Recognition: no theorem link
Sample-Mean Anchored Thompson Sampling for Offline-to-Online Learning with Distribution Shift
Pith reviewed 2026-05-15 05:03 UTC · model grok-4.3
The pith
Anchor-TS uses median anchoring of Thompson samples to the online mean to safely reduce regret with shifted offline data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The median of the online posterior sample, the hybrid posterior sample, and the online sample mean yields an arm index that is systematically optimistic for the optimal arm and pessimistic for suboptimal arms, enabling safe exploitation of offline data despite distribution shift while preserving the theoretical properties of Thompson sampling.
What carries the argument
The median-based anchoring rule that defines each arm index as the median of an online posterior sample, a hybrid posterior sample, and the online sample mean.
If this is right
- Regret scales favorably with offline data volume when the shift is bounded.
- The algorithm remains sublinear-regret even under nonzero distribution shift.
- The median correction strength grows with the accuracy of the online sample mean.
- Hybrid posterior construction can be tuned by the relative weight of offline versus online data.
Where Pith is reading between the lines
- The same median rule could be applied to other posterior-based algorithms such as posterior sampling for reinforcement learning.
- In deployment, one could monitor the gap between the three quantities to detect when the offline data becomes harmful.
- The regret bounds suggest a practical threshold on shift size below which offline data should be used and above which it should be discarded.
Load-bearing premise
The median of the three quantities reliably reduces over-estimation on bad arms and under-estimation on good arms caused by the distribution shift.
What would settle it
A controlled bandit instance where increasing the offline dataset size while keeping the distribution shift fixed produces no regret reduction or increases regret compared with pure online Thompson sampling.
Figures

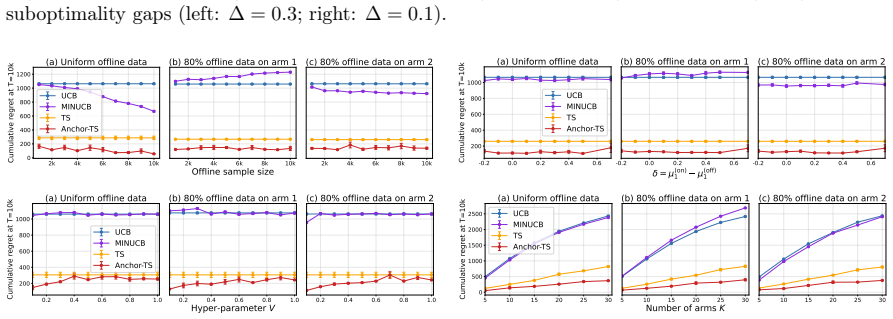

read the original abstract
Offline-to-online learning aims to improve online decision-making by leveraging offline logged data. A central challenge in this setting is the distribution shift between offline and online environments. While some existing works attempt to leverage shifted offline data, they largely rely on UCB-type algorithms. Thompson sampling (TS) represents another canonical class of bandit algorithms, well known for its strong empirical performance and naturally suited to offline-to-online learning through its Bayesian formulation. However, unlike UCB indices, posterior samples in TS are not guaranteed to be optimistic with respect to the true arm means. This makes indices constructed from purely online and hybrid data difficult to compare and complicates their use. To address this issue, we propose sample-mean anchored TS (Anchor-TS), which introduces a novel median-based anchoring rule that defines the arm index as the median of an online posterior sample, a hybrid posterior sample, and the online sample mean. The median anchoring systematically corrects bias induced by distribution shift by mitigating over-estimation for suboptimal arms and under-estimation for optimal arms, while exploiting offline information to obtain more accurate estimates when the shift is small. We establish theoretical guarantees showing that the proposed algorithm safely leverages offline data to accelerate online learning, and quantifying how the degree of distribution shift and the size of offline data affect the resulting regret reduction. Extensive experiments demonstrate consistent improvements of our algorithm over baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Sample-Mean Anchored Thompson Sampling (Anchor-TS) for offline-to-online bandit learning under distribution shift. The algorithm defines each arm index as the median of an online posterior sample, a hybrid posterior sample that mixes offline and online data, and the online sample mean. The authors claim this median anchoring corrects bias from distribution shift (mitigating over-estimation on suboptimal arms and under-estimation on optimal arms), safely incorporates offline data, and yields regret bounds that explicitly quantify the benefit in terms of shift magnitude and offline sample size. Experiments are reported to show consistent gains over baselines.
