Recognition: 2 theorem links
· Lean TheoremMFVLR: Multi-domain Fine-grained Vision-Language Reconstruction for Generalizable Diffusion Face Forgery Detection and Localization
Pith reviewed 2026-05-12 04:25 UTC · model grok-4.3
The pith
A vision-language reconstruction model learns multi-domain forgery traces to detect and localize diffusion-synthesized faces in unseen generators and datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MFVLR explores comprehensive visual forgery traces via language-guided face forgery representation learning to achieve generalizable diffusion-synthesized face forgery detection and localization. A fine-grained language transformer learns general language embeddings through reconstruction. A multi-domain vision encoder captures complementary patterns across image and residual domains. A vision decoder reconstructs appearance and localizes forgeries, while a vision injection module strengthens vision-language interaction.
What carries the argument
The MFVLR architecture, which couples language reconstruction for fine-grained embeddings with a multi-domain visual encoder and decoder plus a vision injection module to link modalities.
If this is right
- Detection and localization performance improves on diffusion faces produced by generators absent from training.
- The same model handles multiple forgery types and datasets without domain-specific retraining.
- Reconstruction of both appearance and language embeddings provides explicit localization maps in addition to classification scores.
- The plug-and-play injection module can be added to other vision-language pipelines for forgery analysis.
Where Pith is reading between the lines
- The method could be tested on video forgeries by extending the reconstruction to temporal sequences.
- If the language component proves critical, similar reconstruction objectives might help other multi-modal forensic tasks such as audio-visual deepfake detection.
- The residual-domain encoder suggests that explicit high-frequency analysis remains useful even when language guidance is added.
Load-bearing premise
Language-guided reconstruction of fine-grained embeddings combined with multi-domain visual encoders will capture forgery traces that transfer to unseen diffusion generators and datasets.
What would settle it
Evaluation on a newly released diffusion face dataset or generator never seen during training, measuring whether detection accuracy and localization IoU remain higher than strong image-only baselines.
Figures









read the original abstract
The swift advancement in photo-realistic face generation technology has sparked considerable concerns across society and academia, emphasizing the requirement of generalizable face forgery detection and localization methods. Prior works tend to capture face forgery patterns across multiple domains using image modality, other modalities like fine-grained texts are not comprehensively investigated, which restricts the generalization capability of models. Besides, they usually analyze facial images created by GAN, but struggle to identify and localize those synthesized by diffusion. To solve the problems, in this paper, we devise a novel multi-domain fine-grained vision-language reconstruction (MFVLR) model, which explores comprehensive and diverse visual forgery traces via language-guided face forgery representation learning, to achieve generalizable diffusion-synthesized face forgery detection and localization (DFFDL). Specifically, we devise a fine-grained language transformer that studies general fine-grained language embeddings using language reconstruction. We propose a multi-domain vision encoder to capture general and complementary visual forgery patterns across the image and residual domains. A vision decoder is designed to reconstruct image appearance and achieve forgery localization. Besides, we propose an innovative plug-and-play vision injection module to enhance the interaction between the vision and language embeddings. Extensive experiments and visualizations demonstrate that our network outperforms the state of the art on different settings like cross-generator, cross-forgery, and cross-dataset evaluations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the MFVLR model for generalizable diffusion face forgery detection and localization (DFFDL). It introduces a fine-grained language transformer that learns embeddings via language reconstruction, a multi-domain vision encoder operating on image and residual domains to capture complementary forgery patterns, a vision decoder for appearance reconstruction and forgery localization, and a plug-and-play vision injection module to fuse vision and language embeddings. The central claim is that this architecture yields forgery traces that generalize better than prior image-only methods, with extensive experiments showing outperformance on cross-generator, cross-forgery, and cross-dataset evaluations.
