Recognition: no theorem link
3DReflecNet: A Large-Scale Dataset for 3D Reconstruction of Reflective, Transparent, and Low-Texture Objects
Pith reviewed 2026-05-12 04:06 UTC · model grok-4.3
The pith
A 22-terabyte hybrid dataset shows that current 3D reconstruction methods lose accuracy on reflective, transparent, and low-texture objects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By releasing this large-scale hybrid dataset of reflective, transparent, and low-texture objects, the work establishes that multi-view reconstruction pipelines fail to deliver reliable geometry and appearance when photometric consistency and distinct texture cues are absent, as demonstrated by the poor performance of existing methods across the five defined benchmarks.
What carries the argument
3DReflecNet, the hybrid dataset of physically-based rendered synthetic scenes and real consumer-device captures that supplies ground-truth geometry and appearance for direct evaluation of 3D vision tasks on challenging materials.
If this is right
- Structure-from-motion and image matching pipelines will exhibit measurable drops in accuracy and completeness on the new data compared with standard diffuse benchmarks.
- Novel view synthesis and relighting methods must incorporate explicit handling of reflections and transparency to reach usable quality.
- Reflection removal performance becomes a necessary intermediate step for accurate 3D geometry recovery on these objects.
- The scale of the dataset enables quantitative comparison of future algorithms across thousands of instances rather than small hand-selected test sets.
- LLM-assisted shape generation combined with physical rendering offers a scalable route to expand coverage of rare material-geometry combinations.
Where Pith is reading between the lines
- The dataset could serve as a training signal for networks that learn material-aware priors directly from the provided multi-view frames.
- Future extensions might add dynamic sequences to test whether current failures persist under object motion or changing illumination.
- Integration with existing large-scale 3D datasets could quantify exactly how much performance on everyday objects is limited by the presence of a few reflective or transparent surfaces.
- The five-task benchmark structure suggests a modular evaluation protocol that other researchers can adopt without re-collecting data.
Load-bearing premise
The hybrid synthetic and real captures together represent the full range of difficulties that reflective, transparent, and low-texture objects present in uncontrolled real-world conditions.
What would settle it
A method achieving near-perfect accuracy on all five benchmark tasks when trained and tested exclusively on the dataset's held-out splits would falsify the claim that these material classes inherently cause state-of-the-art pipelines to fail.
Figures
























read the original abstract
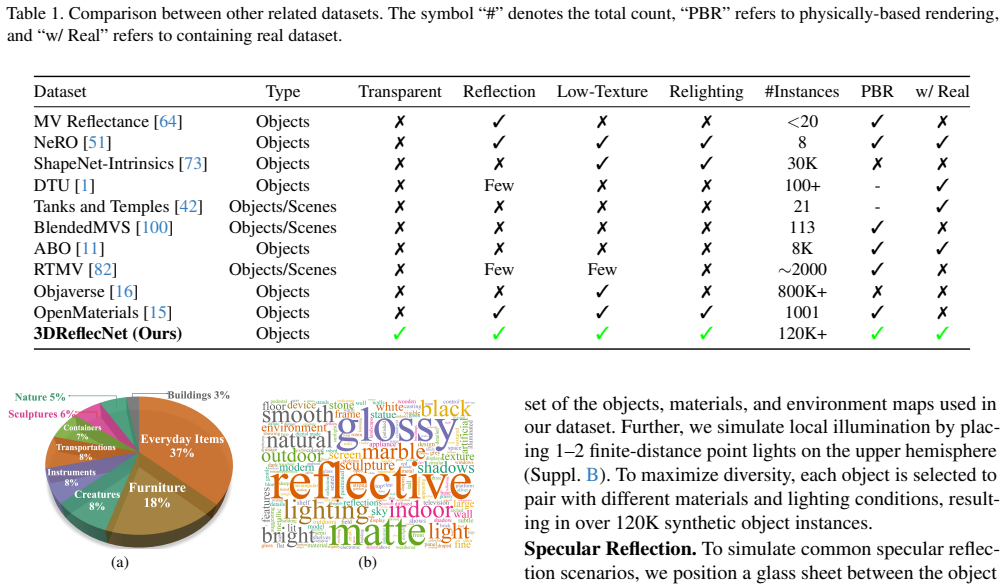
Accurate 3D reconstruction of objects with reflective, transparent, or low-texture surfaces still remains notoriously challenging. Such materials often violate key assumptions in multi-view reconstruction pipelines, such as photometric consistency and the availability on distinct geometric texture cues. Existing datasets primarily focus on diffuse, textured objects, and therefore provide limited insight into performance under real-world material complexities. We introduce 3DReflecNet, a large-scale hybrid dataset exceeding 22 TB that is specifically designed to benchmark and advance 3D vision methods for these challenging materials. 