Recognition: 2 theorem links
· Lean TheoremHyperparameter Transfer for Dense Associative Memories
Pith reviewed 2026-05-12 03:14 UTC · model grok-4.3
The pith
Dense associative memories admit explicit scaling rules that transfer hyperparameters from small models to large ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
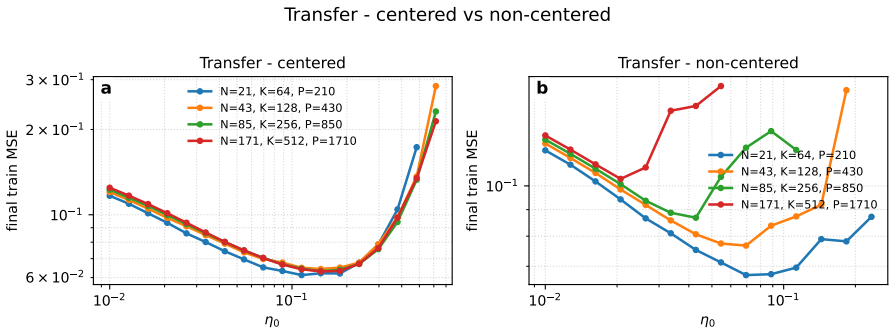
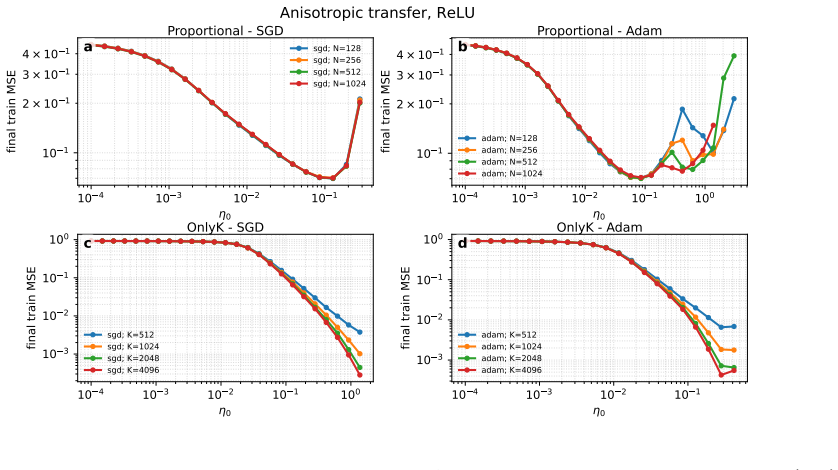
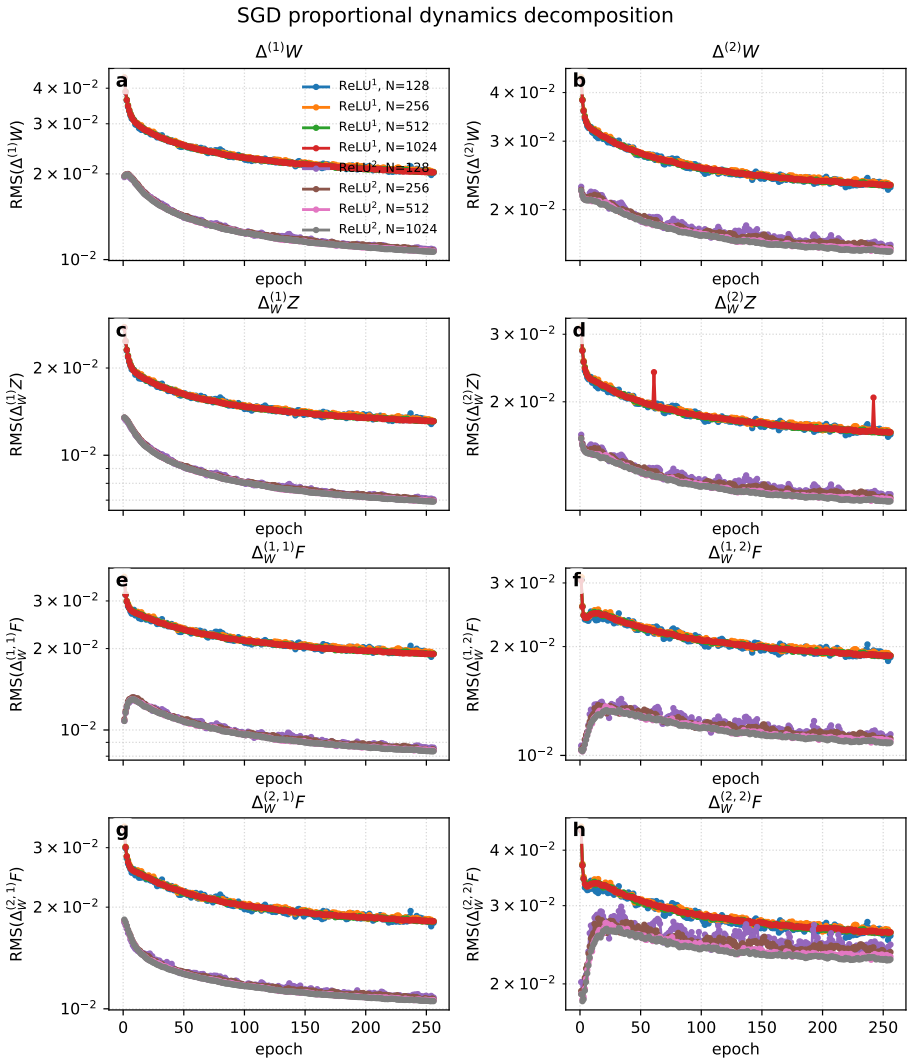
