Recognition: no theorem link
Thermal-Det: Language-Guided Cross-Modal Distillation for Open-Vocabulary Thermal Object Detection
Pith reviewed 2026-05-12 03:20 UTC · model grok-4.3
The pith
Thermal-Det establishes open-vocabulary detection for thermal images by distilling language-guided supervision from an RGB teacher on synthetic thermal data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
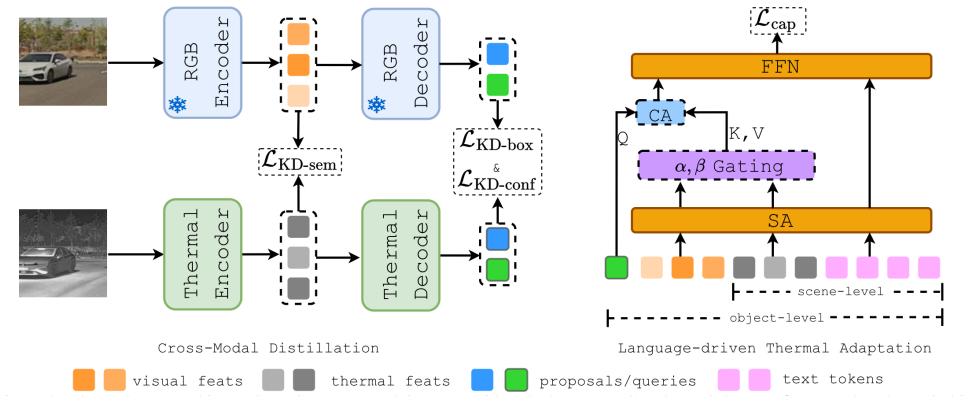
Thermal-Det is the first large language model supervised open-vocabulary detector tailored for thermal images. It is enabled by a synthetic dataset of over one million thermally aligned samples obtained by converting GroundingCap-1M into the thermal domain and removing RGB-specific terms from the captions. The detector jointly optimizes detection, captioning, and cross-modal distillation objectives, letting a frozen RGB teacher supply geometric and semantic pseudo-supervision on paired but unlabeled RGB-thermal data. It adds a Thermal-Text Alignment Head for text calibration and a Modality-Fused Cross-Attention module for dual-modality reasoning. Unlike prior domain-adaptation approaches, it
What carries the argument
Cross-modal distillation pipeline that transfers open-vocabulary knowledge from a frozen RGB teacher to a thermal student via pseudo-supervision on paired unlabeled images and synthetic thermally aligned captions.
If this is right
- Open-vocabulary queries become usable for locating arbitrary objects in thermal footage without retraining the detector for each new class.
- Large-scale training of thermal detectors no longer requires manual thermal annotations because existing RGB datasets can be converted and paired data can supply the missing supervision.
- The detector fully adapts to thermal-specific contrast patterns while preserving its ability to align with language descriptions.
- Consistent 2-4 percent AP improvements appear on standard thermal object-detection benchmarks relative to prior open-vocabulary methods.
- Language-driven thermal perception is now possible as a practical starting point for applications that rely on heat imagery.
Where Pith is reading between the lines
- The same conversion-plus-distillation recipe could be tried on other data-scarce modalities such as depth maps or event-camera streams whenever paired RGB data exists.
- If the caption-filtering step works reliably, the method lowers the cost of building detectors for any visual domain that lacks large labeled corpora.
- Zero-shot detection of novel objects described only in text might become feasible in thermal imagery once the language alignment is strong enough.
- The performance edge could be tested further by replacing the frozen RGB teacher with a jointly trained multimodal teacher or by collecting a small set of real thermal captions for comparison.
Load-bearing premise
Converting RGB captions and bounding boxes into the thermal domain while filtering RGB-specific terms still produces semantically valid training examples whose boxes and descriptions match what thermal images actually show.
What would settle it
Running the trained Thermal-Det on a held-out thermal benchmark that uses only human-verified thermal annotations and finding that its average precision does not exceed or falls below the best RGB open-vocabulary detectors on the same data.