Significance. If the empirical claims are substantiated, the work would be significant for media forensics by extending forgery detection to diffusion-based generators, which current methods handle poorly. Incorporating language-guided fine-grained reconstruction alongside multi-domain visuals offers a multimodal route to improved generalization, addressing a growing practical need as diffusion models proliferate.
major comments (2)
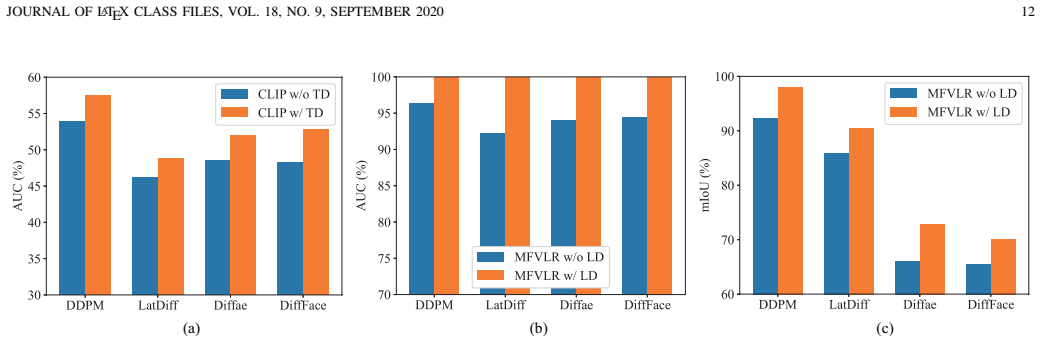
- Abstract: the claim that the network 'outperforms the state of the art on different settings like cross-generator, cross-forgery, and cross-dataset evaluations' is presented without any quantitative metrics, baseline comparisons, ablation results, or error bars, which is load-bearing for the central generalization argument that language-guided reconstruction adds transferable diffusion-specific traces beyond the multi-domain visual encoder alone.
- Method section (vision injection module and fine-grained language transformer): the description of how fine-grained language embeddings are sourced, supervised for forgery cues, or guaranteed to be complementary rather than redundant with residual-domain visuals is high-level only; without ablations isolating their contribution on cross-generator splits or equations detailing the injection mechanism, the assumption that this yields generalizable signals remains unverified.
minor comments (2)
- Abstract: the acronym DFFDL is used without an initial definition.
- The motivation for choosing language reconstruction over other multimodal fusion strategies is not contrasted with prior vision-language work in forgery detection.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to strengthen the presentation of our results and methods.
read point-by-point responses
-
Referee: Abstract: the claim that the network 'outperforms the state of the art on different settings like cross-generator, cross-forgery, and cross-dataset evaluations' is presented without any quantitative metrics, baseline comparisons, ablation results, or error bars, which is load-bearing for the central generalization argument that language-guided reconstruction adds transferable diffusion-specific traces beyond the multi-domain visual encoder alone.
Authors: We agree that the abstract would benefit from quantitative support for the generalization claims. In the revised manuscript, we will add key performance metrics (e.g., AUC improvements on cross-generator and cross-dataset splits) and direct comparisons to the strongest baselines, while keeping the abstract concise. The full ablations, error bars, and per-setting breakdowns are already reported in the Experiments section; we will ensure the abstract now explicitly references the most critical numbers supporting the added value of language-guided reconstruction. revision: yes
-
Referee: Method section (vision injection module and fine-grained language transformer): the description of how fine-grained language embeddings are sourced, supervised for forgery cues, or guaranteed to be complementary rather than redundant with residual-domain visuals is high-level only; without ablations isolating their contribution on cross-generator splits or equations detailing the injection mechanism, the assumption that this yields generalizable signals remains unverified.