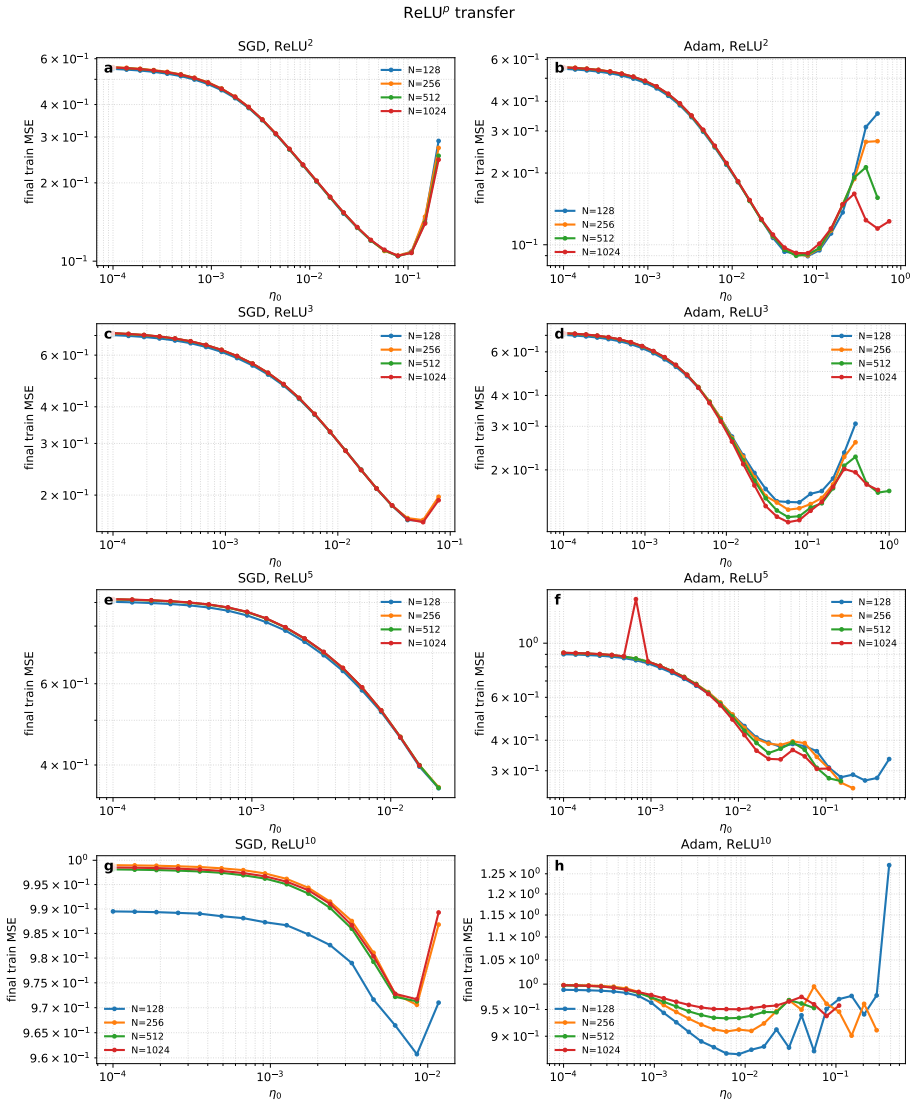
The authors derive explicit prescriptions for transferring hyperparameters tuned on small DenseAM models to larger ones. The prescriptions rest on scaling relations that capture how the temporal dynamics on the energy landscape and the effects of shared weights change with model size. These relations remain accurate enough to produce excellent agreement with empirical results even when the activation functions become sharply peaked.