3DReflecNet combines two types of data: over 120,000 synthetic instances generated via physically-based rendering of more than 12,000 shapes, and over 1,000 real-world objects captured using consumer devices. Together, these data consist of more than 7 million multi-view frames. The dataset spans diverse materials, complex lighting conditions, and a wide range of geometric forms, including shapes generated from both real and LLM-synthesized 2D images using diffusion-based pipelines. To support robust evaluation, we design benchmarks for five core tasks: image matching, structure-from-motion, novel view synthesis, reflection removal, and relighting. Extensive experiments demonstrate that state-of-the-art methods struggle to maintain accuracy across these settings, highlighting the need for more resilient 3D vision models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces 3DReflecNet, a hybrid dataset exceeding 22 TB with over 120,000 synthetic PBR instances from >12,000 shapes and >1,000 real objects captured via consumer devices, yielding >7 million multi-view frames. It targets 3D reconstruction challenges for reflective, transparent, and low-texture surfaces, providing benchmarks for image matching, SfM, novel view synthesis, reflection removal, and relighting, while claiming that SOTA methods struggle to maintain accuracy.
Significance. If the ground-truth protocols and evaluation splits are rigorously defined, this dataset could provide a valuable standardized benchmark for advancing 3D vision methods on materials that violate standard photometric and texture assumptions, complementing existing diffuse-object datasets.
major comments (2)
- [Dataset construction / real captures] Real-data section: the protocol for obtaining independent 3D ground truth on the >1,000 consumer-device captures is not described with sufficient detail (e.g., no mention of laser scanning, verified multi-view stereo, or calibration procedures). Without this, quantitative claims that SOTA methods 'struggle' on the real split cannot be separated from potential errors in the pseudo-ground-truth itself.
- [Experiments and benchmarks] Experiments section: the abstract asserts that 'extensive experiments demonstrate that state-of-the-art methods struggle,' yet no quantitative metrics, error tables, or benchmark protocols (e.g., specific accuracy drops on reflective vs. diffuse subsets) are referenced. This leaves the central empirical claim unsupported in the provided summary.
minor comments (2)
- [Abstract and introduction] Clarify the exact split between synthetic and real data volumes and how the hybrid design ensures that synthetic perfect GT does not substitute for real sensor noise in the reported benchmarks.
- [Benchmarks] Provide explicit definitions or references for the five benchmark tasks, including evaluation metrics and baseline implementations used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript introducing 3DReflecNet. We address each major comment below and will revise the paper to improve clarity on real-data protocols and experimental reporting while preserving the core contributions.
read point-by-point responses
-
Referee: Real-data section: the protocol for obtaining independent 3D ground truth on the >1,000 consumer-device captures is not described with sufficient detail (e.g., no mention of laser scanning, verified multi-view stereo, or calibration procedures). Without this, quantitative claims that SOTA methods 'struggle' on the real split cannot be separated from potential errors in the pseudo-ground-truth itself.