Figures

read the original abstract
Existing open-vocabulary detectors focus on RGB images and fail to generalize to thermal imagery, where low texture and emissivity variations challenge RGB-based semantics. We present Thermal-Det, the first large language model (LLM) supervised open-vocabulary detector tailored for thermal images. To enable large-scale training, we develop a synthetic dataset by converting GroundingCap-1M into the thermal domain and filtering captions to remove RGB-specific terms, yielding over one million thermally aligned samples with bounding boxes, grounding texts, and detailed captions. Thermal-Det jointly optimizes detection, captioning, and cross-modal distillation objectives. A frozen RGB teacher provides geometric and semantic pseudo-supervision for paired but unlabeled RGB-thermal data, transferring open-vocabulary knowledge without manual annotation. The model further employs a Thermal-Text Alignment Head for text calibration and a Modality-Fused Cross-Attention module for dual-modality reasoning. Unlike prior domain-adaptation methods, the detector is fully fine-tuned to internalize thermal contrast patterns while preserving language alignment. Experiments on public benchmarks show consistent 2-4% AP gains over existing open-vocabulary detectors, establishing a strong foundation for scalable, language-driven thermal perception.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Thermal-Det, an open-vocabulary object detector for thermal images that uses LLM supervision via cross-modal distillation from a frozen RGB teacher model. It constructs a synthetic training set of over 1M samples by converting GroundingCap-1M into the thermal domain and filtering RGB-specific caption terms, then jointly optimizes detection, captioning, and distillation losses with a Thermal-Text Alignment Head and Modality-Fused Cross-Attention module. The central empirical claim is consistent 2-4% AP gains over prior open-vocabulary detectors on public benchmarks.
Significance. If the synthetic dataset preserves semantically valid bounding boxes and captions under the domain shift and the reported gains prove robust, the approach would offer a scalable route to language-guided thermal perception without requiring large-scale manual thermal annotations. The distillation strategy and joint optimization objectives represent a reasonable extension of RGB open-vocabulary methods to the thermal domain.
major comments (2)
- [§3.1] §3.1 (Dataset Construction): The conversion of GroundingCap-1M and subsequent RGB-term filtering are presented as producing >1M thermally aligned samples with valid bounding boxes and captions, yet no quantitative validation (human agreement rates, thermal-specific IoU, or caption similarity metrics) is reported to confirm that transferred boxes align with actual thermal contrast regions and that filtered captions accurately describe emissivity patterns rather than RGB appearance.
- [§4] §4 (Experiments): The claim of consistent 2-4% AP gains is stated without specifying the exact baselines, the number of random seeds or runs used to compute the gains, error bars, statistical significance tests, or ablation studies that isolate the contribution of the synthetic dataset versus the distillation objectives and new modules.
minor comments (2)
- [Abstract] The abstract and §1 refer to 'public benchmarks' without naming the datasets (e.g., FLIR, KAIST, or others) or the evaluation protocol (open-vocabulary split details).
- [§3.2] Notation for the loss weighting coefficients (mentioned as free parameters) is introduced without an explicit equation or table showing their values or sensitivity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, indicating the changes we will make in the revised manuscript.
read point-by-point responses
-
Referee: [§3.1] §3.1 (Dataset Construction): The conversion of GroundingCap-1M and subsequent RGB-term filtering are presented as producing >1M thermally aligned samples with valid bounding boxes and captions, yet no quantitative validation (human agreement rates, thermal-specific IoU, or caption similarity metrics) is reported to confirm that transferred boxes align with actual thermal contrast regions and that filtered captions accurately describe emissivity patterns rather than RGB appearance.
Authors: We agree that explicit quantitative validation of the synthetic dataset would strengthen the paper. The original manuscript describes the conversion pipeline from GroundingCap-1M and the RGB-term filtering process but does not report agreement rates or similarity metrics. In the revision we will add a dedicated validation subsection to §3.1 that includes: (i) human evaluation on a sampled subset of 500 images reporting inter-annotator agreement for bounding-box alignment with thermal contrast regions and caption accuracy with respect to emissivity patterns, and (ii) CLIP-based caption similarity scores between original RGB captions and the filtered thermal versions. We note that direct thermal-specific IoU is difficult because the source dataset lacks paired thermal ground truth; the human study will serve as the primary validation proxy. These additions will appear in the main text and supplementary material. revision: yes
-
Referee: [§4] §4 (Experiments): The claim of consistent 2-4% AP gains is stated without specifying the exact baselines, the number of random seeds or runs used to compute the gains, error bars, statistical significance tests, or ablation studies that isolate the contribution of the synthetic dataset versus the distillation objectives and new modules.
