Recognition: 2 theorem links
· Lean TheoremExtraVAR: Stage-Aware RoPE Remapping for Resolution Extrapolation in Visual Autoregressive Models
Pith reviewed 2026-05-12 02:58 UTC · model grok-4.3
The pith
Stage-aware frequency remapping and entropy-based attention scaling let visual autoregressive models generate higher-resolution images without repetition or lost detail.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Visual autoregressive models generate images stage by stage, with each stage dominated by a different RoPE frequency band; when resolution increases, the dominant band for a stage is no longer aligned, producing global repetition, local repetition, or detail loss. Stage-Aware RoPE Remapping assigns a distinct remapping rule to each band so that every stage retains its intended frequency behavior. Entropy-Driven Adaptive Attention Calibration measures attention dispersion with a resolution-invariant normalized entropy and supplies a closed-form per-head scale that restores the training-resolution entropy distribution at the new resolution.
What carries the argument
Stage-Aware RoPE Remapping, which pairs each dominant frequency band with a stage-specific remapping rule, together with Entropy-Driven Adaptive Attention Calibration, which derives a closed-form per-head scaling factor from normalized entropy to match extrapolated attention entropy to its training counterpart.
Load-bearing premise
The three failure modes are caused only by a band-stage mismatch in RoPE frequencies, and the proposed remapping rules plus entropy scaling will continue to work at new resolutions without any retraining or per-resolution tuning.
What would settle it
Generate images at a held-out resolution using the method and count whether global or local repetition patterns appear at rates comparable to naive extrapolation baselines.
Figures





read the original abstract
Visual Autoregressive (VAR) models have emerged as a strong alternative to diffusion for image synthesis, yet their fixed training resolution prevents direct generation at higher resolutions. Naively transferring training-free extrapolation methods from LLMs or diffusion models to VAR yields three characteristic failure modes: global repetition, local repetition, and detail degradation. We trace them to a unified band-stage mismatch: VAR generates images in a coarse-to-fine, scale-wise process where each stage is driven by a distinct dominant RoPE frequency band, and each failure mode emerges when the dominant band of a particular stage is disrupted. Building on this insight, we propose Stage-Aware RoPE Remapping, a training-free strategy that assigns each frequency band a stage-specific remapping rule, jointly suppressing all three failure modes. We further observe that attention becomes systematically dispersed as the image resolution increases. Existing methods typically depend on predefined attention scaling factors, which are neither adaptive to the target resolution nor capable of faithfully capturing the actual extent of attention dispersion. We therefore propose Entropy-Driven Adaptive Attention Calibration, which quantifies dispersion via a resolution-invariant normalized entropy and yields a closed-form per-head scaling factor that realigns the extrapolated-resolution attention entropy with its training-resolution counterpart. Extensive experiments show that our method consistently outperforms prior resolution-extrapolation methods in both structural coherence and fine-detail fidelity. Our code is available at https://github.com/feihongyan1/ExtraVAR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that naive resolution extrapolation in Visual Autoregressive (VAR) models produces three failure modes—global repetition, local repetition, and detail degradation—due to a unified band-stage mismatch in RoPE frequencies across the coarse-to-fine stages. It proposes two training-free fixes: Stage-Aware RoPE Remapping, which assigns stage-specific remapping rules to frequency bands, and Entropy-Driven Adaptive Attention Calibration, which computes a resolution-invariant normalized entropy to derive a closed-form per-head scaling factor that restores training-resolution attention entropy. Experiments reportedly show consistent outperformance over prior extrapolation methods in structural coherence and fine-detail fidelity, with code released.
Significance. If the diagnosis and fixes hold, the work is significant for enabling practical high-resolution generation with VAR models without retraining or per-resolution tuning. Strengths include the training-free closed-form derivations, the unified treatment of multiple failure modes, and the public code release, which supports reproducibility. This addresses a key limitation in scale-wise autoregressive vision models as they compete with diffusion approaches.
major comments (2)
- [Introduction and §3] Introduction and §3 (diagnosis of failure modes): The claim that global repetition, local repetition, and detail degradation arise solely from a unified band-stage RoPE mismatch is load-bearing for the entire method. The manuscript traces the modes to dominant frequency bands per stage but provides no ablation or analysis ruling out independent causes such as stage-wise token count changes or unmodeled cross-stage dependencies. If these exist, the proposed remapping rules address only a subset of the problem.
