Recognition: 1 theorem link
· Lean TheoremDetRefiner: Model-Agnostic Detection Refinement with Feature Fusion Transformer
Pith reviewed 2026-05-12 03:20 UTC · model grok-4.3
The pith
DetRefiner refines open-vocabulary object detections by fusing global and local features in a lightweight Transformer to recalibrate scores without retraining the base model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
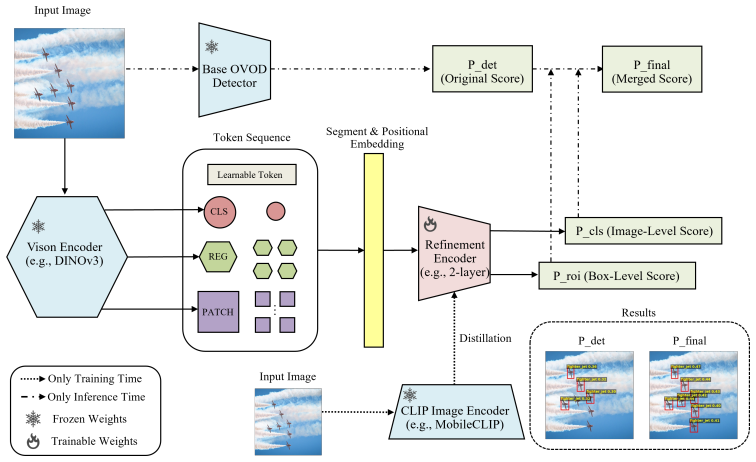
DetRefiner is a model-agnostic plug-and-play module that fuses global image features and patch-level features inside a lightweight Transformer encoder to produce a class vector and patch vectors, infers attribute reliability from those vectors, and merges auxiliary calibration scores with the base detector's scores to produce refined final confidences, all while requiring neither internal access to the detector nor any retraining of it.
What carries the argument
A lightweight Transformer encoder that fuses global image features and patch-level features to produce a class vector and patch vectors from which attribute reliability is inferred for recalibrating base detection scores.
If this is right
- Multiple existing OVOD models receive consistent gains on COCO, LVIS, ODinW13, and Pascal VOC.
- Improvements reach up to +10.1 AP on novel categories that the base model has not seen during training.
- Refinement occurs at inference using only the base detector's final predictions, with no need for internal feature access.
- The refiner can be trained separately from any base model, enabling reuse across different detectors.
Where Pith is reading between the lines
- The separation of training suggests that future improvements in foundational feature extractors could be plugged in without retraining the entire detection pipeline.
- The same global-local fusion pattern could be tested on related tasks such as open-vocabulary instance segmentation where context integration is also limited.
- Because the refiner acts only on predictions, it could be stacked with other post-processing calibration methods to compound gains on rare or unseen classes.
Load-bearing premise
The method assumes that attribute reliability computed solely from the Transformer's class and patch vectors can be trusted to improve the base detector's scores even though the refiner never receives any internal features from the detector.
What would settle it
Apply DetRefiner to any strong OVOD baseline, compute average precision on novel categories in a standard benchmark such as LVIS or ODinW13, and check whether the refined scores produce lower or equal AP than the unchanged baseline; if performance does not rise, the recalibration step is falsified.
Figures




read the original abstract
Open-vocabulary object detection (OVOD) aims to detect both seen and unseen categories, yet existing methods often struggle to generalize to novel objects due to limited integration of global and local contextual cues. We propose DetRefiner, a simple yet effective plug-and-play framework that learns to fuse global and local features to refine open-vocabulary detection. DetRefiner processes global image features and patch-level image features from foundational models (e.g., DINOv3) through a lightweight Transformer encoder. The encoder produces a class vector capturing image-level attributes and patch vectors representing local region attributes, from which attribute reliability is inferred to recalibrate the base model's confidence. Notably, DetRefiner is trained independently of the base OVOD model, requiring neither access to its internal features nor retraining. At inference, it operates solely on the base detector's predictions, producing auxiliary calibration scores that are merged with the base detector's scores to yield the final refined confidence. Despite this simplicity, DetRefiner consistently enhances multiple OVOD models across COCO, LVIS, ODinW13, and Pascal VOC, achieving gains of up to +10.1 AP on novel categories. These results highlight that learning to fuse global and local representations offers a powerful and general mechanism for advancing open-world object detection. Our codes and models are available at https://github.com/hitachi-rd-cv/detrefiner.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DetRefiner, a plug-and-play, model-agnostic module for refining open-vocabulary object detection (OVOD). A lightweight Transformer encoder fuses global image features and patch-level features extracted from DINOv3 to produce a class vector (image-level attributes) and patch vectors (local region attributes); attribute reliability is then inferred from these vectors to generate auxiliary calibration scores that are merged with the base detector's output confidences. The module is trained independently of any base OVOD model, requires no access to its internal features or logits, and is evaluated on COCO, LVIS, ODinW13, and Pascal VOC, where it reportedly yields consistent gains (up to +10.1 AP on novel categories) across multiple OVOD backbones.
