Recognition: 2 theorem links
· Lean TheoremNumColBERT: Non-Intrusive Numeracy Injection for Late-Interaction Retrieval Models
Pith reviewed 2026-05-12 02:50 UTC · model grok-4.3
The pith
NumColBERT provides a non-intrusive way to handle numerical conditions in late-interaction retrieval models by adding gating and contrastive learning at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
NumColBERT is a non-intrusive, inference-time method for late-interaction retrieval models that improves performance on numerically conditioned queries. It achieves this by incorporating a Numerical Gating Mechanism to amplify critical numerical tokens and suppress neutral ones, along with a Numerical Contrastive Learning objective to shape the embedding space according to numerical magnitudes, units, and conditions. The method fully preserves the standard ColBERT indexing and MaxSim scoring pipeline, allowing direct reuse of existing optimizations and ecosystem components.
What carries the argument
The Numerical Gating Mechanism combined with Numerical Contrastive Learning, which together enable numerical conditions to contribute within the unchanged late-interaction scoring framework.
Load-bearing premise
That the numerical gating and contrastive adjustments applied at inference time can enhance numerical query performance while keeping the original late-interaction mechanism and MaxSim scoring fully intact and without added latency.
What would settle it
A controlled experiment comparing NumColBERT against a fine-tuned ColBERT baseline on a dataset of queries with explicit numerical conditions, measuring if retrieval metrics show no improvement or fall short of separate-scoring approaches.
Figures



read the original abstract
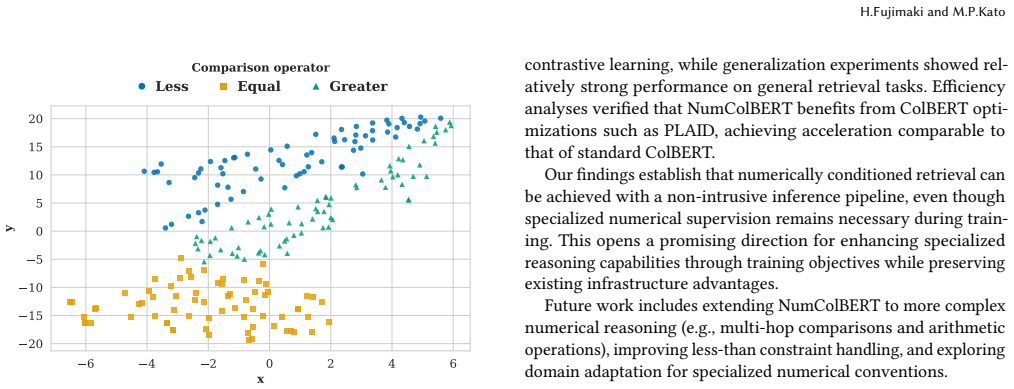
This study addresses the challenge of improving dense retrieval performance for queries containing numerical conditions, such as ``companies with more than one billion dollars in R&D expenditure.'' Although recent research has shown that standard models struggle with numeric information in domains such as finance, e-commerce, and medicine, existing solutions typically decompose queries into textual and numerical components and score them separately. These approaches modify late-interaction retrieval models such as ColBERT and introduce challenges in deployment, latency, and maintainability. To overcome these limitations, we propose NumColBERT, an inference-time non-intrusive method that enhances numerically conditioned retrieval while preserving the original late-interaction mechanism. Because NumColBERT retains the standard ColBERT indexing and MaxSim scoring pipeline, existing optimizations and ecosystem components can be reused directly, facilitating practical deployment. NumColBERT introduces a Numerical Gating Mechanism and a Numerical Contrastive Learning objective to enable numerical conditions to contribute more effectively within standard ColBERT scoring. The gating mechanism amplifies tokens carrying critical numerical constraints while suppressing context-neutral numerical mentions, and the contrastive objective shapes the embedding space to reflect numerical magnitudes, units, and conditions. Experimental results show that NumColBERT substantially outperforms standard fine-tuning baselines and achieves accuracy comparable to or better than prior approaches relying on separate textual and numerical scoring. These findings demonstrate the feasibility of numerically conditioned retrieval with a non-intrusive inference pipeline and present a maintainable solution for real-world deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes NumColBERT, an inference-time non-intrusive method to improve late-interaction models such as ColBERT on queries containing numerical conditions (e.g., 'more than one billion dollars'). It introduces a Numerical Gating Mechanism that amplifies tokens carrying critical numerical constraints while suppressing neutral mentions, together with a Numerical Contrastive Learning objective that shapes embeddings to reflect magnitudes, units, and conditions. The central claim is that these additions preserve the standard ColBERT indexing and MaxSim scoring pipeline, enabling direct reuse of existing optimizations and ecosystem components, while delivering performance superior to standard fine-tuning and comparable to prior separate textual-numerical scoring approaches.