Authors: We acknowledge that the experimental section would benefit from greater reproducibility details and component-wise analysis. The reported gains compare against standard open-vocabulary RGB detectors (GroundingDINO, OWL-ViT) fine-tuned on thermal data, yet the manuscript omits seed counts, variance, and targeted ablations. In the revised version we will: (1) explicitly list all baselines and their exact configurations, (2) report mean AP ± standard deviation over five random seeds together with error bars in all tables, (3) include paired t-test p-values to assess statistical significance of the 2-4% gains, and (4) add a new ablation subsection (4.3) that isolates the synthetic dataset size, distillation loss weight, Thermal-Text Alignment Head, and Modality-Fused Cross-Attention module. Updated tables, figures, and statistical results will be provided in the main paper and appendix. revision: yes
Circularity Check
No significant circularity in Thermal-Det derivation chain
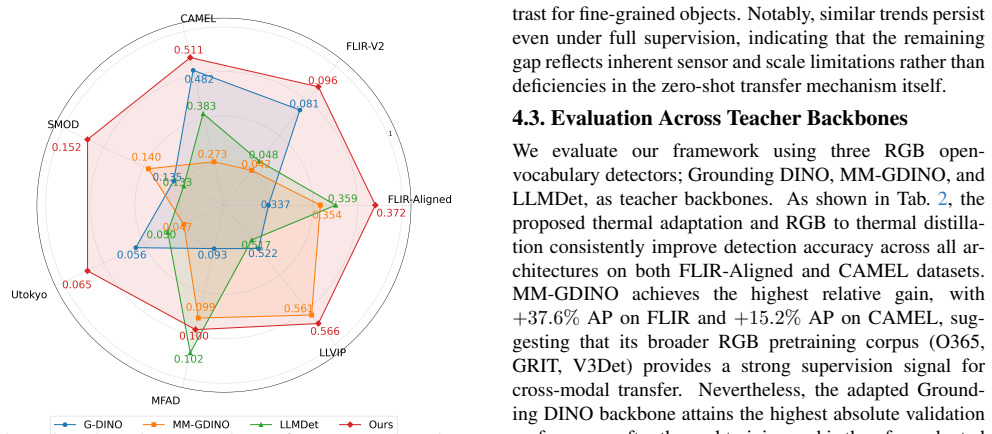
full rationale
The paper's core method creates a synthetic training set by converting an external dataset (GroundingCap-1M) and applies cross-modal distillation from a frozen external RGB teacher; performance gains are reported from benchmark experiments rather than being forced by construction from fitted parameters or self-referential definitions. No self-definitional equations, fitted-input predictions, load-bearing self-citations, or ansatzes that reduce to the target result appear in the provided claims or abstract.
Axiom & Free-Parameter Ledger
free parameters (1)
- loss weighting coefficients
axioms (2)
- domain assumption Paired but unlabeled RGB-thermal images exist and can be used for pseudo-supervision without introducing harmful domain-shift artifacts.
- domain assumption Caption filtering successfully removes all RGB-specific terms while preserving thermal-relevant semantics.
invented entities (2)
-
Thermal-Text Alignment Head
no independent evidence
-
Modality-Fused Cross-Attention module
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Exploring visual prompts for adapting large- scale models
Hyojin Bahng, Ali Jahanian, Swami Sankaranarayanan, and Phillip Isola. Exploring visual prompts for adapting large- scale models.arXiv preprint arXiv:2203.17274, 2022. 2
-
[2]
Thermal image sensing model for robotic planning and search.Sensors, 16(8):1253, 2016
Lidice E Castro Jimenez and Edgar A Mart ´ınez-Garc´ıa. Thermal image sensing model for robotic planning and search.Sensors, 16(8):1253, 2016. 1
work page 2016
-
[3]
Yolo-world: Real-time open-vocabulary object detection
Tianheng Cheng, Lin Song, Yixiao Ge, Wenyu Liu, Xing- gang Wang, and Ying Shan. Yolo-world: Real-time open-vocabulary object detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16901–16911, 2024. 3, 1, 2
work page 2024
-
[4]
Yukyung Choi, Namil Kim, Soonmin Hwang, Kibaek Park, Jae Shin Yoon, Kyounghwan An, and In So Kweon. Kaist multi-spectral day/night data set for autonomous and assisted driving.IEEE Transactions on Intelligent Transportation Systems, 19(3):934–948, 2018. 2
work page 2018
-
[5]
FLIR Thermal Starter Dataset Introduction Version 1.3
FLIR Systems. FLIR Thermal Starter Dataset Introduction Version 1.3. Available for download athttps://www. flir.eu/oem/adas/adas-dataset-form/, 2019. Version 1.3. 2
work page 2019
-
[6]
Shenghao Fu, Qize Yang, Qijie Mo, Junkai Yan, Xihan Wei, Jingke Meng, Xiaohua Xie, and Wei-Shi Zheng. Llmdet: Learning strong open-vocabulary object detectors under the supervision of large language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14987–14997, 2025. 2, 1
work page 2025
-
[7]
On the effectiveness of parameter-efficient fine-tuning