Significance. If the reported gains are reproducible and the reliability signal generalizes, the work supplies a lightweight, post-hoc refinement strategy that leverages external foundational-model features without retraining or internal access. This could be a practical contribution to open-world detection. The public release of code and models is a clear strength that supports verification.
major comments (3)
- [Method section] Method section (around the description of the Transformer encoder and reliability head): the manuscript provides no equations, pseudocode, or explicit formulation for how the class vector and patch vectors are mapped to an attribute reliability score, nor for how the auxiliary calibration scores are merged with the base detector's scores. This formulation is load-bearing for the central claim that DINOv3-derived reliability can correct miscalibrations on novel classes without any base-model signals.
- [Experimental section] Experimental section and associated tables: the abstract and results claim consistent improvements of up to +10.1 AP on novel categories across multiple OVOD models and four datasets, yet no ablation studies, baseline comparisons (e.g., simple score averaging or other post-hoc recalibrators), error bars, or statistical significance tests are referenced. Without these, it is impossible to determine whether the gains arise from the proposed feature-fusion mechanism or from other factors.
- [Training objective paragraph] Training objective paragraph: the loss used to train the reliability head on seen data is not specified. Because DetRefiner never observes the base model's failure modes on novel objects, it is unclear whether the learned reliability signal aligns with the specific miscalibrations that the merging step is intended to correct.
minor comments (3)
- [Abstract] The abstract would benefit from a one-sentence statement of the Transformer depth/width and the exact merging formula (even if high-level).
- [Figures] Figure captions and the architecture diagram should explicitly label the inputs (DINOv3 global/patch features) and outputs (reliability scores) to match the text description.
- [Related work] A short related-work paragraph contrasting DetRefiner with prior post-hoc calibration or feature-fusion methods for detection would help situate the contribution.
Simulated Author's Rebuttal
We are grateful to the referee for the detailed and constructive feedback on our manuscript. We address each of the major comments below and commit to incorporating the suggested improvements in the revised version.
read point-by-point responses
-
Referee: [Method section] Method section (around the description of the Transformer encoder and reliability head): the manuscript provides no equations, pseudocode, or explicit formulation for how the class vector and patch vectors are mapped to an attribute reliability score, nor for how the auxiliary calibration scores are merged with the base detector's scores. This formulation is load-bearing for the central claim that DINOv3-derived reliability can correct miscalibrations on novel classes without any base-model signals.
Authors: We concur that the absence of explicit equations and pseudocode in the method section limits the clarity of the core technical contributions. To rectify this, we will revise the manuscript to include a formal mathematical description of the Transformer encoder, detailing the input processing of global image features and patch-level features from DINOv3, the generation of the class vector and patch vectors, the reliability head's computation of attribute reliability scores, and the fusion mechanism for merging auxiliary calibration scores with the base detector's outputs. Additionally, we will provide pseudocode outlining the inference pipeline. These additions will substantiate the claim that the reliability signal derived from foundational model features can effectively address miscalibrations on novel classes. revision: yes
-
Referee: [Experimental section] Experimental section and associated tables: the abstract and results claim consistent improvements of up to +10.1 AP on novel categories across multiple OVOD models and four datasets, yet no ablation studies, baseline comparisons (e.g., simple score averaging or other post-hoc recalibrators), error bars, or statistical significance tests are referenced. Without these, it is impossible to determine whether the gains arise from the proposed feature-fusion mechanism or from other factors.