Authors: We acknowledge that the current method description is high-level. In the revision we will (1) insert explicit equations for the vision injection module showing the fusion of language and vision embeddings, (2) clarify that fine-grained language embeddings are derived from attribute-level text prompts and supervised by the language reconstruction objective, which targets forgery cues, and (3) add targeted ablations on cross-generator splits that isolate the language transformer and injection module from the multi-domain visual encoder, quantifying their complementary contribution. These additions will make the generalizability argument verifiable from the text. revision: yes
Circularity Check
No circularity: architectural proposal with experimental validation
full rationale
The paper introduces the MFVLR model as an architectural design comprising a fine-grained language transformer for language reconstruction, a multi-domain vision encoder for image and residual domains, a vision decoder for reconstruction and localization, and a vision injection module. No derivation chain, equations, or first-principles predictions are presented that reduce to inputs by construction. Claims of generalization rely on cross-generator, cross-forgery, and cross-dataset experiments rather than any fitted parameters renamed as predictions or self-referential logic. No load-bearing self-citations, uniqueness theorems, or smuggled ansatzes appear in the text. The work is self-contained as an empirical multimodal proposal.
Axiom & Free-Parameter Ledger
free parameters (1)
- model hyperparameters and training settings
axioms (2)
- domain assumption Transformer-based reconstruction losses effectively learn generalizable forgery representations from language and vision inputs
- domain assumption Multi-domain training on image and residual domains yields complementary patterns that generalize across generators
invented entities (1)
-
vision injection module
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We devise a fine-grained language transformer that studies general fine-grained language embeddings using language reconstruction... multi-domain vision encoder... vision injection module
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Appearance reconstruction loss... Language reconstruction loss... Cross-modal contrastive loss
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Xception: Deep learning with depthwise separable convolu- tions,
F. Chollet, “Xception: Deep learning with depthwise separable convolu- tions,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 1800–1807
work page 2017
-
[2]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778. JOURNAL OF LATEX CLASS FILES, VOL. 18, NO. 9, SEPTEMBER 2020 17
work page 2016
-
[3]
Multimodal learning with transform- ers: A survey,
P. Xu, X. Zhu, and D. A. Clifton, “Multimodal learning with transform- ers: A survey,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 10, pp. 12 113–12 132, 2023
work page 2023
-
[4]
A survey on vision transformer,
K. Han, Y . Wang, H. Chen, X. Chen, J. Guo, Z. Liu, Y . Tang, A. Xiao, C. Xu, Y . Xu, Z. Yang, Y . Zhang, and D. Tao, “A survey on vision transformer,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 1, pp. 87–110, 2023
work page 2023
-
[5]
Distilled transformers with locally enhanced global representations for face forgery detection,
Y . Zhang, Q. Li, Z. Yu, and L. Shen, “Distilled transformers with locally enhanced global representations for face forgery detection,”Pattern Recognition, vol. 161, p. 111253, 2025
work page 2025
-
[6]
A robust lightweight deepfake detection network using transformers,
Y . Zhang, T. Wang, M. Shu, and Y . Wang, “A robust lightweight deepfake detection network using transformers,” inPRICAI 2022: Trends in Artificial Intelligence, Cham, 2022, pp. 275–288
work page 2022
-
[7]
