Recognition: 1 theorem link
· Lean TheoremRoute Before Retrieve: Activating Latent Routing Abilities of LLMs for RAG vs. Long-Context Selection
Pith reviewed 2026-05-13 07:42 UTC · model grok-4.3
The pith
LLMs can use lightweight metadata to proactively decide between RAG and full long-context processing before answering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
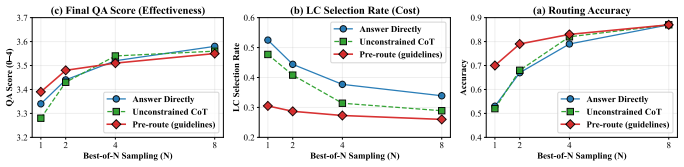
Pre-Route is a proactive framework that elicits LLMs' latent routing ability through structured reasoning on lightweight metadata before retrieval or full-context use. The approach produces explainable decisions and achieves better cost-effectiveness than fixed or reactive baselines. Key supporting results include single-pass performance approaching Best-of-N, improved separability of routing dimensions under structured prompts, and successful distillation to smaller models.
What carries the argument
Pre-Route framework: structured prompts that analyze task requirements, estimate coverage, and predict information needs from document metadata to decide RAG versus long-context routing.
If this is right
- Pre-Route achieves higher overall cost-effectiveness than Always-RAG, Always-LC, and Self-Route on LaRA and LongBench-v2.
- Single-sample routing guided by the structured prompt reaches performance close to multi-sample Best-of-N selection.
- Linear probes confirm that the structured prompt increases separability of the optimal routing choice in the model's representation space.
- Distillation successfully transfers the routing reasoning structure to smaller models for efficient deployment.
Where Pith is reading between the lines
- The same pre-decision structure could be tested for routing among additional strategies such as summarization-first or tool-augmented paths.
- Distilled smaller routers might enable early filtering of documents in large-scale retrieval systems without invoking the full model.
- Explicit pre-reasoning steps may generalize to activating other latent decision skills in LLMs beyond context-length choice.
- Position sensitivity in long contexts could be mitigated if routing decisions also select optimal context windows or chunk orders.
Load-bearing premise
Lightweight metadata such as document type, length, and initial snippet is sufficient to predict task needs and coverage accurately enough for reliable routing decisions.
What would settle it
A benchmark where routing accuracy based solely on metadata falls far below oracle routing performance, causing Pre-Route to underperform the Always-LC baseline on cost-adjusted accuracy.
Figures















read the original abstract
Recent advances in large language models (LLMs) have expanded the context window to beyond 128K tokens, enabling long-document understanding and multi-source reasoning. A key challenge, however, lies in choosing between retrieval-augmented generation (RAG) and long-context (LC) strategies: RAG is efficient but constrained by retrieval quality, while LC supports global reasoning at higher cost and with position sensitivity. Existing methods such as Self-Route adopt failure-driven fallback from RAG to LC, but remain passive, inefficient, and hard to interpret. We propose Pre-Route, a proactive routing framework that performs structured reasoning before answering. Using lightweight metadata (e.g., document type, length, initial snippet), Pre-Route enables task analysis, coverage estimation, and information-need prediction, producing explainable and cost-efficient routing decisions. Our study shows three key findings: (i) LLMs possess latent routing ability that can be reliably elicited with guidelines, allowing single-sample performance to approach that of multi-sample (Best-of-N) results; (ii) linear probes reveal that structured prompts sharpen the separability of the "optimal routing dimension" in representation space; and (iii) distillation transfers this reasoning structure to smaller models for lightweight deployment. Experiments on LaRA (in-domain) and LongBench-v2 (OOD) confirm that Pre-Route outperforms Always-RAG, Always-LC, and Self-Route baselines, achieving superior overall cost-effectiveness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Pre-Route, a proactive routing framework that activates LLMs' latent routing abilities via structured reasoning on lightweight metadata (document type, length, initial snippet) to decide between RAG and long-context (LC) strategies before generation. It reports three findings: (i) single-sample guided routing approaches Best-of-N performance, (ii) structured prompts improve separability of the optimal routing dimension in representation space via linear probes, and (iii) distillation transfers the structure to smaller models. Experiments on LaRA (in-domain) and LongBench-v2 (OOD) claim Pre-Route outperforms Always-RAG, Always-LC, and Self-Route in cost-effectiveness.