- [§4.2] §4.2 (Entropy-Driven Adaptive Attention Calibration): The closed-form per-head scaling factor is derived from a resolution-invariant normalized entropy to realign attention dispersion. However, the derivation assumes entropy fully captures dispersion; it is unclear whether this accounts for resolution-dependent changes in attention patterns beyond entropy (e.g., head-specific or spatial variations). The paper should report a direct comparison of the predicted scaling factor against measured entropy at extrapolated resolutions to validate the formula.
minor comments (2)
- [Abstract] Abstract: States 'extensive experiments' and 'consistent outperformance' but omits specific quantitative metrics, datasets, or extrapolation factors, making it hard to assess the strength of the empirical claims without the full tables.
- [Method] Notation: The description of 'normalized entropy' and 'stage-specific remapping rules' would benefit from an explicit equation or pseudocode early in the method section to clarify the closed-form nature before the experiments.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We have carefully considered each major comment and provide point-by-point responses below. We believe these clarifications and proposed revisions will improve the paper's rigor and clarity.
read point-by-point responses
-
Referee: [Introduction and §3] Introduction and §3 (diagnosis of failure modes): The claim that global repetition, local repetition, and detail degradation arise solely from a unified band-stage RoPE mismatch is load-bearing for the entire method. The manuscript traces the modes to dominant frequency bands per stage but provides no ablation or analysis ruling out independent causes such as stage-wise token count changes or unmodeled cross-stage dependencies. If these exist, the proposed remapping rules address only a subset of the problem.
Authors: We appreciate the referee highlighting this important aspect. In §3, we provide a detailed diagnosis linking each failure mode to specific band-stage mismatches through frequency analysis and visualization of attention patterns. While we did not include an explicit ablation isolating RoPE effects from token count variations, our experiments demonstrate that applying the stage-aware remapping alone significantly mitigates all three failure modes, even as token counts change with resolution. This suggests the RoPE mismatch is the dominant factor. To address the concern, we will add a discussion and a targeted ablation in the revised manuscript to further rule out or quantify contributions from other potential causes. revision: partial
-
Referee: [§4.2] §4.2 (Entropy-Driven Adaptive Attention Calibration): The closed-form per-head scaling factor is derived from a resolution-invariant normalized entropy to realign attention dispersion. However, the derivation assumes entropy fully captures dispersion; it is unclear whether this accounts for resolution-dependent changes in attention patterns beyond entropy (e.g., head-specific or spatial variations). The paper should report a direct comparison of the predicted scaling factor against measured entropy at extrapolated resolutions to validate the formula.
Authors: Thank you for this valuable suggestion. The Entropy-Driven Adaptive Attention Calibration in §4.2 derives the scaling factor from the normalized entropy, which we show is approximately invariant across resolutions in our analysis. To validate the closed-form formula, we will include in the revised manuscript a direct comparison between the predicted scaling factors and the measured attention entropy at extrapolated resolutions for various heads and resolutions. This will confirm that the formula accurately restores the training-resolution entropy levels. revision: yes
Circularity Check
No circularity: explicit rules and closed-form factors derived from analysis, not fitted inputs or self-citations
full rationale