Significance. If the non-intrusive property can be rigorously demonstrated and the performance gains hold under standard evaluation protocols, the work would provide a practically valuable route for deploying dense retrievers in numerical-heavy domains without incurring the latency, maintainability, or indexing overhead of hybrid scoring systems.
major comments (1)
- [Numerical Gating Mechanism description] The Numerical Gating Mechanism is defined as query-dependent amplification of tokens based on the query's numerical conditions. Standard ColBERT MaxSim, however, is a fixed, query-independent max over precomputed token-wise dot products. The manuscript must supply explicit pseudocode or a section detailing the exact insertion point of the gate (e.g., whether it modifies the MaxSim kernel, applies post-lookup scaling, or alters the document embedding matrix) to show that the original late-interaction mechanism and precomputed index remain unmodified; without this, the non-intrusive claim is at risk of being internally inconsistent.
minor comments (1)
- The abstract omits dataset names, concrete metrics, statistical tests, and ablation details; these should be summarized with references to the corresponding tables or sections so readers can immediately assess the strength of the experimental support.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The major comment highlights an important point about clarifying the implementation to rigorously support the non-intrusive claim. We address it below and will revise the paper accordingly.
read point-by-point responses
-
Referee: [Numerical Gating Mechanism description] The Numerical Gating Mechanism is defined as query-dependent amplification of tokens based on the query's numerical conditions. Standard ColBERT MaxSim, however, is a fixed, query-independent max over precomputed token-wise dot products. The manuscript must supply explicit pseudocode or a section detailing the exact insertion point of the gate (e.g., whether it modifies the MaxSim kernel, applies post-lookup scaling, or alters the document embedding matrix) to show that the original late-interaction mechanism and precomputed index remain unmodified; without this, the non-intrusive claim is at risk of being internally inconsistent.
Authors: We agree that the current description of the Numerical Gating Mechanism requires additional precision to demonstrate compatibility with the unmodified ColBERT pipeline. In NumColBERT, the gating mechanism operates exclusively on the query token embeddings at inference time. For each query token, we compute a scalar gate value derived from its semantic alignment with the parsed numerical conditions (magnitude, unit, and relational operator) in the query. This gate is then used to scale the corresponding query embedding vector before it is passed to the standard MaxSim operator. The MaxSim computation itself—max over document-token dot products—remains exactly as in the original ColBERT formulation and is not altered. Critically, all document embeddings are precomputed and indexed without any numerical gating or modification, preserving the original index structure, storage format, and retrieval optimizations. We will add a dedicated subsection (revised Section 3.2) containing explicit pseudocode that shows the precise insertion point: query embedding generation → numerical gating → standard MaxSim with unmodified document embeddings. This revision will eliminate any ambiguity regarding the non-intrusive property. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper presents NumColBERT as an empirical method adding a Numerical Gating Mechanism and Numerical Contrastive Learning objective at inference time, with the central claim that it preserves the standard ColBERT indexing and MaxSim scoring pipeline. No equations, derivations, or first-principles results are visible in the provided text that reduce any prediction or uniqueness claim to a self-definition, fitted input, or self-citation chain. The non-intrusive property is asserted via description of the added components rather than derived from performance metrics or prior author theorems. Experimental comparisons to baselines are presented as independent validation. This is a standard applied ML proposal with no load-bearing circular reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption ColBERT's MaxSim scoring and indexing remain effective when token embeddings are modified by the added gating mechanism
invented entities (2)
-
Numerical Gating Mechanism
no independent evidence
-
Numerical Contrastive Learning objective
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearNumColBERT introduces a Numerical Gating Mechanism and a Numerical Contrastive Learning objective to enable numerical conditions to contribute more effectively within standard ColBERT scoring.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclearthe retrieval scoring N-ii operates identically to ColBERT: the document index remains a standard collection of token embeddings ... unmodified MaxSim
Reference graph
Works this paper leans on
-
[1]
Prayas Agrawal, Nandeesh Kumar K M, Muthusamy Chelliah, Surender Kumar, and Soumen Chakrabarti. 2025. Dense Retrieval with Quantity Comparison In- tent. InFindings of the Association for Computational Linguistics: ACL 2025, Wanx- iang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (Eds.). Association for Computational Linguistics, Vien...
