Recognition: 2 theorem links
· Lean TheoremLASAR: Latent Adaptive Semantic Aligned Reasoning for Generative Recommendation
Pith reviewed 2026-05-12 04:52 UTC · model grok-4.3
The pith
Aligning latent hidden states to chain-of-thought anchors and adapting reasoning depth lets generative recommenders match or beat explicit CoT performance at far lower cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
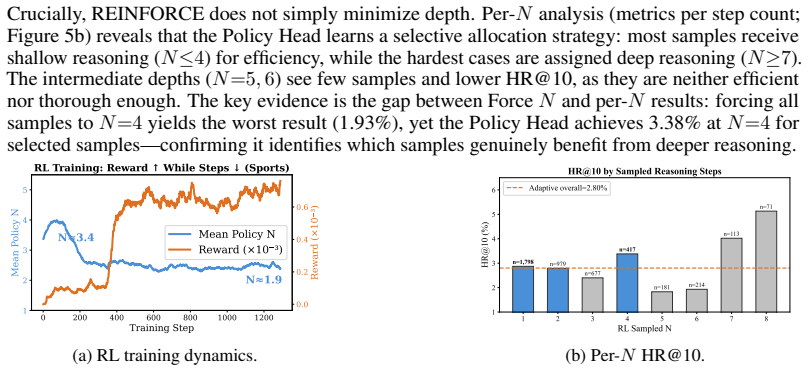
LASAR first grounds Semantic ID semantics in a two-stage supervised fine-tuning process, then constrains the latent reasoning trajectory with step-wise bidirectional KL divergence to hidden-state anchors extracted from explicit CoT text, and finally applies GRPO-based reinforcement learning with terminal-only KL alignment plus REINFORCE optimization of a Policy Head that predicts per-sample reasoning depth; this combination closes the SID-to-latent gap, prevents representation drift, halves average latent step count, and yields higher recommendation quality than baselines on three real-world datasets while adding only marginal inference latency.
What carries the argument
Step-wise bidirectional KL divergence that anchors the latent trajectory to hidden states from explicit CoT text, together with a Policy Head that learns to output variable reasoning depth and is refined by REINFORCE during the RL phase.
If this is right
- Recommendation accuracy rises above all tested baselines on three real-world datasets.
- Average latent reasoning steps drop by nearly half while recommendation quality still improves.
- Inference runs roughly twenty times faster than methods that generate explicit CoT text.
- Added inference latency remains marginal compared with standard generative recommendation pipelines.
- The same alignment and adaptive-depth mechanism supports terminal-only KL constraints during reinforcement learning.
Where Pith is reading between the lines
- The same hidden-state anchoring technique could scaffold latent reasoning in other generative tasks where full text output is too slow.
- Variable per-example depth prediction may prove useful in any setting where input complexity varies widely.
- If the alignment remains stable, interactive recommendation interfaces could shift from token generation to compact latent steps without losing interpretability.
Load-bearing premise
That anchors taken from explicit CoT text supply unbiased and sufficient supervision for the latent trajectory, and that the two-stage grounding plus KL alignment can prevent drift without lowering final recommendation quality.
What would settle it
A controlled ablation that removes the KL alignment step and shows no drop in recommendation metrics or no reduction in measured representation drift between latent states and CoT hidden states.
Figures





read the original abstract
Large Language Models (LLMs) have demonstrated powerful reasoning capabilities through Chain-of-Thought (CoT) in various tasks, yet the inefficiency of token-by-token generation hinders real-world deployment in latency-sensitive recommender systems. Latent reasoning has emerged as an effective paradigm in LLMs, performing multi-step inference in a continuous hidden-state space to achieve stronger reasoning at lower cost. However, this paradigm remains underexplored in mainstream generative recommendation. Adapting it reveals three unique challenges: (1) the gap between prior-less Semantic ID (SID) symbols and continuous latent reasoning - SIDs lack pre-trained semantics, hindering joint optimization; (2) representation drift due to a lack of reasoning chain supervision; and (3) the suboptimality of applying a globally fixed reasoning depth. To address these, we propose LASAR (Latent Adaptive Semantic Aligned Reasoning), an SFT-then-RL framework. First, we bridge this gap via two-stage training: Stage 1 grounds SID semantics before Stage 2 introduces latent reasoning, ensuring efficient convergence. Second, we mitigate representation drift through explicit CoT semantic alignment. Step-wise bidirectional KL divergence constrains the latent reasoning trajectory using hidden-state anchors extracted from CoT text, while a Policy Head predicts per-sample reasoning depth. Third, during the GRPO-based RL phase, terminal-only KL alignment accommodates variable-length reasoning, and REINFORCE optimizes the Policy Head to dynamically allocate steps. This nearly halves the average latent step count while simultaneously improving recommendation quality. Experiments on three real-world datasets demonstrate that LASAR outperforms all baselines. It adds marginal inference latency and is roughly 20 times faster than generating explicit CoT text.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LASAR, an SFT-then-RL framework for latent adaptive semantic aligned reasoning in generative recommendation. It addresses gaps between Semantic IDs and continuous latent reasoning via two-stage grounding, uses step-wise bidirectional KL divergence on CoT hidden-state anchors to mitigate representation drift, introduces a Policy Head for per-sample adaptive reasoning depth, and applies GRPO-based RL with terminal-only KL and REINFORCE optimization. Experiments on three real-world datasets are claimed to show outperformance over baselines, marginal added inference latency, and roughly 20x speedup versus explicit CoT text generation.
