Recognition: 2 theorem links
· Lean TheoremInitiation of Interaction Detection Framework using a Nonverbal Cue for Human-Robot Interaction
Pith reviewed 2026-05-12 03:56 UTC · model grok-4.3
The pith
A robot detects when a human intends to interact by fusing sound localization with face direction or sustained gaze.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
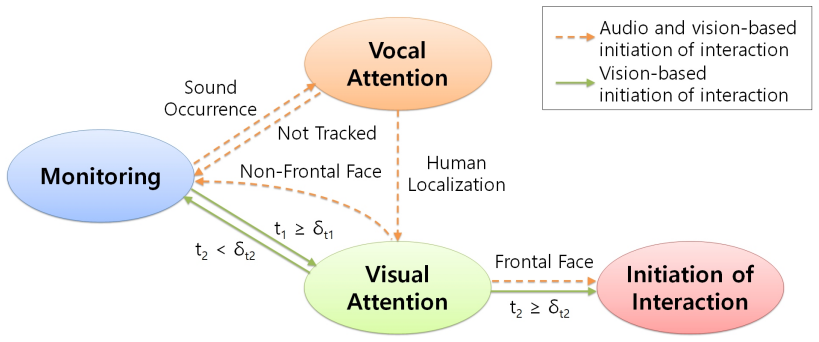
Initiation of interaction is detected when sound source localization and human tracking place a speaker whose face is directed at the robot, or when gaze duration alone exceeds a predefined threshold, all without requiring verbal cues.
What carries the argument
The state transition model that fuses sound source localization, human tracking data, and face orientation checks to move between idle and interaction-ready states.
If this is right
- Robots can begin responding to users who speak while facing them without needing a wake-word trigger.
- Prolonged gaze alone becomes sufficient to start interaction when the user remains silent.
- The ROS implementation allows the same detection logic to run on any mobile robot equipped with basic audio and camera sensors.
- Sensor fusion reduces reliance on either audio or vision alone, improving robustness in variable home environments.
Where Pith is reading between the lines
- The method could lower unwanted activations compared with always-listening voice systems in noisy households.
- Adding body posture or hand gestures as extra inputs might further reduce false positives from accidental stares.
- Similar fusion logic could apply to other service robots that must decide when to approach a person without explicit commands.
Load-bearing premise
A fixed gaze-duration threshold reliably signals interaction intent rather than casual glances, and audio-visual fusion remains accurate in typical domestic lighting and sound conditions.
What would settle it
A test recording many brief, non-intentional looks at the robot that trigger false detections, or a trial showing sound localization errors in rooms with echoes and background noise.
Figures



read the original abstract
This paper describes an initiation of interaction(IoI) detection framework without keywords for human-robot interaction(HRI) based on audio and vision sensor fusion in a domestic environment. In the proposed framework, the robot has its own audio and vision sensors, and can employ external vision sensor for stable human detection and tracking. When the user starts to speak while looking at the robot, the robot can localize his or her position by its sound source localization together with human tracking information. Then the robot can detect the IoI if it perceives the face of the speaker faces the robot. In case that the user does not speak directly, the robot can also detect the IoI if he or she looks at the robot for more than predefined periods of time. A state transition model for the proposed IoI detection framework is designed and verified by experiments with a mobile robot. In order to implement and associate our model in a robot architecture, all the components are implemented and integrated in the Robot Operating System(ROS) environment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a framework for detecting initiation of interaction (IoI) in human-robot interaction using nonverbal cues via audio-visual sensor fusion in domestic settings. When a user speaks while facing the robot, sound source localization combined with human tracking identifies the position, followed by face orientation check; alternatively, IoI is detected via gaze duration exceeding a fixed threshold when no speech occurs. A state-transition model is implemented in ROS on a mobile robot and asserted to be verified by experiments.
Significance. If the framework were shown to achieve reliable detection with quantified low false-positive rates under realistic conditions, it would offer a practical, keyword-free approach to natural HRI that integrates onboard and external sensors. The ROS implementation and use of existing tracking components are positive engineering contributions, but the absence of performance metrics currently confines the work to a high-level description rather than a validated advance.
major comments (3)
- [Abstract] Abstract: the assertion that the state transition model 'is designed and verified by experiments with a mobile robot' is unsupported by any quantitative results (accuracy, precision/recall, false-positive rates), error analysis, or description of how false positives were measured. This directly undermines evaluation of the central IoI claim, which hinges on the gaze-duration threshold and sensor fusion.