Significance. If the central claims hold, the work would supply a Bayesian alternative to existing UCB-style methods for offline-to-online learning, with a concrete mechanism for trading off offline data against shift and explicit regret dependence on those quantities. The median-anchoring construction is a novel index rule that could be useful in other posterior-sampling settings where direct comparison of online and hybrid samples is problematic.
major comments (2)
- [Abstract and §3] Abstract and §3 (algorithm definition): the claim that the median 'systematically corrects bias induced by distribution shift by mitigating over-estimation for suboptimal arms and under-estimation for optimal arms' is load-bearing for the regret analysis, yet no lemma establishes that the median operation preserves the optimism ordering or sub-Gaussian tail bounds when the hybrid posterior deviates arbitrarily from the online posterior. If the ordering fails for even one arm, the standard TS regret decomposition used to quantify the offline-data benefit no longer applies.
- [Theoretical analysis (main theorem)] Theoretical analysis (main theorem, presumably §4): the regret bounds are asserted to depend on the degree of distribution shift and offline data size, but the manuscript provides no explicit derivation showing how the median index inherits sufficient concentration from the online posterior alone once the hybrid component is included. A concrete bound or counter-example under large shift is required to confirm the claimed regret reduction.
minor comments (2)
- [Abstract] The abstract is dense; the contribution paragraph would be clearer if the three quantities entering the median were listed explicitly and the bias-correction intuition separated from the regret statement.
- [§3] Notation for the hybrid posterior (mixing parameter, weighting of offline vs. online samples) should be introduced with a short display equation in §3 to avoid ambiguity when the regret analysis refers to it.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The comments highlight important points for strengthening the theoretical foundations of Anchor-TS. We address each major comment below and will revise the manuscript to incorporate additional lemmas and expanded derivations.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (algorithm definition): the claim that the median 'systematically corrects bias induced by distribution shift by mitigating over-estimation for suboptimal arms and under-estimation for optimal arms' is load-bearing for the regret analysis, yet no lemma establishes that the median operation preserves the optimism ordering or sub-Gaussian tail bounds when the hybrid posterior deviates arbitrarily from the online posterior. If the ordering fails for even one arm, the standard TS regret decomposition used to quantify the offline-data benefit no longer applies.
Authors: We agree that the current version lacks an explicit supporting lemma for the median's effect on ordering and concentration. The median is constructed over the online posterior sample, the hybrid sample, and the online sample mean; by definition of the median, the resulting index is guaranteed to lie between the online sample mean and the larger of the two posterior samples. This ensures the index remains at least as optimistic as the pure online sample mean, which is sufficient for the standard TS regret decomposition to apply. We will add a new lemma (in §3 and the appendix) that formally establishes (i) preservation of the optimism ordering in expectation and with high probability and (ii) inheritance of sub-Gaussian tail bounds from the online posterior alone, with the hybrid component only improving concentration when the shift is small. revision: yes
-
Referee: [Theoretical analysis (main theorem)] Theoretical analysis (main theorem, presumably §4): the regret bounds are asserted to depend on the degree of distribution shift and offline data size, but the manuscript provides no explicit derivation showing how the median index inherits sufficient concentration from the online posterior alone once the hybrid component is included. A concrete bound or counter-example under large shift is required to confirm the claimed regret reduction.