Significance. If the empirical claims hold with proper validation, the work could advance efficient multi-step reasoning for latency-sensitive recommender systems by shifting from token-by-token CoT to continuous hidden-state trajectories while preserving recommendation quality. The two-stage training, bidirectional alignment, and adaptive depth via Policy Head represent a coherent attempt to adapt latent reasoning paradigms to SID-based generative recsys, with potential for broader impact if the alignment mechanism proves robust.
major comments (2)
- [Abstract] Abstract: The central claims of outperforming all baselines on three datasets and achieving ~20x speedup with marginal latency are presented without any quantitative metrics, baseline descriptions, statistical significance tests, or implementation details. This is load-bearing because the primary contribution is empirical and the abstract supplies no evidence to evaluate soundness or reproducibility.
- [Abstract] Abstract (method description): The assertion that step-wise bidirectional KL alignment with CoT hidden-state anchors prevents representation drift without harming final quality rests on the untested assumption that these anchors provide unbiased, sufficient step-wise supervision. No evidence is supplied that the anchors capture full multi-step reasoning structure (rather than marginal statistics) or that terminal-only KL in the GRPO phase preserves alignment across variable depths.
minor comments (2)
- The description of the two-stage training and Policy Head could include explicit notation or pseudocode for the per-sample depth prediction and KL terms to improve clarity.
- Clarify whether the three datasets are standard public benchmarks and list the exact baselines compared against.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We agree the abstract requires strengthening with quantitative details and have revised it accordingly. We address each point below with references to the manuscript's empirical results and clarifications.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of outperforming all baselines on three datasets and achieving ~20x speedup with marginal latency are presented without any quantitative metrics, baseline descriptions, statistical significance tests, or implementation details. This is load-bearing because the primary contribution is empirical and the abstract supplies no evidence to evaluate soundness or reproducibility.
Authors: We agree the abstract would benefit from more concrete evidence. In the revised version we have added specific quantitative results drawn from the experiments section, including relative improvements over baselines on each of the three datasets, the measured average speedup factor (approximately 20x versus explicit CoT), confirmation of marginal added latency, and a note that all comparisons include statistical significance testing as detailed in Section 5. Baseline names and high-level implementation settings are now briefly referenced. These additions keep the abstract concise while directly supporting the empirical claims. revision: yes
-
Referee: [Abstract] Abstract (method description): The assertion that step-wise bidirectional KL alignment with CoT hidden-state anchors prevents representation drift without harming final quality rests on the untested assumption that these anchors provide unbiased, sufficient step-wise supervision. No evidence is supplied that the anchors capture full multi-step reasoning structure (rather than marginal statistics) or that terminal-only KL in the GRPO phase preserves alignment across variable depths.
Authors: The abstract is a high-level summary; supporting evidence appears in the full manuscript. Section 4.2 describes how CoT hidden states serve as step-wise anchors because they are extracted directly from explicit multi-step reasoning trajectories, and the bidirectional KL is applied at each latent step to enforce alignment. Experiments in Section 5.3 and the associated ablations demonstrate that this alignment reduces representation drift (measured via hidden-state divergence) while improving final recommendation quality, indicating the anchors capture sequential structure beyond marginal statistics. For the GRPO phase, Section 4.3 explains that terminal-only KL is combined with the Policy Head's adaptive depth selection; results show that variable-depth trajectories maintain quality gains without drift accumulation. We have added a short clarifying sentence to the abstract and expanded the discussion in Section 4.3 to explicitly reference these empirical validations. revision: partial
Circularity Check
No circularity: LASAR's claims rest on empirical validation of a novel two-stage SFT+RL pipeline rather than self-referential definitions or fitted quantities.