The paper's core claims rest on an observational diagnosis of failure modes traced to band-stage RoPE mismatch, followed by explicit stage-specific remapping rules and a closed-form entropy-based scaling factor. These are presented as training-free constructions that do not reduce to parameters fitted on target-resolution data or to quantities defined by the same constants used in evaluation. No equations equate a 'prediction' back to its own inputs by construction, and the central premise is not justified solely via self-citation chains. The method remains self-contained against external benchmarks, with the remapping and calibration steps adding independent content beyond renaming or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VAR models generate images in a coarse-to-fine scale-wise process where each stage is driven by a distinct dominant RoPE frequency band
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We trace them to a unified band-stage mismatch: VAR generates images in a coarse-to-fine, scale-wise process where each stage is driven by a distinct dominant RoPE frequency band... Stage-Aware RoPE Remapping... Entropy-Driven Adaptive Attention Calibration, which quantifies dispersion via a resolution-invariant normalized entropy
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
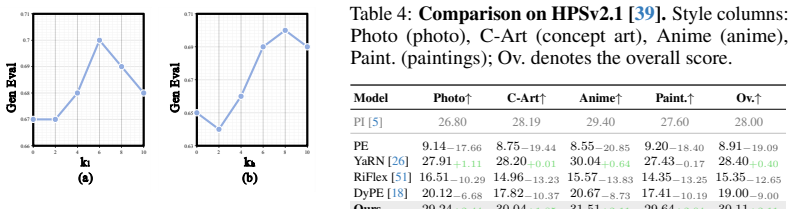
K=13 generation scale steps... kl=6 and kh=9... High/Mid and Mid/Low band boundaries
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Multidiffusion: Fusing diffusion paths for controlled image generation
Omer Bar-Tal, Lior Yariv, Yaron Lipman, and Tali Dekel. Multidiffusion: Fusing diffusion paths for controlled image generation. InInternational Conference on Machine Learning, 2023
work page 2023
-
[2]
Jiazi Bu, Pengyang Ling, Yujie Zhou, Pan Zhang, Tong Wu, Xiaoyi Dong, Yuhang Zang, Yuhang Cao, Dahua Lin, and Jiaqi Wang. Hiflow: Training-free high-resolution image generation with flow-aligned guidance.arXiv preprint arXiv:2504.06232, 2025
-
[3]
Pixart- σ: Weak-to-strong training of diffusion transformer for 4k text-to-image generation
Junsong Chen, Chongjian Ge, Enze Xie, Yue Wu, Lewei Yao, Xiaozhe Ren, Zhongdao Wang, Ping Luo, Huchuan Lu, and Zhenguo Li. Pixart- σ: Weak-to-strong training of diffusion transformer for 4k text-to-image generation. InEuropean Conference on Computer Vision, pages 74–91. Springer, 2024
work page 2024
-
[4]
Generative pretraining from pixels
Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Heewoo Jun, David Luan, and Ilya Sutskever. Generative pretraining from pixels. InInternational conference on machine learning, pages 1691–1703. PMLR, 2020
work page 2020
-
[5]
Extending Context Window of Large Language Models via Positional Interpolation
Shouyuan Chen, Sherman Wong, Liangjian Chen, and Yuandong Tian. Extending context window of large language models via positional interpolation.arXiv preprint arXiv:2306.15595, 2023
work page internal anchor Pith review arXiv 2023
-
[6]
Critical attention scaling in long-context transformers
Shi Chen, Zhengjiang Lin, Yury Polyanskiy, and Philippe Rigollet. Critical attention scaling in long-context transformers. InInternational Conference on Learning Representations, 2026
work page 2026
-
[7]
Ruoyi Du, Dongyang Liu, Le Zhuo, Qi Qin, Hongsheng Li, Zhanyu Ma, and Peng Gao. I-max: Max- imize the resolution potential of pre-trained rectified flow transformers with projected flow.ArXiv, abs/2410.07536, 2024
-
[8]
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
work page 2023
-
[9]
Fastvar: Linear visual autoregressive modeling via cached token pruning
Hang Guo, Yawei Li, Taolin Zhang, Jiangshan Wang, Tao Dai, Shu-Tao Xia, and Luca Benini. Fastvar: Linear visual autoregressive modeling via cached token pruning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 19011–19021, 2025
work page 2025
-
[10]
Make a cheap scaling: A self-cascade diffusion model for higher-resolution adaptation
