitivity analysis to prototype quality would further validate the design. Our existing ablations (comparing full MUSDA against variants without HSC or without PGW) already quantify the contribution of each component under the same prototype-generation pipeline. We will add a new ablation that replaces the learned prototypes with uniform and random weights for PGW, and we will include a short discussion of how the two-level hierarchical conditioning in HSC mitigates early-stage noise in target features. These additions will be included in the revised experimental section. revision: partial
Circularity Check
No circularity: framework components are standard DA extensions without self-referential reductions
full rationale
The paper presents a descriptive framework for multi-source multi-modality UDA in 3D detection, introducing HSC domain classifiers for feature alignment and PGW fusion via prototype graphs. No equations, derivations, or parameter-fitting steps are shown that reduce any claimed prediction or result to its own inputs by construction. The abstract and description rely on empirical outperformance on Waymo/nuScenes/Lyft rather than tautological definitions or load-bearing self-citations. Components extend existing adversarial DA and prototype-based fusion ideas without renaming known results or smuggling ansatzes via self-citation. The derivation chain is self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Are we ready for autonomous driving? the kitti vision benchmark suite,
A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for autonomous driving? the kitti vision benchmark suite,” in2012 IEEE conference on computer vision and pattern recognition. IEEE, 2012, pp. 3354–3361
work page 2012
-
[2]
Lyft level 5 perception dataset 2019,
Lyft, “Lyft level 5 perception dataset 2019,” in https://level5.lyft.com/dataset/, 2019
work page 2019
-
[3]
nuscenes: A multimodal dataset for autonomous driving,
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11 621–11 631
work page 2020
-
[4]
Scalability in perception for autonomous driving: Waymo open dataset,
P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V . Patnaik, P. Tsui, J. Guo, Y . Zhou, Y . Chai, B. Caineet al., “Scalability in perception for autonomous driving: Waymo open dataset,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 2446–2454
work page 2020
-
[5]
Seeing through fog without seeing fog: Deep multi- modal sensor fusion in unseen adverse weather,
M. Bijelic, T. Gruber, F. Mannan, F. Kraus, W. Ritter, K. Dietmayer, and F. Heide, “Seeing through fog without seeing fog: Deep multi- modal sensor fusion in unseen adverse weather,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 11 682–11 692
work page 2020
-
[6]
Ithaca365: Dataset and driving perception under repeated and challenging weather conditions,
C. A. Diaz-Ruiz, Y . Xia, Y . You, J. Nino, J. Chen, J. Monica, X. Chen, K. Luo, Y . Wang, M. Emondet al., “Ithaca365: Dataset and driving perception under repeated and challenging weather conditions,” inPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 21 383–21 392
work page 2022
-
[7]
Argoverse 2: Next Generation Datasets for Self-Driving Perception and Forecasting
B. Wilson, W. Qi, T. Agarwal, J. Lambert, J. Singh, S. Khandelwal, B. Pan, R. Kumar, A. Hartnett, J. K. Ponteset al., “Argoverse 2: Next generation datasets for self-driving perception and forecasting,”arXiv preprint arXiv:2301.00493, 2023
work page internal anchor Pith review arXiv 2023
-
[8]
Msu-4s-the michigan state university four seasons dataset,
D. Kent, M. Alyaqoub, X. Lu, H. Khatounabadi, K. Sung, C. Scheller, A. Dalat, A. bin Thabit, R. Whitley, and H. Radha, “Msu-4s-the michigan state university four seasons dataset,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 22 658–22 667
work page 2024
-
[9]
Muses: The multi-sensor semantic per- ception dataset for driving under uncertainty,
T. Br ¨odermann, D. Bruggemann, C. Sakaridis, K. Ta, O. Liagouris, J. Corkill, and L. Van Gool, “Muses: The multi-sensor semantic per- ception dataset for driving under uncertainty,” inEuropean Conference on Computer Vision. Springer, 2025, pp. 21–38
