Recognition: no theorem link
Scalable Gaussian process inference via neural feature maps
Pith reviewed 2026-05-12 04:54 UTC · model grok-4.3
The pith
Neural feature maps let Gaussian processes perform exact inference at scale for regression and classification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
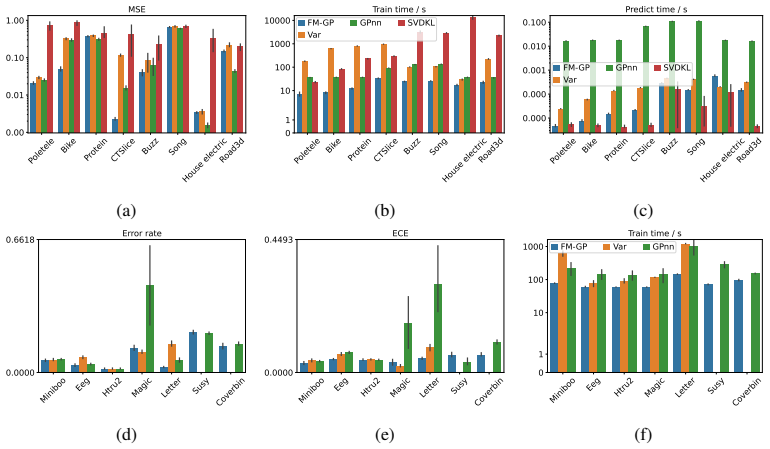
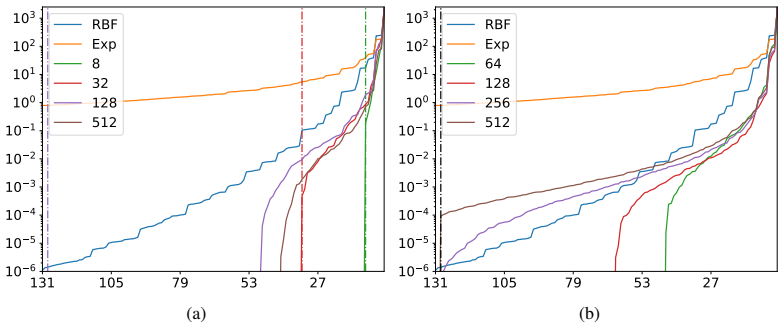
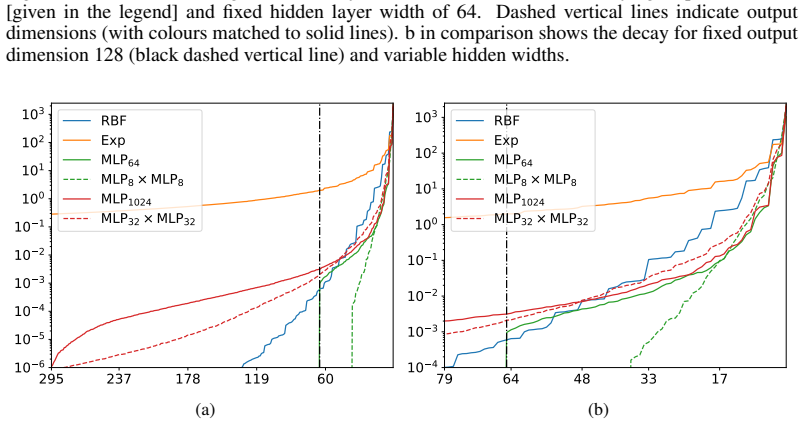
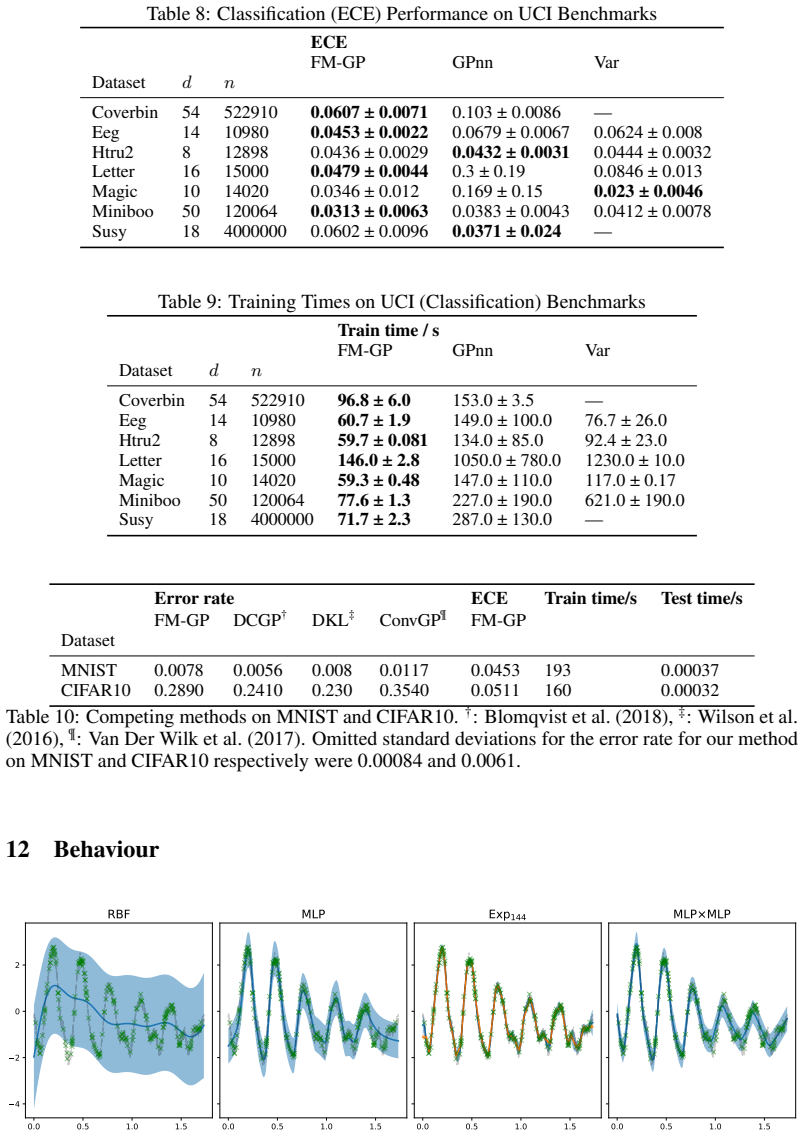
The learned neural feature map serves as an optimal low-rank approximation to a Gram matrix derived from an implied RKHS, from which consistency of the GP posterior follows. The work further analyses the spectral properties of the induced kernels and introduces product feature-map kernels to address oversmoothing. This enables fast, scalable, and accurate exact GP inference with minimal upfront work across regression, classification, and diverse data modalities.
What carries the argument
Neural feature maps that induce kernels via inner products and act as low-rank approximations to implied RKHS Gram matrices.
Load-bearing premise
The neural network learns a feature map that sufficiently approximates the optimal low-rank structure of the kernel's reproducing kernel Hilbert space.
What would settle it
If the method produces posteriors that diverge from those of an exact GP on a dataset small enough for traditional exact computation, the consistency claim would be challenged.