Lanqing Guo, Yingqing He, Haoxin Chen, Menghan Xia, Xiaodong Cun, Yufei Wang, Siyu Huang, Yong Zhang, Xintao Wang, Qifeng Chen, et al. Make a cheap scaling: A self-cascade diffusion model for higher-resolution adaptation. InEuropean conference on computer vision, pages 39–55. Springer, 2024
work page 2024
-
[11]
Moayed Haji-Ali, Guha Balakrishnan, and Vicente Ordonez. Elasticdiffusion: Training-free arbitrary size image generation through global-local content separation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6603–6612, 2024
work page 2024
-
[12]
Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis
Jian Han, Jinlai Liu, Yi Jiang, Bin Yan, Yuqi Zhang, Zehuan Yuan, Bingyue Peng, and Xiaobing Liu. Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 15733–15744, 2025
work page 2025
-
[13]
Scalecrafter: Tuning-free higher-resolution visual generation with diffusion models
Yingqing He, Shaoshu Yang, Haoxin Chen, Xiaodong Cun, Menghan Xia, Yong Zhang, Xintao Wang, Ran He, Qifeng Chen, and Ying Shan. Scalecrafter: Tuning-free higher-resolution visual generation with diffusion models. InThe Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[14]
simple diffusion: End-to-end diffusion for high resolution images
Emiel Hoogeboom, Jonathan Heek, and Tim Salimans. simple diffusion: End-to-end diffusion for high resolution images. InInternational Conference on Machine Learning, pages 13213–13232. PMLR, 2023
work page 2023
-
[15]
ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
Xiwei Hu, Rui Wang, Yixiao Fang, Bin Fu, Pei Cheng, and Gang Yu. Ella: Equip diffusion models with llm for enhanced semantic alignment.arXiv preprint arXiv:2403.05135, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Fouriscale: A frequency perspective on training-free high-resolution image synthesis
Linjiang Huang, Rongyao Fang, Aiping Zhang, Guanglu Song, Si Liu, Yu Liu, and Hongsheng Li. Fouriscale: A frequency perspective on training-free high-resolution image synthesis. InEuropean conference on computer vision, pages 196–212. Springer, 2024
work page 2024
-
[17]
Entropy rectifying guidance for diffusion and flow models
Tariq Berrada Ifriqi, Adriana Romero-Soriano, Michal Drozdzal, Jakob Verbeek, and Karteek Alahari. Entropy rectifying guidance for diffusion and flow models. InNeurIPS 2025-Thirty-ninth Conference on Neural Information Processing Systems, 2025
work page 2025
-
[18]
Noam Issachar, Guy Yariv, Sagie Benaim, Yossi Adi, Dani Lischinski, and Raanan Fattal. Dype: Dynamic position extrapolation for ultra high resolution diffusion.arXiv preprint arXiv:2510.20766, 2025. 10
-
[19]
Zhiyu Jin, Xuli Shen, Bin Li, and Xiangyang Xue. Training-free diffusion model adaptation for variable- sized text-to-image synthesis.Advances in Neural Information Processing Systems, 36:70847–70860, 2023
work page 2023
-
[20]
Amirhossein Kazemnejad, Inkit Padhi, Karthikeyan Natesan Ramamurthy, Payel Das, and Siva Reddy. The impact of positional encoding on length generalization in transformers.Advances in Neural Information Processing Systems, 36:24892–24928, 2023
work page 2023
-
[21]
Diffusehigh: Training-free progressive high-resolution image synthesis through structure guidance
Younghyun Kim, Geunmin Hwang, Junyu Zhang, and Eunbyung Park. Diffusehigh: Training-free progressive high-resolution image synthesis through structure guidance. InProceedings of the AAAI conference on artificial intelligence, pages 4338–4346, 2025
work page 2025
-
[22]
Scalediff: Higher- resolution image synthesis via efficient and model-agnostic diffusion
Sungho Koh, SeungJu Cha, Hyunwoo Oh, Kwanyoung Lee, and Dong-Jin Kim. Scalediff: Higher- resolution image synthesis via efficient and model-agnostic diffusion. InAdvances in Neural Information Processing Systems, 2025
work page 2025
-
[23]
Yuseung Lee, Kunho Kim, Hyunjin Kim, and Minhyuk Sung. Syncdiffusion: Coherent montage via synchronized joint diffusions.Advances in Neural Information Processing Systems, 36:50648–50660, 2023
work page 2023
-
[24]
Yexin Liu, Wen-Jie Shu, Zile Huang, Haoze Zheng, Yueze Wang, Manyuan Zhang, Ser-Nam Lim, and Harry Yang. Alignvid: Training-free attention scaling for semantic fidelity in text-guided image-to-video generation.arXiv preprint arXiv:2512.01334, 2025