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative Adversarial Nets,” inProceedings of the Neural Information Processing Systems (NIPS), 2014, pp. 2672–2680
work page 2014
-
[8]
Alias-free generative adversarial networks,
T. Karras, M. Aittala, S. Laine, E. H ¨ark¨onen, J. Hellsten, J. Lehtinen, and T. Aila, “Alias-free generative adversarial networks,” inProceedings of the Neural Information Processing Systems (NIPS), 2021
work page 2021
-
[9]
Analyzing and improving the image quality of stylegan,
T. Karras, S. Laine, M. Aittala, J. Hellsten, J. Lehtinen, and T. Aila, “Analyzing and improving the image quality of stylegan,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 8107–8116
work page 2020
-
[10]
Denoising Diffusion Probabilistic Models
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” arXiv preprint arXiv:2006.11239, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[11]
Deepfake detection: A comprehensive survey from the reliability perspective,
T. Wang, X. Liao, K. P. Chow, X. Lin, and Y . Wang, “Deepfake detection: A comprehensive survey from the reliability perspective,” ACM Comput. Surv., Oct. 2024
work page 2024
-
[12]
Detect Any Deepfakes: Segment anything meets face forgery detection and localization,
Y . Lai, Z. Luo, and Z. Yu, “Detect Any Deepfakes: Segment anything meets face forgery detection and localization,” inBiometric Recognition, W. Jia, W. Kang, Z. Pan, X. Ben, Z. Bian, S. Yu, Z. He, and J. Wang, Eds. Singapore: Springer Nature Singapore, 2023, pp. 180–190
work page 2023
-
[13]
On the detection of digital face manipulation,
H. Dang, F. Liu, J. Stehouwer, X. Liu, and A. K. Jain, “On the detection of digital face manipulation,” inProceedings of the IEEE Conference on Computer Vision and Pattern recognition (CVPR), 2020, pp. 5781–5790
work page 2020
-
[14]
M2TR: Multi-modal multi-scale transformers for deepfake detection,
J. Wang, Z. Wu, W. Ouyang, X. Han, J. Chen, Y .-G. Jiang, and S.-N. Li, “M2TR: Multi-modal multi-scale transformers for deepfake detection,” inProceedings of the International Conference on Multimedia Retrieval (ICMR), 2022, p. 615–623
work page 2022
-
[15]
Multi-spectral Class Center Network for face ma- nipulation detection and localization,
C. Miao, Q. Chu, Z. Tan, Z. Jin, T. Gong, W. Zhuang, Y . Wu, B. Liu, H. Hu, and N. Yu, “Multi-spectral Class Center Network for face ma- nipulation detection and localization,”arXiv preprint arXiv:2305.10794, 2024
-
[16]
Hierarchical fine-grained image forgery detection and localization,
X. Guo, X. Liu, Z. Ren, S. Grosz, I. Masi, and X. Liu, “Hierarchical fine-grained image forgery detection and localization,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 3155–3165
work page 2023
-
[17]
Leveraging frequency analysis for deep fake image recog- nition,
J. Frank, T. Eisenhofer, L. Sch ¨onherr, A. Fischer, D. Kolossa, and T. Holz, “Leveraging frequency analysis for deep fake image recog- nition,” inProceedings of the International Conference on Machine Learning (ICML), 2020
work page 2020
-
[18]
R. Durall, M. Keuper, and J. Keuper, “Watch your up-convolution: Cnn based generative deep neural networks are failing to reproduce spectral distributions,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), jun 2020, pp. 7887–7896
work page 2020
-
[19]
K. Sun, S. Chen, T. Yao, H. Yang, X. Sun, S. Ding, and R. Ji, “Towards general visual-linguistic face forgery detection,”arXiv preprint arXiv:2402.01123, 2024
-
[20]
Common sense reasoning for deep fake detection,
Y . Zhang, B. Colman, A. Shahriyari, and G. Bharaj, “Common sense reasoning for deep fake detection,”arXiv preprint arXiv:2402.00126, 2024
-
[21]
MFCLIP: Multi-modal fine-grained clip for generalizable diffusion face forgery detection,
Y . Zhang, T. Wang, Z. Yu, Z. Gao, L. Shen, and S. Chen, “MFCLIP: Multi-modal fine-grained clip for generalizable diffusion face forgery detection,”arXiv preprint arXiv:2409.09724, 2024
-
[22]