Authors: We agree that the real-data ground-truth protocol requires more explicit description to allow independent assessment of the quantitative results. In the revised manuscript we will add a dedicated subsection under Dataset Construction that details the consumer-device capture pipeline, intrinsic/extrinsic calibration procedures, and the independent 3D ground-truth acquisition method (including laser-scanner cross-validation and multi-view stereo verification steps). This addition will directly address the concern about separating method errors from potential pseudo-ground-truth inaccuracies. revision: yes
-
Referee: Experiments section: the abstract asserts that 'extensive experiments demonstrate that state-of-the-art methods struggle,' yet no quantitative metrics, error tables, or benchmark protocols (e.g., specific accuracy drops on reflective vs. diffuse subsets) are referenced. This leaves the central empirical claim unsupported in the provided summary.
Authors: The full manuscript contains a complete Experiments section (Section 4) with quantitative tables, error metrics, and benchmark protocols for all five tasks, explicitly comparing performance on reflective/transparent/low-texture subsets versus diffuse baselines. To make these results more immediately visible, we will revise the abstract to include a concise reference to key findings and add a summary table in the introduction that highlights representative accuracy drops. We will also expand the benchmark-protocol descriptions for clarity. revision: partial
Circularity Check
No circularity: dataset paper with no derivations, predictions, or fitted quantities
full rationale
The paper introduces a hybrid dataset (synthetic PBR + real consumer captures) and runs standard benchmarks on existing SOTA methods for tasks like SfM and NVS. No equations, no parameter fitting, no predictions derived from the data itself, and no self-citation chains that bear the central claim. The contribution is the data collection and curation protocol; evaluation uses off-the-shelf methods whose performance is measured against the provided ground truth, with no reduction of results to the inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Henrik Aanæs, Rasmus Ramsbøl Jensen, George V ogiatzis, Engin Tola, and Anders Bjorholm Dahl. Large-scale data for multiple-view stereopsis.International Journal of Computer Vision, 120:153–168, 2016. 3, 5
work page 2016
-
[2]
Surf: Speeded up robust features
Herbert Bay, Tinne Tuytelaars, and Luc Van Gool. Surf: Speeded up robust features. InComputer Vision–ECCV 2006: 9th European Conference on Computer Vision, Graz, Austria, May 7-13, 2006. Proceedings, Part I 9, pages 404–
work page 2006
-
[3]
Texfusion: Synthesizing 3d textures with text-guided image diffusion models
Tianshi Cao, Karsten Kreis, Sanja Fidler, Nicholas Sharp, and Kangxue Yin. Texfusion: Synthesizing 3d textures with text-guided image diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 4169–4181, 2023. 8
work page 2023
-
[4]
Alessandro Cefalu, Norbert Haala, and Dieter Fritsch. Hi- erarchical structure from motion combining global image orientation and structureless bundle adjustment.The Inter- national Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 42:535–542, 2017. 3
work page 2017
-
[5]
Efficient and robust large-scale rotation averaging
Avishek Chatterjee and Venu Madhav Govindu. Efficient and robust large-scale rotation averaging. InProceedings of the IEEE international conference on computer vision, pages 521–528, 2013. 3
work page 2013
-
[6]
Danpeng Chen, Hai Li, Weicai Ye, Yifan Wang, Weijian Xie, Shangjin Zhai, Nan Wang, Haomin Liu, Hujun Bao, and Guofeng Zhang. Pgsr: Planar-based gaussian splatting for efficient and high-fidelity surface reconstruction.IEEE Transactions on Visualization and Computer Graphics, 31 (9):6100–6111, 2025. 7, 18