- [Framework description] Framework description (gaze-based path): the 'predefined periods of time' threshold for detecting IoI from gaze alone is introduced without a numerical value, justification, or analysis of its effect on false positives from casual looks. Because this parameter is load-bearing for the non-speech case and listed as a free parameter, its omission prevents assessment of robustness.
- [Implementation and experiments] Sensor fusion and experimental setup: no details are supplied on how audio localization is combined with visual tracking, how external vision sensors are integrated, or on test conditions (lighting variation, background noise levels, number of trials). Without these, the claim of reliable operation in domestic environments cannot be evaluated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our IoI detection framework. The comments highlight important areas for strengthening the evaluation and clarity of the manuscript. We address each major comment below and will revise the paper to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the state transition model 'is designed and verified by experiments with a mobile robot' is unsupported by any quantitative results (accuracy, precision/recall, false-positive rates), error analysis, or description of how false positives were measured. This directly undermines evaluation of the central IoI claim, which hinges on the gaze-duration threshold and sensor fusion.
Authors: We agree that quantitative performance metrics are needed to substantiate the verification claim in the abstract and experiments section. The current manuscript describes the ROS implementation and qualitative observations from mobile robot trials, but lacks explicit metrics. In the revision, we will add accuracy, precision, recall, and false-positive rates derived from the conducted experiments, along with an error analysis and details on how false positives were identified and measured across speech and non-speech scenarios. The abstract will be updated to reflect these additions. revision: yes
-
Referee: [Framework description] Framework description (gaze-based path): the 'predefined periods of time' threshold for detecting IoI from gaze alone is introduced without a numerical value, justification, or analysis of its effect on false positives from casual looks. Because this parameter is load-bearing for the non-speech case and listed as a free parameter, its omission prevents assessment of robustness.
Authors: The gaze-duration threshold is indeed a critical parameter for the non-speech IoI path. We will revise the framework description to specify the exact numerical value employed in our implementation, provide justification drawn from our preliminary calibration tests, and include an analysis of its influence on false positives arising from casual glances. This will improve the assessment of the framework's robustness. revision: yes
-
Referee: [Implementation and experiments] Sensor fusion and experimental setup: no details are supplied on how audio localization is combined with visual tracking, how external vision sensors are integrated, or on test conditions (lighting variation, background noise levels, number of trials). Without these, the claim of reliable operation in domestic environments cannot be evaluated.
Authors: We acknowledge the need for greater detail on the technical integration and experimental conditions. The revised manuscript will expand the implementation section to explain the audio-visual sensor fusion process (combining sound source localization with human tracking), the integration of external vision sensors, and the experimental setup. This will include specifics on test conditions such as lighting variations, background noise levels, and the number of trials performed to support claims of operation in domestic environments. revision: yes
Circularity Check
No circularity: procedural framework without derivations or self-referential reductions
full rationale
The paper describes an IoI detection framework via direct design rules (sound-source localization fused with human tracking and face orientation when speech occurs; fixed gaze-duration threshold when no speech occurs) implemented as a state-transition model in ROS. No equations, parameter fits, uniqueness theorems, or self-citations appear in the derivation chain; the rules are presented as explicit procedural choices verified by experiment rather than derived from or reducing to prior outputs by construction. The framework is therefore self-contained as a descriptive system architecture with no load-bearing steps that collapse to their own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- predefined periods of time for gaze
axioms (1)
- domain assumption Sound source localization combined with human tracking can accurately identify the speaker's position and orientation relative to the robot.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the robot can also detect the IoI if he or she looks at the robot for more than predefined periods of time... Typical values for δt1 and δt2 are in the range of 2−3 sec.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A state transition model for the proposed IoI detection framework is designed and verified by experiments
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Assistive social robots in elderly care: A review,
J. Broekens, M. Heerink, and H. Rosendal, “Assistive social robots in elderly care: A review,”Gerontechnology, vol. 8, no. 2, pp. 94–103, 2009
work page 2009
-
[2]
A multi-modal perception based assistive robotic system for the elderly,