Deepfake video detection using convolutional vision transformer,
D. Wodajo and S. Atnafu, “Deepfake video detection using convolutional vision transformer,” 2021, arXiv preprint arXiv:2102.11126
-
[23]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,” inProceedings of the International Conference on Learning Representations (ICLR), Austria, 2021
work page 2021
-
[24]
Face forgery detection by 3d decomposition and composition search,
X. Zhu, H. Fei, B. Zhang, T. Zhang, X. Zhang, S. Z. Li, and Z. Lei, “Face forgery detection by 3d decomposition and composition search,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 7, pp. 8342–8357, 2023
work page 2023
-
[25]
Fully unsupervised deepfake video detection via enhanced contrastive learning,
T. Qiao, S. Xie, Y . Chen, F. Retraint, and X. Luo, “Fully unsupervised deepfake video detection via enhanced contrastive learning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 7, pp. 4654–4668, 2024
work page 2024
-
[26]
DIRE for diffusion-generated image detection,
Z. Wang, J. Bao, W. Zhou, W. Wang, H. Hu, H. Chen, and H. Li, “DIRE for diffusion-generated image detection,” inProceedings of the IEEE International Conference on Computer Vision (ICCV), 2023, pp. 22 388–22 398
work page 2023
-
[27]
C. Tan, Y . Zhao, S. Wei, G. Gu, P. Liu, and Y . Wei, “Frequency-aware deepfake detection: Improving generalizability through frequency space domain learning,” inProceedings of the AAAI Conference on Artificial Intelligence (AAAI), vol. 38, no. 5, 2024, pp. 5052–5060
work page 2024
-
[28]
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo, P. Dollar, and R. Gir- shick, “Segment Anything,” inProceedings of the IEEE International Conference on Computer Vision (ICCV), October 2023, pp. 4015–4026
work page 2023
-
[29]
Z. Huang, J. Hu, X. Li, Y . He, X. Zhao, B. Peng, B. Wu, X. Huang, and G. Cheng, “Sida: Social media image deepfake detection, localization and explanation with large multimodal model,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 28 831– 28 841
work page 2025
-
[30]
Diffforensics: Leveraging diffusion prior to image forgery detection and localization,
Z. Yu, J. Ni, Y . Lin, H. Deng, and B. Li, “Diffforensics: Leveraging diffusion prior to image forgery detection and localization,” in2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 12 765–12 774
work page 2024
-
[31]
Vision-language models for vision tasks: A survey,
J. Zhang, J. Huang, S. Jin, and S. Lu, “Vision-language models for vision tasks: A survey,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 8, pp. 5625–5644, 2024
work page 2024
-
[32]
On evaluating adversarial robustness of large vision-language models,
Y . Zhao, T. Pang, C. Du, X. Yang, C. Li, N.-M. M. Cheung, and M. Lin, “On evaluating adversarial robustness of large vision-language models,” inProceedings of the Advances in Neural Information Processing Systems (NIPS), vol. 36, 2024
work page 2024
-
[33]
Task residual for tuning vision-language models,
T. Yu, Z. Lu, X. Jin, Z. Chen, and X. Wang, “Task residual for tuning vision-language models,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 10 899– 10 909
work page 2023
-
[34]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inProceedings of the International Conference on Machine Learning (ICML). PMLR, 2021, pp. 8748–8763
work page 2021
-
[35]
Learning to prompt for vision- language models,
K. Zhou, J. Yang, C. C. Loy, and Z. Liu, “Learning to prompt for vision- language models,”International Journal of Computer Vision, vol. 130, no. 9, pp. 2337–2348, 2022
work page 2022
-
[36]
SoftClip: Softer cross-modal alignment makes clip stronger,
Y . Gao, J. Liu, Z. Xu, T. Wu, E. Zhang, K. Li, J. Yang, W. Liu, and X. Sun, “SoftClip: Softer cross-modal alignment makes clip stronger,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 3, 2024, pp. 1860–1868
work page 2024
-
[37]