-
[2]
Satya Almasian, Milena Bruseva, and Michael Gertz. 2024. Numbers Matter! Bringing Quantity-awareness to Retrieval Systems. InFindings of the Association for Computational Linguistics: EMNLP 2024, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association for Computational Linguistics, Miami, Florida, USA, 12120–12136. doi:10.18653/v1/2024.findi...
-
[3]
Satya Almasian, Vivian Kazakova, Philipp Göldner, and Michael Gertz. 2023. CQE: A Comprehensive Quantity Extractor. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore, 12845–12859. doi:10.18653/v1/2023.emnlp-main.793
-
[4]
Chung-Chi Chen, Hiroya Takamura, Ichiro Kobayashi, and Yusuke Miyao. 2023. Improving Numeracy by Input Reframing and Quantitative Pre-Finetuning Task. InFindings of the Association for Computational Linguistics: EACL 2023, Andreas Vlachos and Isabelle Augenstein (Eds.). Association for Computational Linguis- tics, Dubrovnik, Croatia, 69–77. doi:10.18653/v...
-
[5]
Zhiyu Chen, Wenhu Chen, Charese Smiley, Sameena Shah, Iana Borova, Dylan Langdon, Reema Moussa, Matt Beane, Ting-Hao Huang, Bryan Routledge, and William Yang Wang. 2021. FinQA: A Dataset of Numerical Reasoning over Financial Data. InEMNLP. 3697–3711
work page 2021
-
[6]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Jill Burstein, Christy...
work page 2019
-
[7]
Dheeru Dua, Yizhong Wang, Pradeep Dasigi, Gabriel Stanovsky, Sameer Singh, and Matt Gardner. 2019. DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs. InNAACL-HLT. 2368–2378
work page 2019
-
[8]
Thibault Formal, Benjamin Piwowarski, and Stéphane Clinchant. 2021. SPLADE: Sparse Lexical and Expansion Model for First Stage Ranking. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval(Virtual Event, Canada)(SIGIR ’21). Association for NumColBERT: Non-Intrusive Numeracy Injection for Late-In...
-
[9]
Haruki Fujimaki and Makoto P. Kato. 2025. Investigating the Performance of Dense Retrievers for Queries with Numerical Conditions. InAdvances in Informa- tion Retrieval, Claudia Hauff, Craig Macdonald, Dietmar Jannach, Gabriella Kazai, Franco Maria Nardini, Fabio Pinelli, Fabrizio Silvestri, and Nicola Tonellotto (Eds.). Springer Nature Switzerland, Cham, 210–218
work page 2025
-
[10]
Mor Geva, Ankit Gupta, and Jonathan Berant. 2020. Injecting Numerical Rea- soning Skills into Language Models. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault (Eds.). Association for Computational Linguistics, Online, 946–958. doi:10.18653/v1/2020.acl-main.89
-
[11]
Amritpal Singh Gill, Sannikumar Patel, Péter Varga, Patrick Miller, and Sakis Athanasiadis. 2025. From Keywords to Concepts: A Late Interaction Approach to Semantic Product Search on IKEA.com. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (Padua, Italy)(SIGIR ’25). Association for Computi...
-
[12]
Vinh Thinh Ho, Yusra Ibrahim, Koninika Pal, Klaus Berberich, and Gerhard Weikum. 2019. Qsearch: Answering Quantity Queries from Text. InThe Se- mantic Web – ISWC 2019: 18th International Semantic Web Conference, Auckland, New Zealand, October 26–30, 2019, Proceedings, Part I(Auckland, New Zealand). Springer-Verlag, Berlin, Heidelberg, 237–257. doi:10.1007...
