Recognition: no theorem link
Adaptive Action Chunking via Multi-Chunk Q Value Estimation
Pith reviewed 2026-05-12 02:24 UTC · model grok-4.3
The pith
ACH lets RL agents dynamically choose action sequence lengths by estimating values for all candidates in one Transformer forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ACH dynamically modulates chunk length by simultaneously estimating action-values for all candidate chunk lengths in a single forward pass of a Transformer-based architecture, allowing the agent to select the most effective chunk length adaptively based on the current state.
What carries the argument
Multi-chunk Q-value estimation, in which one Transformer forward pass produces separate Q-value estimates for every candidate chunk length so the policy can choose the best length per state.
If this is right
- Agents can improve behavioral consistency and reduce bootstrapping errors by adapting chunk length to the current state.
- The same architecture supports both offline pre-training and online fine-tuning without extra training signals.
- Performance improves on 34 diverse tasks, indicating better generalization across environments with varying optimal horizons.
- Training and inference cost remain comparable to a single fixed-length model because all estimates share one forward pass.
Where Pith is reading between the lines
- The method could lower the cost of hyperparameter search by removing the need to tune chunk length in advance.
- The single-pass multi-scale estimation pattern may transfer to other sequence-decision problems such as option discovery or hierarchical RL.
- In real-time control settings the adaptive choice might reduce unnecessary commitment to long plans when the environment changes rapidly.
Load-bearing premise
A single Transformer forward pass can produce accurate and non-interfering Q-value estimates for every candidate chunk length at once.
What would settle it
An ablation that replaces the shared Transformer head with independent Q-heads for each chunk length and measures whether the performance gap over fixed-length baselines disappears.
Figures




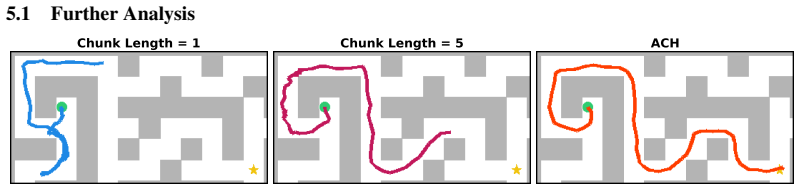


read the original abstract
Action chunking emerged as a pivotal technique in imitation learning, enabling policies to predict cohesive action sequences rather than single actions. Recently, this approach has expanded to reinforcement learning (RL), enhancing behavioral consistency and reducing bootstrapping errors in value function estimation. However, existing methods rely on a fixed chunk length, creating a performance bottleneck as the optimal length varies across states and tasks. In this paper, we propose Adaptive Action CHunking (ACH), a novel offline-to-online RL algorithm that dynamically modulates chunk length during both training and inference. To find the optimal chunk length for a dynamically varying current state, we simultaneously estimate action-values for all candidate chunk lengths in a single forward pass, using a Transformer-based architecture. Our mechanism allows the agent to select the most effective chunk length adaptively based on the current state. Evaluated on 34 challenging tasks, ACH consistently outperforms fixed-length baselines, demonstrating superior generalization and learning efficiency in complex environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Adaptive Action Chunking (ACH), an offline-to-online RL algorithm that dynamically selects action chunk length at each state by estimating Q-values for all candidate lengths simultaneously via a single Transformer forward pass and choosing the length with the highest Q-value. It claims this adaptive mechanism yields consistent outperformance over fixed-length chunking baselines on 34 challenging tasks, with gains in generalization and learning efficiency.
Significance. If the multi-chunk Q-estimation mechanism proves reliable, the approach could meaningfully advance action chunking in RL by removing the fixed-length bottleneck that limits prior methods. The single-pass architecture offers computational efficiency, and the scale of evaluation (34 tasks) provides a reasonable testbed for generalization claims.
major comments (2)
- [Method (multi-chunk Q estimation) and Experiments] The core technical claim (abstract and method section) rests on the Transformer producing accurate, comparable, and non-interfering Q-value estimates for multiple chunk lengths in one forward pass. No ablations, separate-head controls, auxiliary disentanglement losses, or per-length calibration experiments are described to isolate whether representational interference occurs or whether selection is driven by the adaptive mechanism rather than other architectural factors.
- [Experiments and Results] The experimental results (abstract) report consistent outperformance on 34 tasks but provide no details on run-to-run variance, statistical significance tests, or the exact composition of the fixed-length baselines (e.g., which lengths were tested and how they were chosen). This makes it difficult to assess whether the reported gains are robust or sensitive to hyperparameter choices.
minor comments (2)
- [Abstract] The abstract would benefit from explicitly stating the set of candidate chunk lengths considered and the precise Transformer architecture (number of layers, attention heads, output heads) to aid reproducibility.