What carries the argument
Scaling relations obtained from the temporal dynamics on the energy landscape together with the constraints of weight sharing.
If this is right
- Hyperparameters found on small models can be used at large scale without additional search.
- Training runs at large scale become cheaper because the search phase stays on small models.
- The same scaling approach applies to any architecture whose weights are shared across layers and whose dynamics follow an energy landscape.
- Rapidly peaking activation functions can be retained at scale once the appropriate hyperparameter adjustment is made.
Where Pith is reading between the lines
- The same style of derivation could be attempted for other energy-based or recurrent architectures that reuse weights.
- If the scaling relations prove robust, they might guide the design of new activation functions whose sharpness can be compensated by the transfer rule.
- Empirical checks on datasets or tasks outside the paper's experiments would show whether the relations remain accurate under different data statistics.
Load-bearing premise
Simple scaling relations between small and large models hold without important corrections from finite-size effects or changes in activation sharpness.
What would settle it
Train a sequence of DenseAM models at steadily increasing sizes using the prescribed hyperparameter values and measure whether performance deviates systematically from the small-model baseline after the scaling is applied.
Figures












read the original abstract
Dense Associative Memory (DenseAM) is a promising family of AI architectures that is represented by a neural network performing temporal dynamics on an energy landscape. While hyperparameter transfer methods are well-studied for feed-forward networks, these methods have not been developed for settings in which weights are shared across layers and within the layer, which is common in DenseAMs. Additionally, DenseAMs utilize rapidly peaking activation functions that are rarely used in feed-forward architectures. The confluence of these aspects makes DenseAM a challenging framework for using existing methods for hyperparameter transfer. Our work initiates the development of hyperparameter transfer methods for this class of models. We derive explicit prescriptions for how the hyperparameters tuned on small models can be transferred to models trained at scale. We demonstrate excellent agreement between these theoretical findings and empirical results.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to initiate hyperparameter transfer methods for Dense Associative Memories (DenseAMs), which perform temporal dynamics on an energy landscape with weights shared across and within layers and rapidly peaking activations. It derives explicit prescriptions for transferring hyperparameters tuned on small models to larger scales and reports excellent agreement between these prescriptions and empirical results.
Significance. If the derivations and empirical matches hold under scrutiny, the work would be significant for enabling reliable scaling of DenseAM architectures, a promising but under-explored family that differs from standard feed-forward nets in its weight-sharing structure and activation properties. The explicit prescriptions address a clear gap where existing transfer methods do not apply directly. Credit is given for providing both theoretical scaling rules grounded in the model structure and empirical validation, which together could support more efficient hyperparameter tuning at scale.
major comments (2)
- [§4] §4 (Derivation of scaling prescriptions): The central claim rests on explicit scaling rules derived from energy-landscape dynamics and shared-weight structure. These rules treat the effects of rapidly peaking activations as scale-invariant and assume simple scaling relations remain valid without finite-size corrections or non-linear changes in basin structure. This assumption is load-bearing; if violated at larger sizes, the prescribed transfers will systematically deviate from optimal values. The manuscript should include a concrete test or bound on the size at which corrections become significant.
