Recognition: no theorem link
FormalRewardBench: A Benchmark for Formal Theorem Proving Reward Models
Pith reviewed 2026-05-12 04:17 UTC · model grok-4.3
The pith
A new benchmark shows frontier LLMs judge formal proofs more accurately than specialized theorem provers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FormalRewardBench is the first benchmark for reward models in formal theorem proving with Lean 4. It consists of 250 preference pairs formed by pairing correct proofs with incorrect variants generated through five expert-curated error injection strategies. Evaluation across frontier LLMs, judge LLMs, general-purpose LLMs, and specialized theorem provers shows frontier LLMs achieve the highest performance at 59.8 percent while specialized theorem provers perform the worst at 24.4 percent, indicating that theorem proving ability does not transfer to proof evaluation.
What carries the argument
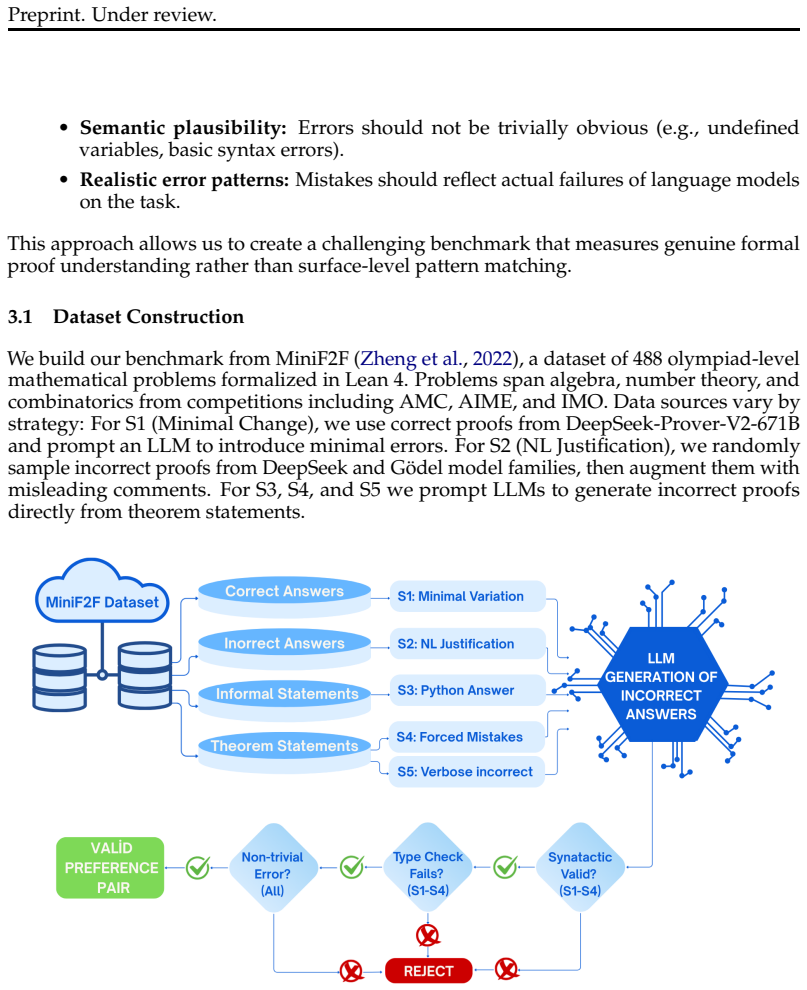
The collection of 250 preference pairs created by applying five error injection strategies (forced mistakes, minimal single-point variations, verbose incorrect proofs, natural language justification, and Python code injection) to correct Lean 4 proofs.
If this is right
- Reward models for formal proofs can be compared directly on preference pairs without running full RL training loops.
- Frontier LLMs can act as practical reward models to guide training of better theorem provers.
- Specialized theorem proving models need separate development to become reliable proof evaluators.
- Different error injection strategies pose varying levels of difficulty, with most remaining challenging for current models.
Where Pith is reading between the lines
- LLM-based reward models could give training signals on partial progress that binary verification cannot provide.
- The observed gap between generation and evaluation skills suggests hybrid models that combine both abilities may be worth testing.
- Extending the benchmark with errors actually produced by model search traces would test how well the current pairs represent real failure modes.
- If reward models trained on this data improve prover performance, the benchmark could become a standard test for future reward model work.
Load-bearing premise
The five expert-curated error injection strategies produce incorrect proofs that match the kinds of mistakes actual models make during proof attempts.
What would settle it
Training a theorem prover with a reward model that scores highest on the benchmark and measuring whether it solves more new theorems than one trained only with binary verification signals.