- [Method] Notation for the multi-chunk Q-function and the selection rule should be formalized with equations in the method section rather than left at a high-level description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of the multi-chunk Q estimation and experimental details.
read point-by-point responses
-
Referee: [Method (multi-chunk Q estimation) and Experiments] The core technical claim (abstract and method section) rests on the Transformer producing accurate, comparable, and non-interfering Q-value estimates for multiple chunk lengths in one forward pass. No ablations, separate-head controls, auxiliary disentanglement losses, or per-length calibration experiments are described to isolate whether representational interference occurs or whether selection is driven by the adaptive mechanism rather than other architectural factors.
Authors: We agree that additional controls would better isolate the contribution of the joint estimation mechanism. In the revised manuscript we will add an ablation comparing the shared Transformer against a multi-head architecture with separate Q-heads per chunk length, along with an analysis of Q-value correlations across lengths to check for interference. These results will clarify whether adaptive selection is driven by the proposed mechanism. revision: yes
-
Referee: [Experiments and Results] The experimental results (abstract) report consistent outperformance on 34 tasks but provide no details on run-to-run variance, statistical significance tests, or the exact composition of the fixed-length baselines (e.g., which lengths were tested and how they were chosen). This makes it difficult to assess whether the reported gains are robust or sensitive to hyperparameter choices.
Authors: We acknowledge the need for greater experimental transparency. The revised version will report run-to-run variance with standard deviations across multiple seeds, include statistical significance tests comparing ACH to the fixed-length baselines, and explicitly describe the baseline chunk lengths tested together with the selection criteria used. revision: yes
Circularity Check
No circularity: new algorithmic proposal with no self-referential derivations or fitted predictions.
full rationale
The paper introduces ACH as a novel offline-to-online RL algorithm that uses a Transformer to simultaneously estimate Q-values for multiple chunk lengths in one forward pass, then selects the best length adaptively. No equations, derivations, or parameter-fitting steps are described that reduce to prior quantities by construction. The method is presented as an empirical algorithm evaluated on 34 tasks, with no load-bearing self-citations, uniqueness theorems, or ansatzes imported from the authors' prior work. The central claim (adaptive chunking via multi-chunk Q estimation) is independent of its own outputs and does not rename known results or call fitted inputs predictions. This is a standard non-circular algorithmic contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Michael Albergo and Eric Vanden-Eijnden. 2023. Building Normalizing Flows with Stochastic Interpolants. InThe Eleventh International Conference on Learning Representations
work page 2023
-
[2]
Philip J Ball, Laura Smith, Ilya Kostrikov, and Sergey Levine. 2023. Efficient online reinforce- ment learning with offline data. InInternational Conference on Machine Learning. PMLR, 1577–1594
work page 2023
-
[3]
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. 2025. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. 2024. π0: A Vision-Language-Action Flow Model for General Robot Control.arXiv preprint arXiv:2410.24164(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [5]
-
[6]
Jongseong Chae, Jongeui Park, Yongjae Shin, Gyeongmin Kim, Seungyul Han, and Youngchul Sung. [n. d.]. Flow Actor-Critic for Offline Reinforcement Learning. InThe Fourteenth Interna- tional Conference on Learning Representations
-
[7]
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. 2025. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research44, 10-11 (2025), 1684–1704
work page 2025
-
[8]
Perry Dong, Qiyang Li, Dorsa Sadigh, and Chelsea Finn. 2025. Expo: Stable reinforcement learning with expressive policies.arXiv preprint arXiv:2507.07986(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Philippe Hansen-Estruch, Ilya Kostrikov, Michael Janner, Jakub Grudzien Kuba, and Sergey Levine. 2023. Idql: Implicit q-learning as an actor-critic method with diffusion policies.arXiv preprint arXiv:2304.10573(2023)