- [25]
-
[26]
Yarn: Efficient context window extension of large language models
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. Yarn: Efficient context window extension of large language models. InInternational Conference on Learning Representations, 2024
work page 2024
-
[27]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Freescale: Unleashing the resolution of diffusion models via tuning-free scale fusion
Haonan Qiu, Shiwei Zhang, Yujie Wei, Ruihang Chu, Hangjie Yuan, Xiang Wang, Yingya Zhang, and Ziwei Liu. Freescale: Unleashing the resolution of diffusion models via tuning-free scale fusion. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 16893–16903, 2025
work page 2025
-
[29]
Jingjing Ren, Wenbo Li, Haoyu Chen, Renjing Pei, Bin Shao, Yong Guo, Long Peng, Fenglong Song, and Lei Zhu. Ultrapixel: Advancing ultra high-resolution image synthesis to new peaks.Advances in Neural Information Processing Systems, 37:111131–111171, 2024
work page 2024
-
[30]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
work page 2024
-
[31]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Peize Sun, Yi Jiang, Shoufa Chen, Shilong Zhang, Bingyue Peng, Ping Luo, and Zehuan Yuan. Autore- gressive model beats diffusion: Llama for scalable image generation.arXiv preprint arXiv:2406.06525, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Jiangtong Tan, Hu Yu, Jie Huang, Jie Xiao, and Feng Zhao. Freepca: Integrating consistency information across long-short frames in training-free long video generation via principal component analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27979– 27988, 2025
work page 2025
-
[33]
Haotian Tang, Yecheng Wu, Shang Yang, Enze Xie, Junsong Chen, Junyu Chen, Zhuoyang Zhang, Han Cai, Yao Lu, and Song Han. Hart: Efficient visual generation with hybrid autoregressive transformer.arXiv preprint arXiv:2410.10812, 2024
-
[34]
Relay diffusion: Unifying diffusion process across resolutions for image synthesis
Jiayan Teng, Wendi Zheng, Ming Ding, Wenyi Hong, Jianqiao Wangni, Zhuoyi Yang, and Jie Tang. Relay diffusion: Unifying diffusion process across resolutions for image synthesis. InInternational Conference on Learning Representations, 2024
work page 2024
-
[35]
Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Liwei Wang. Visual autoregressive modeling: Scalable image generation via next-scale prediction.Advances in neural information processing systems, 37:84839–84865, 2024
work page 2024
-
[36]
Pixel recurrent neural networks
Aäron Van Den Oord, Nal Kalchbrenner, and Koray Kavukcuoglu. Pixel recurrent neural networks. In International conference on machine learning, pages 1747–1756. PMLR, 2016. 11
work page 2016
-
[37]
Emu3: Next-Token Prediction is All You Need
Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, et al. Emu3: Next-token prediction is all you need.arXiv preprint arXiv:2409.18869, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Native-resolution image synthesis
Zidong Wang, Lei Bai, Xiangyu Yue, Wanli Ouyang, and Yiyuan Zhang. Native-resolution image synthesis. InAdvances in Neural Information Processing Systems, 2025
work page 2025
-
[39]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis.arXiv preprint arXiv:2306.09341, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Sana: Efficient high-resolution image synthesis with linear diffusion transformers
Enze Xie, Junsong Chen, Junyu Chen, Han Cai, Haotian Tang, Yujun Lin, Zhekai Zhang, Muyang Li, Ligeng Zhu, Yao Lu, et al. Sana: Efficient high-resolution image synthesis with linear diffusion transformers. InInternational Conference on Learning Representations, 2025
work page 2025
-
[41]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. Show-o: One single transformer to unify multimodal understanding and generation.arXiv preprint arXiv:2408.12528, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gunjan Baid, Zirui Wang, Vijay Vasudevan, Alexander Ku, Yinfei Yang, Burcu Karagol Ayan, et al. Scaling autoregressive models for content-rich text-to-image generation.arXiv preprint arXiv:2206.10789, 2(3):5, 2022