work page 2025
-
[7]
Text2tex: Text-driven tex- ture synthesis via diffusion models
Dave Zhenyu Chen, Yawar Siddiqui, Hsin-Ying Lee, Sergey Tulyakov, and Matthias Nießner. Text2tex: Text-driven tex- ture synthesis via diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 18558–18568, 2023. 8, 22
work page 2023
-
[8]
Aspanformer: Detector-free image matching with adaptive span transformer
Hongkai Chen, Zixin Luo, Lei Zhou, Yurun Tian, Ming- min Zhen, Tian Fang, David Mckinnon, Yanghai Tsin, and Long Quan. Aspanformer: Detector-free image matching with adaptive span transformer. InEuropean Conference on Computer Vision, pages 20–36. Springer, 2022. 2, 7
work page 2022
-
[9]
arXiv preprint arXiv:2410.02619 , year=
Hongze Chen, Zehong Lin, and Jun Zhang. Gi-gs: Global illumination decomposition on gaussian splatting for inverse rendering.arXiv preprint arXiv:2410.02619, 2024. 18, 25
-
[10]
Jin et al. Christy. Openmaterial: A comprehensive dataset of complex materials for 3d reconstruction. https:// christy61.github.io/openmaterial.github. io/, 2023. 2
work page 2023
-
[11]
Abo: Dataset and benchmarks for real-world 3d object un- derstanding
Jasmine Collins, Shubham Goel, Kenan Deng, Achlesh- war Luthra, Leon Xu, Erhan Gundogdu, Xi Zhang, Tomas F Yago Vicente, Thomas Dideriksen, Himanshu Arora, et al. Abo: Dataset and benchmarks for real-world 3d object un- derstanding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21126– 21136, 2022. 3, 5
work page 2022
-
[12]
Robert L. Cook and Kenneth E. Torrance. A reflectance model for computer graphics.ACM Transactions on Graph- ics, 1(1):7–24, 1982. 20
work page 1982
-
[13]
David J Crandall, Andrew Owens, Noah Snavely, and Daniel P Huttenlocher. Sfm with mrfs: Discrete-continuous optimization for large-scale structure from motion.IEEE transactions on pattern analysis and machine intelligence, 35(12):2841–2853, 2012. 2
work page 2012
-
[14]
Hsfm: Hybrid structure-from-motion
Hainan Cui, Xiang Gao, Shuhan Shen, and Zhanyi Hu. Hsfm: Hybrid structure-from-motion. InProceedings of the IEEE conference on computer vision and pattern recog- nition, pages 1212–1221, 2017. 2
work page 2017
-
[15]
Zheng Dang, Jialu Huang, Fei Wang, and Mathieu Salzmann. Openmaterial: A comprehensive dataset of complex materi- als for 3d reconstruction.arXiv preprint arXiv:2406.08894,
-
[16]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. InProceedings of the IEEE/CVF conference on computer vision and pattern recog- nition, pages 13142–13153, 2023. 3, 5
work page 2023
-
[17]
Superpoint: Self-supervised interest point detection and description
Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabi- novich. Superpoint: Self-supervised interest point detection and description. InProceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 224–236, 2018. 2, 7, 16
work page 2018
-
[18]
Siyan Dong, Shuzhe Wang, Shaohui Liu, Lulu Cai, Qingnan Fan, Juho Kannala, and Yanchao Yang. Reloc3r: Large-scale training of relative camera pose regression for generaliz- able, fast, and accurate visual localization.arXiv preprint arXiv:2412.08376, 2024. 4
-
[19]
Zheng Dong, Ke Xu, Yin Yang, Hujun Bao, Weiwei Xu, and Rynson W.H. Lau. Location-aware single image reflection removal. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 5017–5026,
-
[20]
D2-net: A trainable cnn for joint description and detection of lo- cal features
Mihai Dusmanu, Ignacio Rocco, Tomas Pajdla, Marc Polle- feys, Josef Sivic, Akihiko Torii, and Torsten Sattler. D2-net: A trainable cnn for joint description and detection of lo- cal features. InProceedings of the ieee/cvf conference on 9 computer vision and pattern recognition, pages 8092–8101,