full rationale
The paper introduces LASAR as an SFT-then-RL framework that first grounds Semantic ID semantics, then applies step-wise bidirectional KL alignment between latent trajectories and explicit CoT hidden-state anchors, followed by GRPO with terminal-only KL and REINFORCE for adaptive depth. None of these components reduce to their inputs by construction: the anchors are extracted from a separate explicit CoT process, the KL objectives are standard divergence terms with new application to recommendation latent space, and the performance claims (outperformance on three datasets, ~20x speedup, halved step count) are presented as experimental outcomes rather than algebraic identities or renamed fits. No self-citation chain, uniqueness theorem, or ansatz smuggling is invoked in the provided text to justify core choices. The derivation chain is self-contained against external benchmarks and does not exhibit any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
free parameters (2)
- KL divergence weights
- Policy Head parameters
axioms (2)
- domain assumption Semantic IDs lack pre-trained semantics and require explicit two-stage grounding before latent reasoning can be introduced
- domain assumption Hidden states from explicit CoT text form reliable anchors that can supervise latent reasoning without introducing bias
Lean theorems connected to this paper
-
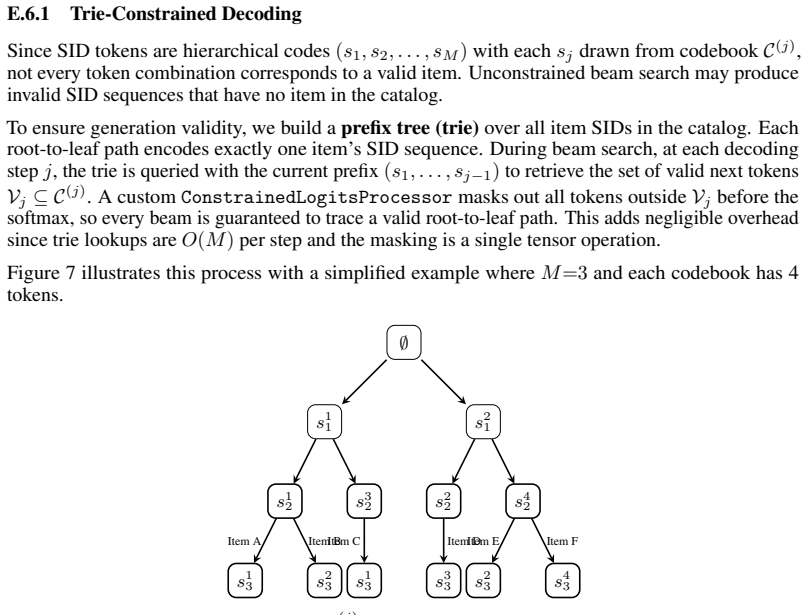
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearStep-wise bidirectional KL divergence constrains the latent reasoning trajectory using hidden-state anchors extracted from CoT text
Reference graph
Works this paper leans on
-
[1]
Keqin Bao, Jizhi Zhang, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He. Tall- rec: An effective and efficient tuning framework to align large language model with rec- ommendation. In Jie Zhang, Li Chen, Shlomo Berkovsky, Min Zhang, Tommaso Di Noia, Justin Basilico, Luiz Pizzato, and Yang Song, editors,Proceedings of the 17th ACM Conference on Recomme...
-
[2]
In: Wooldridge, M.J., Dy, J.G., Natarajan, S
Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, and Torsten Hoefler. Graph of thoughts: Solving elaborate problems with large language mod- els. In Michael J. Wooldridge, Jennifer G. Dy, and Sriraam Natarajan, editors,Thirty-Eighth AAAI Conf...