Authors: The main regret theorem in §4 decomposes the instantaneous regret using the fact that the median index is stochastically dominated by the online posterior sample when the shift is large. We will expand the proof to include an explicit intermediate step deriving the concentration inequality for the median index: P(median > μ + t) ≤ P(online sample > μ + t), which directly inherits the sub-Gaussian tail from the online posterior. For large shifts we recover the standard TS regret bound (no degradation); for small shifts the hybrid term tightens the bound proportionally to the offline sample size. The revision will also add a short remark containing a simple counter-example (two arms, extreme shift) illustrating that the median collapses to the online mean, confirming the claimed non-degradation. revision: yes
Circularity Check
No significant circularity: anchoring rule is a novel definition whose regret analysis does not reduce to fitted inputs by construction
full rationale
The paper introduces Anchor-TS by explicitly defining the arm index as the median of three quantities (online posterior sample, hybrid posterior sample, online sample mean). This is a constructive definition, not a fit to data that is then relabeled as a prediction. The abstract and description state that theoretical guarantees are established for regret reduction under distribution shift, but no equation or step is shown where a bound is obtained by substituting the same quantities used to define the median back into itself. No self-citation is invoked as a load-bearing uniqueness theorem, no ansatz is smuggled via prior work, and no known empirical pattern is merely renamed. The derivation chain therefore remains self-contained: the algorithm is specified first, then analyzed. The reader's suggested score of 2.0 is consistent with a minor (non-load-bearing) self-citation possibility, but none appears in the provided text; the central claim does not collapse to an identity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Bandit arms have fixed but unknown means with rewards drawn from distributions that may differ between offline and online phases.
invented entities (1)
-
Sample-mean anchored Thompson sampling index
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Journal of the ACM (JACM) , volume=
Near-optimal regret bounds for thompson sampling , author=. Journal of the ACM (JACM) , volume=. 2017 , publisher=
work page 2017
-
[2]
Finite Time Analysis of the Multiarmed Bandit Problem , author=. Machine Learning , volume=. 2002 , publisher=
work page 2002
-
[3]
Proceedings of the 41st International Conference on Machine Learning , pages=
Leveraging (biased) information: multi-armed bandits with offline data , author=. Proceedings of the 41st International Conference on Machine Learning , pages=. 2024 , publisher =
work page 2024
-
[4]
American Journal of Physics , volume=
Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables , author=. American Journal of Physics , volume=
-
[5]
Proceedings of the 40th International Conference on Machine Learning , pages=
Thompson sampling with less exploration is fast and optimal , author=. Proceedings of the 40th International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[6]
Advances in Applied Mathematics , volume=
Asymptotically efficient adaptive allocation rules , author=. Advances in Applied Mathematics , volume=. 1985 , publisher=
work page 1985
-
[7]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Predictive off-policy policy evaluation for nonstationary decision problems, with applications to digital marketing , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[8]
Guidelines for reinforcement learning in healthcare , author=. Nature medicine , volume=. 2019 , publisher=
work page 2019
-
[9]
The Journal of Machine Learning Research , volume=
Counterfactual reasoning and learning systems: The example of computational advertising , author=. The Journal of Machine Learning Research , volume=. 2013 , publisher=
work page 2013
-
[10]
Proceedings of the 25th International Conference on Neural Information Processing Systems , pages=
An empirical evaluation of thompson sampling , author=. Proceedings of the 25th International Conference on Neural Information Processing Systems , pages=
-
[11]
Proceedings of the 19th international conference on World wide web , pages=
A contextual-bandit approach to personalized news article recommendation , author=. Proceedings of the 19th international conference on World wide web , pages=
-
[12]
