Recognition: 2 theorem links
· Lean TheoremCCD-Level and Load-Aware Thread Orchestration for In-Memory Vector ANNS on Multi-Core CPUs
Pith reviewed 2026-05-12 03:09 UTC · model grok-4.3
The pith
CCD-aware thread orchestration for vector search raises throughput up to 3.7 times while cutting latency and stalls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The CCD-level and load-aware thread orchestration framework supplies a uniform interface for parallel HNSW and IVF searches, performs cache-friendly and workload-adaptive task dispatching, and applies CCD-aware task stealing; on production workloads this yields up to 3.7x higher throughput, 30-90% lower P50 and P999 latency, 6-30% fewer cache misses, and 20-80% less total CPU stall time.
What carries the argument
CCD-level thread orchestration framework that aligns task-to-core mapping with chiplet cache boundaries and observed request locality for both inter- and intra-query parallelism.
If this is right
- Cache-miss ratio falls 6-30% relative to the baseline scheduler.
- Total CPU stall time drops 20-80%.
- P50 and P999 latencies improve 30-90% on the same hardware.
- The same dispatching and stealing logic works for both HNSW inter-query and IVF intra-query parallelism.
Where Pith is reading between the lines
- The same locality-driven mapping could be applied to other cache-sensitive workloads on chiplet CPUs without changing the core search algorithms.
- Raw core count increases may continue to give diminishing returns until schedulers explicitly respect chiplet cache domains.
- Dynamic monitoring of per-CCD hit rates could allow the framework to adjust stealing thresholds on the fly as query patterns shift.
Load-bearing premise
Real vector search requests exhibit enough repeated access to the same vectors that mapping tasks inside a single CCD will keep working sets in the local cache.
What would settle it
Measure throughput and cache-miss rate on the same CCD hardware when queries are replaced by fully independent random vectors that destroy locality; if the reported gains disappear, the locality premise is false.
Figures













read the original abstract
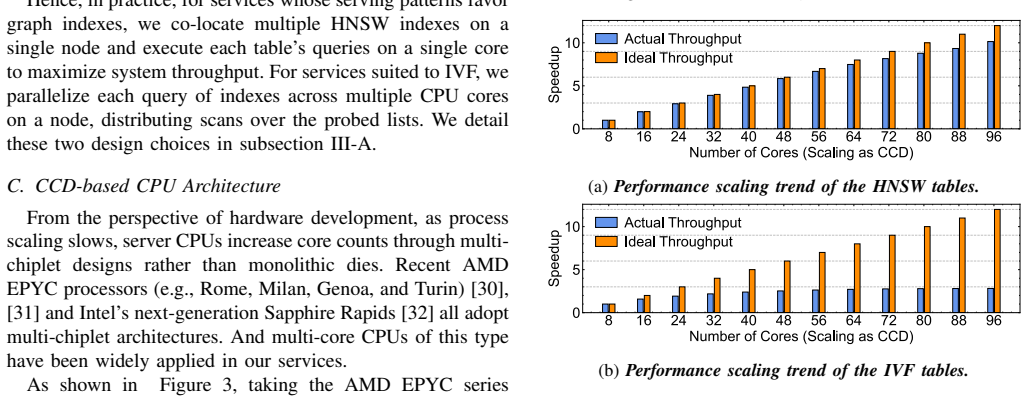
Vector approximate nearest neighbor search (ANNS) underpins search engines, recommendation systems, and advertising services. Recent advances in ANNS indexes make CPU a cost-effective choice for serving million-scale, in-memory vector search, yet per-core throughput remains constrained by memory access latency of vector reading and the compute intensity of distance evaluations in production deployments. With the growing scale of the business and advances in hardware, modern CCD-based multi-core CPUs have been widely deployed for high throughput in our services. However, we find that simply increasing core counts does not yield optimal performance scaling. To improve the efficiency of more cores from the CCD-based architecture, we analyze the distributions of real-world requests in our production environments. We observe high access locality in vector search in our online services and low cache utilization, resulting from overlooking the multi-chiplet nature of CCD based CPUs. Hence, we propose a workload- and hardware-aware thread orchestration framework at CCD-level that (i) provides a uniform interface for both inter-query parallel HNSW search and intra-query parallel IVF search, (ii) achieves cache-friendly and workload-adaptive mapping of task dispatching, and (iii) employs CCD-aware task stealing to address load imbalance. Applied to real production workloads from search, recommendation, and advertising services of Xiaohongshu (RedNote), our approach delivers up to 3.7x higher throughput and 30-90% reductions in P50 and P999 latency. In detail, compared with the original framework, the cache-miss ratio decreases by 6-30%, and the total CPU stall is reduced by 20-80%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a CCD-level and load-aware thread orchestration framework for in-memory vector approximate nearest neighbor search (ANNS) on multi-core CPUs. It identifies high access locality in real-world vector search workloads leading to suboptimal cache utilization on multi-chiplet CCD architectures. The framework provides a uniform interface for inter-query parallel HNSW and intra-query parallel IVF searches, implements cache-friendly task dispatching, and uses CCD-aware task stealing for load balancing. Evaluated on production workloads from search, recommendation, and advertising services at Xiaohongshu, it reports up to 3.7× higher throughput, 30-90% reductions in P50 and P999 latencies, 6-30% lower cache-miss ratios, and 20-80% reduced CPU stalls compared to the original framework.