Authors: We acknowledge the importance of ablations and rigorous statistical analysis for validating the source of the observed performance gains. Although the current manuscript demonstrates consistent improvements across diverse settings, we agree that additional experiments are necessary. In the revised manuscript, we will incorporate ablation studies that isolate the effects of global-local feature fusion, comparisons against baseline post-hoc recalibration techniques such as simple averaging or temperature scaling, and report results with error bars along with statistical significance tests. This will provide stronger evidence that the gains are attributable to the proposed DetRefiner mechanism. revision: yes
-
Referee: [Training objective paragraph] Training objective paragraph: the loss used to train the reliability head on seen data is not specified. Because DetRefiner never observes the base model's failure modes on novel objects, it is unclear whether the learned reliability signal aligns with the specific miscalibrations that the merging step is intended to correct.
Authors: We appreciate this observation regarding the training details. The revised manuscript will explicitly specify the loss function employed to train the reliability head using supervision from seen classes. We will also elaborate on the rationale for this training strategy, explaining how learning reliability from seen data enables generalization to novel classes by capturing general attribute reliability patterns independent of the base model's specific errors on unseen objects. This clarification will address concerns about the alignment between the learned signal and the calibration corrections applied during merging. revision: yes
Circularity Check
No significant circularity; independent training on external DINO features yields non-tautological refinement
full rationale
The abstract and description present DetRefiner as a separately trained lightweight Transformer that ingests only DINOv3 global/patch features plus base-detector outputs, infers reliability attributes, and merges auxiliary scores. No load-bearing step reduces by construction to the input predictions or to a self-citation chain; the claimed AP gains are empirical outcomes of this external fusion process rather than a re-labeling of fitted parameters or a uniqueness theorem imported from prior author work. The derivation chain therefore remains self-contained against external benchmarks and does not exhibit any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DetRefiner processes global image features and patch-level image features from foundational models (e.g., DINOv3) through a lightweight Transformer encoder. The encoder produces a class vector capturing image-level attributes and patch vectors representing local region attributes, from which attribute reliability is inferred to recalibrate the base model's confidence.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
YOLOv4: Optimal Speed and Accuracy of Object Detection
Alexey Bochkovskiy, Chien-Yao Wang, and Hong- Yuan Mark Liao. Yolov4: Optimal speed and accuracy of object detection.arXiv preprint arXiv:2004.10934, 2020. 1
work page internal anchor Pith review arXiv 2004
-
[2]
End-to- end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to- end object detection with transformers. InEuropean confer- ence on computer vision, pages 213–229. Springer, 2020. 1
work page 2020
-
[3]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. InPro- ceedings of the IEEE/CVF international conference on com- puter vision, pages 9650–9660, 2021. 2, 3
work page 2021
-
[4]
Vision transformers need registers
Timoth ´ee Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision transformers need registers. InThe Twelfth International Conference on Learning Representa- tions, 2024. 3, 8
work page 2024
-
[5]
Learning to prompt for open-vocabulary ob- ject detection with vision-language model
Yu Du, Fangyun Wei, Zihe Zhang, Miaojing Shi, Yue Gao, and Guoqi Li. Learning to prompt for open-vocabulary ob- ject detection with vision-language model. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14084–14093, 2022. 2, 3
work page 2022
-
[6]
Prob- ing the 3d awareness of visual foundation models
Mohamed El Banani, Amit Raj, Kevis-Kokitsi Maninis, Ab- hishek Kar, Yuanzhen Li, Michael Rubinstein, Deqing Sun, Leonidas Guibas, Justin Johnson, and Varun Jampani. Prob- ing the 3d awareness of visual foundation models. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21795–21806, 2024. 3