work page internal anchor Pith review arXiv 2022
-
[43]
Ultra-resolution adaptation with ease
Ruonan Yu, Songhua Liu, Zhenxiong Tan, and Xinchao Wang. Ultra-resolution adaptation with ease. In Proceedings of the 42nd International Conference on Machine Learning, pages 73241–73261. PMLR, 2025
work page 2025
-
[44]
Guohui Zhang, Jiangtong Tan, Linjiang Huang, Zhonghang Yuan, Mingde Yao, Jie Huang, and Feng Zhao. Infoscale: Unleashing training-free variable-scaled image generation via effective utilization of information.arXiv preprint arXiv:2509.01421, 2025
-
[45]
Diffusion-4k: Ultra-high-resolution im- age synthesis with latent diffusion models
Jinjin Zhang, Qiuyu Huang, Junjie Liu, Xiefan Guo, and Di Huang. Diffusion-4k: Ultra-high-resolution im- age synthesis with latent diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 23464–23473, 2025
work page 2025
-
[46]
Hidiffusion: Unlock- ing higher-resolution creativity and efficiency in pretrained diffusion models
Shen Zhang, Zhaowei Chen, Zhenyu Zhao, Yuhao Chen, Yao Tang, and Jiajun Liang. Hidiffusion: Unlock- ing higher-resolution creativity and efficiency in pretrained diffusion models. InEuropean Conference on Computer Vision, pages 145–161. Springer, 2024
work page 2024
-
[47]
Ledit: Your length-extrapolatable diffusion transformer without positional encoding
Shen Zhang, Siyuan Liang, Yaning Tan, Zhaowei Chen, Linze Li, Ge Wu, Yuhao Chen, Shuheng Li, Zhenyu Zhao, Caihua Chen, et al. Ledit: Your length-extrapolatable diffusion transformer without positional encoding. InAdvances in Neural Information Processing Systems, 2025
work page 2025
-
[48]
Extending llms’ context window with 100 samples.arXiv preprint arXiv:2401.07004, 2024
Yikai Zhang, Junlong Li, and Pengfei Liu. Extending llms’ context window with 100 samples.arXiv preprint arXiv:2401.07004, 2024
-
[49]
Zhenyu Zhang, Runjin Chen, Shiwei Liu, Zhewei Yao, Olatunji Ruwase, Beidi Chen, Xiaoxia Wu, and Zhangyang Wang. Found in the middle: How language models use long contexts better via plug-and-play positional encoding.Advances in Neural Information Processing Systems, 37:60755–60775, 2024
work page 2024
-
[50]
Frecas: Efficient higher-resolution image generation via frequency-aware cascaded sampling
Zhengqiang Zhang, Ruihuang Li, and Lei Zhang. Frecas: Efficient higher-resolution image generation via frequency-aware cascaded sampling. InInternational Conference on Learning Representations, 2025
work page 2025
-
[51]
Riflex: A free lunch for length extrapolation in video diffusion transformers
Min Zhao, Guande He, Yixiao Chen, Hongzhou Zhu, Chongxuan Li, and Jun Zhu. Riflex: A free lunch for length extrapolation in video diffusion transformers.arXiv preprint arXiv:2502.15894, 2025
-
[52]
Min Zhao, Bokai Yan, Xue Yang, Hongzhou Zhu, Jintao Zhang, Shilong Liu, Chongxuan Li, and Jun Zhu. Ultraimage: Rethinking resolution extrapolation in image diffusion transformers.arXiv preprint arXiv:2512.04504, 2025
-
[53]
Any- size-diffusion: Toward efficient text-driven synthesis for any-size hd images
Qingping Zheng, Yuanfan Guo, Jiankang Deng, Jianhua Han, Ying Li, Songcen Xu, and Hang Xu. Any- size-diffusion: Toward efficient text-driven synthesis for any-size hd images. InProceedings of the AAAI Conference on Artificial Intelligence, pages 7571–7578, 2024
work page 2024
-
[54]
Understanding the rope extensions of long-context llms: An attention perspective
Meizhi Zhong, Chen Zhang, Yikun Lei, Xikai Liu, Yan Gao, Yao Hu, Kehai Chen, and Min Zhang. Understanding the rope extensions of long-context llms: An attention perspective. InProceedings of the 31st International Conference on Computational Linguistics, pages 8955–8962, 2025. 12 A Background A.1 Visual autoregressive modeling via next-scale prediction Vi...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.