Zihao Fu, Haoran Yang, Anthony Man-Cho So, Wai Lam, Lidong Bing, and Nigel Collier. On the effectiveness of parameter-efficient fine-tuning. InProceedings of the AAAI conference on artificial intelligence, pages 12799–12807,
-
[8]
Thermal cameras and applications: a survey.Machine vision and applications, 25 (1):245–262, 2014
Rikke Gade and Thomas B Moeslund. Thermal cameras and applications: a survey.Machine vision and applications, 25 (1):245–262, 2014. 1
work page 2014
-
[9]
Camel dataset for vi- sual and thermal infrared multiple object detection and track- ing
Evan Gebhardt and Marilyn Wolf. Camel dataset for vi- sual and thermal infrared multiple object detection and track- ing. In2018 15th IEEE international conference on ad- vanced video and signal based surveillance (AVSS), pages 1–6. IEEE, 2018. 2
work page 2018
-
[10]
Domain-adaptive pedestrian detection in thermal images
Tiantong Guo, Cong Phuoc Huynh, and Mashhour Solh. Domain-adaptive pedestrian detection in thermal images. In 2019 IEEE international conference on image processing (ICIP), pages 1660–1664. IEEE, 2019. 2, 1
work page 2019
-
[11]
Hanna H Hamrell and J ¨orgen M Karlholm. Image-to-image translation for improvement of synthetic thermal infrared training data using generative adversarial networks. InAr- tificial Intelligence and Machine Learning in Defense Appli- cations III, pages 61–72. SPIE, 2021. 2
work page 2021
-
[12]
Kai A Horstmann, Maxim Clouser, and Kia Khezeli. Inference-time scaling of diffusion models for infrared data generation.arXiv preprint arXiv:2511.07362, 2025. 2
-
[13]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022. 2, 4
work page 2022
-
[14]
Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, Bharath Hariharan, and Ser-Nam Lim. Vi- sual prompt tuning. InEuropean conference on computer vision, pages 709–727. Springer, 2022. 2
work page 2022
-
[15]
Llvip: A visible-infrared paired dataset for low-light vision, 2021
Xinyu Jia, Chuang Zhu, Minzhen Li, Wenqi Tang, Shengjie Liu, and Wenli Zhou. Llvip: A visible-infrared paired dataset for low-light vision, 2021. 2
work page 2021
-
[16]
Llvip: A visible-infrared paired dataset for low-light vision
Xinyu Jia, Chuang Zhu, Minzhen Li, Wenqi Tang, and Wenli Zhou. Llvip: A visible-infrared paired dataset for low-light vision. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 3496–3504, 2021. 2
work page 2021
-
[17]
Chenchen Jiang, Huazhong Ren, Xin Ye, Jinshun Zhu, Hui Zeng, Yang Nan, Min Sun, Xiang Ren, and Hongtao Huo. Object detection from uav thermal infrared images and videos using yolo models.International Journal of Applied Earth Observation and Geoinformation, 112:102912, 2022. 1
work page 2022
-
[18]
T-rex2: Towards generic object detec- tion via text-visual prompt synergy
Qing Jiang, Feng Li, Zhaoyang Zeng, Tianhe Ren, Shilong Liu, and Lei Zhang. T-rex2: Towards generic object detec- tion via text-visual prompt synergy. InEuropean Conference on Computer Vision, pages 38–57. Springer, 2024. 1, 2
work page 2024
-
[19]
A novel approach for surveillance using vi- sual and thermal images
GD Jones, MA Hodgetts, RE Allsop, N Sumpter, and MA Vicencio-Silva. A novel approach for surveillance using vi- sual and thermal images. InA DERA/IEE Workshop on In- telligent Sensor Processing (Ref. No. 2001/050), pages 9–1. IET, 2001. 1
work page 2001
-
[20]
A spoken language dataset of descrip- tions for speech-based grounded language learning
Gaoussou Youssouf Kebe, Padraig Higgins, Patrick Jenk- ins, Kasra Darvish, Rishabh Sachdeva, Ryan Barron, John Winder, Donald Engel, Edward Raff, Francis Ferraro, and Cynthia Matuszek. A spoken language dataset of descrip- tions for speech-based grounded language learning. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Be...