-
[3]
Haolin Chen, Yihao Feng, Zuxin Liu, Weiran Yao, Akshara Prabhakar, Shelby Heinecke, Ricky Ho, Phil Mui, Silvio Savarese, Caiming Xiong, and Huan Wang. Language models are hidden reasoners: Unlocking latent reasoning capabilities via self-rewarding.CoRR, abs/2411.04282,
-
[6]
Zeyu Cui, Jianxin Ma, Chang Zhou, Jingren Zhou, and Hongxia Yang. M6-rec: Generative pretrained language models are open-ended recommender systems.CoRR, abs/2205.08084,
-
[12]
Towards revealing the mystery behind chain of thought: A theoretical perspective
Guhao Feng, Bohang Zhang, Yuntian Gu, Haotian Ye, Di He, and Liwei Wang. Towards revealing the mystery behind chain of thought: A theoretical perspective. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, edi- tors,Advances in Neural Information Processing Systems 36: Annual Conference on Neu- ral Information Proc...
work page 2023
-
[13]
Think-at-Hard: Selective Latent Iterations to Improve Reasoning Language Models
Tianyu Fu, Yichen You, Zekai Chen, Guohao Dai, Huazhong Yang, and Yu Wang. Think-at- hard: Selective latent iterations to improve reasoning language models.CoRR, abs/2511.08577,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. Recommendation as language processing (RLP): A unified pretrain, personalized prompt & predict paradigm (P5). In Jennifer Golbeck, F. Maxwell Harper, Vanessa Murdock, Michael D. Ekstrand, Bracha Shapira, Justin Basilico, Keld T. Lundgaard, and Even Oldridge, editors,RecSys ’22: Sixtee...
-
[17]
Think before you speak: Training language models with pause tokens
Sachin Goyal, Ziwei Ji, Ankit Singh Rawat, Aditya Krishna Menon, Sanjiv Kumar, and Vaishnavh Nagarajan. Think before you speak: Training language models with pause tokens. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL https://openreview.net/forum? id=ph04CRkPdC
work page 2024
-
[20]
Session-based recommendations with recurrent neural networks
Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk. Session-based recommendations with recurrent neural networks. In Yoshua Bengio and Yann LeCun, editors, 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May 2-4, 2016, Conference Track Proceedings, 2016. URL http://arxiv.org/abs/1511. 06939
work page 2016
-
[22]
How to index item ids for recommendation foundation models
Wenyue Hua, Shuyuan Xu, Yingqiang Ge, and Yongfeng Zhang. How to index item ids for recommendation foundation models. In Qingyao Ai, Yiqin Liu, Alistair Moffat, Xuanjing Huang, Tetsuya Sakai, and Justin Zobel, editors,Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region, SIGIR-AP 2023, B...
-
[23]
Haonan Li, Yixuan Zhang, Fajri Koto, Yifei Yang, Hai Zhao, Yeyun Gong, Nan Duan, and Timothy Baldwin
Clark Mingxuan Ju, Liam Collins, Leonardo Neves, Bhuvesh Kumar, Louis Yufeng Wang, Tong Zhao, and Neil Shah. Generative recommendation with semantic ids: A practitioner’s handbook. In Meeyoung Cha, Chanyoung Park, Noseong Park, Carl Yang, Senjuti Basu Roy, Jessie Li, Jaap Kamps, Kijung Shin, Bryan Hooi, and Lifang He, editors,Proceedings of the 34th ACM I...
-
[24]
Wang-Cheng Kang and Julian J. McAuley. Self-attentive sequential recommendation. In IEEE International Conference on Data Mining, ICDM 2018, Singapore, November 17-20, 2018, pages 197–206. IEEE Computer Society, 2018. doi: 10.1109/ICDM.2018.00035. URL https://doi.org/10.1109/ICDM.2018.00035. 11
-
[25]
Large language models are zero-shot reasoners
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwa- sawa. Large language models are zero-shot reasoners. In Sanmi Koyejo, S. Mo- hamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors,Advances in Neu- ral Information Processing Systems 35: Annual Conference on Neural Information Pro- cessing Systems 2022, NeurIPS 2022,...
work page 2022
-
[28]
Jiacheng Lin, Tian Wang, and Kun Qian. Rec-r1: Bridging generative large language models and user-centric recommendation systems via reinforcement learning.Trans. Mach. Learn. Res., 2025, 2025. URLhttps://openreview.net/forum?id=YBRU9MV2vE
work page 2025
-
[29]
How can recommender systems benefit from large language models: A survey.ACM Trans
Jianghao Lin, Xinyi Dai, Yunjia Xi, Weiwen Liu, Bo Chen, Hao Zhang, Yong Liu, Chuhan Wu, Xiangyang Li, Chenxu Zhu, Huifeng Guo, Yong Yu, Ruiming Tang, and Weinan Zhang. How can recommender systems benefit from large language models: A survey.ACM Trans. Inf. Syst., 43(2):28:1–28:47, 2025. doi: 10.1145/3678004. URL https://doi.org/10.1145/3678004
-
[30]
LARES: latent reasoning for sequential recommendation.CoRR, abs/2505.16865,
Enze Liu, Bowen Zheng, Xiaolei Wang, Wayne Xin Zhao, Jinpeng Wang, Sheng Chen, and Ji-Rong Wen. LARES: latent reasoning for sequential recommendation.CoRR, abs/2505.16865,
-
[32]
The expressive power of transformers with chain of thought
William Merrill and Ashish Sabharwal. The expressive power of transformers with chain of thought. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL https://openreview.net/ forum?id=NjNGlPh8Wh
work page 2024
-
[33]
Jianmo Ni, Jiacheng Li, and Julian J. McAuley. Justifying recommendations using distantly- labeled reviews and fine-grained aspects. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xi- aojun Wan, editors,Proceedings of the 2019 Conference on Empirical Methods in Natu- ral Language Processing and the 9th International Joint Conference on Natural Language Proc...
