Recognition: 2 theorem links
· Lean TheoremParameterized Complexity of Stationarity Testing for Piecewise-Affine Functions and Shallow CNN Losses
Pith reviewed 2026-05-12 03:27 UTC · model grok-4.3
The pith
Testing approximate stationarity for continuous piecewise-affine functions is XP-tractable in fixed dimension for some cases but W[1]-hard for others, with ETH lower bounds excluding subexponential dependence on dimension.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the parameterized complexity of approximate stationarity testing for continuous piecewise-affine functions, with dimension d as parameter, consists of XP algorithms on the tractable sides, W[1]-hardness on the complementary sides, and ETH-based lower bounds ruling out any runtime rho(d) size^{o(d)} for computable rho. These results immediately yield the corresponding parameterized picture for testing local minimality of continuous PA functions and extend directly to stationarity testing for a family of shallow ReLU CNN training losses when stationarity is checked in the trainable weight space.
What carries the argument
The ambient dimension d as the parameter for XP algorithms and W[1]-hardness reductions on the stationarity-testing problem for continuous piecewise-affine functions and shallow ReLU CNN losses.
If this is right
- XP algorithms exist for the tractable sides of stationarity testing when dimension is fixed.
- W[1]-hardness holds for the complementary sides, so no FPT algorithm is expected unless FPT equals W[1].
- Exponential Time Hypothesis lower bounds prohibit algorithms whose dependence on input size is subexponential in dimension.
- The identical complexity classification holds for testing local minimality of continuous piecewise-affine functions.
- The same XP-versus-W[1]-hardness picture applies to stationarity testing for shallow ReLU CNN losses in the weight space.
Where Pith is reading between the lines
- Practical stationarity checks for neural-network losses may remain feasible only when dimension stays small or when additional structure beyond the piecewise-affine model is exploited.
- The hardness results suggest that exact first-order verification inside even simple CNN training objectives is unlikely to scale with dimension without further restrictions.
- Similar parameterized analyses could be applied to other nonsmooth optimization primitives that share the same polyhedral local geometry.
- Average-case or smoothed versions of the stationarity-testing problem might admit better parameterized runtimes than the worst-case picture obtained here.
Load-bearing premise
That continuous piecewise-affine functions adequately capture the local polyhedral geometry of ReLU-type losses and that the chosen notion of approximate first-order stationarity is the right one for the parameterized analysis.
What would settle it
Discovery of an algorithm solving the stationarity-testing problem in time f(d) times size to the o(d) for some computable f, or a polynomial-time algorithm for any of the W[1]-hard cases when dimension is fixed, would refute the stated lower bounds.
Figures
read the original abstract
We study the parameterized complexity of testing approximate first-order stationarity at a prescribed point for continuous piecewise-affine (PA) functions, a basic task in nonsmooth optimization. PA functions form a canonical model for nonsmooth stationarity testing and capture the local polyhedral geometry that appears in ReLU-type training losses. Recent work by Tian and So (SODA 2025) shows that testing approximate stationarity notions for PA functions is computationally intractable in the worst case, and identifies fixed-dimensional tractability as an open direction. We address this direction from the viewpoint of parameterized complexity, with the ambient dimension $d$ as the parameter. In this paper, we give XP algorithms in fixed dimension for the tractable sides, and prove W[1]-hardness for the complementary sides. Moreover, lower bounds under the Exponential Time Hypothesis rule out algorithms running in time $\rho(d)\size^{o(d)}$ for any computable function $\rho$, where $\size$ denotes the total binary encoding length of the stationarity-testing instance. As a further consequence, our results yield the corresponding parameterized complexity picture for testing local minimality of continuous PA functions. We further extend our hardness results to a family of shallow ReLU CNN training losses, with stationarity tested in the trainable weight space. Thus, the same parameterized-complexity picture also appears for simple CNN training losses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies the parameterized complexity of testing approximate first-order stationarity at a given point for continuous piecewise-affine (PA) functions, taking ambient dimension d as the parameter. It establishes XP algorithms (n^{f(d)} time) for the tractable variants via dynamic programming over hyperplane arrangements, W[1]-hardness for the complementary variants via dimension-preserving reductions, and ETH-based lower bounds excluding any algorithm running in time ρ(d)·size^{o(d)} for computable ρ. The same complexity picture is shown to hold for testing local minimality of PA functions and is extended to stationarity testing (in weight space) for a family of shallow ReLU CNN training losses.