work page 2021
-
[21]
Frederik S Leira, H ˚akon Hagen Helgesen, Tor Arne Jo- hansen, and Thor I Fossen. Object detection, recognition, and tracking from uavs using a thermal camera.Journal of Field Robotics, 38(2):242–267, 2021. 1
work page 2021
-
[22]
Grounded language-image pre-training
Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jian- wei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, et al. Grounded language-image pre-training. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10965–10975, 2022. 2, 1
work page 2022
-
[23]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014. 3
work page 2014
-
[24]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 3
work page 2023
-
[25]
Pm-adapter: Moe based dynamic denoising fine-tuning for thermal infrared object detection
Haijun Liu, Jun Zhang, Hang Yu, Boya Wei, Jing Nie, Suju Li, and Xichuan Zhou. Pm-adapter: Moe based dynamic denoising fine-tuning for thermal infrared object detection. Neurocomputing, page 131718, 2025. 2
work page 2025
-
[26]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuro- pean conference on computer vision, pages 38–55. Springer,
-
[27]
Dora: Weight-decomposed low-rank adaptation
Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. Dora: Weight-decomposed low-rank adaptation. InForty-first International Conference on Ma- chine Learning, 2024. 4
work page 2024
-
[28]
Thermalsynth: A novel approach for generating synthetic thermal human scenarios
Neelu Madan, Mia Sandra Nicole Siemon, Magnus Kauf- mann Gjerde, Bastian Starup Petersson, Arijus Gro- tuzas, Malthe Aaholm Esbensen, Ivan Adriyanov Nikolov, Mark Philip Philipsen, Kamal Nasrollahi, and Thomas B Moeslund. Thermalsynth: A novel approach for generating synthetic thermal human scenarios. InProceedings of the IEEE/CVF Winter Conference on App...
work page 2023
-
[29]
Visual modality prompt for adapting vision-language object detectors
Heitor R Medeiros, Atif Belal, Srikanth Muralidharan, Eric Granger, and Marco Pedersoli. Visual modality prompt for adapting vision-language object detectors. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 2172–2182, 2025. 2
work page 2025
-
[30]
Matthias Minderer, Alexey Gritsenko, and Neil Houlsby. Scaling open-vocabulary object detection.Advances in Neu- ral Information Processing Systems, 36:72983–73007, 2023. 2
work page 2023
-
[31]
Sstn: Self- supervised domain adaptation thermal object detection for autonomous driving
Farzeen Munir, Shoaib Azam, and Moongu Jeon. Sstn: Self- supervised domain adaptation thermal object detection for autonomous driving. In2021 IEEE/RSJ international con- ference on intelligent robots and systems (IROS), pages 206–
-
[32]
Xuran Pan, Tianzhu Ye, Dongchen Han, Shiji Song, and Gao Huang. Contrastive language-image pre-training with knowledge graphs.Advances in Neural Information Process- ing Systems, 35:22895–22910, 2022. 2
work page 2022
-
[33]
Paranjape, Celso de Melo, and Vishal M
Jay N. Paranjape, Celso de Melo, and Vishal M. Patel. F- vita: Foundation model guided visible to thermal translation,
-
[34]
F- vita: Foundation model guided visible to thermal translation
Jay N Paranjape, Celso de Melo, and Vishal M Patel. F- vita: Foundation model guided visible to thermal translation. arXiv preprint arXiv:2504.02801, 2025. 2
-
[35]
Jonas Rauch, Christopher Doer, and Gert F Trommer. Object detection on thermal images for unmanned aerial vehicles us- ing domain adaption through fine-tuning. In2021 28th Saint Petersburg International Conference on Integrated Naviga- tion Systems (ICINS), pages 1–4. IEEE, 2021. 2
work page 2021
-
[36]
Christopher Dahlin Rodin, Luciano Netto de Lima, Fabio Augusto de Alcantara Andrade, Diego Barreto Had- dad, Tor Arne Johansen, and Rune Storvold. Object clas- sification in thermal images using convolutional neural net- works for search and rescue missions with unmanned aerial systems. In2018 International Joint Conference on Neural Networks (IJCNN), pag...