Figures


read the original abstract
Recent neural theorem provers use reinforcement learning with verifiable rewards (RLVR), where proof assistants provide binary correctness signals. While verifiable rewards are cheap and scalable without reward hacking issues, they suffer from sparse credit assignment: models receive no learning signal from difficult problems where partial progress goes unrewarded. This motivates learned reward models that can evaluate proof quality beyond binary verification. However, comparing reward models is challenging since it typically requires expensive RL training ablations. To address this, we introduce \textbf{FormalRewardBench}, the first benchmark for evaluating reward models in formal theorem proving with Lean 4. Our benchmark consists of 250 preference pairs where correct proofs are paired with incorrect variants generated through five expert curated error injection strategies: forced mistakes, minimal single-point variations, verbose incorrect proofs, natural language justification, and Python code injection. We evaluate frontier LLMs (e.g., Claude Opus 4.5), judge LLMs (e.g., CompassJudger-1-14B), general-purpose LLMs (e.g., Qwen2.5-72B-Instruct), and specialized theorem proving models (e.g., DeepSeek-Prover-V2-7B). Our results reveal that frontier LLMs achieve the highest performance (59.8\%) while specialized theorem provers perform the worst (24.4\%), suggesting that theorem proving ability does not transfer to proof evaluation. We provide further insights on various error injection mechanisms, highlighting the challenging nature of most injection mechanisms. We release \textbf{FormalRewardBench} publicly to encourage more research on developing reward models in formal mathematics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FormalRewardBench, the first benchmark for reward models in formal theorem proving with Lean 4. It consists of 250 preference pairs pairing correct proofs with incorrect variants generated via five expert-curated error injection strategies (forced mistakes, minimal single-point variations, verbose incorrect proofs, natural-language justification, and Python code injection). The authors evaluate frontier LLMs (e.g., Claude Opus 4.5 at 59.8%), judge LLMs, general-purpose LLMs, and specialized theorem provers (e.g., DeepSeek-Prover-V2-7B at 24.4%), concluding that frontier LLMs perform best while specialized provers perform worst, suggesting that theorem-proving ability does not transfer to proof evaluation. They release the benchmark publicly and provide insights on the relative difficulty of the injection mechanisms.
Significance. If the benchmark construction is validated, this work provides a scalable, low-cost alternative to full RL training ablations for comparing reward models in neural theorem proving. The empirical finding that general frontier LLMs substantially outperform specialized provers on preference judgments offers a concrete signal for future reward model design. The public release of the 250-pair dataset is a clear strength that enables reproducible follow-up work.
major comments (2)
- [Benchmark construction] Benchmark construction section: the five error injection strategies are presented as producing the incorrect proofs for the 250 pairs, but no comparison is reported between the distribution of these synthetic errors and the actual incorrect proofs generated by the evaluated models (frontier LLMs or specialized provers). This representativeness assumption is load-bearing for the central interpretation that the 59.8% vs. 24.4% gap demonstrates lack of transfer from proving to evaluation.
- [Results] Results section (and abstract): performance figures such as 59.8% and 24.4% are reported without any mention of how the 250 pairs were validated (e.g., expert review process), inter-annotator agreement, or statistical tests (e.g., McNemar or bootstrap) for the differences across model categories. With only 250 pairs, the absence of these details leaves the reliability of the headline comparison open to methodological questions.
minor comments (2)
- [Abstract] The abstract and introduction could more explicitly state the total number of unique theorems underlying the 250 pairs and whether multiple error types were applied per theorem.
- [Results] Table or figure presenting per-strategy accuracies would benefit from error bars or per-model breakdowns to clarify which injection mechanisms drive the overall gap.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions to improve the manuscript.
read point-by-point responses
-
Referee: Benchmark construction section: the five error injection strategies are presented as producing the incorrect proofs for the 250 pairs, but no comparison is reported between the distribution of these synthetic errors and the actual incorrect proofs generated by the evaluated models (frontier LLMs or specialized provers). This representativeness assumption is load-bearing for the central interpretation that the 59.8% vs. 24.4% gap demonstrates lack of transfer from proving to evaluation.
Authors: We acknowledge that comparing the distribution of our expert-curated synthetic errors to the actual error patterns produced by the evaluated models would strengthen the transferability interpretation. The benchmark is intentionally constructed around diverse, expert-defined error types (forced mistakes, minimal variations, verbose proofs, natural-language justifications, and code injection) to create challenging preference pairs that test reward model robustness beyond binary verification. The observed performance gap still provides evidence that specialized provers underperform on proof evaluation tasks relative to frontier LLMs. In the revision, we will add a dedicated limitations paragraph clarifying the scope of the benchmark, noting the absence of a direct distributional comparison, and recommending future work to collect model-generated incorrect proofs for such analysis. revision: partial
-
Referee: Results section (and abstract): performance figures such as 59.8% and 24.4% are reported without any mention of how the 250 pairs were validated (e.g., expert review process), inter-annotator agreement, or statistical tests (e.g., McNemar or bootstrap) for the differences across model categories. With only 250 pairs, the absence of these details leaves the reliability of the headline comparison open to methodological questions.