work page 2024
-
[7]
Mark Everingham, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes (voc) challenge.International journal of computer vision, 88(2):303–338, 2010. 2, 5, 6
work page 2010
-
[8]
Simple image-level classification improves open-vocabulary object detection
Ruohuan Fang, Guansong Pang, and Xiao Bai. Simple image-level classification improves open-vocabulary object detection. InThe 38th Annual AAAI Conference on Artificial Intelligence, 2024. 2
work page 2024
-
[9]
Shenghao Fu, Qize Yang, Qijie Mo, Junkai Yan, Xihan Wei, Jingke Meng, Xiaohua Xie, and Wei-Shi Zheng. Llmdet: Learning strong open-vocabulary object detectors under the supervision of large language models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14987–14997, 2025. 2, 3, 6
work page 2025
-
[10]
Open-vocabulary object detection via vision and language knowledge distillation
Xiuye Gu, Tsung-Yi Lin, Weicheng Kuo, and Yin Cui. Open-vocabulary object detection via vision and language knowledge distillation. InInternational Conference on Learning Representations, 2022. 2, 3, 5
work page 2022
-
[11]
Lvis: A dataset for large vocabulary instance segmentation
Agrim Gupta, Piotr Dollar, and Ross Girshick. Lvis: A dataset for large vocabulary instance segmentation. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5356–5364, 2019. 1, 2, 5, 6
work page 2019
-
[12]
Kaiming He, Georgia Gkioxari, Piotr Doll ´ar, and Ross Gir- shick. Mask r-cnn. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 2961–2969,
-
[13]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll´ar, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000– 16009, 2022. 4
work page 2022
-
[14]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distill- ing the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015. 2
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[15]
Averaging weights leads to wider optima and better generalization
P Izmailov, AG Wilson, D Podoprikhin, D Vetrov, and T Garipov. Averaging weights leads to wider optima and better generalization. In34th Conference on Uncertainty in Artifi- cial Intelligence 2018, UAI 2018, pages 876–885, 2018. 5
work page 2018
-
[16]
Scaling up visual and vision-language representa- tion learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representa- tion learning with noisy text supervision. InInternational conference on machine learning, pages 4904–4916. PMLR,
-
[17]
T-rex2: Towards generic object detec- tion via text-visual prompt synergy
Qing Jiang, Feng Li, Zhaoyang Zeng, Tianhe Ren, Shilong Liu, and Lei Zhang. T-rex2: Towards generic object detec- tion via text-visual prompt synergy. InEuropean Conference on Computer Vision, pages 38–57. Springer, 2024. 8
work page 2024
-
[18]
LLMs meet VLMs: Boost open vocabu- lary object detection with fine-grained descriptors
Sheng Jin, Xueying Jiang, Jiaxing Huang, Lewei Lu, and Shijian Lu. LLMs meet VLMs: Boost open vocabu- lary object detection with fine-grained descriptors. InThe Twelfth International Conference on Learning Representa- tions, 2024. 2, 3
work page 2024
-
[19]
Mdetr- modulated detection for end-to-end multi-modal understand- ing
Aishwarya Kamath, Mannat Singh, Yann LeCun, Gabriel Synnaeve, Ishan Misra, and Nicolas Carion. Mdetr- modulated detection for end-to-end multi-modal understand- ing. InProceedings of the IEEE/CVF international confer- ence on computer vision, pages 1780–1790, 2021. 2
work page 2021
-
[20]
Brave: Broadening the visual encoding of vision-language models
O ˘guzhan Fatih Kar, Alessio Tonioni, Petra Poklukar, Achin Kulshrestha, Amir Zamir, and Federico Tombari. Brave: Broadening the visual encoding of vision-language models. InEuropean Conference on Computer Vision, pages 113–
-
[21]
Vilt: Vision- and-language transformer without convolution or region su- pervision
Wonjae Kim, Bokyung Son, and Ildoo Kim. Vilt: Vision- and-language transformer without convolution or region su- pervision. InInternational conference on machine learning, pages 5583–5594. PMLR, 2021. 4
work page 2021
-
[22]
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InIn The Third International Con- ference on Learning Representations, 2015. 5
work page 2015
-