Figures



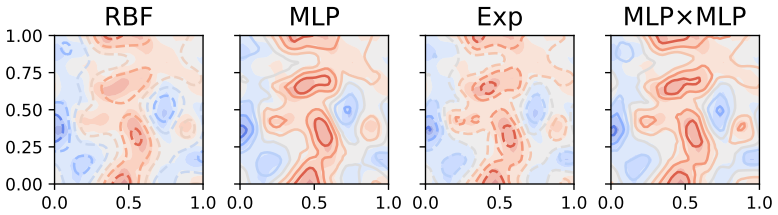
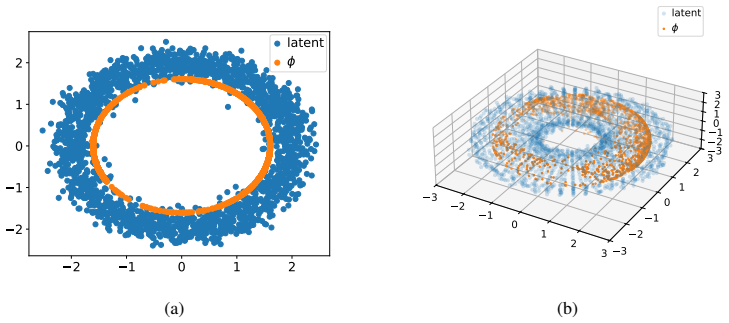
read the original abstract
We present a theoretically grounded Gaussian process framework that leverages neural feature maps to construct expressive kernels. We show that the learned feature map can be interpreted as an optimal low-rank approximation to a Gram matrix derived from an implied RKHS, from which we establish consistency of the GP posterior. We further analyse the spectral properties of the induced kernels and introduce product feature-map kernels to address oversmoothing. This simple yet powerful approach enables fast, scalable, and accurate exact GP inference with minimal upfront work. The flexibility of kernel design supports seamless application to both regression and classification tasks across diverse data modalities, including tabular inputs and structured domains such as images. On benchmark datasets, this approach surpasses pre-existing methods in terms of accuracy and training and prediction efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Gaussian process framework that constructs expressive kernels via neural feature maps. It claims that the learned feature map admits an interpretation as an optimal low-rank approximation to a Gram matrix arising from an implied RKHS, from which posterior consistency is derived. The work further analyzes spectral properties of the induced kernels, introduces product feature-map kernels to counteract oversmoothing, and reports that the resulting exact GP inference is fast, scalable, and accurate on regression and classification benchmarks across tabular and structured data modalities.
Significance. If the central consistency argument can be made rigorous, the approach would offer a principled route to data-driven yet theoretically grounded kernels that support exact GP inference at scale. The combination of neural flexibility with posterior consistency and the proposed product kernels could be useful for practitioners working with non-stationary or high-dimensional data. The empirical claims of improved accuracy and efficiency are potentially valuable, but their weight depends on the resolution of the theoretical gap.
major comments (1)
- [Abstract] Abstract: the claim that the learned neural feature map 'can be interpreted as an optimal low-rank approximation to a Gram matrix derived from an implied RKHS, from which we establish consistency of the GP posterior' is load-bearing. Standard neural-network training (via ELBO, cross-entropy, or similar) optimizes a different functional from the low-rank Gram approximation whose error controls posterior contraction rates. An explicit equivalence, inequality, or bound linking the training objective to the relevant approximation error must be supplied; without it the consistency statement does not follow from the low-rank interpretation alone.
minor comments (1)
- [Abstract] Abstract: the statement that the method 'surpasses pre-existing methods in terms of accuracy and training and prediction efficiency' would benefit from naming the specific baselines, datasets, and quantitative metrics in the abstract itself.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. We appreciate the recognition of the potential value of neural feature maps for expressive yet consistent Gaussian process inference. The referee's primary concern focuses on the rigor of the consistency claim in the abstract, which we address directly below. We agree that an explicit link is necessary and will strengthen the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the learned neural feature map 'can be interpreted as an optimal low-rank approximation to a Gram matrix derived from an implied RKHS, from which we establish consistency of the GP posterior' is load-bearing. Standard neural-network training (via ELBO, cross-entropy, or similar) optimizes a different functional from the low-rank Gram approximation whose error controls posterior contraction rates. An explicit equivalence, inequality, or bound linking the training objective to the relevant approximation error must be supplied; without it the consistency statement does not follow from the low-rank interpretation alone.