-
[13]
Vinh Thinh Ho, Koninika Pal, Niko Kleer, Klaus Berberich, and Gerhard Weikum
-
[14]
Entities with Quantities: Extraction, Search, and Ranking. InProceedings of the 13th International Conference on Web Search and Data Mining(Houston, TX, USA)(WSDM ’20). Association for Computing Machinery, New York, NY, USA, 833–836. doi:10.1145/3336191.3371860
-
[15]
Vinh Thinh Ho, Koninika Pal, Simon Razniewski, Klaus Berberich, and Gerhard Weikum. 2021. Extracting Contextualized Quantity Facts from Web Tables. InProceedings of the Web Conference 2021(Ljubljana, Slovenia)(WWW ’21). Association for Computing Machinery, New York, NY, USA, 4033–4042. doi:10. 1145/3442381.3450072
-
[16]
Vinh Thinh Ho, Koninika Pal, and Gerhard Weikum. 2021. QuTE: Answer- ing Quantity Queries from Web Tables. InProceedings of the 2021 Interna- tional Conference on Management of Data(Virtual Event, China)(SIGMOD ’21). Association for Computing Machinery, New York, NY, USA, 2740–2744. doi:10.1145/3448016.3452763
-
[17]
Vinh Thinh Ho, Daria Stepanova, Dragan Milchevski, Jannik Strötgen, and Gerhard Weikum. 2022. Enhancing Knowledge Bases with Quantity Facts. In Proceedings of the ACM Web Conference 2022(Virtual Event, Lyon, France)(WWW ’22). Association for Computing Machinery, New York, NY, USA, 893–901. doi:10. 1145/3485447.3511932
-
[18]
Sebastian Hofstätter, Omar Khattab, Sophia Althammer, Mete Sertkan, and Al- lan Hanbury. 2022. Introducing Neural Bag of Whole-Words with ColBERTer: Contextualized Late Interactions using Enhanced Reduction. InProceedings of the 31st ACM International Conference on Information & Knowledge Management (Atlanta, GA, USA)(CIKM ’22). Association for Computing ...
-
[19]
Sebastian Hofstätter, Aldo Lipani, Markus Zlabinger, and Allan Hanbury. 2020. Learning to Re-Rank with Contextualized Stopwords. InProceedings of the 29th ACM International Conference on Information & Knowledge Management(Virtual Event, Ireland)(CIKM ’20). Association for Computing Machinery, New York, NY, USA, 2057–2060. doi:10.1145/3340531.3412079
-
[20]
Yusra Ibrahim, Mirek Riedewald, and Gerhard Weikum. 2016. Making Sense of Entities and Quantities in Web Tables. InProceedings of the 25th ACM International on Conference on Information and Knowledge Management(Indianapolis, Indiana, USA)(CIKM ’16). Association for Computing Machinery, New York, NY, USA, 1703–1712. doi:10.1145/2983323.2983772
-
[21]
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. 2021. What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences11, 14 (2021), 6421
work page 2021
-
[22]
Hyukkyu Kang, Injung Kim, and Wook-Shin Han. 2025. TRIAL: Token Rela- tions and Importance Aware Late-interaction for Accurate Text Retrieval. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (Eds.). Association for Computational Lingui...
-
[23]
Omar Khattab and Matei Zaharia. 2020. ColBERT: Efficient and Effective Pas- sage Search via Contextualized Late Interaction over BERT. InProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Infor- mation Retrieval(Virtual Event, China)(SIGIR ’20). Association for Computing Machinery, New York, NY, USA, 39–48. doi:10.11...
-
[24]
Tongliang Li, Lei Fang, Jian-Guang Lou, Zhoujun Li, and Dongmei Zhang
-
[25]
AnaSearch: Extract, Retrieve and Visualize Structured Results from Unstructured Text for Analytical Queries. InProceedings of the 14th ACM In- ternational Conference on Web Search and Data Mining(Virtual Event, Israel) (WSDM ’21). Association for Computing Machinery, New York, NY, USA, 906–909. doi:10.1145/3437963.3441694
-
[26]
Ilya Loshchilov and Frank Hutter. 2019. Decoupled Weight Decay Regularization. In7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6–9, 2019
work page 2019
-
[27]
Laurens van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-SNE. Journal of machine learning research9, Nov (2008), 2579–2605
work page 2008
-
[28]
Rahmad Mahendra, Damiano Spina, Lawrence Cavedon, and Karin Verspoor
-
[29]
Do Numbers Matter? Types and Prevalence of Numbers in Clinical Texts. In Proceedings of the 23rd Workshop on Biomedical Natural Language Processing, Dina Demner-Fushman, Sophia Ananiadou, Makoto Miwa, Kirk Roberts, and Junichi Tsujii (Eds.). Association for Computational Linguistics, Bangkok, Thailand, 409–415. doi:10.18653/v1/2024.bionlp-1.32
-
[30]
Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, and Li Deng. 2016. MS MARCO: A Human Generated MAchine Reading COmprehension Dataset. InProceedings of the Workshop on Cogni- tive Computation: Integrating neural and symbolic approaches 2016 co-located with the 30th Annual Conference on Neural Information Processing Syste...
