Recognition: 1 theorem link
· Lean TheoremExplanation-Aware Learning for Enhanced Interpretability in Biomedical Imaging
Pith reviewed 2026-05-12 02:11 UTC · model grok-4.3
The pith
Incorporating explanation loss during training improves alignment of medical image model explanations with clinical annotations while keeping accuracy comparable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that adding an explanation loss term to the training objective of deep neural networks for biomedical images guides attention to clinically meaningful regions, yielding quantitatively improved explanation alignment as measured by annotation coverage and saliency precision while maintaining comparable predictive accuracy on chest X-ray datasets.
What carries the argument
Explanation loss added to the training objective, measured by the new metrics of annotation coverage and saliency precision, to enforce spatial faithfulness to clinical annotations.
If this is right
- A clear trade-off exists between explanation quality and the coefficient strength of the added loss term.
- Quantitative statistical analysis shows consistently improved explanation alignment across tested configurations.
- The approach extends to a broad range of annotated biomedical imaging modalities beyond chest X-rays.
- Practical guidance emerges for incorporating explanation loss under conditions of noisy clinical annotations.
Where Pith is reading between the lines
- This method could reduce reliance on separate post-hoc explanation techniques when deploying medical imaging models.
- High-quality clinical annotations become even more critical for effective model guidance during training.
- The framework might be tested on modalities such as MRI or CT to check for similar gains in explanation faithfulness.
- It could increase model resistance to learning from confounding or spurious image features.
Load-bearing premise
The provided clinical annotations reliably identify the features the model should use, and balancing the explanation loss does not introduce new unintended biases.
What would settle it
Training identical models with and without the explanation loss on a held-out set of annotated images and finding no improvement in annotation coverage or saliency precision would falsify the central claim.
Figures




read the original abstract
Deep neural networks for medical image diagnosis often achieve high predictive accuracy while relying on spurious or clinically irrelevant visual cues, limiting their trustworthiness in practice. Post-hoc explanation methods are widely used to visualize model decisions in the form of saliency maps; however, these explanations do not influence how models learn during training, allowing non-causal or confounding features to persist. This motivates the incorporation of explanation supervision directly into the training objective to guide model attention toward clinically meaningful regions and promote clinically grounded decision-making. This paper presents a systematic approach to integrate explanation loss into model training and analyzes how different explanation loss designs and supervision strengths influence both predictive performance and spatial faithfulness of explanations. To quantitatively assess interpretability, two complementary explanation performance metrics-annotation coverage and saliency precision-are introduced, enabling rigorous evaluation beyond qualitative visualization. Our experimental results reveal a clear trade-off between explanation quality and explanation loss coefficients. Furthermore, quantitative statistical analysis yields consistently improved explanation alignment while maintaining comparable accuracy. Experiments were conducted on annotated chest X-ray datasets; however, the proposed framework is applicable to a broad range of annotated biomedical imaging modalities. Overall, these findings demonstrate that explanation supervision is not a monolithic design choice and provide practical guidance for incorporating explanation loss into training objectives under noisy clinical annotations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes integrating explanation supervision directly into the training objective of deep neural networks for biomedical image diagnosis. It systematically analyzes the effects of different explanation loss designs and supervision strengths on both predictive accuracy and spatial faithfulness of explanations. New quantitative metrics (annotation coverage and saliency precision) are introduced to evaluate interpretability beyond qualitative saliency maps. Experiments on annotated chest X-ray datasets are reported to show a trade-off between explanation quality and loss coefficients, yet overall improved alignment with clinical annotations while maintaining comparable accuracy. The framework is presented as applicable to other annotated biomedical imaging modalities.
Significance. If the empirical claims hold, the work would supply practical guidance for training more trustworthy models in medical imaging by explicitly balancing accuracy against explanation alignment under noisy annotations. The introduction of complementary quantitative metrics for spatial faithfulness represents a constructive step beyond purely qualitative assessment of interpretability.
major comments (2)
- [Abstract] Abstract: the central claim that 'quantitative statistical analysis yields consistently improved explanation alignment while maintaining comparable accuracy' is asserted without any equations, training details, statistical tests, error bars, or result tables, rendering the claim unverifiable from the provided text and load-bearing for the paper's contribution.
- [Abstract] Abstract: the approach relies on the assumption that clinical annotations reliably indicate the features models should attend to, yet the text acknowledges 'noisy clinical annotations' without specifying how the explanation-loss balancing avoids introducing new unintended biases or how robustness to annotation noise was tested.
minor comments (1)
- [Abstract] Abstract: the metrics 'annotation coverage' and 'saliency precision' are named but receive no operational definitions or formulas, which would aid immediate understanding even in a high-level summary.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major comment point by point below, indicating whether revisions will be incorporated.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'quantitative statistical analysis yields consistently improved explanation alignment while maintaining comparable accuracy' is asserted without any equations, training details, statistical tests, error bars, or result tables, rendering the claim unverifiable from the provided text and load-bearing for the paper's contribution.