-
[21]
Roma: Robust dense feature matching
Johan Edstedt, Qiyu Sun, Georg B ¨okman, M ˚arten Wadenb¨ack, and Michael Felsberg. Roma: Robust dense feature matching. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pages 19790–19800, 2024. 2, 4, 7, 16
work page 2024
-
[22]
Epic Games. RealityScan. https : / / www . realityscan.com, 2025. Accessed: 2025-10-06. 6
work page 2025
-
[23]
Plenoxels: Radiance fields without neural networks
Sara Fridovich-Keil, Alex Yu, Matthew Tancik, Qinhong Chen, Benjamin Recht, and Angjoo Kanazawa. Plenoxels: Radiance fields without neural networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5501–5510, 2022. 2, 3
work page 2022
-
[24]
Towards high-quality specular highlight removal by leveraging large-scale synthetic data
Gang Fu, Qing Zhang, Lei Zhu, Chunxia Xiao, and Ping Li. Towards high-quality specular highlight removal by leveraging large-scale synthetic data. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 12857–12865, 2023. 16, 24
work page 2023
-
[25]
Colmap-free 3d gaussian splat- ting
Yang Fu, Sifei Liu, Amey Kulkarni, Jan Kautz, Alexei A Efros, and Xiaolong Wang. Colmap-free 3d gaussian splat- ting. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 20796–20805,
-
[26]
Massively parallel multiview stereopsis by surface normal diffusion
Silvano Galliani, Katrin Lasinger, and Konrad Schindler. Massively parallel multiview stereopsis by surface normal diffusion. InProceedings of the IEEE international confer- ence on computer vision, pages 873–881, 2015. 2, 3
work page 2015
-
[27]
Greivenkamp.Field Guide to Geometrical Optics
John E. Greivenkamp.Field Guide to Geometrical Optics. SPIE Press, 2004. 20
work page 2004
-
[28]
Paul Hand, Choongbum Lee, and Vladislav V oroninski. Shapefit: Exact location recovery from corrupted pairwise directions.Communications on Pure and Applied Mathe- matics, 71(1):3–50, 2018. 3
work page 2018
-
[29]
Richard Hartley and Andrew Zisserman.Multiple view geometry in computer vision. Cambridge university press,
-
[30]
Eric Heitz. Understanding the masking–shadowing function in microfacet-based brdfs.Journal of Computer Graphics Techniques, 3(2):24–78, 2014. 20
work page 2014
-
[31]
Single image reflection sep- aration via component synergy
Qiming Hu and Xiaojie Guo. Single image reflection sep- aration via component synergy. InProceedings of the IEEE/CVF international conference on computer vision, pages 13138–13147, 2023. 18
work page 2023
-
[32]
Single image reflection separation via dual-stream interactive transformers
Qiming Hu, Hainuo Wang, and Xiaojie Guo. Single image reflection separation via dual-stream interactive transformers. Advances in Neural Information Processing Systems, 37: 55228–55248, 2024. 18, 24
work page 2024
-
[33]
2d gaussian splatting for geometrically ac- curate radiance fields
Binbin Huang, Zehao Yu, Anpei Chen, Andreas Geiger, and Shenghua Gao. 2d gaussian splatting for geometrically ac- curate radiance fields. InACM SIGGRAPH 2024 conference papers, pages 1–11, 2024. 2, 3, 7, 18
work page 2024
-
[34]
David S. Immel, Michael F. Cohen, and Donald P. Green- berg. A radiosity method for non-diffuse environments. In Proceedings of the 13th Annual Conference on Computer Graphics and Interactive Techniques, page 133–142, New York, NY , USA, 1986. Association for Computing Machin- ery. 20
work page 1986
-
[35]
Henrik W. Jensen, Steve R. Marschner, Marc Levoy, and Pat Hanrahan. A practical model for subsurface light transport. InProceedings of SIGGRAPH, pages 511–518, 2001. 21
work page 2001
-
[36]
Large scale multi-view stereopsis evalu- ation