[23]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, et al. Segment any- thing. InProceedings of the IEEE/CVF international confer- ence on computer vision, pages 4015–4026, 2023. 3
work page 2023
-
[24]
Chunyuan Li, Haotian Liu, Liunian Li, Pengchuan Zhang, Jyoti Aneja, Jianwei Yang, Ping Jin, Houdong Hu, Zicheng Liu, Yong Jae Lee, et al. Elevater: A benchmark and toolkit for evaluating language-augmented visual models.Advances in Neural Information Processing Systems, 35:9287–9301,
-
[25]
Grounded language-image pre-training
Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jian- wei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu 9 Yuan, Lei Zhang, Jenq-Neng Hwang, et al. Grounded language-image pre-training. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10965–10975, 2022. 2, 3, 5, 6, 1
work page 2022
-
[26]
Yanqi Li, Jianwei Niu, and Tao Ren. Benefit from seen: Enhancing open-vocabulary object detection by bridging vi- sual and textual co-occurrence knowledge. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 22110–22119, 2025. 2, 3
work page 2025
-
[27]
Learning object-language alignments for open-vocabulary object de- tection
Chuang Lin, Peize Sun, Yi Jiang, Ping Luo, Lizhen Qu, Gho- lamreza Haffari, Zehuan Yuan, and Jianfei Cai. Learning object-language alignments for open-vocabulary object de- tection. InThe Eleventh International Conference on Learn- ing Representations, 2023. 3
work page 2023
-
[28]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014. 2, 5, 6, 1
work page 2014
-
[29]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuro- pean conference on computer vision, pages 38–55. Springer,
-
[30]
Decoupled weight de- cay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight de- cay regularization. InInternational Conference on Learning Representations, 2019. 5
work page 2019
-
[31]
Simple open-vocabulary object detection
Matthias Minderer, Alexey Gritsenko, Austin Stone, Maxim Neumann, Dirk Weissenborn, Alexey Dosovitskiy, Aravindh Mahendran, Anurag Arnab, Mostafa Dehghani, Zhuoran Shen, et al. Simple open-vocabulary object detection. In European conference on computer vision, pages 728–755. Springer, 2022. 2
work page 2022
-
[32]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 1, 2, 3
work page 2021
-
[33]
Am-radio: Agglomerative vision foundation model reduce all domains into one
Mike Ranzinger, Greg Heinrich, Jan Kautz, and Pavlo Molchanov. Am-radio: Agglomerative vision foundation model reduce all domains into one. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12490–12500, 2024. 3
work page 2024
-
[34]
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks.IEEE transactions on pattern analysis and machine intelligence, 39(6):1137–1149, 2016. 1
work page 2016
-
[35]
Grounding dino 1.5: Advance the” edge” of open-set object detection
Tianhe Ren, Qing Jiang, Shilong Liu, Zhaoyang Zeng, Wen- long Liu, Han Gao, Hongjie Huang, Zhengyu Ma, Xiaoke Jiang, Yihao Chen, et al. Grounding dino 1.5: Advance the” edge” of open-set object detection.arXiv preprint arXiv:2405.10300, 2024. 8
-
[36]
Fitnets: Hints for thin deep nets
Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, and Yoshua Bengio. Fitnets: Hints for thin deep nets. InIn Proceedings of ICLR, 2015. 2
work page 2015
-
[37]
Edadet: Open-vocabulary object detection using early dense alignment
Cheng Shi and Sibei Yang. Edadet: Open-vocabulary object detection using early dense alignment. InProceedings of the IEEE/CVF international conference on computer vision, pages 15724–15734, 2023. 2
work page 2023
-
[38]
Eagle: Exploring the de- sign space for multimodal llms with mixture of encoders
Min Shi, Fuxiao Liu, Shihao Wang, Shijia Liao, Subhashree Radhakrishnan, Yilin Zhao, De-An Huang, Hongxu Yin, Karan Sapra, Yaser Yacoob, et al. Eagle: Exploring the de- sign space for multimodal llms with mixture of encoders. In The Thirteenth International Conference on Learning Rep- resentations, 2025. 3
work page 2025
-
[39]
Oriane Sim ´eoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamonjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104, 2025. 2, 3, 5, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Antti Tarvainen and Harri Valpola. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results.Advances in neural information processing systems, 30, 2017. 5
work page 2017
-
[41]
Eyes wide shut? exploring the visual shortcomings of multimodal llms