CFPL-FAS: Class free prompt learning for generalizable face anti-spoofing,
A. Liu, S. Xue, J. Gan, J. Wan, Y . Liang, J. Deng, S. Escalera, and Z. Lei, “CFPL-FAS: Class free prompt learning for generalizable face anti-spoofing,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 222–232
work page 2024
-
[38]
C2p-clip: Injecting category common prompt in clip to enhance generalization in deepfake detection,
C. Tan, R. Tao, H. Liu, G. Gu, B. Wu, Y . Zhao, and Y . Wei, “C2p-clip: Injecting category common prompt in clip to enhance generalization in deepfake detection,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 7, 2025, pp. 7184–7192
work page 2025
-
[39]
Visual Grounding Via Accumulated Attention ,
C. Deng, Q. Wu, Q. Wu, F. Hu, F. Lyu, and M. Tan, “ Visual Grounding Via Accumulated Attention ,”IEEE Transactions on Pattern Analysis & Machine Intelligence, vol. 44, no. 03, pp. 1670–1684, Mar. 2022
work page 2022
-
[40]
On learning multi-modal forgery representation for diffusion generated video detection,
X. Song, X. Guo, J. Zhang, Q. Li, L. Bai, X. Liu, G. Zhai, and X. Liu, “On learning multi-modal forgery representation for diffusion generated video detection,”Advances in Neural Information Processing Systems, vol. 37, pp. 122 054–122 077, 2024
work page 2024
-
[41]
Rethinking vision- language model in face forensics: Multi-modal interpretable forged face detector,
X. Guo, X. Song, Y . Zhang, X. Liu, and X. Liu, “Rethinking vision- language model in face forensics: Multi-modal interpretable forged face detector,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 105–116
work page 2025
-
[42]
GenFace: A large-scale fine-grained face forgery benchmark and cross appearance-edge learning,
Y . Zhang, Z. Yu, T. Wang, X. Huang, L. Shen, Z. Gao, and J. Ren, “GenFace: A large-scale fine-grained face forgery benchmark and cross appearance-edge learning,”IEEE Transactions on Information Forensics and Security, vol. 19, pp. 8559–8572, 2024
work page 2024
-
[43]
Generalizing face forgery detection with high-frequency features,
Y . Luo, Y . Zhang, J. Yan, and W. Liu, “Generalizing face forgery detection with high-frequency features,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 16 312–16 321
work page 2021
-
[44]
U-Net: Convolutional net- works for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-Net: Convolutional net- works for biomedical image segmentation,” inMedical Image Comput- JOURNAL OF LATEX CLASS FILES, VOL. 18, NO. 9, SEPTEMBER 2020 18 ing and Computer-Assisted Intervention (MICCAI), N. Navab, J. Horneg- ger, W. M. Wells, and A. F. Frangi, Eds. Cham: Springer International Publishing, 2015, p...
work page 2020
-
[45]
Forgery-aware adaptive transformer for generalizable synthetic image detection,
H. Liu, Z. Tan, C. Tan, Y . Wei, J. Wang, and Y . Zhao, “Forgery-aware adaptive transformer for generalizable synthetic image detection,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2024, pp. 10 770–10 780
work page 2024
-
[46]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion(CVPR), 2022, pp. 10 684–10 695
work page 2022
-
[47]
Collaborative diffusion for multi-modal face generation and editing,
Z. Huang, K. C. Chan, Y . Jiang, and Z. Liu, “Collaborative diffusion for multi-modal face generation and editing,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 6080–6090
work page 2023
-
[48]
Diffusion Autoencoders: Toward a meaningful and decodable repre- sentation,
K. Preechakul, N. Chatthee, S. Wizadwongsa, and S. Suwajanakorn, “Diffusion Autoencoders: Toward a meaningful and decodable repre- sentation,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022
work page 2022
-
[49]
A latent transformer for disentangled face editing in images and videos,
X. Yao, A. Newson, Y . Gousseau, and P. Hellier, “A latent transformer for disentangled face editing in images and videos,” inProceedings of the IEEE International Conference on Computer Vision (ICCV), 2021, pp. 13 769–13 778