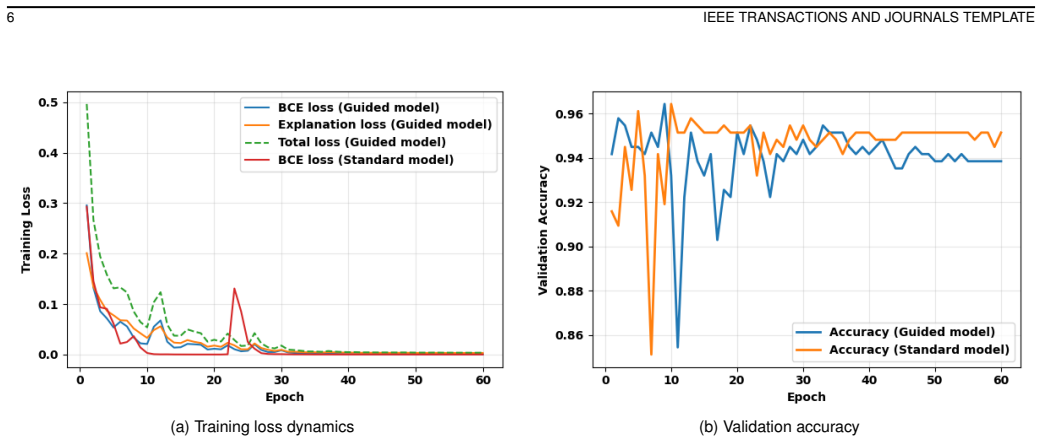
Authors: The abstract is intentionally concise and summarizes the primary findings. The full manuscript supplies all requested elements: the combined training objective and explanation loss terms are formalized in Equations (2) and (3) of Section 2; the complete training protocol, including optimizer settings and hyperparameter ranges, appears in Section 3.1; statistical significance is assessed via paired t-tests and Wilcoxon tests with reported p-values in Section 4.2; error bars are shown on all bar plots in Figures 3–5 and Tables 1–2; and full numerical results are tabulated in Section 4. Because the referee has access to the complete paper, the central claim is directly verifiable there. We will add one sentence to the abstract noting that improvements are statistically significant (p < 0.05). revision: partial
-
Referee: [Abstract] Abstract: the approach relies on the assumption that clinical annotations reliably indicate the features models should attend to, yet the text acknowledges 'noisy clinical annotations' without specifying how the explanation-loss balancing avoids introducing new unintended biases or how robustness to annotation noise was tested.
Authors: The abstract explicitly references guidance under noisy clinical annotations. The balancing mechanism is the scalar coefficient λ multiplying the explanation term; Section 4.1 reports a systematic sweep over λ values that identifies operating points where annotation alignment rises while classification accuracy remains statistically indistinguishable from the baseline. This sweep itself constitutes an empirical robustness check. In addition, the supplementary material contains a controlled noise-injection study in which Gaussian perturbations are added to the ground-truth masks; the proposed method continues to outperform the unsupervised baseline across moderate noise levels. We will expand the discussion section with a short paragraph that (i) acknowledges the risk of propagating annotation biases and (ii) summarizes the noise-robustness findings. revision: yes
Circularity Check
No circularity: empirical claims with no derivations or self-citations visible
full rationale
The abstract presents an empirical framework for incorporating explanation loss into training, introduces two new metrics (annotation coverage and saliency precision), and reports experimental outcomes on chest X-ray datasets. No equations, derivations, fitted parameters, or self-citations appear in the text. The central claims rest on quantitative results rather than any mathematical reduction or uniqueness theorem, so no step reduces to its inputs by construction. The work is therefore self-contained as a methods-and-results paper.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Ltotal = Lbce + α Lexp ... explanation loss formulations (logit-based and probability-based) ... annotation coverage and saliency precision
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
CheXNet: Radiologist-Level Pneumonia Detection on Chest X-Rays with Deep Learning
P. Rajpurkar, J. Irvin, K. Zhu, B. Yang, H. Mehta, T. Duan, D. Ding, A. Bagul, C. Langlotz, K. Shpanskayaet al., “Chexnet: Radiologist- level pneumonia detection on chest x-rays with deep learning,”arXiv preprint arXiv:1711.05225, 2017
work page Pith review arXiv 2017
-
[2]
A survey on deep learning in medical image analysis,
G. Litjens, T. Kooi, B. E. Bejnordi, A. A. A. Setio, F. Ciompi, M. Ghafoorian, J. A. van der Laak, B. van Ginneken, and C. I. S ´anchez, “A survey on deep learning in medical image analysis,”Medical Image Analysis, vol. 42, pp. 60–88, 2017
work page 2017
-
[3]
J. R. Zech, M. A. Badgeley, M. Liu, A. B. Costa, J. J. Titano, and E. K. Oermann, “Variable generalization performance of a deep learning model to detect pneumonia in chest radiographs,”PLOS Medicine, vol. 15, no. 11, p. e1002683, 2018
work page 2018
-
[4]
Deep learning predicts hip fracture using confounding patient and healthcare variables,