Significance. If the technical claims hold, the work resolves the fixed-dimensional tractability question left open by Tian and So (SODA 2025) and supplies a complete parameterized-complexity classification for a canonical model of nonsmooth stationarity testing. The extension to shallow CNN losses demonstrates that the same hardness/tractability dichotomy appears in a concrete neural-network setting. The reliance on standard parameterized reductions and explicit dynamic-programming constructions over arrangements is a methodological strength.
minor comments (3)
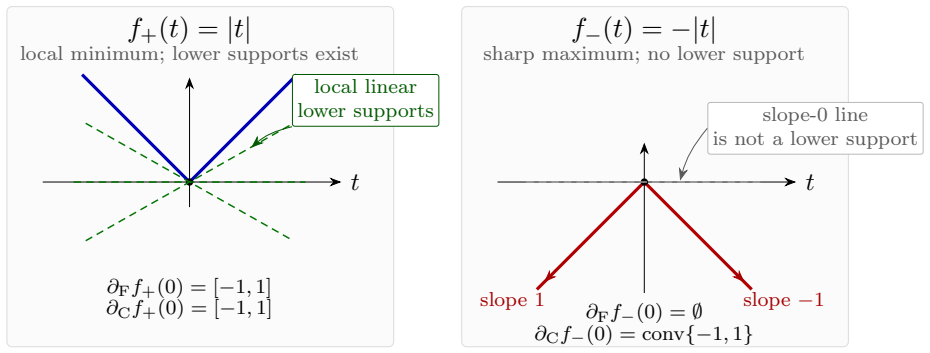
- [Abstract / §1] The abstract and introduction refer to “the tractable sides” and “the complementary sides” without immediately naming the precise stationarity notions (e.g., which subdifferential or directional-derivative conditions) that fall on each side; a short clarifying sentence or table would improve readability.
- [§3 (or wherever the ETH statement appears)] In the ETH lower-bound statement, the quantity “size” is defined as the total binary encoding length of the instance; it would be helpful to state explicitly whether this includes the bit length of the rational coefficients of the PA pieces or only the combinatorial description.
- [§5] The extension to shallow ReLU CNN losses is described as an “embedding” of the weight-space stationarity test into an equivalent PA instance; a brief paragraph sketching the dimension and size blow-up of this reduction would make the claim easier to verify.
Simulated Author's Rebuttal
We thank the referee for their positive summary of our manuscript, for highlighting its significance in resolving the open question from Tian and So (SODA 2025), and for recommending minor revision. We are pleased that the parameterized complexity classification for stationarity testing of PA functions and its extension to shallow ReLU CNN losses is viewed as a methodological strength.
Circularity Check
No significant circularity detected
full rationale
The paper's core results consist of XP algorithms via dynamic programming on hyperplane arrangements for fixed dimension, W[1]-hardness via standard parameterized reductions, and ETH-based lower bounds excluding subexponential dependence on dimension. These follow directly from established parameterized complexity machinery and the prior intractability result of Tian and So (SODA 2025), with no self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations. The CNN extension is a straightforward embedding reduction into an equivalent PA instance. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Exponential Time Hypothesis (ETH)
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.lean, AlexanderDuality.leanreality_from_one_distinction unclearLemma 2.4 (Characterization of Fréchet stationarity): ... s + Y ⊆ X ... Lemma 2.5 (Clarke): conv(Se(X,Y)) via simultaneously exposed vertices
Reference graph
Works this paper leans on
- [1]
-
[2]
M. K. Kozlov and S. P. Tarasov and L. G. Khachiyan , title =
-
[3]
Advances in Neural Information Processing Systems , volume =
Stargalla, Moritz and Hertrich, Christoph and Reichman, Daniel , title =. Advances in Neural Information Processing Systems , volume =
- [4]
-
[5]
Proceedings of the 42nd International Conference on Machine Learning , pages =
An Online Adaptive Sampling Algorithm for Stochastic Difference-of-convex Optimization with Time-varying Distributions , author =. Proceedings of the 42nd International Conference on Machine Learning , pages =. 2025 , volume =
work page 2025
- [6]
- [7]
- [8]
-
[9]
Stefan Scholtes , title =
-
[10]
Sergei Ovchinnikov , title =. Beitr
-
[11]
Katta G. Murty and Santosh N. Kabadi , title =. Mathematical Programming , volume =
-
[12]
Mathematical Programming , volume =
Yurii Nesterov , title =. Mathematical Programming , volume =
-
[13]
Advances in Mathematics , volume =
Amir Ali Ahmadi and Jeffrey Zhang , title =. Advances in Mathematics , volume =
-
[14]
Mathematical Programming , volume =
Amir Ali Ahmadi and Jeffrey Zhang , title =. Mathematical Programming , volume =
-
[15]
Jiajin Li and Anthony Man-Cho So and Wing-Kin Ma , title =
-
[16]
Damek Davis and Dmitriy Drusvyatskiy , title =
-
[17]
Damek Davis and Dmitriy Drusvyatskiy and Sham M. Kakade and Jason D. Lee , title =. Foundations of Computational Mathematics , volume =
-
[18]
Proceedings of the 37th International Conference on Machine Learning , series =
Jingzhao Zhang and Hongzhou Lin and Stefanie Jegelka and Suvrit Sra and Ali Jadbabaie , title =. Proceedings of the 37th International Conference on Machine Learning , series =
-
[19]
Proceedings of the 39th International Conference on Machine Learning , series =
Lai Tian and Kaiwen Zhou and Anthony Man-Cho So , title =. Proceedings of the 39th International Conference on Machine Learning , series =