Rasmus Jensen, Anders Dahl, George V ogiatzis, Engin Tola, and Henrik Aanæs. Large scale multi-view stereopsis evalu- ation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 406–413, 2014. 2
work page 2014
-
[37]
A global linear method for camera pose registration
Nianjuan Jiang, Zhaopeng Cui, and Ping Tan. A global linear method for camera pose registration. InProceedings of the IEEE international conference on computer vision, pages 481–488, 2013. 2
work page 2013
-
[38]
Tensoir: Tensorial inverse rendering
Haian Jin, Isabella Liu, Peijia Xu, Xiaoshuai Zhang, Song- fang Han, Sai Bi, Xiaowei Zhou, Zexiang Xu, and Hao Su. Tensoir: Tensorial inverse rendering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 165–174, 2023. 18
work page 2023
-
[39]
Fresnel reflection of diffusely incident light
Deane B Judd. Fresnel reflection of diffusely incident light
-
[40]
James T Kajiya. The rendering equation. InProceedings of the 13th annual conference on Computer graphics and interactive techniques, pages 143–150, 1986. 20
work page 1986
-
[41]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1,
-
[42]
Arno Knapitsch, Jaesik Park, Qian-Yi Zhou, and Vladlen Koltun. Tanks and temples: Benchmarking large-scale scene reconstruction.ACM Transactions on Graphics, 36(4), 2017. 3, 5
work page 2017
-
[43]
Ein beitrag zur optik der farbanstriche.Zeitschrift f ¨ur Technische Physik, 12:593–601,
Paul Kubelka and Franz Munk. Ein beitrag zur optik der farbanstriche.Zeitschrift f ¨ur Technische Physik, 12:593–601,
-
[44]
Robust reflection removal with reflection-free flash-only cues
Chenyang Lei and Qifeng Chen. Robust reflection removal with reflection-free flash-only cues. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14811–14820, 2021. 5
work page 2021
-
[45]
Zone: Zero-shot instruction-guided local editing
Shanglin Li, Bohan Zeng, Yutang Feng, Sicheng Gao, Xi- uhui Liu, Jiaming Liu, Lin Li, Xu Tang, Yao Hu, Jianzhuang Liu, et al. Zone: Zero-shot instruction-guided local editing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6254–6263, 2024. 8, 23
work page 2024
-
[46]
Megadepth: Learning single- view depth prediction from internet photos
Zhengqi Li and Noah Snavely. Megadepth: Learning single- view depth prediction from internet photos. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2041–2050, 2018. 7
work page 2041
-
[47]
Luciddreamer: Towards high- fidelity text-to-3d generation via interval score matching
Yixun Liang, Xin Yang, Jiantao Lin, Haodong Li, Xiao- gang Xu, and Yingcong Chen. Luciddreamer: Towards high- fidelity text-to-3d generation via interval score matching. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6517–6526, 2024. 8
work page 2024
-
[48]
Gs-ir: 3d gaussian splatting for inverse rendering
Zhihao Liang, Qi Zhang, Ying Feng, Ying Shan, and Kui Jia. Gs-ir: 3d gaussian splatting for inverse rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21644–21653, 2024. 18, 24
work page 2024
-
[49]
Lightglue: Local feature matching at light speed
Philipp Lindenberger, Paul-Edouard Sarlin, and Marc Polle- feys. Lightglue: Local feature matching at light speed. In 10 Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 17627–17638, 2023. 7
work page 2023
-
[50]
Minghua Liu, Ruoxi Shi, Linghao Chen, Zhuoyang Zhang, Chao Xu, Xinyue Wei, Hansheng Chen, Chong Zeng, Ji- ayuan Gu, and Hao Su. One-2-3-45++: Fast single image to 3d objects with consistent multi-view generation and 3d dif- fusion. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 10072–10083,
-
[51]
Yuan Liu, Peng Wang, Cheng Lin, Xiaoxiao Long, Jiepeng Wang, Lingjie Liu, Taku Komura, and Wenping Wang. Nero: Neural geometry and brdf reconstruction of reflective objects from multiview images.ACM Transactions on Graphics (ToG), 42(4):1–22, 2023. 3, 5, 16