M. A. Badgeley, J. R. Zech, L. Oakden-Rayner, B. S. Glicksberg, M. Liu, W. Gale, M. V . McConnell, B. Percha, M. Snyder, and J. T. Dudley, “Deep learning predicts hip fracture using confounding patient and healthcare variables,”NPJ Digital Medicine, vol. 2, no. 1, p. 31, 2019
work page 2019
-
[5]
Key challenges for delivering clinical impact with artificial intelligence,
C. J. Kelly, A. Karthikesalingam, M. Suleyman, G. Corrado, and D. King, “Key challenges for delivering clinical impact with artificial intelligence,”BMC Medicine, vol. 17, no. 1, p. 195, 2019
work page 2019
-
[6]
What clinicians want: contextualizing explainable machine learning for clinical end use,
S. Tonekaboni, S. Joshi, M. D. McCradden, and A. Goldenberg, “What clinicians want: contextualizing explainable machine learning for clinical end use,”NPJ Digital Medicine, vol. 2, no. 1, p. 79, 2019
work page 2019
-
[7]
A survey of methods for explaining black box models,
R. Guidotti, A. Monreale, S. Ruggieri, F. Turini, D. Pedreschi, and F. Giannotti, “A survey of methods for explaining black box models,” IEEE Access, vol. 6, pp. 61 538–61 565, 2018
work page 2018
-
[8]
A survey on explainable artificial intelligence (xai): Toward medical xai,
E. Tjoa and C. Guan, “A survey on explainable artificial intelligence (xai): Toward medical xai,”IEEE Transactions on Neural Networks and Learning Systems, vol. 32, no. 11, pp. 4793–4813, 2021
work page 2021
-
[9]
Explainability of cnn based classification models for acoustic signal,
Z. Faruqui, M. S. McIntire, R. Dubey, and J. McEntee, “Explainability of cnn based classification models for acoustic signal,” 2025. [Online]. Available: https://arxiv.org/abs/2509.08717
-
[10]
Towards A Rigorous Science of Interpretable Machine Learning
F. Doshi-Velez and B. Kim, “Towards a rigorous science of interpretable machine learning,”arXiv preprint arXiv:1702.08608, 2017
work page internal anchor Pith review arXiv 2017
-
[11]
W. Samek, T. Wiegand, and K.-R. M ¨uller, “Explainable artificial in- telligence: Understanding, visualizing and interpreting deep learning models,”ITU Journal: ICT Discoveries, vol. 1, no. 1, 2019
work page 2019
-
[12]
Grad-cam: Visual explanations from deep networks via gradient-based localization,
R. R. Selvarajuet al., “Grad-cam: Visual explanations from deep networks via gradient-based localization,” inProceedings of the IEEE International Conference on Computer Vision, 2017
work page 2017
-
[13]
Benchmarking saliency methods for chest x-ray interpretation,
A. Saportaet al., “Benchmarking saliency methods for chest x-ray interpretation,”Nature Machine Intelligence, vol. 4, pp. 269–281, 2022
work page 2022
-
[14]
Explanation-guided training for cross-domain few-shot classification,
J. Sunet al., “Explanation-guided training for cross-domain few-shot classification,” inProceedings of ICPR, 2020
work page 2020
-
[15]
Expert-guided explain- able few-shot learning for medical image diagnosis,
I. I. Uddin, L. Wang, and K. Santosh, “Expert-guided explain- able few-shot learning for medical image diagnosis,”arXiv preprint arXiv:2509.08007, 2025
-
[16]
Interpretations are useful: penalizing explanations to align neural networks with prior knowledge,
L. Rieger, C. Singh, W. J. Murdoch, and B. Yu, “Interpretations are useful: penalizing explanations to align neural networks with prior knowledge,” 2020. [Online]. Available: https://arxiv.org/abs/1909.13584
-
[17]
Right for the right rea- sons: Training differentiable models by constraining their explanations,
A. S. Ross, M. C. Hughes, and F. Doshi-Velez, “Right for the right rea- sons: Training differentiable models by constraining their explanations,” inProceedings of IJCAI, 2017
work page 2017
-
[18]
Vindr-cxr: An open dataset of chest x-rays with radiologist annotations,
H. T. Nguyen, H. T. Pham, T. T. Le, H. Q. Nguyen, M. T. Vu et al., “Vindr-cxr: An open dataset of chest x-rays with radiologist annotations,”Scientific Data, vol. 9, no. 1, p. 429, 2022
work page 2022
-
[19]