work page 2016
- [31]
-
[32]
Subhro Roy, Tim Vieira, and Dan Roth. 2015. Reasoning about Quantities in Natural Language.Transactions of the Association for Computational Linguistics 3 (2015), 1–13. doi:10.1162/tacl_a_00118
-
[33]
Maciej Rybinski, Stephen Wan, Sarvnaz Karimi, Cecile Paris, Brian Jin, Neil Huth, Peter Thorburn, and Dean Holzworth. 2023. SciHarvester: Searching Scientific Documents for Numerical Values. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval(Taipei, Taiwan)(SIGIR ’23). Association for Computin...
-
[34]
Keshav Santhanam, Omar Khattab, Christopher Potts, and Matei Zaharia. 2022. PLAID: An Efficient Engine for Late Interaction Retrieval. InProceedings of the 31st ACM International Conference on Information & Knowledge Management. Association for Computing Machinery, New York, NY, USA, 1747–1756. doi:10. 1145/3511808.3557325
-
[35]
Keshav Santhanam, Omar Khattab, Jon Saad-Falcon, Christopher Potts, and Matei Zaharia. 2022. ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction. InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Marine Carpuat, Marie-Catherine de Marn...
work page 2022
-
[36]
doi:10.18653/v1/2022.naacl-main.272
-
[37]
Mandar Sharma, Rutuja Taware, Pravesh Koirala, Nikhil Muralidhar, and Naren Ramakrishnan. 2024. Laying Anchors: Semantically Priming Numerals in Language Modeling. InFindings of the Association for Computational Lin- guistics: NAACL 2024, Kevin Duh, Helena Gomez, and Steven Bethard (Eds.). Association for Computational Linguistics, Mexico City, Mexico, 26...
-
[38]
Jasivan Alex Sivakumar and Nafise Sadat Moosavi. 2025. How to Leverage Digit Embeddings to Represent Numbers?. InProceedings of the 31st International Conference on Computational Linguistics, Owen Rambow, Leo Wanner, Marianna Apidianaki, Hend Al-Khalifa, Barbara Di Eugenio, and Steven Schockaert (Eds.). Association for Computational Linguistics, Abu Dhabi...
work page 2025
-
[39]
Dhanasekar Sundararaman, Shijing Si, Vivek Subramanian, Guoyin Wang, Deva- manyu Hazarika, and Lawrence Carin. 2020. Methods for Numeracy-Preserving Word Embeddings. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu (Eds.). Association for Computational Ling...
-
[40]
Avijit Thawani, Jay Pujara, Filip Ilievski, and Pedro Szekely. 2021. Representing Numbers in NLP: a Survey and a Vision. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguis- tics: Human Language Technologies, Kristina Toutanova, Anna Rumshisky, Luke Zettlemoyer, Dilek Hakkani-Tur, Iz Beltagy, Ste...
-
[41]
Ellen M. Voorhees. 2013. The TREC Medical Records Track. InProceedings of the International Conference on Bioinformatics, Computational Biology and Biomed- ical Informatics(Wshington DC, USA)(BCB’13). Association for Computing Machinery, New York, NY, USA, 239–246. doi:10.1145/2506583.2506624
-
[42]
Eric Wallace, Yizhong Wang, Sujian Li, Sameer Singh, and Matt Gardner. 2019. Do NLP Models Know Numbers? Probing Numeracy in Embeddings. InEMNLP- IJCNLP. 5307–5315. H.Fujimaki and M.P.Kato
work page 2019
-
[43]
Haotong Yang, Yi Hu, Shijia Kang, Zhouchen Lin, and Muhan Zhang. 2025. Number Cookbook: Number Understanding of Language Models and How to Improve It. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.