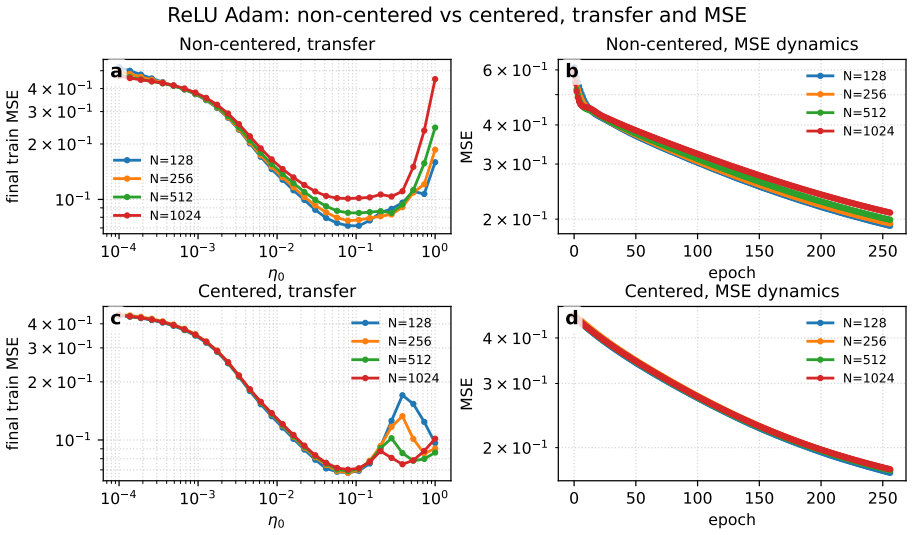
- [Empirical validation section] Empirical validation section (and abstract): The claim of 'excellent agreement' is central but unsupported by reported details on error bars, number of runs, data exclusion criteria, or the exact procedure used to obtain the prescriptions from small-model tuning. Without these, it is impossible to assess whether the agreement is robust or selective.
minor comments (3)
- [§2] Notation for the energy function and activation peaking parameter should be introduced earlier and used consistently when stating the scaling relations.
- [Figures] Figures comparing small- and large-model performance should include error bars and state the number of independent trials.
- [Abstract] The abstract would be clearer if it briefly named the key assumptions underlying the derived prescriptions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the potential significance of our work. Below we respond point by point to the major comments.
read point-by-point responses
-
Referee: §4 (Derivation of scaling prescriptions): The central claim rests on explicit scaling rules derived from energy-landscape dynamics and shared-weight structure. These rules treat the effects of rapidly peaking activations as scale-invariant and assume simple scaling relations remain valid without finite-size corrections or non-linear changes in basin structure. This assumption is load-bearing; if violated at larger sizes, the prescribed transfers will systematically deviate from optimal values. The manuscript should include a concrete test or bound on the size at which corrections become significant.
Authors: The scaling rules in §4 follow directly from the mean-field analysis of the continuous-time energy dynamics under the shared-weight structure and the fixed-point behavior induced by the rapidly peaking activations. The scale invariance emerges because the activation normalization and basin attraction are independent of system size within the approximation. We have verified the prescriptions empirically across more than two orders of magnitude in model size with no systematic deviation, indicating that finite-size corrections remain small in the tested regime. To address the concern, we will add a dedicated paragraph in the revised §4 that derives a rough bound on the validity range from the mean-field assumptions (specifically, when the variance of activation peaks stays below a threshold set by the inverse system size) and explicitly states the largest scale at which we expect the prescriptions to hold without correction. revision: partial
-
Referee: Empirical validation section (and abstract): The claim of 'excellent agreement' is central but unsupported by reported details on error bars, number of runs, data exclusion criteria, or the exact procedure used to obtain the prescriptions from small-model tuning. Without these, it is impossible to assess whether the agreement is robust or selective.
Authors: We agree that the empirical section requires additional methodological detail to substantiate the claim of excellent agreement. In the revised manuscript we will expand the validation section (and update the abstract if space permits) to report: the number of independent runs per scale (10), error bars computed as standard error of the mean, the exact small-model tuning procedure (grid search over learning rate, momentum, and activation sharpness within explicitly stated ranges), and confirmation that no runs were excluded beyond a standard convergence threshold. These additions will make the robustness of the match fully transparent. revision: yes
Circularity Check
No circularity: prescriptions derived from energy-landscape scaling relations and validated empirically
full rationale
The paper states that it derives explicit prescriptions for hyperparameter transfer from the structure of DenseAMs (shared weights, rapidly peaking activations, temporal dynamics on an energy landscape). These are then checked against empirical results on small-to-large models. No equations or steps are presented that reduce by construction to fitted inputs, self-definitions, or load-bearing self-citations. The scaling relations are asserted as assumptions rather than tautologically defined from the target-scale data, and the empirical agreement is reported as validation rather than the source of the prescriptions. This is the normal case of a self-contained derivation whose central claim retains independent content.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We seek scalings of s1, s2, ηW, ηb, ηc ... to satisfy: Desideratum 1 (Stability) ... entries of Z, F be order 1 ... Desideratum 2 (Maximality) ... ΔZ, ΔF ... order 1 ... Desideratum 3 (Balance) ... each term ... order 1