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. Eyes wide shut? exploring the visual shortcomings of multimodal llms. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9568–9578, 2024. 3
work page 2024
-
[42]
Mobile- clip: Fast image-text models through multi-modal reinforced training
Pavan Kumar Anasosalu Vasu, Hadi Pouransari, Fartash Faghri, Raviteja Vemulapalli, and Oncel Tuzel. Mobile- clip: Fast image-text models through multi-modal reinforced training. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15963– 15974, 2024. 2, 3, 5
work page 2024
-
[43]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017. 2, 5
work page 2017
-
[44]
V3det: Vast vocabulary visual detection dataset
Jiaqi Wang, Pan Zhang, Tao Chu, Yuhang Cao, Yujie Zhou, Tong Wu, Bin Wang, Conghui He, and Dahua Lin. V3det: Vast vocabulary visual detection dataset. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 19844–19854, 2023. 1, 6
work page 2023
-
[45]
Open-vocabulary calibration for fine-tuned clip
Shuoyuan Wang, Jindong Wang, Guoqing Wang, Bob Zhang, Kaiyang Zhou, and Hongxin Wei. Open-vocabulary calibration for fine-tuned clip. InInternational Conference on Machine Learning, pages 51734–51754. PMLR, 2024. 2
work page 2024
-
[46]
Aligning bag of regions for open- vocabulary object detection
Size Wu, Wenwei Zhang, Sheng Jin, Wentao Liu, and Chen Change Loy. Aligning bag of regions for open- vocabulary object detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15254–15264, 2023. 2, 3
work page 2023
-
[47]
Open-vocabulary object detection using captions
Alireza Zareian, Kevin Dela Rosa, Derek Hao Hu, and Shih- Fu Chang. Open-vocabulary object detection using captions. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 14393–14402, 2021. 2, 5
work page 2021
-
[48]
Long-clip: Unlocking the long-text capability of clip
Beichen Zhang, Pan Zhang, Xiaoyi Dong, Yuhang Zang, and Jiaqi Wang. Long-clip: Unlocking the long-text capability of clip. InEuropean conference on computer vision, pages 310–325. Springer, 2024. 2 10
work page 2024
-
[49]
Dino: Detr with improved denoising anchor boxes for end-to-end object de- tection
Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel Ni, and Heung-Yeung Shum. Dino: Detr with improved denoising anchor boxes for end-to-end object de- tection. InThe Eleventh International Conference on Learn- ing Representations, 2023. 1
work page 2023
-
[50]
Xiangyu Zhao, Yicheng Chen, Shilin Xu, Xiangtai Li, Xin- jiang Wang, Yining Li, and Haian Huang. An open and com- prehensive pipeline for unified object grounding and detec- tion.arXiv preprint arXiv:2401.02361, 2024. 2, 3, 6
-
[51]
Training-free boost for open- vocabulary object detection with confidence aggregation
Yanhao Zheng and Kai Liu. Training-free boost for open- vocabulary object detection with confidence aggregation. arXiv preprint arXiv:2404.08603, 2024. 2
-
[52]
Regionclip: Region- based language-image pretraining
Yiwu Zhong, Jianwei Yang, Pengchuan Zhang, Chun- yuan Li, Noel Codella, Liunian Harold Li, Luowei Zhou, Xiyang Dai, Lu Yuan, Yin Li, et al. Regionclip: Region- based language-image pretraining. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16793–16803, 2022. 2, 3
work page 2022
-
[53]
Detecting twenty-thousand classes using image-level supervision
Xingyi Zhou, Rohit Girdhar, Armand Joulin, Philipp Kr¨ahenb¨uhl, and Ishan Misra. Detecting twenty-thousand classes using image-level supervision. InEuropean confer- ence on computer vision, pages 350–368. Springer, 2022. 2, 3 11 DetRefiner: Model-Agnostic Detection Refinement with Feature Fusion Transformer Supplementary Material
work page 2022
-
[54]
Reproducible Evaluation of Open- Vocabulary Object Detectors Before applying DetRefiner, we reproduce ten representa- tive open-vocabulary detectors across all benchmarks under a unified evaluation protocol. All reported improvements are measured with respect to these reproduced baselines to ensure consistent comparison. GLIP [25] is implemented using its...
-
[55]
Additional Visualization Results Figure 4 illustrates how DetRefiner refines predictions from the base detector. It suppresses overconfident false positives and boosts missed true positives using both global and local cues. The bottom row indicates scene-level (class vector) and region-level (patch vector) calibration, which together improve open-vocabula...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.