C. Mollaret, A. A. Mekonnen, F. Lerasle, I. Ferran ´e, J. Pinquier, B. Boudet, and P. Rumeau, “A multi-modal perception based assistive robotic system for the elderly,”Computer Vision and Image Under- standing, vol. 149, pp. 78–97, 2016
work page 2016
-
[3]
E. Fardeau, A. S. Senghor, and E. Racine, “The impact of socially assistive robots on human flourishing in the context of dementia: A scoping review,”International Journal of Social Robotics, pp. 1–51, 2023
work page 2023
-
[4]
A dichotomic approach to adaptive interaction for socially assistive robots,
R. D. Benedictis, A. Umbrico, F. Fracasso, G. Cortellessa, A. Orlan- dini, and A. Cesta, “A dichotomic approach to adaptive interaction for socially assistive robots,”User Modeling and User-Adapted Interac- tion, vol. 33, no. 2, pp. 293–331, 2023
work page 2023
-
[5]
Defining socially assistive robotics,
D. Feil-Seifer and M. J. Matari ´c, “Defining socially assistive robotics,” inProceedings of the IEEE International Conference on Rehabilitation Robotics, 2005, pp. 465–468
work page 2005
-
[6]
Multimodal uncer- tainty reduction for intention recognition in human-robot interaction,
S. Trick, D. Koert, J. Peters, and C. A. Rothkopf, “Multimodal uncer- tainty reduction for intention recognition in human-robot interaction,” in2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2019, pp. 7009–7016
work page 2019
-
[7]
Service robots: value co-creation and co-destruction in elderly care networks,
M. ˇCai´c, G. Odekerken-Schr ¨oder, and D. Mahr, “Service robots: value co-creation and co-destruction in elderly care networks,”Journal of Service Management, vol. 29, no. 2, pp. 178–205, 2018
work page 2018
-
[8]
M. A. Shareef, J. U. Ahmed, M. Giannakis, Y . K. Dwivedi, V . Kumar, I. Butt, and U. Kumar, “Machine autonomy for rehabilitation of elderly people: A trade-off between machine intelligence and consumer trust,” Journal of Business Research, vol. 164, p. 113961, 2023
work page 2023
- [9]
-
[10]
Continuous multi-modal human interest detection for a domestic companion humanoid robot,
J. Chen and W. J. Fitzgerald, “Continuous multi-modal human interest detection for a domestic companion humanoid robot,” in2013 16th International Conference on Advanced Robotics (ICAR). IEEE, 2013, pp. 1–6
work page 2013
-
[11]
Heterogeneous robot-assisted services in isolation wards: A system development and usability study,
Y . Kwon, S. Shin, K. Yang, S. Park, S. Shin, H. Jeon, K. Kim, G. Yun, S. Park, J. Byunet al., “Heterogeneous robot-assisted services in isolation wards: A system development and usability study,” in2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2023, pp. 8069–8076
work page 2023
-
[12]
Ros: an open-source robot operating system,
M. Quigley, K. Conley, B. Gerkey, J. Faust, T. Foote, J. Leibs, R. Wheeler, A. Y . Nget al., “Ros: an open-source robot operating system,” inICRA workshop on open source software, vol. 3, no. 3.2. Kobe, Japan, 2009, p. 5
work page 2009
-
[13]
From the perception of action to the understanding of intention,
S.-J. Blakemore and J. Decety, “From the perception of action to the understanding of intention,”Nature reviews neuroscience, vol. 2, no. 8, pp. 561–567, 2001
work page 2001
-
[14]
S. Trick, V . Lott, L. Scherf, C. A. Rothkopf, and D. Koert, “What can i help you with: Towards task-independent detection of intentions for interaction in a human-robot environment,” in2023 32nd IEEE Inter- national Conference on Robot and Human Interactive Communication (RO-MAN). IEEE, 2023, pp. 592–599
work page 2023
-
[15]
J. Bi, F. Hu, Y . Wang, M. Luo, and M. He, “Human engagement intention intensity recognition method based on two states fusion fuzzy inference system,”Intelligent Service Robotics, pp. 1–16, 2023
work page 2023
-
[16]
Proactively approaching pedestrians with an autonomous mobile robot in urban environments,
D. Carton, A. Turnwald, D. Wollherr, and M. Buss, “Proactively approaching pedestrians with an autonomous mobile robot in urban environments,” inExperimental Robotics: The 13th International Symposium on Experimental Robotics. Springer, 2013, pp. 199–214
work page 2013
-
[17]
Measuring communication participation to initiate conversation in human–robot interaction,
C. Shi, M. Shiomi, T. Kanda, H. Ishiguro, and N. Hagita, “Measuring communication participation to initiate conversation in human–robot interaction,”International Journal of Social Robotics, vol. 7, pp. 889– 910, 2015
work page 2015
-
[18]
Conversational inverse infor- mation for context-based retrieval of personal experiences,
Y . Katagiri, M. Bono, and N. Suzuki, “Conversational inverse infor- mation for context-based retrieval of personal experiences,” inNew Frontiers in Artificial Intelligence: Joint JSAI 2005 Workshop Post- Proceedings. Springer, 2006, pp. 365–376
work page 2005
-
[19]
Spa- tial formation model for initiating conversation,
C. Shi, M. Shimada, T. Kanda, H. Ishiguro, and N. Hagita, “Spa- tial formation model for initiating conversation,” inProceedings of robotics: Science and systems VII, 2011, pp. 305–313
work page 2011
-
[20]
X.-T. Truong and T.-D. Ngo, ““to approach humans?”: A unified framework for approaching pose prediction and socially aware robot navigation,”IEEE Transactions on Cognitive and Developmental Sys- tems, vol. 10, no. 3, pp. 557–572, 2017
work page 2017
-
[21]
Estimating a user’s conversational engagement based on head pose information,
R. Ooko, R. Ishii, and Y . I. Nakano, “Estimating a user’s conversational engagement based on head pose information,” inIntelligent Virtual Agents: 10th International Conference, IVA 2011, Reykjavik, Iceland, September 15-17, 2011. Proceedings 11. Springer, 2011, pp. 262– 268. [22]HARK Wiki Open Source Robot Audition Software, (last accessed 20/01/2024. [...