work page internal anchor Pith review arXiv 2023
-
[10]
Dan Hendrycks and Kevin Gimpel. 2016. Gaussian Error Linear Units (GELUs).arXiv preprint arXiv:1606.08415(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[11]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models. Advances in neural information processing systems33 (2020), 6840–6851
work page 2020
-
[12]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. 2025. π0.5: a Vision- Language-Action Model with Open-World Generalization.arXiv preprint arXiv:2504.16054 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Changyeon Kim, Haeone Lee, Younggyo Seo, Kimin Lee, and Yuke Zhu. 2026. DEAS: DEtached value learning with Action Sequence for Scalable Offline RL. InThe Fourteenth International Conference on Learning Representations. https://openreview.net/forum? id=bVTaAXeBmE
work page 2026
-
[14]
Moo Jin Kim, Chelsea Finn, and Percy Liang. 2025. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Diederik P. Kingma and Jimmy Ba. 2015. Adam: A Method for Stochastic Optimization. In3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings
work page 2015
-
[16]
Ilya Kostrikov, Ashvin Nair, and Sergey Levine. 2022. Offline Reinforcement Learning with Implicit Q-Learning. InInternational Conference on Learning Representations
work page 2022
-
[17]
Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. 2020. Conservative q-learning for offline reinforcement learning.Advances in neural information processing systems33 (2020), 1179–1191. 10
work page 2020
-
[18]
Seunghyun Lee, Younggyo Seo, Kimin Lee, Pieter Abbeel, and Jinwoo Shin. 2022. Offline-to- online reinforcement learning via balanced replay and pessimistic q-ensemble. InConference on Robot Learning. PMLR, 1702–1712
work page 2022
-
[19]
Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. 2020. Offline reinforcement learning: Tutorial, review, and perspectives on open problems.arXiv preprint arXiv:2005.01643 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[20]
Ge Li, Dong Tian, Hongyi Zhou, Xinkai Jiang, Rudolf Lioutikov, and Gerhard Neumann. 2025. TOP-ERL: Transformer-based Off-Policy Episodic Reinforcement Learning. InThe Thirteenth International Conference on Learning Representations
work page 2025
-
[21]
Qiyang Li, Seohong Park, and Sergey Levine. 2026. Decoupled Q-Chunking. InThe Fourteenth International Conference on Learning Representations. https://openreview.net/forum? id=aqGNdZQL9l
work page 2026
-
[22]
Qiyang Li, Zhiyuan Zhou, and Sergey Levine. 2025. Reinforcement Learning with Action Chunking. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
work page 2025
-
[23]
Yuanchang Liang, Shikai Li, Shiji Song, and Gao Huang. 2026. Adaptive Action Chunking at Inference-time for Vision-Language-Action Models. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR). arXiv preprint arXiv:2604.04161
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. 2023. Flow Matching for Generative Modeling. InThe Eleventh International Conference on Learning Representations
work page 2023
-
[25]
Qin-Wen Luo, Ming-Kun Xie, Yewen Wang, and Sheng-Jun Huang. 2024. Optimistic critic reconstruction and constrained fine-tuning for general offline-to-online RL.Advances in Neural Information Processing Systems37 (2024), 108167–108207
work page 2024
-
[26]
Ajay Mandlekar, Danfei Xu, Josiah Wong, Soroush Nasiriany, Chen Wang, Rohun Kulkarni, Li Fei-Fei, Silvio Savarese, Yuke Zhu, and Roberto Martín-Martín. 2021. What Matters in Learning from Offline Human Demonstrations for Robot Manipulation. In5th Annual Conference on Robot Learning
work page 2021
- [27]
-
[28]
Mitsuhiko Nakamoto, Simon Zhai, Anikait Singh, Max Sobol Mark, Yi Ma, Chelsea Finn, Aviral Kumar, and Sergey Levine. 2023. Cal-ql: Calibrated offline rl pre-training for efficient online fine-tuning.Advances in Neural Information Processing Systems36 (2023), 62244–62269
work page 2023
-
[29]
Kwanyoung Park, Seohong Park, Youngwoon Lee, and Sergey Levine. 2026. Scalable Offline Model-Based RL with Action Chunks. InThe Fourteenth International Conference on Learning Representations.https://openreview.net/forum?id=WXGb9unEHo
work page 2026
-
[30]
Seohong Park, Kevin Frans, Benjamin Eysenbach, and Sergey Levine. 2025. OGBench: Benchmarking Offline Goal-Conditioned RL. InThe Thirteenth International Conference on Learning Representations