-
[20]
Advances in Neural Information Processing Systems , volume =
Guy Kornowski and Ohad Shamir , title =. Advances in Neural Information Processing Systems , volume =
-
[21]
Proceedings of the 36th Conference on Learning Theory , series =
Michael Jordan and Guy Kornowski and Tianyi Lin and Ohad Shamir and Manolis Zampetakis , title =. Proceedings of the 36th Conference on Learning Theory , series =
-
[22]
Mathematical Programming , volume =
Lai Tian and Anthony Man-Cho So , title =. Mathematical Programming , volume =
- [23]
-
[24]
Proceedings of the 2025 Annual
Lai Tian and Anthony Man-Cho So , title =. Proceedings of the 2025 Annual
work page 2025
- [25]
-
[26]
International Conference on Learning Representations , year =
Raman Arora and Amitabh Basu and Poorya Mianjy and Anirbit Mukherjee , title =. International Conference on Learning Representations , year =
-
[27]
Guido F. Mont. On the Number of Linear Regions of Deep Neural Networks , booktitle =
-
[28]
Journal of Artificial Intelligence Research , volume =
Vincent Froese and Christoph Hertrich and Rolf Niedermeier , title =. Journal of Artificial Intelligence Research , volume =
-
[29]
SIAM Journal on Computing , volume =
Herbert Edelsbrunner and Joseph O'Rourke and Raimund Seidel , title =. SIAM Journal on Computing , volume =
-
[30]
Advances in Neural Information Processing Systems , volume =
Vincent Froese and Christoph Hertrich , title =. Advances in Neural Information Processing Systems , volume =
-
[31]
Proceedings of the 38th Conference on Learning Theory , series =
Vincent Froese and Moritz Grillo and Martin Skutella , title =. Proceedings of the 38th Conference on Learning Theory , series =
-
[32]
Proceedings of the 38th Conference on Learning Theory , series =
Vincent Froese and Moritz Grillo and Christoph Hertrich and Martin Skutella , title =. Proceedings of the 38th Conference on Learning Theory , series =
-
[33]
International Conference on Learning Representations , note =
Vincent Froese and Moritz Grillo and Christoph Hertrich and Moritz Stargalla , title =. International Conference on Learning Representations , note =
-
[34]
European Journal of Control , volume =
Adrian Kulmburg and Matthias Althoff , title =. European Journal of Control , volume =
-
[35]
Bodlaender and Peter Gritzmann and Victor Klee and Jan van Leeuwen , title =
Hans L. Bodlaender and Peter Gritzmann and Victor Klee and Jan van Leeuwen , title =. Combinatorica , volume =
-
[36]
Jean-Antoine Ferrez and Komei Fukuda and Thomas M. Liebling , title =. European Journal of Operational Research , volume =
-
[37]
Theoretical Computer Science , volume =
Vladimir Shenmaier , title =. Theoretical Computer Science , volume =
-
[38]
Sadra Sadraddini and Russ Tedrake , title =. 2019
work page 2019
-
[39]
Volker Kaibel and Marc E. Pfetsch , title =. Algebra, Geometry, and Software Systems , pages =
- [40]
-
[41]
Memoirs of the American Mathematical Society , volume =
Thomas Zaslavsky , title =. Memoirs of the American Mathematical Society , volume =
- [42]
-
[43]
Dill and Kyle Julian and Mykel J
Guy Katz and Clark Barrett and David L. Dill and Kyle Julian and Mykel J. Kochenderfer , title =. Computer Aided Verification , series =
-
[44]
Guy Katz and Derek A. Huang and Duligur Ibeling and Kyle Julian and Christopher Lazarus and Rachel Lim and Parth Shah and Shantanu Thakoor and Haoze Wu and Aleksandar Zeljic and David L. Dill and Mykel J. Kochenderfer and Clark Barrett , title =. Computer Aided Verification , series =
-
[45]
Advances in Neural Information Processing Systems , volume =
Aladin Virmaux and Kevin Scaman , title =. Advances in Neural Information Processing Systems , volume =
-
[46]
Matt Jordan and Alexandros G. Dimakis , title =. Advances in Neural Information Processing Systems , volume =
-
[47]
Advances in Neural Information Processing Systems , volume =
Christoph Hertrich and Amitabh Basu and Marco Di Summa and Martin Skutella , title =. Advances in Neural Information Processing Systems , volume =
-
[48]
arXiv preprint arXiv:2411.03006 , year =
Christoph Hertrich and Georg Loho , title =. arXiv preprint arXiv:2411.03006 , year =
-
[49]
International Conference on Learning Representations , year =
Chulhee Yun and Suvrit Sra and Ali Jadbabaie , title =. International Conference on Learning Representations , year =
-
[50]
Ying Cui and Jong-Shi Pang , title =
-
[51]
arXiv preprint arXiv:2505.07143 , year =
Hanyang Li and Ying Cui , title =. arXiv preprint arXiv:2505.07143 , year =
-
[52]
Geometric Algorithms and Combinatorial Optimization , series =
Martin Gr. Geometric Algorithms and Combinatorial Optimization , series =
-
[53]
Yurii Nesterov and Arkadii Nemirovskii , title =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.