Authors: We acknowledge that the current manuscript does not supply an explicit inequality or bound connecting the neural network training objective (ELBO or cross-entropy) to the low-rank Gram-matrix approximation error that governs posterior contraction. The low-rank interpretation is derived from the representer theorem applied to the implied RKHS, but the optimization path from the training loss to this approximation error is left implicit. In the revised version we will add a new proposition (with proof) that provides a concrete bound: the excess risk of the learned feature map relative to the optimal low-rank approximant is controlled by the training objective plus a term that vanishes under standard assumptions on the neural network class. This will make the consistency argument rigorous and directly address the referee's point. revision: yes
Circularity Check
No significant circularity; derivation relies on independent RKHS interpretation
full rationale
The paper claims that the learned neural feature map admits an interpretation as an optimal low-rank Gram approximation in an implied RKHS, from which posterior consistency is established. This step is presented as a theoretical consequence of the feature-map construction and standard RKHS approximation theory rather than a quantity fitted by construction or defined in terms of the target result. No equations in the abstract reduce the consistency claim to the training objective itself, no self-citations are invoked as load-bearing uniqueness theorems, and no ansatz is smuggled via prior work. The spectral analysis and product kernels are introduced as additional design choices, not as renamed empirical patterns. The central claim therefore retains independent theoretical content and does not collapse to its inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Variational Learning of Inducing Variables in Sparse Gaussian Processes , author =. Proceedings of the Twelfth International Conference on Artificial Intelligence and Statistics , pages =. 2009 , editor =
work page 2009
-
[2]
Gaussian processes for Big data , year =
Hensman, James and Fusi, Nicol\`. Gaussian processes for Big data , year =. Proceedings of the Twenty-Ninth Conference on Uncertainty in Artificial Intelligence , pages =
-
[3]
32nd International Conference on Machine Learning, ICML 2015 , author =
Kernel interpolation for scalable structured. 32nd International Conference on Machine Learning, ICML 2015 , author =. 2015 , note =
work page 2015
-
[4]
Gilboa, Elad and Saatçi, Yunus and Cunningham, John P. , month = sep, year =. Scaling
-
[5]
Izmailov, Pavel A. and Novikov, Alexander V. and Kropotov, Dmitry A. , arxivId =. 2018 , booktitle =
work page 2018
-
[6]
A. Neural Computation , author =. 2000 , pmid =. doi:10.1162/089976600300014908 , abstract =
-
[7]
Advances in Neural Information Processing Systems , author =
Convolutional. Advances in Neural Information Processing Systems , author =. 2017 , note =. doi:10.17863/CAM.21271 , abstract =
-
[8]
Kumar, Vinayak and Singh, Vaibhav and Srijith, P. K. and Damianou, Andreas , year =. Deep
-
[9]
Dirichlet-based Gaussian Processes for Large-scale Calibrated Classification , url =
Milios, Dimitrios and Camoriano, Raffaello and Michiardi, Pietro and Rosasco, Lorenzo and Filippone, Maurizio , booktitle =. Dirichlet-based Gaussian Processes for Large-scale Calibrated Classification , url =
-
[10]
Proceedings of the 34th International Conference on Machine Learning , pages =
On Calibration of Modern Neural Networks , author =. Proceedings of the 34th International Conference on Machine Learning , pages =. 2017 , editor =
work page 2017
- [11]
- [12]
-
[13]