work page 2021
-
[50]
Ia-FaceS: A bidirectional method for semantic face editing,
W. Huang, S. Tu, and L. Xu, “Ia-FaceS: A bidirectional method for semantic face editing,”Neural Networks, vol. 158, pp. 272–292, 2023
work page 2023
-
[51]
High-resolution face swapping via latent semantics disentanglement,
Y . Xu, B. Deng, J. Wang, Y . Jing, J. Pan, and S. He, “High-resolution face swapping via latent semantics disentanglement,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 7632–7641
work page 2022
-
[52]
Learning disentangled rep- resentation for one-shot progressive face swapping,
Q. Li, W. Wang, C. Xu, and Z. Sun, “Learning disentangled rep- resentation for one-shot progressive face swapping,”arXiv preprint arXiv:2203.12985, 2022
-
[53]
FaceForensics++: Learning to detect manipulated facial images,
A. R ¨ossler, D. Cozzolino, L. Verdoliva, C. Riess, J. Thies, and M. Niess- ner, “FaceForensics++: Learning to detect manipulated facial images,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2019, pp. 1–11
work page 2019
-
[54]
The DeepFake Detection Challenge (DFDC) Dataset
B. Dolhansky, J. Bitton, B. Pflaum, J. Lu, R. Howes, M. Wang, and C. Canton-Ferrer, “The deepfake detection challenge dataset,”arXiv preprint arXiv:2006.07397, 2020
work page internal anchor Pith review arXiv 2006
-
[55]
Celeb-DF: A large-scale challenging dataset for deepfake forensics,
Y . Li, X. Yang, P. Sun, H. Qi, and S. Lyu, “Celeb-DF: A large-scale challenging dataset for deepfake forensics,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2020, pp. 3204–3213
work page 2020
-
[56]
DeeperForensics-1.0: A large-scale dataset for real-world face forgery detection,
L. Jiang, R. Li, W. Wu, C. Qian, and C. C. Loy, “DeeperForensics-1.0: A large-scale dataset for real-world face forgery detection,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2020, pp. 2886–2895
work page 2020
-
[57]
End-to- end reconstruction-classification learning for face forgery detection,
J. Cao, C. Ma, T. Yao, S. Chen, S. Ding, and X. Yang, “End-to- end reconstruction-classification learning for face forgery detection,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 4113–4122
work page 2022
-
[58]
Combining efficientnet and vision transformers for video deepfake detection,
D. A. Coccomini, N. Messina, C. Gennaro, and F. Falchi, “Combining efficientnet and vision transformers for video deepfake detection,” in Proceedings of the International Conference on Image Analysis and Processing (IAP). Springer, 2022, pp. 219–229
work page 2022
-
[59]
Learning to discover forgery cues for face forgery detection,
J. Tian, P. Chen, C. Yu, X. Fu, X. Wang, J. Dai, and J. Han, “Learning to discover forgery cues for face forgery detection,”IEEE Transactions on Information Forensics and Security, vol. 19, pp. 3814–3828, 2024
work page 2024
-
[60]
W. Zhuang, Q. Chu, Z. Tan, Q. Liu, H. Yuan, C. Miao, Z. Luo, and N. Yu, “UIA-ViT: Unsupervised inconsistency-aware method based on vision transformer for face forgery detection,” inProceedings of the European Conference on Computer Vision (ECCV). Springer, 2022, pp. 391–407
work page 2022
-
[61]
Uncertainty-aware hierarchical labeling for face forgery detection,
B. Yu, W. Li, X. Li, J. Zhou, and J. Lu, “Uncertainty-aware hierarchical labeling for face forgery detection,”Pattern Recognition, vol. 153, p. 110526, 2024
work page 2024
-
[62]
Improving generalization of deepfake detectors by imposing gradient regularization,
W. Guan, W. Wang, J. Dong, and B. Peng, “Improving generalization of deepfake detectors by imposing gradient regularization,”IEEE Trans- actions on Information Forensics and Security, vol. 19, pp. 5345–5356, 2024. Yaning Zhangreceived the double bachelor’s de- gree in Internet of Things Engineering and English and the M.S. degree in Computer Applied Techn...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.