Significance. If the empirical claims hold, the work offers a timely advance in efficient long-document handling by shifting from reactive fallbacks (e.g., Self-Route) to proactive, explainable decisions that balance RAG efficiency against LC's global reasoning costs. The distillation result is a practical strength for deployment, and the representation-space analysis provides mechanistic insight. However, significance depends on stronger validation of the metadata-driven routing premise.
major comments (3)
- The central claim of superior cost-effectiveness rests on the premise that lightweight metadata alone enables reliable task analysis, coverage estimation, and information-need prediction. No ablation isolates the contribution of each metadata element, and no error analysis examines failure modes for multi-hop or position-sensitive queries on OOD data such as LongBench-v2; this is load-bearing for the routing reliability assertion.
- The linear-probe result (finding ii) demonstrates sharpened separability in representation space but only establishes correlation, not that the metadata signals are causally sufficient for accurate downstream routing decisions; a controlled test linking probe accuracy to end-to-end routing performance is needed.
- The abstract asserts quantitative superiority and three key findings without reporting specific metrics, error bars, or methodology details; the experiments section must supply these (e.g., exact cost-effectiveness deltas, variance across runs) to substantiate the outperformance over baselines.
minor comments (2)
- Clarify notation for the routing decision function and the exact definition of 'cost-effectiveness' (e.g., whether it combines latency, token cost, and accuracy with explicit weights).
- Add error bars and statistical significance tests to all performance tables comparing Pre-Route against the three baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for strengthening the empirical validation of Pre-Route. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: The central claim of superior cost-effectiveness rests on the premise that lightweight metadata alone enables reliable task analysis, coverage estimation, and information-need prediction. No ablation isolates the contribution of each metadata element, and no error analysis examines failure modes for multi-hop or position-sensitive queries on OOD data such as LongBench-v2; this is load-bearing for the routing reliability assertion.
Authors: We agree that isolating the contribution of each metadata element (document type, length, initial snippet) is necessary to substantiate the premise. In the revised version we will add a dedicated ablation study that systematically removes one metadata component at a time and reports the resulting changes in routing accuracy, cost-effectiveness, and decision consistency on both LaRA and LongBench-v2. We will also include a new error-analysis subsection that categorizes failure cases on LongBench-v2, with particular attention to multi-hop and position-sensitive queries, providing concrete examples and discussing when Pre-Route routes sub-optimally. revision: yes
-
Referee: The linear-probe result (finding ii) demonstrates sharpened separability in representation space but only establishes correlation, not that the metadata signals are causally sufficient for accurate downstream routing decisions; a controlled test linking probe accuracy to end-to-end routing performance is needed.
Authors: We acknowledge that the current linear-probe analysis shows correlation rather than direct causation. To close this gap we will add a controlled experiment that uses probe-derived predictions (via thresholding) to drive routing decisions and directly compares the resulting end-to-end accuracy and cost-effectiveness against the full Pre-Route pipeline. We will also report the correlation between probe accuracy and downstream routing performance across prompt variations and model scales to provide quantitative evidence of the causal relationship. revision: yes
-
Referee: The abstract asserts quantitative superiority and three key findings without reporting specific metrics, error bars, or methodology details; the experiments section must supply these (e.g., exact cost-effectiveness deltas, variance across runs) to substantiate the outperformance over baselines.
Authors: We will update the abstract to include concrete quantitative results (e.g., exact cost-effectiveness deltas versus Self-Route on LaRA and LongBench-v2) together with a brief statement on the evaluation protocol. The experiments section already contains the full methodology for computing cost-effectiveness (accuracy normalized by token usage) and reports standard deviations across three independent runs; we will ensure all tables explicitly display error bars and add a compact summary table of key deltas in the main text for immediate visibility. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents Pre-Route as a proactive framework using lightweight metadata for task analysis and routing decisions, validated through experiments on LaRA and LongBench-v2 against baselines like Always-RAG and Self-Route. No equations or derivations reduce by construction to fitted inputs or self-citations; the linear-probe separability result is offered as supporting evidence of representation sharpening rather than a definitional tautology. The central performance claims rely on external dataset comparisons and elicited LLM behavior, remaining self-contained without load-bearing self-references or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs possess latent routing abilities that can be reliably elicited with guidelines
Reference graph
Works this paper leans on
-
[1]
Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju Hwang, and Jong Park
Association for Computational Linguistics. Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju Hwang, and Jong Park. 2024. Adaptive-rag: Learn- ing to adapt retrieval-augmented large language mod- els through question complexity. InProceedings of the 2024 Conference of the North American Chap- ter of the Association for Computational Linguistics: Human Langu...