Dropout as a Bayesian Approximation: Appendix , author=. 2016 , eprint=
work page 2016
- [14]
- [15]
-
[16]
Hensman, James and Matthews, Alexander and Ghahramani, Zoubin , booktitle =. 2015 , editor =
work page 2015
-
[17]
Kim, Hyun-Chul and Ghahramani, Zoubin , journal=. 2006 , volume=. doi:10.1109/TPAMI.2006.238 , url =
-
[18]
Leveraging Locality and Robustness to Achieve Massively Scalable Gaussian Process Regression , url =
Allison, Robert and Stephenson, Anthony and F, Samuel and Pyzer-Knapp, Edward O , booktitle =. Leveraging Locality and Robustness to Achieve Massively Scalable Gaussian Process Regression , url =
-
[19]
Calibrated Reliable Regression using Maximum Mean Discrepancy , url =
Cui, Peng and Hu, Wenbo and Zhu, Jun , booktitle =. Calibrated Reliable Regression using Maximum Mean Discrepancy , url =
-
[20]
Garriga-Alonso, Adrià and Aitchison, Laurence and Rasmussen, Carl Edward , pages =. 2019 , journal =. doi:10.17863/CAM.42340 , arxivId =
- [21]
-
[22]
Proceedings of the 24th International Conference on Artificial Intelligence , pages =
Huang, Wenbing and Zhao, Deli and Sun, Fuchun and Liu, Huaping and Chang, Edward , title =. Proceedings of the 24th International Conference on Artificial Intelligence , pages =. 2015 , isbn =
work page 2015
-
[23]
https://stats.stackexchange.com/q/46615 , URL =
Expected value of a Gaussian random variable transformed with a logistic function , AUTHOR =. https://stats.stackexchange.com/q/46615 , URL =
-
[24]
Chapter 4: The Matrix-Variate Gaussian Distribution
Mathai, Arak and Provost, Serge and Haubold, Hans. Chapter 4: The Matrix-Variate Gaussian Distribution. Multivariate Statistical Analysis in the Real and Complex Domains. 2022. doi:10.1007/978-3-030-95864-0_4
-
[25]
Proceedings of the 19th International Conference on Artificial Intelligence and Statistics , pages =
Deep Kernel Learning , author =. Proceedings of the 19th International Conference on Artificial Intelligence and Statistics , pages =. 2016 , editor =
work page 2016
-
[26]
Deep Neural Decision Forests , year=
Kontschieder, Peter and Fiterau, Madalina and Criminisi, Antonio and Bulò, Samuel Rota , booktitle=. Deep Neural Decision Forests , year=
-
[27]
Proceedings of the 36th International Conference on Machine Learning , pages =
On the Spectral Bias of Neural Networks , author =. Proceedings of the 36th International Conference on Machine Learning , pages =. 2019 , editor =
work page 2019
- [28]
-
[29]
Anthony Stephenson , title =
-
[30]
Stein, Michael L. , biburl =. Interpolation of spatial data , url =. doi:10.1007/978-1-4612-1494-6 , interhash =
-
[31]
Williams, Christopher K and Rasmussen, Carl Edward , PUBLISHER =. 2006 , TITLE =
work page 2006
-
[32]
Artificial Intelligence Review , author =
A survey of uncertainty in deep neural networks , volume =. Artificial Intelligence Review , author =. 2023 , pages =. doi:10.1007/s10462-023-10562-9 , abstract =
-
[33]
Damianou, Andreas and Lawrence, Neil D. , booktitle =. Deep. 2013 , editor =
work page 2013
-
[34]
Adaptive Approximation and Generalization of Deep Neural Network with Intrinsic Dimensionality , author=. 2020 , eprint=
work page 2020
-
[35]
Proceedings of The 24th International Conference on Artificial Intelligence and Statistics , pages =
A Spectral Analysis of Dot-product Kernels , author =. Proceedings of The 24th International Conference on Artificial Intelligence and Statistics , pages =. 2021 , editor =
work page 2021
-
[36]
Journal of Machine Learning Research , year =
Aad van der Vaart and Harry van Zanten , title =. Journal of Machine Learning Research , year =
-
[37]
Advances in neural information processing systems , volume=