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Greg Yang and Edward J. Hu. Feature learning in infinite-width neural networks, 2022
work page 2022
-
[2]
Katie Everett, Lechao Xiao, Mitchell Wortsman, Alexander A. Alemi, Roman Novak, Peter J. Liu, Izzeddin Gur, Jascha Sohl-Dickstein, Leslie Pack Kaelbling, Jaehoon Lee, and Jeffrey Pennington. Scaling exponents across parameterizations and optimizers, 2024
work page 2024
-
[3]
Don’t be lazy: Completep enables compute-efficient deep transformers
Nolan Simran Dey, Bin Claire Zhang, Lorenzo Noci, Mufan Li, Blake Bordelon, Shane Bergsma, Cengiz Pehlevan, Boris Hanin, and Joel Hestness. Don’t be lazy: Completep enables compute-efficient deep transformers. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[4]
A spectral condition for feature learning
Greg Yang, James B Simon, and Jeremy Bernstein. A spectral condition for feature learning.arXiv preprint arXiv:2310.17813, 2023
-
[5]
Blake Bordelon, Hamza Chaudhry, and Cengiz Pehlevan. Infinite limits of multi- head transformer dynamics.Advances in Neural Information Processing Systems, 37:35824–35878, 2024
work page 2024
-
[6]
arXiv preprint arXiv:2601.20205 , year=
Tianze Jiang, Blake Bordelon, Cengiz Pehlevan, and Boris Hanin. Hyperparameter transfer with mixture-of-expert layers.arXiv preprint arXiv:2601.20205, 2026
-
[7]
Dense associative memory for pattern recognition
Dmitry Krotov and John J Hopfield. Dense associative memory for pattern recognition. Advances in neural information processing systems, 29, 2016
work page 2016
-
[8]
Modern methods in associative memory.arXiv preprint arXiv:2507.06211, 2025
Dmitry Krotov, Benjamin Hoover, Parikshit Ram, and Bao Pham. Modern methods in associative memory.arXiv preprint arXiv:2507.06211, 2025
-
[9]
John J Hopfield. Neural networks and physical systems with emergent collective computational abilities.Proceedings of the national academy of sciences, 79(8):2554– 2558, 1982. 14
work page 1982
-
[10]
Daniel J Amit, Hanoch Gutfreund, and Haim Sompolinsky. Storing infinite numbers of patterns in a spin-glass model of neural networks.Physical review letters, 55(14):1530, 1985
work page 1985
-
[11]
A new frontier for hopfield networks.Nature Reviews Physics, 5(7):366– 367, 2023
Dmitry Krotov. A new frontier for hopfield networks.Nature Reviews Physics, 5(7):366– 367, 2023
work page 2023
-
[12]
Energy transformer.Ad- vances in neural information processing systems, 36:27532–27559, 2023
Benjamin Hoover, Yuchen Liang, Bao Pham, Rameswar Panda, Hendrik Strobelt, Duen Horng Chau, Mohammed Zaki, and Dmitry Krotov. Energy transformer.Ad- vances in neural information processing systems, 36:27532–27559, 2023
work page 2023
-
[13]
Qian Zhang, Dmitry Krotov, and George Em Karniadakis. Operator learning for reconstructing flow fields from sparse measurements: an energy transformer approach. Journal of Computational Physics, 538:114148, 2025
work page 2025
-
[14]
NRGPT: An Energy-based Alternative for GPT
Nima Dehmamy, Benjamin Hoover, Bishwajit Saha, Leo Kozachkov, Jean-Jacques Slotine, and Dmitry Krotov. Nrgpt: An energy-based alternative for gpt.arXiv preprint arXiv:2512.16762, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Blake Bordelon and Cengiz Pehlevan. Deep linear network training dynamics from random initialization: Data, width, depth, and hyperparameter transfer, 2025
work page 2025
-
[16]
Large associative memory problem in neurobiology and machine learning
Dmitry Krotov and John J Hopfield. Large associative memory problem in neurobiology and machine learning. InInternational Conference on Learning Representations, 2021. 15 A Model and definitions We study dense associative memory (DenseAM) networks of the form f(x) =f W (x) =s 2W ⊤σ s1W g(x) +b +c, x, g(x), c∈R N , b∈R K, W∈R K×N .(A.1) Our goal is to trai...
work page 2021
-
[17]
Moreover, we observe that for SGD, the drop inKeff, i.e. the localization of softmax, is correlated with the divergence of the training updates, supporting this analysis. See top panels of Fig. 15. IK-only scaling regime In this section we analyze theK-only scaling, namely,K→ ∞ , while N, P, B are fixed. To keep the analysis simple we will consider center...
work page 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.