work page 2019
-
[34]
Association for Computational Linguistics, 2019. doi: 10.18653/V1/D19-1018. URL https://doi.org/10.18653/v1/D19-1018
-
[37]
Tran, Jonah Samost, Maciej Kula, Ed H
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Q. Tran, Jonah Samost, Maciej Kula, Ed H. Chi, and Mahesh Sathiamoorthy. Recommender systems with generative retrieval. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, edi- tors,Advances in...
work page 2023
-
[38]
Nikunj Saunshi, Nishanth Dikkala, Zhiyuan Li, Sanjiv Kumar, and Sashank J. Reddi. Reasoning with latent thoughts: On the power of looped transformers. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenRe- view.net, 2025. URLhttps://openreview.net/forum?id=din0lGfZFd
work page 2025
-
[41]
CODI: compress- ing chain-of-thought into continuous space via self-distillation
Zhenyi Shen, Hanqi Yan, Linhai Zhang, Zhanghao Hu, Yali Du, and Yulan He. CODI: compress- ing chain-of-thought into continuous space via self-distillation. In Christos Christodoulopou- los, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, EMNLP 2025, Suzhou, ...
-
[43]
Charlie Victor Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time com- pute optimally can be more effective than scaling parameters for reasoning. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28,
work page 2025
-
[44]
URLhttps://openreview.net/forum?id=4FWAwZtd2n
OpenReview.net, 2025. URLhttps://openreview.net/forum?id=4FWAwZtd2n
work page 2025
-
[45]
Token assorted: Mixing latent and text tokens for improved language model reasoning
DiJia Su, Hanlin Zhu, Yingchen Xu, Jiantao Jiao, Yuandong Tian, and Qinqing Zheng. Token assorted: Mixing latent and text tokens for improved language model reasoning. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,Forty-second International Conference on Machine Learn...
work page 2025
-
[46]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang. Bert4rec: Sequential recommendation with bidirectional encoder representations from transformer. In Wenwu Zhu, Dacheng Tao, Xueqi Cheng, Peng Cui, Elke A. Rundensteiner, David Carmel, Qi He, and Jeffrey Xu Yu, editors,Proceedings of the 28th ACM International Conference on Inform...
-
[48]
Alicia Tsai, Adam Kraft, Long Jin, Chenwei Cai, Anahita Hosseini, Taibai Xu, Zemin Zhang, Lichan Hong, Ed Huai-hsin Chi, and Xinyang Yi. Leveraging LLM reasoning enhances per- sonalized recommender systems. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and ...
-
[49]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V . Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language 13 models. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. URL https://openreview.net/ for...
work page 2023
-
[50]
EAGER: two-stream generative recommender with behavior-semantic collaboration
Ye Wang, Jiahao Xun, Minjie Hong, Jieming Zhu, Tao Jin, Wang Lin, Haoyuan Li, Linjun Li, Yan Xia, Zhou Zhao, and Zhenhua Dong. EAGER: two-stream generative recommender with behavior-semantic collaboration. In Ricardo Baeza-Yates and Francesco Bonchi, editors, Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD 2024, B...