Significance. If the empirical results hold under scrutiny and generalize beyond the tested services and hardware, the work could meaningfully advance efficient deployment of vector ANNS on modern multi-chiplet CPUs, with direct benefits for latency-sensitive production systems in search and recommendation. The use of real production traffic rather than synthetic benchmarks is a positive aspect that strengthens the practical relevance of the throughput and latency claims.
major comments (3)
- Abstract and Evaluation section: The central claims of up to 3.7× throughput improvement, 30-90% latency reductions, 6-30% cache-miss decrease, and 20-80% CPU-stall reduction are presented without any description of the experimental setup, hardware configuration (number of CCDs, L3 cache sizes per CCD, interconnect details), baseline implementations, workload characteristics, or statistical measures such as error bars and significance tests. This directly affects verifiability of the reported gains.
- Workload analysis (likely §3): The observation of 'high access locality' and resulting low cache utilization is stated as motivation, yet no quantitative breakdown, figures, or metrics on vector access patterns across CCD boundaries are provided. Without this, it is impossible to evaluate how representative the locality is or to predict gains on other index sizes or query distributions.
- Evaluation section: No ablation experiments isolate the contribution of the proposed CCD-level task mapping and dispatching from standard NUMA-aware scheduling or simple thread pinning. Similarly, there is no measurement of overhead introduced by CCD-aware task stealing under varying load conditions. These omissions are load-bearing for the claim that the uniform interface and orchestration deliver the stated efficiency improvements.
minor comments (2)
- The description of the uniform interface for HNSW and IVF could be clarified with a diagram or pseudocode snippet showing how inter-query and intra-query parallelism are handled under the same orchestration layer.
- Hardware platform details (CPU model, core counts per CCD) appear only implicitly through results; explicit specification in the evaluation setup would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve verifiability and completeness.
read point-by-point responses
-
Referee: Abstract and Evaluation section: The central claims of up to 3.7× throughput improvement, 30-90% latency reductions, 6-30% cache-miss decrease, and 20-80% CPU-stall reduction are presented without any description of the experimental setup, hardware configuration (number of CCDs, L3 cache sizes per CCD, interconnect details), baseline implementations, workload characteristics, or statistical measures such as error bars and significance tests. This directly affects verifiability of the reported gains.
Authors: We agree that additional details are required for verifiability. In the revised manuscript we will expand the Evaluation section with a full description of the hardware (CCD count, per-CCD L3 sizes, interconnect), baseline implementations (original framework plus NUMA-aware and pinning variants), production workload characteristics, and statistical measures from repeated runs with error bars. A brief reference to the setup will also be added to the abstract. revision: yes
-
Referee: Workload analysis (likely §3): The observation of 'high access locality' and resulting low cache utilization is stated as motivation, yet no quantitative breakdown, figures, or metrics on vector access patterns across CCD boundaries are provided. Without this, it is impossible to evaluate how representative the locality is or to predict gains on other index sizes or query distributions.
Authors: We will strengthen the workload analysis section with quantitative metrics on cross-CCD vector access rates and cache utilization under the observed query distributions, together with supporting figures that illustrate access patterns. These additions will allow readers to assess representativeness and potential generalization. revision: yes
-
Referee: Evaluation section: No ablation experiments isolate the contribution of the proposed CCD-level task mapping and dispatching from standard NUMA-aware scheduling or simple thread pinning. Similarly, there is no measurement of overhead introduced by CCD-aware task stealing under varying load conditions. These omissions are load-bearing for the claim that the uniform interface and orchestration deliver the stated efficiency improvements.