work page 2011
-
[22]
Multiple emitter location and signal parameter estima- tion,
R. Schmidt, “Multiple emitter location and signal parameter estima- tion,”IEEE transactions on antennas and propagation, vol. 34, no. 3, pp. 276–280, 1986
work page 1986
-
[23]
M.-D. Iordache, J. M. Bioucas-Dias, A. Plaza, and B. Somers, “Music- csr: Hyperspectral unmixing via multiple signal classification and collaborative sparse regression,”IEEE Transactions on Geoscience and Remote Sensing, vol. 52, no. 7, pp. 4364–4382, 2013
work page 2013
-
[24]
Time reversal imaging of obscured targets from multistatic data,
A. J. Devaney, “Time reversal imaging of obscured targets from multistatic data,”IEEE Transactions on Antennas and Propagation, vol. 53, no. 5, pp. 1600–1610, 2005
work page 2005
-
[25]
Performance analysis of time-reversal music,
D. Ciuonzo, G. Romano, and R. Solimene, “Performance analysis of time-reversal music,”IEEE Transactions on Signal Processing, vol. 63, no. 10, pp. 2650–2662, 2015
work page 2015
-
[26]
YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors,
C.-Y . Wang, A. Bochkovskiy, and H.-Y . M. Liao, “YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
work page 2023
-
[27]
Simple online and realtime tracking with a deep association metric,
N. Wojke, A. Bewley, and D. Paulus, “Simple online and realtime tracking with a deep association metric,” in2017 IEEE international conference on image processing (ICIP). IEEE, 2017, pp. 3645–3649
work page 2017
-
[28]
Simple online and realtime tracking,
A. Bewley, Z. Ge, L. Ott, F. Ramos, and B. Upcroft, “Simple online and realtime tracking,” in2016 IEEE international conference on image processing (ICIP). IEEE, 2016, pp. 3464–3468
work page 2016
-
[29]
Goffman,Behavior in public places
E. Goffman,Behavior in public places. Simon and Schuster, 2008
work page 2008
-
[30]
Non-verbal communication in human social interaction,
M. Argyle, “Non-verbal communication in human social interaction,” Non-verbal communication, vol. 2, no. 1, 1972
work page 1972
-
[31]
Hu- man gaze following for human-robot interaction,
A. Saran, S. Majumdar, E. S. Short, A. Thomaz, and S. Niekum, “Hu- man gaze following for human-robot interaction,” in2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2018, pp. 8615–8621
work page 2018
-
[32]
H. Kiilavuori, V . Sariola, M. J. Peltola, and J. K. Hietanen, “Making eye contact with a robot: Psychophysiological responses to eye contact with a human and with a humanoid robot,”Biological psychology, vol. 158, p. 107989, 2021
work page 2021
-
[33]
MediaPipe: A Framework for Building Perception Pipelines
C. Lugaresi, J. Tang, H. Nash, C. McClanahan, E. Uboweja, M. Hays, F. Zhang, C.-L. Chang, M. G. Yong, J. Leeet al., “Mediapipe: A framework for building perception pipelines,”arXiv preprint arXiv:1906.08172, 2019
work page internal anchor Pith review arXiv 1906
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.