work page 2025
-
[10]
Unsupervised domain adaptation via domain-adaptive diffusion,
D. Peng, Q. Ke, A. Ambikapathi, Y . Yazici, Y . Lei, and J. Liu, “Unsupervised domain adaptation via domain-adaptive diffusion,”IEEE Transactions on Image Processing, 2024
work page 2024
-
[11]
Dare-gram: Unsupervised domain adaptation regression by aligning inverse gram matrices,
I. Nejjar, Q. Wang, and O. Fink, “Dare-gram: Unsupervised domain adaptation regression by aligning inverse gram matrices,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 11 744–11 754
work page 2023
-
[12]
To adapt or not to adapt? real-time adaptation for semantic segmentation,
M. B. Colomer, P. L. Dovesi, T. Panagiotakopoulos, J. F. Carvalho, L. H ¨arenstam-Nielsen, H. Azizpour, H. Kjellstr ¨om, D. Cremers, and M. Poggi, “To adapt or not to adapt? real-time adaptation for semantic segmentation,” inProceedings of the IEEE/CVF International Confer- ence on Computer Vision, 2023, pp. 16 548–16 559
work page 2023
-
[13]
Adpl: Adaptive dual path learning for domain adaptation of semantic segmentation,
Y . Cheng, F. Wei, J. Bao, D. Chen, and W. Zhang, “Adpl: Adaptive dual path learning for domain adaptation of semantic segmentation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 8, pp. 9339–9356, 2023
work page 2023
-
[14]
X. Lu and H. Radha, “Dali: Domain adaptive lidar object detection via distribution-level and instance-level pseudo label denoising,”IEEE Transactions on Robotics, 2024
work page 2024
-
[15]
M. Kennerley, J.-G. Wang, B. Veeravalli, and R. T. Tan, “2pcnet: Two-phase consistency training for day-to-night unsupervised domain adaptive object detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 11 484–11 493
work page 2023
-
[16]
Confmix: Unsupervised domain adaptation for object detection via confidence-based mixing,
G. Mattolin, L. Zanella, E. Ricci, and Y . Wang, “Confmix: Unsupervised domain adaptation for object detection via confidence-based mixing,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2023, pp. 423–433
work page 2023
-
[17]
Multimodal 3d object detection on unseen domains,
D. Hegde, S. Lohit, K.-C. Peng, M. J. Jones, and V . M. Patel, “Multimodal 3d object detection on unseen domains,”arXiv preprint arXiv:2404.11764, 2024
-
[18]
Cmda: Cross-modal and domain adversarial adaptation for lidar-based 3d object detection,
G. Chang, W. Roh, S. Jang, D. Lee, D. Ji, G. Oh, J. Park, J. Kim, and S. Kim, “Cmda: Cross-modal and domain adversarial adaptation for lidar-based 3d object detection,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 2, 2024, pp. 972–980
work page 2024
-
[19]
D. Tsai, J. S. Berrio, M. Shan, S. Worrall, and E. Nebot, “See eye to eye: A lidar-agnostic 3d detection framework for unsupervised multi-target domain adaptation,”IEEE Robotics and Automation Letters, 2022
work page 2022
-
[20]
G. Eskandar, R. A. Marsden, P. Pandiyan, M. D ¨obler, K. Guirguis, and B. Yang, “An unsupervised domain adaptive approach for multimodal 2d object detection in adverse weather conditions,” in2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2022, pp. 10 865–10 872
work page 2022
-
[21]
Multi-source-free domain adaptive object detection,
S. Zhao, H. Yao, C. Lin, Y . Gao, and G. Ding, “Multi-source-free domain adaptive object detection,”International Journal of Computer Vision, vol. 132, no. 12, pp. 5950–5982, 2024
work page 2024
-
[22]
Multi-source domain adaptation for object detection with prototype- based mean teacher,
A. Belal, A. Meethal, F. P. Romero, M. Pedersoli, and E. Granger, “Multi-source domain adaptation for object detection with prototype- based mean teacher,” inProceedings of the IEEE/CVF Winter Confer- ence on Applications of Computer Vision, 2024, pp. 1277–1286
work page 2024
-
[23]
Ms3d++: Ensemble of experts for multi-source unsupervised domain adaptation in 3d object detection,
D. Tsai, J. S. Berrio, M. Shan, E. Nebot, and S. Worrall, “Ms3d++: Ensemble of experts for multi-source unsupervised domain adaptation in 3d object detection,” 2024