Authors: We will add ablation experiments that isolate CCD-level mapping and dispatching from standard NUMA-aware scheduling and thread pinning. We will also report the overhead of CCD-aware task stealing by comparing performance with and without the mechanism across different load levels. These results will be included in the revised Evaluation section. revision: yes
Circularity Check
No circularity: empirical systems paper with direct measurements
full rationale
The paper contains no mathematical derivation, equations, fitted parameters, or predictions. It reports observations from production workloads at Xiaohongshu, proposes a CCD-aware thread orchestration framework, and evaluates it via direct empirical measurement of throughput, latency, cache misses, and CPU stalls on the same workloads. No self-citations are load-bearing for the central claims, no ansatz is smuggled, and no result is renamed or forced by construction. The derivation chain is simply observation → implementation → measurement, which is self-contained and externally falsifiable.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearwe propose a workload- and hardware-aware thread orchestration framework at CCD-level that (i) provides a uniform interface for both inter-query parallel HNSW search and intra-query parallel IVF search, (ii) achieves cache-friendly and workload-adaptive mapping of task dispatching, and (iii) employs CCD-aware task stealing
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearthe cache-miss ratio decreases by 6-30%, and the total CPU stall is reduced by 20-80%
Reference graph
Works this paper leans on
-
[1]
Seeping Seman- tics: Linking Datasets Using Word Embeddings for Data Discovery,
R. Castro Fernandez, E. Mansour, A. A. Qahtan, A. Elmagarmid, I. Ilyas, S. Madden, M. Ouzzani, M. Stonebraker, and N. Tang, “Seeping Seman- tics: Linking Datasets Using Word Embeddings for Data Discovery,” 2018 IEEE 34th International Conference on Data Engineering (ICDE), pp. 989–1000, 2018
work page 2018
-
[2]
A Cold-start Recommendation System at Kuaishou Designed from the Short-video Perspective,
G. Chen, R. Sun, Y . Jiang, T. Li, Y . Dai, Q. Shi, X. Qin, J. Fu, P. Chen, R. Huang, N. Li, Q. Zhang, J. Liang, H. Li, and K. Gai, “A Cold-start Recommendation System at Kuaishou Designed from the Short-video Perspective,”Companion Proceedings of the ACM on Web Conference 2025, p. 124–132, 2025
work page 2025
-
[3]
Y . Zhang, S. Liu, and J. Wang, “Are There Fundamental Limitations in Supporting Vector Data Management in Relational Databases? A Case Study of PostgreSQL,”2024 IEEE 40th International Conference on Data Engineering (ICDE), pp. 3640–3653, 2024
work page 2024
- [4]
-
[5]
https://www.statista.com/statistics/1327421/china-xiaohongshu- monthly-active-users/
Number of monthly active users of Xiaohongshu app. https://www.statista.com/statistics/1327421/china-xiaohongshu- monthly-active-users/
-
[6]
CAGRA: Highly Parallel Graph Construction and Approximate Nearest Neighbor Search for GPUs,
H. Ootomo, A. Naruse, C. Nolet, R. Wang, T. Feher, and Y . Wang, “CAGRA: Highly Parallel Graph Construction and Approximate Nearest Neighbor Search for GPUs,”2024 IEEE 40th International Conference on Data Engineering (ICDE), pp. 4236–4247, 2024
work page 2024
- [7]
-
[8]
Y . A. Malkov and D. A. Yashunin, “Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs,”IEEE Transactions on Pattern Analysis and Machine Intelli- gence, vol. 42, no. 4, pp. 824–836, 2020
work page 2020
-
[9]
DiskANN: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node,
S. Jayaram Subramanya, F. Devvrit, H. V . Simhadri, R. Krishnawamy, and R. Kadekodi, “DiskANN: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node,”Advances in Neural Information Processing Systems, vol. 32, 2019
work page 2019
-
[10]
https://github.com/facebookresearch/faiss
Facebook faiss. https://github.com/facebookresearch/faiss
-
[11]
AMD EPYC™ 9004 Series Architecture Overview. https://www.amd.com/content/dam/amd/en/documents/epyc-technical- docs/white-papers/58015-epyc-9004-tg-architecture-overview.pdf
-
[12]
Parallelization Strategies for DLRM Embedding Bag Operator on AMD CPUs,
K. Nair, A.-C. Pandey, S. Karabannavar, M. Arunachalam, J. Kala- matianos, V . Agrawal, S. Gupta, A. Sirasao, E. Delaye, S. Reinhardt, R. Vivekanandham, R. Wittig, V . Kathail, P. Gopalakrishnan, S. Pareek, R. Jain, M. T. Kandemir, J.-L. Lin, G. G. Akbulut, and C. R. Das, “Parallelization Strategies for DLRM Embedding Bag Operator on AMD CPUs,”IEEE Micro,...