work page 2023
-
[52]
David G Lowe. Distinctive image features from scale- invariant keypoints.International journal of computer vision, 60(2):91–110, 2004. 21
work page 2004
-
[53]
Fresnel equations.Encyclopedia of Optical Engineering, 27:1–6, 2013
Alexander I Lvovsky. Fresnel equations.Encyclopedia of Optical Engineering, 27:1–6, 2013. 20
work page 2013
-
[54]
Multiview stereo with cascaded epipolar raft
Zeyu Ma, Zachary Teed, and Jia Deng. Multiview stereo with cascaded epipolar raft. InEuropean Conference on Computer Vision, pages 734–750. Springer, 2022. 2
work page 2022
-
[55]
Hidenobu Matsuki, Riku Murai, Paul HJ Kelly, and An- drew J Davison. Gaussian splatting slam. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18039–18048, 2024. 2, 3
work page 2024
-
[56]
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view syn- thesis.Communications of the ACM, 65(1):99–106, 2021. 2, 3, 24
work page 2021
-
[57]
Instant neural graphics primitives with a multires- olution hash encoding.ACM Trans
Thomas M¨uller, Alex Evans, Christoph Schied, and Alexan- der Keller. Instant neural graphics primitives with a multires- olution hash encoding.ACM Trans. Graph., 41(4):102:1– 102:15, 2022. 7
work page 2022
-
[58]
Thomas M¨uller, Alex Evans, Christoph Schied, and Alexan- der Keller. Instant neural graphics primitives with a mul- tiresolution hash encoding.ACM transactions on graphics (TOG), 41(4):1–15, 2022. 2, 3, 17, 18
work page 2022
-
[59]
Extracting triangular 3d models, materials, and lighting from images
Jacob Munkberg, Jon Hasselgren, Tianchang Shen, Jun Gao, Wenzheng Chen, Alex Evans, Thomas M¨uller, and Sanja Fi- dler. Extracting triangular 3d models, materials, and lighting from images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8280– 8290, 2022. 18, 24
work page 2022
-
[60]
Thomas M¨uller, Alex Evans, Christoph Schied, and Alexan- der Keller. Instant neural graphics primitives with a mul- tiresolution hash encoding.ACM Transactions on Graphics, 41(4):1–15, 2022. TLDR: A versatile new input encoding that permits the use of a smaller network without sacrificing quality, thus significantly reducing the number of floating point ...
work page 2022
-
[61]
Contrastive denoising score for text-guided latent diffusion image editing
Hyelin Nam, Gihyun Kwon, Geon Yeong Park, and Jong Chul Ye. Contrastive denoising score for text-guided latent diffusion image editing. InProceedings of the IEEE/CVF conference on computer vision and pattern recog- nition, pages 9192–9201, 2024. 8, 23
work page 2024
-
[62]
Pauline C Ng and Steven Henikoff. Sift: Predicting amino acid changes that affect protein function.Nucleic acids research, 31(13):3812–3814, 2003. 2
work page 2003
-
[63]
Unisurf: Unifying neural implicit surfaces and radiance fields for multi-view reconstruction
Michael Oechsle, Songyou Peng, and Andreas Geiger. Unisurf: Unifying neural implicit surfaces and radiance fields for multi-view reconstruction. InProceedings of the IEEE/CVF international conference on computer vision, pages 5589–5599, 2021. 2, 3, 16
work page 2021
-
[64]
Multiview shape and reflectance from natural illumination
Geoffrey Oxholm and Ko Nishino. Multiview shape and reflectance from natural illumination. InProceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion, pages 2155–2162, 2014. 3, 5
work page 2014
-
[65]
Robust camera location esti- mation by convex programming
Onur Ozyesil and Amit Singer. Robust camera location esti- mation by convex programming. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2674–2683, 2015. 3
work page 2015
-
[66]
DreamFusion: Text-to-3D using 2D Diffusion
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Milden- hall. Dreamfusion: Text-to-3d using 2d diffusion.arXiv preprint arXiv:2209.14988, 2022. 8, 22