Authors: We agree that explicit details on validation and statistical rigor are necessary for a benchmark paper. All 250 pairs were constructed and manually validated by Lean 4 experts to confirm that the injected variants are indeed invalid while preserving the original theorem statement. We will expand the benchmark construction section to describe this expert review process in detail. Additionally, we will report inter-annotator agreement metrics (where multiple reviewers assessed subsets) and include statistical tests such as bootstrap confidence intervals and McNemar's test for pairwise model comparisons in the results section and abstract to quantify the reliability of the reported differences. revision: yes
Circularity Check
No significant circularity in empirical benchmark construction and evaluation
full rationale
The paper constructs FormalRewardBench from 250 preference pairs using five expert-curated error injection strategies and reports direct empirical accuracies for different model classes on those pairs. No equations, derivations, fitted parameters, or predictions appear; the headline result (59.8% vs 24.4%) is a straightforward measurement on the fixed dataset rather than a quantity forced by the paper's own definitions or self-citations. The work contains no self-definitional steps, fitted-input predictions, uniqueness theorems, or ansatzes smuggled via citation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert-curated error injection strategies generate incorrect proofs that meaningfully test reward model capabilities.
Reference graph
Works this paper leans on
-
[1]
Olympiad- level formal mathematical reasoning with reinforcement learning
URLhttps://arxiv.org/abs/2410.16256. Leonardo de Moura and Sebastian Ullrich. The Lean 4 theorem prover and programming language.https://leanprover.github.io/, 2021. Accessed: 2024. Zhiyuan Fan, Dadi Guo, Zhitao He, Elias Stengel-Eskin, Mohit Bansal, and Yi R. Fung. Proof-verifier: Enabling reinforcement learning from verifiable rewards for mathematical t...
-
[2]
URLhttps://openreview.net/forum?id=MwU2SGLKpS. Saumya Malik, Valentina Pyatkin, Sander Land, Jacob Morrison, Noah A. Smith, Hannaneh Hajishirzi, and Nathan Lambert. Rewardeval: Advancing reward model evaluation. InThe Fourteenth International Conference on Learning Representations, 2026. URL https: //openreview.net/forum?id=fb0G86Dewb. Tobias Nipkow, Lawr...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2026
-
[3]
URLhttps://arxiv.org/abs/2503.17181. Haiming Wang, Mert Unsal, Xiaohan Lin, Mantas Baksys, Junqi Liu, Marco Dos Santos, Flood Sung, Marina Vinyes, Zhenzhe Ying, Zekai Zhu, Jianqiao Lu, Hugues de Saxcé, Bolton Bailey, Chendong Song, Chenjun Xiao, Dehao Zhang, Ebony Zhang, Frederick Pu, Han Zhu, Jiawei Liu, Jonas Bayer, Julien Michel, Longhui Yu, Léo Dreyfu...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2025.emnlp-main 2025
-
[4]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
URLhttps://aclanthology.org/2025.emnlp-main.103/. Huajian Xin, Z. Z. Ren, Junxiao Song, Zhihong Shao, Wanjia Zhao, Haocheng Wang, Bo Liu, Liyue Zhang, Xuan Lu, Qiushi Du, Wenjun Gao, Haowei Zhang, Qihao Zhu, Dejian Yang, Zhibin Gou, Z. F. Wu, Fuli Luo, and Chong Ruan. Deepseek-prover-v1.5: Harnessing proof assistant feedback for reinforcement learning and...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2025.emnlp-main.712 2025
-
[5]
and Isabelle (Nipkow et al., 2002) that share similar tactic-based proof construction. B Background: Reward Model Formulations Given a prompt x and two candidate responses y1 and y2, reward models determine which response is preferred. LLM-as-Judgedirectly prompts a language model to compare two responses and output a preference judgmentI∈ {1, 2}. Generat...
work page 2002
-
[6]
Incorrect application of tactics (simp, rw, apply)
-
[7]
Wrong hypothesis selection or variable scoping
-
[8]
Mismatched term types or implicit argument errors
-
[9]
Incomplete case analysis or missing edge cases
-
[10]
Incorrect use of induction hypotheses
-
[11]
Wrong lemma instantiation or theorem application
-
[12]
Scope errors with bound variables
-
[13]
Input {theorem} Output Output only the completed proof, starting afterby
Misunderstanding proof state after tactic application Rules • Use valid Lean 4 syntax • Make errors from automated proof generation • Focus on formal reasoning mistakes, not basic math errors • The proof should appear plausible at first glance User Complete the following Lean 4 theorem with an INCORRECT proof containing a typical proof generation error. I...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.