work page 2024
-
[13]
Https://hothardware.com/news/amd-server-revenue-market-share- hits-new-high
AMD Data Center Server Market Share Hits New High. Https://hothardware.com/news/amd-server-revenue-market-share- hits-new-high
- [14]
-
[15]
https://www.alibabacloud.com/en/product/lindorm
Aliyun. https://www.alibabacloud.com/en/product/lindorm
-
[16]
Milvus: A Purpose-Built Vector Data Management System,
J. Wang, X. Yi, R. Guo, H. Jin, P. Xu, S. Li, X. Wang, X. Guo, C. Li, X. Xu, K. Yu, Y . Yuan, Y . Zou, J. Long, Y . Cai, Z. Li, Z. Zhang, Y . Mo, J. Gu, R. Jiang, Y . Wei, and C. Xie, “Milvus: A Purpose-Built Vector Data Management System,”Proc. ACM Manag. Data, p. 2614–2627, 2021
work page 2021
-
[17]
Vexless: A Serverless Vector Data Management System Using Cloud Functions,
Y . Su, Y . Sun, M. Zhang, and J. Wang, “Vexless: A Serverless Vector Data Management System Using Cloud Functions,”Proc. ACM Manag. Data, vol. 2, no. 3, May 2024
work page 2024
-
[18]
Z. Peng, M. Zhang, K. Li, R. Jin, and B. Ren, “iQAN: Fast and Accurate Vector Search with Efficient Intra-Query Parallelism on Multi- Core Architectures,”Proceedings of the 28th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming, p. 313–328, 2023
work page 2023
-
[19]
Improving Approximate Nearest Neighbor Search through Learned Adaptive Early Termination,
C. Li, M. Zhang, D. G. Andersen, and Y . He, “Improving Approximate Nearest Neighbor Search through Learned Adaptive Early Termination,” Proc. ACM Manag. Data, p. 2539–2554, 2020
work page 2020
-
[20]
DARTH: Declara- tive Recall Through Early Termination for Approximate Nearest Neigh- bor Search,
M. Chatzakis, Y . Papakonstantinou, and T. Palpanas, “DARTH: Declara- tive Recall Through Early Termination for Approximate Nearest Neigh- bor Search,” 2025, https://arxiv.org/abs/2505.19001
-
[21]
Neos: A NVMe-GPUs Direct Vector Service Buffer in User Space,
Y . Huang, X. Fan, S. Yan, and C. Weng, “Neos: A NVMe-GPUs Direct Vector Service Buffer in User Space,”2024 IEEE 40th International Conference on Data Engineering (ICDE), pp. 3767–3781, 2024
work page 2024
-
[22]
VSAG: An Optimized Search Framework for Graph-Based Approximate Nearest Neighbor Search,
X. Zhong, H. Li, J. Jin, M. Yang, D. Chu, X. Wang, Z. Shen, W. Jia, G. Gu, Y . Xie, X. Lin, H. T. Shen, J. Song, and P. Cheng, “VSAG: An Optimized Search Framework for Graph-Based Approximate Nearest Neighbor Search,”Proc. VLDB Endow., vol. 18, no. 12, p. 5017–5030, Sep. 2025
work page 2025
-
[23]
https://github.com/facebookresearch/faiss/wiki/MetricType- and-distances
Faiss-Metric. https://github.com/facebookresearch/faiss/wiki/MetricType- and-distances
-
[24]
VDTuner: Automated Performance Tuning for Vector Data Management Systems,
T. Yang, W. Hu, W. Peng, Y . Li, J. Li, G. Wang, and X. Liu, “VDTuner: Automated Performance Tuning for Vector Data Management Systems,” 2024 IEEE 40th International Conference on Data Engineering (ICDE), pp. 4357–4369, 2024
work page 2024
-
[25]
J. Gao and C. Long, “RaBitQ: Quantizing High-Dimensional Vectors with a Theoretical Error Bound for Approximate Nearest Neighbor Search,”Proc. ACM Manag. Data, vol. 2, no. 3, May 2024
work page 2024
-
[26]
Product Quantization for Nearest Neighbor Search,
H. J ´egou, M. Douze, and C. Schmid, “Product Quantization for Nearest Neighbor Search,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 33, no. 1, pp. 117–128, 2011