work page 2018
-
[37]
Springer Science & Business Media, 2012
Luc Steels and Manfred Hild.Language grounding in robots. Springer Science & Business Media, 2012. 3
work page 2012
-
[38]
Language grounding with 3d ob- jects
Jesse Thomason, Mohit Shridhar, Yonatan Bisk, Chris Pax- ton, and Luke Zettlemoyer. Language grounding with 3d ob- jects. InConference on Robot Learning, pages 1691–1701. PMLR, 2022. 3
work page 2022
-
[39]
Meta-uda: Unsupervised domain adaptive thermal object detection using meta-learning
Vibashan Vs, Domenick Poster, Suya You, Shuowen Hu, and Vishal M Patel. Meta-uda: Unsupervised domain adaptive thermal object detection using meta-learning. Inproceed- ings of the IEEE/CVF winter conference on applications of computer vision, pages 1412–1423, 2022. 2
work page 2022
-
[40]
V3det: Vast vocabulary visual detection dataset
Jiaqi Wang, Pan Zhang, Tao Chu, Yuhang Cao, Yujie Zhou, Tong Wu, Bin Wang, Conghui He, and Dahua Lin. V3det: Vast vocabulary visual detection dataset. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 19844–19854, 2023. 3
work page 2023
-
[41]
Jiuhong Xiao, Roshan Nayak, Ning Zhang, Daniel Tortei, and Giuseppe Loianno. Thermalgen: Style-disentangled flow-based generative models for rgb-to-thermal image translation.arXiv preprint arXiv:2509.24878, 2025. 2
-
[42]
Filip: Fine-grained interactive language-image pre-training.ArXiv, abs/2111.07783, 2021
Lewei Yao, Runhui Huang, Lu Hou, Guansong Lu, Minzhe Niu, Hang Xu, Xiaodan Liang, Zhenguo Li, Xin Jiang, and Chunjing Xu. Filip: Fine-grained interactive language-image pre-training.arXiv preprint arXiv:2111.07783, 2021. 2
-
[43]
Thermal image tracking for search and res- cue missions with a drone.Drones, 8(2):53, 2024
Seokwon Yeom. Thermal image tracking for search and res- cue missions with a drone.Drones, 8(2):53, 2024. 1
work page 2024
-
[44]
Adapter is all you need for tuning visual tasks.arXiv preprint arXiv:2311.15010, 2023
Dongshuo Yin, Leiyi Hu, Bin Li, and Youqun Zhang. Adapter is all you need for tuning visual tasks.arXiv preprint arXiv:2311.15010, 2023. 2
-
[45]
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M Ni, and Heung-Yeung Shum. Dino: Detr with improved denoising anchor boxes for end-to-end object detection.arXiv preprint arXiv:2203.03605, 2022. 3
work page internal anchor Pith review arXiv 2022
-
[46]
Conditional prompt learning for vision-language mod- els
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Conditional prompt learning for vision-language mod- els. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 16816–16825,
-
[47]
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models.In- ternational Journal of Computer Vision, 130(9):2337–2348,
-
[48]
2 Thermal-Det: Language-Guided Cross-Modal Distillation for Open-Vocabulary Thermal Object Detection Supplementary Material S1. Implementation Details We build our framework on Grounding DINO, extending it with Thermal Adapters and TTAH for thermal domain adaptation. All experiments use MMDetection v3.2 with mixed precision and gradient checkpointing. A p...
-
[49]
The detector processesp4andp5encoder features (resized to27×27and20×20) concatenated into one to- ken sequence. The CLIP text encoder is frozen, while the adapters, detection head, and TTAH are optimized jointly with detection, distillation, and alignment losses. Training runs on8×RTX A6000 GPUs with a total batch size of 16 for 150K iterations. We use Ad...
-
[50]
Zero-shot detection results on thermal datasets FLIR-Aligned, FLIR-V2, CAMEL, and Utokyo
used self-supervised and adversarial methods to re- duce modality gaps, while ThermalSynth [28] and Ham- Table S2. Zero-shot detection results on thermal datasets FLIR-Aligned, FLIR-V2, CAMEL, and Utokyo. Method FLIR-Aligned FLIR-V2 CAMEL Utokyo AP AP 50 AP75 AP AP 50 AP75 AP AP 50 AP75 AP AP 50 AP75 GLIP 0.251 0.471 0.226 0.025 0.041 0.028 0.186 0.324 0....
-
[51]
and ThermalGen [41], achieve semantically consistent visible-to-thermal synthesis, marking a shift toward scal- able cross-modal generation. Yet, most approaches treat thermal adaptation and semantic grounding separately, and our work unifies them through synthetic supervision, lan- guage alignment, and cross-modal distillation for zero-shot thermal detec...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.