-
[2]
Self-knowledge guided retrieval augmenta- tion for large language models. InFindings of the Association for Computational Linguistics: EMNLP 2023, Singapore, December 6-10, 2023, pages 10303– 10315. Association for Computational Linguistics. Peng Xu, Wei Ping, Xianchao Wu, Lawrence McAfee, Chen Zhu, Zihan Liu, Sandeep Subramanian, Evelina Bakhturina, Moha...
work page 2023
-
[3]
Corrective Retrieval Augmented Generation
Corrective retrieval augmented generation. CoRR, abs/2401.15884. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Day- iheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 40 others. 2025. Qwen3 technical report.CoRR, abs/2505.09388. Xin...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
and task-oriented datasets (Bai et al., 2024a; An et al., 2024; Dasigi et al., 2021; s Koˇ ciský et al., 2018; Pang et al., 2022). These studies re- vealed performance degradation as context length grows (Levy et al., 2024; Hsieh et al., 2024) and phenomena such as lost-in-the-middle (Liu et al., 2024). Nevertheless, most benchmarks do not ex- ceed 128K t...
work page 2024
-
[5]
Why does Stella repeatedly think that their father will ’kill’ Miles?
Initial Analysis: The Query and RAG’s Scope Query:"Why does Stella repeatedly think that their father will ’kill’ Miles?" The presence of the keywordrepeatedly is crucial, as it implies that the necessary context is likely scattered across multiple passages, requiring a broader understanding than localized snippets might provide. RAG Retrieved Snippets An...
-
[6]
Comparative Analysis and Scoring Long-Context Answer (Score: 4/4): "Stella repeatedly thinks their father will ’kill’ Miles because she knows he was ex- pelledagain. She anticipates not only her father’s anger but also hisdisappointment, given thehigh expectationsthey have for Miles, and thus fears asevere outcome." RAG Answer (Score: 3/4):"Stella thinks ...
-
[7]
Check whether each assistant is hallucinating . If the answer is ** consistent ** with the groundtruth , and the question is **not present in the original text **, it is considered **not hallucinating **
-
[8]
For each answer, assign a quality score from 1 to 4: − 4 = Fully correct (not hallucinating and consistent ) − 3 = Mostly correct (minor detail missing or uncertain ) − 2 = Partially correct (some correct points , some hallucination ) − 1 = Hallucinated , irrelevant , or incorrect
-
[9]
Write a brief comparative analysis
-
[10]
Decide who is better : "A", "B", or "Tie" Return JSON in this format: { " analysis ": "...", "score_a ": int , "score_b ": int , " better ": "A" | "B" | "Tie" } [Question] {query} [Groundtruth Answer] { label } [ Assistant A’s Answer] {pred_a} [ Assistant B’s Answer] {pred_b} Start your evaluation : Figure 8: An adapted prompt from the LaRA benchmark, spe...
-
[11]
How do these affect the need for deep context understanding or precise retrieval ?
‘<step1 >‘: Identify the question type (e.g ., factual , reasoning , comparison, judgment, etc .) and the document type (e.g ., book, article , report ) . How do these affect the need for deep context understanding or precise retrieval ?
-
[12]
How does this affect strategy selection ?
‘<step2 >‘: Assess whether the relevant information is likely concentrated in one part of the document or scattered across multiple sections . How does this affect strategy selection ?
-
[13]
If not , how does that impact strategy choice?
‘<step3 >‘: Evaluate whether the document can fully fit into the context window, based on ‘document_fits_window‘ above. If not , how does that impact strategy choice?
-
[14]
‘<step4 >‘: Consider whether the query can be answered through keyword−based retrieval (e.g ., names, dates ) , or requires synthesizing implicit logic , analogies , or multi−part reasoning
-
[15]
Consider both its context window size and model capacity (parameters)
‘<step5 >‘: Reflect on the model being used (e.g ., {model}). Consider both its context window size and model capacity (parameters) . Although some models may have large context windows, smaller models may still struggle with effective long−context reasoning due to limited capacity . How does this influence your strategy recommendation?
-
[16]
If quality is likely similar , which strategy is more efficient ?
‘< step6_efficiency >‘: Compare **expected efficiency ** of RAG vs LONG_CONTEXT: expected context size, retrieval selectivity , latency , and cost . If quality is likely similar , which strategy is more efficient ?
-
[17]
‘< reflection >‘: Based on your reasoning above, state which strategy is more suitable overall −− **RAG**, **LONG_CONTEXT** −− and explain why
-
[18]
‘< decision >‘: Write your final strategy choice clearly as either ‘RAG‘, ‘LONG_CONTEXT‘. ### Decision Rules − If both strategies are **equally suitable ** or quality difference is ** negligible / uncertain **, **prefer RAG for efficiency **. − Prefer **LONG_CONTEXT** only if (a) the document **fits** in the window **and** (b) the query requires **global ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.