Gpytorch: Blackbox matrix-matrix gaussian process inference with gpu acceleration , author=. Advances in neural information processing systems , volume=
-
[38]
Advances in Neural Information Processing Systems , volume=
Exact Gaussian processes on a million data points , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
When Gaussian Process Meets Big Data: A Review of Scalable GPs , author=. 2019 , eprint=
work page 2019
-
[40]
Petersen, Kaare Brandt and Pedersen, Michael Syskind , year =. The. doi:10.1007/978-3-030-49840-5_1 , abstract =
-
[41]
Forty-second International Conference on Machine Learning , year=
Scalable Gaussian Processes with Latent Kronecker Structure , author=. Forty-second International Conference on Machine Learning , year=
-
[42]
Burt and Carl Edward Rasmussen and Mark van der Wilk , title =
David R. Burt and Carl Edward Rasmussen and Mark van der Wilk , title =. Journal of Machine Learning Research , year =
-
[43]
Journal of Machine Learning Research , year =
Dennis Nieman and Botond Szabo and Harry van Zanten , title =. Journal of Machine Learning Research , year =
-
[44]
Gaussian Processes and Kernel Methods: A Review on Connections and Equivalences , author=. 2018 , eprint=
work page 2018
-
[45]
Fundamentals of Nonparametric Bayesian Inference , publisher=
Ghosal, Subhashis and van der Vaart, Aad , year=. Fundamentals of Nonparametric Bayesian Inference , publisher=
-
[46]
On choosing and bounding probability metrics , author=. 2002 , eprint=
work page 2002
-
[47]
Horn, Roger A. and Johnson, Charles R. , isbn =. 1985 , booktitle =
work page 1985
-
[48]
On majorization and Schur products , journal =. 1985 , issn =. doi:https://doi.org/10.1016/0024-3795(85)90147-8 , url =
-
[49]
Lin and Allan Pinkus and Shimon Schocken , keywords =
Moshe Leshno and Vladimir Ya. Lin and Allan Pinkus and Shimon Schocken , keywords =. Multilayer feedforward networks with a nonpolynomial activation function can approximate any function , journal =. 1993 , issn =. doi:https://doi.org/10.1016/S0893-6080(05)80131-5 , url =
- [50]
-
[51]
Seeger, Matthias W. and Kakade, Sham M. and Foster, Dean P. , journal=. Information Consistency of Nonparametric Gaussian Process Methods , year=
-
[52]
MLP-Mixer: An all-MLP Architecture for Vision , author=. 2021 , eprint=
work page 2021
-
[53]
Kohler, M. and Krzyzak, A. , booktitle=. Adaptive regression estimation with multilayer feedforward neural networks , year=
-
[54]
The Annals of Statistics , number =
Benedikt Bauer and Michael Kohler , title =. The Annals of Statistics , number =. 2019 , doi =
work page 2019
-
[55]
Nonparametric regression using deep neural networks with ReLU activation function , volume=
Schmidt-Hieber, Johannes , year=. Nonparametric regression using deep neural networks with ReLU activation function , volume=. The Annals of Statistics , publisher=. doi:10.1214/19-aos1875 , number=
-
[56]
Stochastic Variational Deep Kernel Learning , url =
Wilson, Andrew G and Hu, Zhiting and Salakhutdinov, Russ R and Xing, Eric P , booktitle =. Stochastic Variational Deep Kernel Learning , url =
-
[57]
Proceedings of the Thirty-Seventh Conference on Uncertainty in Artificial Intelligence , pages =
The promises and pitfalls of deep kernel learning , author =. Proceedings of the Thirty-Seventh Conference on Uncertainty in Artificial Intelligence , pages =. 2021 , editor =
work page 2021
-
[58]
Why do tree-based models still outperform deep learning on tabular data? , author=. 2022 , eprint=
work page 2022
-
[59]
10 Harmonizable, Cramér, and Karhunen classes of processes , series =. 1985 , booktitle =. doi:https://doi.org/10.1016/S0169-7161(85)05012-X , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.