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[67]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024. 6, 16
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[68]
Jeremy et al. Reizenstein. Common objects in 3d: Large- scale learning and evaluation of real-life 3d category recon- struction. InICCV, 2021. 2
work page 2021
-
[69]
Texture: Text-guided texturing of 3d shapes
Elad Richardson, Gal Metzer, Yuval Alaluf, Raja Giryes, and Daniel Cohen-Or. Texture: Text-guided texturing of 3d shapes. InACM SIGGRAPH 2023 conference proceedings, pages 1–11, 2023. 8, 22
work page 2023
-
[70]
Orb: An efficient alternative to sift or surf
Ethan Rublee, Vincent Rabaud, Kurt Konolige, and Gary Bradski. Orb: An efficient alternative to sift or surf. In 2011 International conference on computer vision, pages 2564–2571. Ieee, 2011. 2
work page 2011
-
[71]
Superglue: Learning feature match- ing with graph neural networks
Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Superglue: Learning feature match- ing with graph neural networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recog- nition, pages 4938–4947, 2020. 7
work page 2020
-
[72]
Pixelwise view selection for unstructured multi-view stereo
Johannes L Sch ¨onberger, Enliang Zheng, Jan-Michael Frahm, and Marc Pollefeys. Pixelwise view selection for unstructured multi-view stereo. InComputer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Nether- lands, October 11-14, 2016, Proceedings, Part III 14, pages 501–518. Springer, 2016. 3
work page 2016
-
[73]
Learning non-lambertian object intrinsics across shapenet categories
Jian Shi, Yue Dong, Hao Su, and Stella X Yu. Learning non-lambertian object intrinsics across shapenet categories. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1685–1694, 2017. 3, 5
work page 2017
-
[74]
A survey of multimodal- guided image editing with text-to-image diffusion models
Xincheng Shuai, Henghui Ding, Xingjun Ma, Rongcheng Tu, Yu-Gang Jiang, and Dacheng Tao. A survey of multimodal- guided image editing with text-to-image diffusion models. arXiv preprint arXiv:2406.14555, 2024. 8 11
-
[75]
Photo tourism: exploring photo collections in 3d
Noah Snavely, Steven M Seitz, and Richard Szeliski. Photo tourism: exploring photo collections in 3d. InACM siggraph 2006 papers, pages 835–846. 2006. 3, 16
work page 2006
-
[76]
Direct voxel grid optimization: Super-fast convergence for radiance fields reconstruction
Cheng Sun, Min Sun, and Hwann-Tzong Chen. Direct voxel grid optimization: Super-fast convergence for radiance fields reconstruction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5459– 5469, 2022. 2, 3
work page 2022
-
[77]
Loftr: Detector-free local feature matching with transformers
Jiaming Sun, Zehong Shen, Yuang Wang, Hujun Bao, and Xiaowei Zhou. Loftr: Detector-free local feature matching with transformers. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 8922–8931, 2021. 2, 16
work page 2021
-
[78]
Loftr: Detector-free local feature matching with transformers
Jiaming Sun, Zehong Shen, Yuang Wang, Hujun Bao, and Xiaowei Zhou. Loftr: Detector-free local feature matching with transformers. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 8922–8931, 2021. 4, 7
work page 2021
-
[79]
Nerfstudio: A modular framework for neural radiance field development
Matthew Tancik, Ethan Weber, Evonne Ng, Ruilong Li, Brent Yi, Terrance Wang, Alexander Kristoffersen, Jake Austin, Kamyar Salahi, Abhik Ahuja, et al. Nerfstudio: A modular framework for neural radiance field development. InACM SIGGRAPH 2023 conference proceedings, pages 1–12, 2023. 7, 18
work page 2023
- [80]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.