work page 2025
-
[31]
Seohong Park, Kevin Frans, Deepinder Mann, Benjamin Eysenbach, Aviral Kumar, and Sergey Levine. 2025. Horizon Reduction Makes RL Scalable. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
work page 2025
-
[32]
Seohong Park, Qiyang Li, and Sergey Levine. 2025. Flow Q-Learning. InInternational Conference on Machine Learning (ICML)
work page 2025
-
[33]
Kohei Sendai, Maxime Alvarez, Tatsuya Matsushima, Yutaka Matsuo, and Yusuke Iwasawa
- [34]
-
[35]
Younggyo Seo and Pieter Abbeel. 2025. Coarse-to-fine Q-Network with Action Sequence for Data-Efficient Reinforcement Learning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems.https://openreview.net/forum?id=VoFXUNc9Zh
work page 2025
-
[36]
Yongjae Shin, Jongseong Chae, Jongeui Park, and Youngchul Sung. 2026. Flow Matching with Injected Noise for Offline-to-Online Reinforcement Learning. InThe Fourteenth Inter- national Conference on Learning Representations. https://openreview.net/forum?id= 6wd38R8L0Z
work page 2026
-
[37]
Yongjae Shin, Jeonghye Kim, Whiyoung Jung, Sunghoon Hong, Deunsol Yoon, Youngsoo Jang, Geon-Hyeong Kim, Jongseong Chae, Youngchul Sung, Kanghoon Lee, and Woohyung Lim. 2025. Online Pre-Training for Offline-to-Online Reinforcement Learning. InForty-second International Conference on Machine Learning
work page 2025
-
[38]
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. 2015. Deep unsupervised learning using nonequilibrium thermodynamics. InInternational conference on machine learning. pmlr, 2256–2265
work page 2015
- [39]
-
[40]
1998.Reinforcement learning: An introduction
Richard S Sutton, Andrew G Barto, et al. 1998.Reinforcement learning: An introduction. V ol. 1. MIT press Cambridge
work page 1998
-
[41]
Denis Tarasov, Vladislav Kurenkov, Alexander Nikulin, and Sergey Kolesnikov. 2023. Revisiting the minimalist approach to offline reinforcement learning.Advances in Neural Information Processing Systems36 (2023), 11592–11620
work page 2023
-
[42]
Dong Tian, Onur Celik, and Gerhard Neumann. 2026. Chunking the Critic: A Transformer- based Soft Actor-Critic with N-Step Returns. InThe Fourteenth International Conference on Learning Representations.https://openreview.net/forum?id=rb5eTktqbc
work page 2026
-
[43]
Shenzhi Wang, Qisen Yang, Jiawei Gao, Matthieu Lin, Hao Chen, Liwei Wu, Ning Jia, Shiji Song, and Gao Huang. 2023. Train once, get a family: State-adaptive balances for offline-to- online reinforcement learning.Advances in Neural Information Processing Systems36 (2023), 47081–47104
work page 2023
-
[44]
Jialong Wu, Haixu Wu, Zihan Qiu, Jianmin Wang, and Mingsheng Long. 2022. Supported policy optimization for offline reinforcement learning.Advances in Neural Information Processing Systems35 (2022), 31278–31291
work page 2022
-
[45]
Jiarui Yang, Bin Zhu, Jingjing Chen, and Yu-Gang Jiang. 2026. Actor-critic for continuous action chunks: A reinforcement learning framework for long-horizon robotic manipulation with sparse reward. InProceedings of the AAAI Conference on Artificial Intelligence, V ol. 40. 18692–18700
work page 2026
-
[46]
Zishun Yu and Xinhua Zhang. 2023. Actor-critic alignment for offline-to-online reinforcement learning. InInternational Conference on Machine Learning. PMLR, 40452–40474
work page 2023
-
[47]
Haichao Zhang, Wei Xu, and Haonan Yu. 2023. Policy Expansion for Bridging Offline- to-Online Reinforcement Learning. InThe Eleventh International Conference on Learning Representations
work page 2023
-
[48]
Yinmin Zhang, Jie Liu, Chuming Li, Yazhe Niu, Yaodong Yang, Yu Liu, and Wanli Ouyang
-
[49]
In Proceedings of the AAAI Conference on Artificial Intelligence, V ol
A Perspective of Q-value Estimation on Offline-to-Online Reinforcement Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, V ol. 38. 16908–16916
-
[50]
Tony Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. 2023. Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware.Robotics: Science and Systems XIX(2023)
work page 2023
-
[51]
Zhiyuan Zhou, Andy Peng, Qiyang Li, Sergey Levine, and Aviral Kumar. 2024. Efficient Online Reinforcement Learning Fine-Tuning Need Not Retain Offline Data. InThe Thirteenth International Conference on Learning Representations. 12 A Limitations Since the proposed method employs a Transformer as the value function, which is relatively heavier than the MLP ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.