work page 2024
-
[24]
Ms3d: Leveraging multiple detectors for unsupervised domain adaptation in 3d object detection,
——, “Ms3d: Leveraging multiple detectors for unsupervised domain adaptation in 3d object detection,” in2023 IEEE 26th International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2023, pp. 140–147
work page 2023
-
[25]
Towards universal lidar-based 3d object detection by multi-domain knowledge transfer,
G. Wu, T. Cao, B. Liu, X. Chen, and Y . Ren, “Towards universal lidar-based 3d object detection by multi-domain knowledge transfer,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 8669–8678
work page 2023
-
[26]
Target-relevant knowledge preservation for multi-source domain adaptive object detection,
J. Wu, J. Chen, M. He, Y . Wang, B. Li, B. Ma, W. Gan, W. Wu, Y . Wang, and D. Huang, “Target-relevant knowledge preservation for multi-source domain adaptive object detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 5301–5310
work page 2022
-
[27]
Multi-source unsu- pervised domain adaptation for object detection,
D. Zhang, M. Ye, Y . Liu, L. Xiong, and L. Zhou, “Multi-source unsu- pervised domain adaptation for object detection,”Information Fusion, vol. 78, pp. 138–148, 2022
work page 2022
-
[28]
Multi-source domain adaptation for object detection,
X. Yao, S. Zhao, P. Xu, and J. Yang, “Multi-source domain adaptation for object detection,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 3273–3282
work page 2021
-
[29]
Domain-invariant disentangled network for generalizable object detection,
C. Lin, Z. Yuan, S. Zhao, P. Sun, C. Wang, and J. Cai, “Domain-invariant disentangled network for generalizable object detection,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 8771–8780
work page 2021
-
[30]
Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation,
Z. Liu, H. Tang, A. Amini, X. Yang, H. Mao, D. L. Rus, and S. Han, “Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation,” in2023 IEEE international conference on robotics and automation (ICRA). IEEE, 2023, pp. 2774–2781
work page 2023
-
[31]
Domain-adversarial training of neural networks,
Y . Ganin, E. Ustinova, H. Ajakan, P. Germain, H. Larochelle, F. Lavio- lette, M. Marchand, and V . Lempitsky, “Domain-adversarial training of neural networks,”The Journal of Machine Learning Research, vol. 17, no. 1, pp. 2096–2030, 2016
work page 2096
-
[32]
Every pixel matters: Center-aware feature alignment for domain adaptive object detector,
C. C. Hsu, Y . H. Tsai, Y . Y . Lin, and M. H. Yang, “Every pixel matters: Center-aware feature alignment for domain adaptive object detector,” in Proceedings of the European conference on computer vision (ECCV). Springer Science and Business Media Deutschland GmbH, 2020, pp. 733–748
work page 2020
-
[33]
Multiscale domain adaptive yolo for cross- domain object detection,
M. Hnewa and H. Radha, “Multiscale domain adaptive yolo for cross- domain object detection,” in2021 IEEE International Conference on Image Processing (ICIP). IEEE, 2021, pp. 3323–3327
work page 2021
-
[34]
Cross-domain weakly-supervised object detection through progressive domain adap- tation,
N. Inoue, R. Furuta, T. Yamasaki, and K. Aizawa, “Cross-domain weakly-supervised object detection through progressive domain adap- tation,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 5001–5009
work page 2018
-
[35]
MMDetection3D: OpenMMLab next-generation platform for general 3D object detection,
M. Contributors, “MMDetection3D: OpenMMLab next-generation platform for general 3D object detection,” https://github.com/open- mmlab/mmdetection3d, 2020
work page 2020
-
[36]
Train in germany, test in the usa: Making 3d object detectors generalize,
Y . Wang, X. Chen, Y . You, L. E. Li, B. Hariharan, M. Campbell, K. Q. Weinberger, and W.-L. Chao, “Train in germany, test in the usa: Making 3d object detectors generalize,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 11 713–11 723
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.