work page 2011
-
[27]
https://ann- benchmarks.com/hnswlib.html
Recall/Build time (s) of HNSW. https://ann- benchmarks.com/hnswlib.html
-
[28]
https://ann-benchmarks.com/faiss- ivf.html
Recall/Build time (s) of Faiss-IVF. https://ann-benchmarks.com/faiss- ivf.html
- [29]
-
[30]
Pioneering chiplet technology and design for the AMD EPYC™ and Ryzen™ processor families,
S. Naffziger, N. Beck, T. Burd, K. Lepak, G. H. Loh, M. Subramony, and S. White, “Pioneering chiplet technology and design for the AMD EPYC™ and Ryzen™ processor families,”Proceedings of the 48th Annual International Symposium on Computer Architecture (ISCA), p. 57–70, 2021
work page 2021
-
[31]
R. Bhargava and K. Troester, “AMD Next-Generation “Zen 4” Core and 4th Gen AMD EPYC Server CPUs,”IEEE Micro, vol. 44, no. 3, pp. 8–17, 2024
work page 2024
-
[32]
https://fuse.wikichip.org/news/6119/intel-unveils-sapphire-rapids-next- generation-server-cpus/
Intel Unveils Sapphire Rapids: Next-Generation Server CPUs. https://fuse.wikichip.org/news/6119/intel-unveils-sapphire-rapids-next- generation-server-cpus/
-
[33]
J. L. Phillip Allen Lane, “The AMD Rome Memory Barrier,” 2022, https://arxiv.org/abs/2211.11867
-
[34]
Https://github.com/apache/brpc/tree/master/src/bthread
bthread. Https://github.com/apache/brpc/tree/master/src/bthread
-
[35]
Similarity Search in High Dimensions via Hashing,
A. Gionis, P. Indyk, and R. Motwani, “Similarity Search in High Dimensions via Hashing,”Proc. VLDB, pp. 518–529, 1999
work page 1999
-
[36]
Multidimensional Binary Search Trees Used for Asso- ciative Searching,
J. L. Bentley, “Multidimensional Binary Search Trees Used for Asso- ciative Searching,”Communications of the ACM, vol. 18, no. 9, pp. 509–517, 1975
work page 1975
-
[37]
https://github.com/microsoft/SPTAG
(2019) SPTAG: Space Partition Tree And Graph (BKT/KDT). https://github.com/microsoft/SPTAG
work page 2019
-
[38]
Fast Approximate Nearest Neighbor Search with the Navigating Spreading-out Graph,
C. Fu, C. Xiang, C. Wang, and D. Cai, “Fast Approximate Nearest Neighbor Search with the Navigating Spreading-out Graph,”Proc. PVLDB, vol. 12, no. 5, pp. 461–474, 2019
work page 2019
-
[39]
Manu: a cloud native vector database management system,
R. Guo, X. Luan, L. Xiang, X. Yan, X. Yi, J. Luo, Q. Cheng, W. Xu, J. Luo, F. Liu, Z. Cao, Y . Qiao, T. Wang, B. Tang, and C. Xie, “Manu: a cloud native vector database management system,”Proc. VLDB Endow., vol. 15, no. 12, p. 3548–3561, Aug. 2022
work page 2022
- [40]
-
[41]
SingleStore-V: An Integrated Vector Database System in SingleStore,
C. Chen, C. Jin, Y . Zhang, S. Podolsky, C. Wu, S.-P. Wang, E. Hanson, Z. Sun, R. Walzer, and J. Wang, “SingleStore-V: An Integrated Vector Database System in SingleStore,”Proc. VLDB Endow., vol. 17, no. 12, p. 3772–3785, Aug. 2024
work page 2024
-
[42]
Vector Database Management Techniques and Systems,
J. J. Pan, J. Wang, and G. Li, “Vector Database Management Techniques and Systems,”Proc. ACM Manag. Data, p. 597–604, 2024
work page 2024
-
[43]
Vector Databases: What’s Really New and What’s Next? (VLDB 2024 Panel),
J. Wang, E. Hanson, G. Li, Y . Papakonstantinou, H. Simhadri, and C. Xie, “Vector Databases: What’s Really New and What’s Next? (VLDB 2024 Panel),”Proc. VLDB Endow., vol. 17, no. 12, p. 4505–4506, Aug. 2024
work page 2024
-
[44]