H. W. Loh, C. P. Ooi, S. Seoni, P. D. Barua, F. Molinari, and U. R. Acharya, “Application of explainable artificial intelligence for health- care: A systematic review of the last decade (2011–2022),”Computer Methods and Programs in Biomedicine, vol. 226, p. 107161, 2022
work page 2011
-
[20]
H. Panwar, P. K. Gupta, M. K. Siddiqui, R. Morales-Menendez, and P. Bhardwaj, “A deep learning and grad-cam based color visualization approach for fast detection of covid-19 cases using chest x-ray and ct- scan images,”International Journal of Imaging Systems and Technology, 2020
work page 2020
-
[21]
Detection of covid-19 using transfer learning and grad-cam visualizations on chest x-ray images,
M. Umairet al., “Detection of covid-19 using transfer learning and grad-cam visualizations on chest x-ray images,”Sensors, vol. 21, no. 17, 2021
work page 2021
-
[22]
Explainable deep learning in medical imaging: brain tumor and pneumonia detection,
S. T. Erukude, V . C. Marella, and S. R. Veluru, “Explainable deep learning in medical imaging: brain tumor and pneumonia detection,” arXiv preprint arXiv:2510.21823, 2025. 10 IEEE TRANSACTIONS AND JOURNALS TEMPLATE
-
[23]
M. T. Ribeiro, S. Singh, and C. Guestrin, ““why should i trust you?”: Explaining the predictions of any classifier,” inProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2016, pp. 1135–1144
work page 2016
-
[24]
A unified approach to interpreting model predictions,
S. M. Lundberg and S.-I. Lee, “A unified approach to interpreting model predictions,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 30, 2017
work page 2017
-
[25]
Unmasking clever hans predictors and assessing what machines really learn,
S. Lapuschkin, S. W ¨aldchen, A. Binder, G. Montavon, W. Samek, and K.-R. M ¨uller, “Unmasking clever hans predictors and assessing what machines really learn,”Pattern Recognition, vol. 87, pp. 1–15, 2019
work page 2019
-
[26]
The (un)reliability of saliency methods,
P.-J. Kindermans, S. Hooker, J. Adebayo, M. Alber, K. T. Sch ¨utt, S. D ¨ahne, D. Erhan, and B. Kim, “The (un)reliability of saliency methods,” inExplainable AI: Interpreting, Explaining and Visualizing Deep Learning. Springer, 2019, pp. 267–280
work page 2019
-
[27]
Sanity checks for saliency maps,
J. Adebayoet al., “Sanity checks for saliency maps,” inAdvances in Neural Information Processing Systems, 2018
work page 2018
-
[28]
Explaining decisions of convolutional neural networks for brain tumor classification,
M. ˇSefˇc´ık, W. Samek, S. Lapuschkin, A. Binder, and K.-R. M ¨uller, “Explaining decisions of convolutional neural networks for brain tumor classification,”Pattern Recognition, vol. 112, p. 107797, 2021
work page 2021
-
[29]
Doctor-in-the- loop: Human-in-the-loop framework for clinical decision support using deep learning,
A. Caragliano, A. Bhandari, V . Lakshminarayananet al., “Doctor-in-the- loop: Human-in-the-loop framework for clinical decision support using deep learning,”IEEE Transactions on Medical Imaging, vol. 40, no. 5, pp. 1328–1340, 2021
work page 2021
-
[30]
Benchmarking saliency methods for chest x-ray interpretation,
A. Saportaet al., “Benchmarking saliency methods for chest x-ray interpretation,”Nature Machine Intelligence, 2022
work page 2022
-
[31]
Thoracic disease identification and localization with limited supervision,
Z. Liet al., “Thoracic disease identification and localization with limited supervision,” inProceedings of CVPR, 2018
work page 2018
-
[32]
Densely connected convolutional networks,
G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger, “Densely connected convolutional networks,” inProceedings of the IEEE Confer- ence on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 4700–4708
work page 2017
-
[33]
S. Rajaraman, S. Antani, S. Candemir, Z. Xue, and G. R. Thoma, “Impact of transfer learning strategies on the generalization of deep learning models for chest radiograph classification,”PLOS Digital Health, vol. 3, no. 1, p. e0000418, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.