-
[51]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems 35: Annual Conference on Neura...
work page 2022
-
[52]
C-pack: Packaged resources to advance general chinese embedding, 2023
Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighoff. C-pack: Packaged resources to advance general chinese embedding, 2023
work page 2023
-
[54]
Softcot: Soft chain-of-thought for efficient reasoning with llms
Yige Xu, Xu Guo, Zhiwei Zeng, and Chunyan Miao. Softcot: Soft chain-of-thought for efficient reasoning with llms. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna, Austria, July 27 - Augus...
work page 2025
-
[55]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Kun Yang, Yuxuan Zhu, Yazhe Chen, Siyao Zheng, Bangyang Hong, Kangle Wu, Yabo Ni, Anxiang Zeng, Cong Fu, and Hui Li. Mancar: Manifold-constrained latent reasoning with adaptive test-time computation for sequential recommendation.CoRR, abs/2602.20093,
-
[58]
Tree of thoughts: Deliberate problem solving with large language models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors,Advances in Neural Information Processing Systems 36: Annual Conference on Neural Inf...
work page 2023
-
[61]
Towards reasoning-aware recommender systems: A survey in the llm era
Jiaqi Zhang, Junliang Yu, Zongwei Wang, Wei Yuan, Tong Chen, Quoc Viet Hung Nguyen, Bin Cui, and Hongzhi Yin. Towards reasoning-aware recommender systems: A survey in the llm era. TechRxiv, 2025(1117), 2025. doi: 10.36227/techrxiv.176287939.92578520/v2. URL https: //www.techrxiv.org/doi/abs/10.36227/techrxiv.176287939.92578520/v2
-
[63]
Reinforced latent reasoning for llm-based recommendation,
Yang Zhang, Wenxin Xu, Xiaoyan Zhao, Wenjie Wang, Fuli Feng, Xiangnan He, and Tat-Seng Chua. Reinforced latent reasoning for llm-based recommendation.CoRR, abs/2505.19092,
-
[64]
Language Model Cascades: Token-Level Uncertainty and Beyond
doi: 10.48550/ARXIV .2505.19092. URL https://doi.org/10.48550/arXiv.2505. 19092
work page internal anchor Pith review doi:10.48550/arxiv
-
[65]
Adapting large language models by integrating collaborative semantics for recommen- dation
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, Ming Chen, and Ji-Rong Wen. Adapting large language models by integrating collaborative semantics for recommenda- tion. In40th IEEE International Conference on Data Engineering, ICDE 2024, Utrecht, The Netherlands, May 13-16, 2024, pages 1435–1448. IEEE, 2024. doi: 10.1109/ICDE60146.2024. 00118....
-
[66]
Prompt left-padding: Left-pad prompts with pad_token_id to the batch’s maximum prompt length, aligning the first⟨thought⟩position across all samples
-
[67]
Per-sample latent insertion: Insert Ni copies of ⟨thought⟩ per sample after the prompt, producing naturally different latent region lengths
-
[68]
Latent region right-padding: For samples with Ni <max(N) , pad the remaining latent slots with pad_token_id (not ⟨thought⟩) and set attention mask to 0. The latent loop 19 iterates max(N) times uniformly; extra steps for short- N samples operate on masked positions and produce hidden states that are ignored by subsequent attention
-
[69]
Sequence right-padding: Use pad_sequence to align total sequence lengths (prompt + latent region + answer) to the batch maximum
-
[70]
Loss masking: The LM loss is computed only on answer tokens, and the alignment loss filters positions exceeding each sample’s actual Ni via a valid_mask, so padded latent positions contribute zero gradient. E.2 Prompt Format and CoT Reasoning Details All generative methods (LASAR, MiniOneRec, LC-Rec, and Explicit CoTGREAM) share an identical prompt templa...
-
[71]
Semantic segment matching: Use cumsum to compute each latent token’s ordinal within the batch, vectorized-matching to the corresponding CoT segment
-
[72]
Boundary safety: Filter out samples where N exceeds the number of CoT segments to prevent out-of-bounds access
-
[73]
Device consistency: CoT embeddings are preloaded on CPU and dynamically converted to GPU dtype and device during training. E.4 RL Phase Terminal Alignment RL-phase alignment targets only thelastlatent step of the reasoning chain:
-
[74]
Natural latent embedding collection: During Phase 2 training, hidden states from each step of the latent loop are automatically collected as a latent_embs list (cached from the forward pass, with no extra forward passes needed)
-
[75]
Dynamic step indexing: latent_embs[N−1] directly retrieves the last step’s hidden state for bidirectional KL computation with the CoT final state
-
[76]
Adding it as a direct loss to the total objective ensures stable gradient signals
Alignment as direct loss, not reward: If alignment were a reward component, GRPO’s within-group advantage zero-mean property would cancel it out. Adding it as a direct loss to the total objective ensures stable gradient signals. E.5 Reward Formulation For each prompt,Gcandidates are generated via beam search. The exact match reward is: r(i) rule = 1ifˆy (...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.