2018 IEEE international conference on robotics and automation (ICRA) , pages=
Overcoming exploration in reinforcement learning with demonstrations , author=. 2018 IEEE international conference on robotics and automation (ICRA) , pages=. 2018 , organization=
work page 2018
-
[13]
arXiv preprint arXiv:2210.06718 , year=
Hybrid rl: Using both offline and online data can make rl efficient , author=. arXiv preprint arXiv:2210.06718 , year=
-
[14]
Reinforcement Learning Journal , volume=
A natural extension to online algorithms for hybrid RL with limited coverage , author=. Reinforcement Learning Journal , volume=
-
[15]
The 39th Annual Conference on Neural Information Processing Systems , year=
Learning Across the Gap: Hybrid Multi-armed Bandits with Heterogeneous Offline and Online Data , author=. The 39th Annual Conference on Neural Information Processing Systems , year=
-
[16]
Bulletin of the American Mathematical Society , volume=
Some aspects of the sequential design of experiments , author=. Bulletin of the American Mathematical Society , volume=
- [17]
-
[18]
Artificial Intelligence and Statistics , pages=
Multi-armed bandit problems with history , author=. Artificial Intelligence and Statistics , pages=. 2012 , organization=
work page 2012
-
[19]
Proceedings of the 36th International Conference on Machine Learning , pages=
Warm-starting Contextual Bandits: Robustly Combining Supervised and Bandit Feedback , author=. Proceedings of the 36th International Conference on Machine Learning , pages=. 2019 , organization=
work page 2019
-
[20]
International conference on machine learning , pages=
Off-policy deep reinforcement learning without exploration , author=. International conference on machine learning , pages=. 2019 , organization=
work page 2019
-
[21]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Offline reinforcement learning: Tutorial, review, and perspectives on open problems , author=. arXiv preprint arXiv:2005.01643 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2005
- [22]
-
[23]
International conference on machine learning , pages=
Safe policy improvement with baseline bootstrapping , author=. International conference on machine learning , pages=. 2019 , organization=
work page 2019
-
[24]
Proceedings of the 38th International Conference on Machine Learning , pages=
Mots: Minimax optimal thompson sampling , author=. Proceedings of the 38th International Conference on Machine Learning , pages=. 2021 , organization=
work page 2021
-
[25]
Advances in Neural Information Processing Systems , volume=
Finite-time regret of thompson sampling algorithms for exponential family multi-armed bandits , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
Scalable deep reinforcement learning for vision-based robotic manipulation , author=
Qt-opt. Scalable deep reinforcement learning for vision-based robotic manipulation , author=. arXiv preprint , year=
-
[27]
arXiv preprint arXiv:2109.10813 , year=
A workflow for offline model-free robotic reinforcement learning , author=. arXiv preprint arXiv:2109.10813 , year=
-
[28]
arXiv preprint arXiv:2402.05546 , year=
Offline actor-critic reinforcement learning scales to large models , author=. arXiv preprint arXiv:2402.05546 , year=
-
[29]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[30]
2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , year=
Domain randomization for transferring deep neural networks from simulation to the real world , author=. 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , year=
work page 2017
-
[31]
2018 IEEE international conference on robotics and automation (ICRA) , pages=
Sim-to-real transfer of robotic control with dynamics randomization , author=. 2018 IEEE international conference on robotics and automation (ICRA) , pages=. 2018 , organization=
work page 2018
-
[32]
International Conference on Artificial Intelligence and Statistics , pages=
Hybrid Transfer Reinforcement Learning: Provable Sample Efficiency from Shifted-Dynamics Data , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2025 , organization=
work page 2025
-
[33]
Advances in neural information processing systems , volume=
Safe model-based reinforcement learning with stability guarantees , author=. Advances in neural information processing systems , volume=
-
[34]
Uncertainty-Aware Reinforcement Learning for Collision Avoidance
Uncertainty-aware reinforcement learning for collision avoidance , author=. arXiv preprint arXiv:1702.01182 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