BlendHouse: A Cloud-Native Vector Database System in ByteHouse,
Z. Niu, X. Tian, X. Peng, and X. Chen, “BlendHouse: A Cloud-Native Vector Database System in ByteHouse,”2025 IEEE 41st International Conference on Data Engineering (ICDE), pp. 4332–4345, 2025
work page 2025
-
[45]
GaussDB- Vector: A Large-Scale Persistent Real-Time Vector Database for LLM Applications,
J. Sun, G. Li, J. Pan, J. Wang, Y . Xie, R. Liu, and W. Nie, “GaussDB- Vector: A Large-Scale Persistent Real-Time Vector Database for LLM Applications,”Proc. VLDB Endow., vol. 18, no. 12, p. 4951–4963, Sep. 2025
work page 2025
-
[46]
Cost-Effective, Low Latency Vector Search with Azure Cosmos DB,
N. Upreti, H. V . Simhadri, H. S. Sundar, K. Sundaram, S. Boshra, B. Perumalswamy, S. Atri, M. Chisholm, R. R. Singh, G. Yang, T. Hass, N. Dudhey, S. Pattipaka, M. Hildebrand, M. Manohar, J. Moffitt, H. Xu, N. Datha, S. Gupta, R. Krishnaswamy, P. Gupta, A. Sahu, H. Varada, S. Barthwal, R. Mor, J. Codella, S. Cooper, K. Pilch, S. Moreno, A. Kataria, S. Kul...
work page 2025
-
[47]
DiskANN: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node,
S. J. Subramanya, Devvrit, R. Kadekodi, R. Krishnaswamy, and H. V . Simhadri, “DiskANN: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node,”NeurIPS, 2019
work page 2019
-
[48]
SPANN: Highly-efficient Billion-scale Approximate Nearest Neighbor Search,
Q. Chen, B. Zhao, H. Wang, M. Li, C. Liu, Z. Li, M. Yang, and J. Wang, “SPANN: Highly-efficient Billion-scale Approximate Nearest Neighbor Search,”NeurIPS, 2021
work page 2021
-
[49]
M. Wang, W. Xu, X. Yi, S. Wu, Z. Peng, X. Ke, Y . Gao, X. Xu, R. Guo, and C. Xie, “Starling: An I/O-Efficient Disk-Resident Graph Index Framework for High-Dimensional Vector Similarity Search on Data Segment,”Proc. ACM Manag. Data, vol. 2, no. 1, Mar. 2024
work page 2024
-
[50]
Turbocharging Vector Databases Using Modern SSDs,
J. Shim, J. Oh, H. Roh, J. Do, and S.-W. Lee, “Turbocharging Vector Databases Using Modern SSDs,”Proc. VLDB Endow., vol. 18, no. 11, pp. 4710–4722, 2025
work page 2025
-
[51]
TigerVector: Supporting Vector Search in Graph Databases for Advanced RAGs,
S. Liu, Z. Zeng, L. Chen, A. Ainihaer, A. Ramasami, S. Chen, Y . Xu, M. Wu, and J. Wang, “TigerVector: Supporting Vector Search in Graph Databases for Advanced RAGs,”Proc. ACM Manag. Data, p. 553–565, 2025
work page 2025
-
[52]
Realizing the AMD Exascale Heterogeneous Processor Vision,
A. Smith, G. H. Loh, M. J. Schulte, M. Ignatowski, S. Naffziger, M. Mantor, M. Fowler, N. Kalyanasundharam, V . Alla, N. Malaya, J. L. Greathouse, E. Chapman, and R. Swaminathan, “Realizing the AMD Exascale Heterogeneous Processor Vision,”Proc. 51st ACM/IEEE Int’l Symp. on Computer Architecture (ISCA), Industry Track, pp. 876–889, 2024
work page 2024
-
[53]
OLAP on Modern Chiplet-Based Processors,
A. Fogli, B. Zhao, P. Pietzuch, M. Bandle, and J. Giceva, “OLAP on Modern Chiplet-Based Processors,”Proc. VLDB Endow., vol. 17, no. 11, p. 3428–3441, Jul. 2024
work page 2024
-
[54]
Load and MLP-Aware Thread Orchestration for Recommendation Systems Inference on CPUs,
R. Jain, T. Chou, O. Kayiran, J. Kalamatianos, G. H. Loh, M. T. Kandemir, and C. R. Das, “Load and MLP-Aware Thread Orchestration for Recommendation Systems Inference on CPUs,”Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), p. 589–603, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.