arXiv preprint arXiv:2502.08259 , year=
Balancing optimism and pessimism in offline-to-online learning , author=. arXiv preprint arXiv:2502.08259 , year=
-
[36]
The 41st Conference on Uncertainty in Artificial Intelligence , year=
Augmenting Online RL with Offline Data is All You Need: A Unified Hybrid RL Algorithm Design and Analysis , author=. The 41st Conference on Uncertainty in Artificial Intelligence , year=
-
[37]
Proceedings of the 40th International Conference on Machine Learning , pages=
Efficient online reinforcement learning with offline data , author=. Proceedings of the 40th International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[38]
On the likelihood that one unknown probability exceeds another in view of the evidence of two samples , author=. Biometrika , volume=. 1933 , publisher=
work page 1933
-
[39]
Conference on Learning Theory , pages=
Analysis of thompson sampling for the multi-armed bandit problem , author=. Conference on Learning Theory , pages=. 2012 , organization=
work page 2012
-
[40]
International Conference on Algorithmic Learning Theory , pages=
Thompson sampling: An asymptotically optimal finite-time analysis , author=. International Conference on Algorithmic Learning Theory , pages=. 2012 , organization=
work page 2012
-
[41]
International Journal of Intelligent Computing and Cybernetics , volume=
Solving two-armed Bernoulli bandit problems using a Bayesian learning automaton , author=. International Journal of Intelligent Computing and Cybernetics , volume=. 2010 , publisher=
work page 2010
-
[42]
Applied Stochastic Models in Business and Industry , volume=
A modern Bayesian look at the multi-armed bandit , author=. Applied Stochastic Models in Business and Industry , volume=. 2010 , publisher=
work page 2010
-
[43]
Mathematics of Operations Research , volume=
Learning to optimize via posterior sampling , author=. Mathematics of Operations Research , volume=. 2014 , publisher=
work page 2014
-
[44]
Journal of Machine Learning Research , volume=
An information-theoretic analysis of thompson sampling , author=. Journal of Machine Learning Research , volume=
-
[45]
Advances in Neural Information Processing Systems , volume=
An information-theoretic analysis for thompson sampling with many actions , author=. Advances in Neural Information Processing Systems , volume=
-
[46]
Knowledge and Information Systems , volume=
Cutting to the chase with warm-start contextual bandits , author=. Knowledge and Information Systems , volume=. 2023 , publisher=
work page 2023
-
[47]
Proceedings of the 40th International Conference on Machine Learning , pages=
Leveraging offline data in online reinforcement learning , author=. Proceedings of the 40th International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[48]
Available at SSRN 5350921 , year=
Online Decisions with (Biased) Offline Data , author=. Available at SSRN 5350921 , year=
-
[49]
The 39th Annual Conference on Neural Information Processing Systems , year=
Contextual Online Pricing with (Biased) Offline Data , author=. The 39th Annual Conference on Neural Information Processing Systems , year=
-
[50]
arXiv preprint arXiv:2505.23165 , year=
Best Arm Identification with Possibly Biased Offline Data , author=. arXiv preprint arXiv:2505.23165 , year=
-
[51]
Multi-Armed Bandits with Biased and Heteroscedastic Auxiliary Rewards , author=. Proceedings of the 34th ACM International Conference on Information and Knowledge Management , pages=
-
[52]
Proceedings of the fourth ACM international conference on Web search and data mining , pages=
Unbiased offline evaluation of contextual-bandit-based news article recommendation algorithms , author=. Proceedings of the fourth ACM international conference on Web search and data mining , pages=
-
[53]
Proceedings of the 37th International Conference on Neural Information Processing Systems , pages=
Cal-ql: Calibrated offline rl pre-training for efficient online fine-tuning , author=. Proceedings of the 37th International Conference on Neural Information Processing Systems , pages=
-
[54]
Proceedings of the 40th International Conference on Machine Learning , pages=
Actor-critic alignment for offline-to-online reinforcement learning , author=. Proceedings of the 40th International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[55]
Conference on Robot Learning , pages=
Offline-to-online reinforcement learning via balanced replay and pessimistic q-ensemble , author=. Conference on Robot Learning , pages=. 2022 , organization=
work page 2022
-
[56]
arXiv preprint arXiv:2210.00025 , year=
Artificial replay: a meta-algorithm for harnessing historical data in bandits , author=. arXiv preprint arXiv:2210.00025 , year=
-
[57]
AWAC: Accelerating Online Reinforcement Learning with Offline Datasets
Awac: Accelerating online reinforcement learning with offline datasets , author=. arXiv preprint arXiv:2006.09359 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[58]
A tutorial on thompson sampling , author=. Foundations and Trends. 2018 , publisher=
work page 2018
-
[59]
Proceedings of the 30th International Conference on Machine Learning , pages =
Thompson Sampling for Contextual Bandits with Linear Payoffs , author =. Proceedings of the 30th International Conference on Machine Learning , pages =. 2013 , publisher =
work page 2013
-
[60]
Proceedings of the 35th International Conference on Machine Learning , pages=
Thompson sampling for combinatorial semi-bandits , author=. Proceedings of the 35th International Conference on Machine Learning , pages=. 2018 , organization=
work page 2018
-
[61]
Multi-agent thompson sampling for bandit applications with sparse neighbourhood structures , author=. Scientific Reports , volume=. 2020 , publisher=
work page 2020
-
[62]
Proceedings of the 32nd International Conference on Machine Learning , pages=
Optimal regret analysis of thompson sampling in stochastic multi-armed bandit problem with multiple plays , author=. Proceedings of the 32nd International Conference on Machine Learning , pages=. 2015 , organization=
work page 2015
-
[63]
The 9th International Conference on Learning Representations , year=
Neural Thompson Sampling , author=. The 9th International Conference on Learning Representations , year=
-
[64]
and Li, Jerry and Paduraru, Cosmin and Gowal, Sven and Hester, Todd , title =
Dulac-Arnold, Gabriel and Levine, Nir and Mankowitz, Daniel J. and Li, Jerry and Paduraru, Cosmin and Gowal, Sven and Hester, Todd , title =. Mach. Learn. , pages =. 2021 , issue_date =
work page 2021
-
[65]
arXiv preprint arXiv:2406.09574 , year=
Online Bandit Learning with Offline Preference Data for Improved RLHF , author=. arXiv preprint arXiv:2406.09574 , year=
-
[66]
User Modeling and User-Adapted Interaction , volume=
Toward joint utilization of absolute and relative bandit feedback for conversational recommendation , author=. User Modeling and User-Adapted Interaction , volume=. 2024 , publisher=
work page 2024
-
[67]
The Annals of Statistics , volume=
Transfer learning for contextual multi-armed bandits , author=. The Annals of Statistics , volume=. 2024 , publisher=
work page 2024
-
[68]
35th Conference on Neural Information Processing Systems , pages=
Policy Finetuning: Bridging Sample-Efficient Offline and Online Reinforcement Learning , author=. 35th Conference on Neural Information Processing Systems , pages=
-
[69]
The 11th International Conference on Learning Representations , year=
Hybrid RL: Using both offline and online data can make RL efficient , author=. The 11th International Conference on Learning Representations , year=
-
[70]
International Conference on Machine Learning , pages=
Instabilities of offline rl with pre-trained neural representation , author=. International Conference on Machine Learning , pages=. 2021 , organization=
work page 2021
-
[71]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Robustly Improving Bandit Algorithms with Confounded and Selection Biased Offline Data: A Causal Approach , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=. 2024 , organization=
work page 2024
-
[72]
Distributionally robust batch contextual bandits , author=. Management Science , volume=. 2023 , publisher=
work page 2023
-
[73]
A theory of learning from different domains , author=. Machine learning , volume=. 2010 , publisher=
work page 2010
-
[74]
arXiv preprint arXiv:2512.21925 , year=
Hybrid Combinatorial Multi-armed Bandits with Probabilistically Triggered Arms , author=. arXiv preprint arXiv:2512.21925 , year=
-
[75]
International Conference on Algorithmic Learning Theory , pages=
On the prior sensitivity of thompson sampling , author=. International Conference on Algorithmic Learning Theory , pages=. 2016 , organization=
work page 2016
-
[76]
Proceedings of the 35th International Conference on Neural Information Processing Systems , pages=
Bayesian decision-making under misspecifed priors with applications to meta-learning , author=. Proceedings of the 35th International Conference on Neural Information Processing Systems , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.