Recognition: no theorem link
Characterizing the Generalization Error of Random Feature Regression with Arbitrary Data-Augmentation
Pith reviewed 2026-05-12 04:48 UTC · model grok-4.3
The pith
The test error of random feature regression with arbitrary data augmentation admits a tight characterization using only the population quantities of the true data and the first and second order statistics of the augmentation scheme.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the proportional regime, the test mean squared error for random feature regression with arbitrary data augmentation is given by a closed-form expression depending solely on the population quantities of the true data together with the first and second order statistics of the augmentation scheme. This holds under misspecified feature maps and for any architecture in which only the readout layer is trained while the rest of the network is frozen or randomly initialized. When the data are Gaussian the asymptotic formula is tight.
What carries the argument
The asymptotic formula for the mean squared test error expressed solely in terms of the true data's population quantities and the augmentation scheme's first- and second-order statistics.
If this is right
- The benefit of any augmentation scheme can be predicted in advance from its induced moments without retraining the model.
- Different augmentation procedures can be ranked or optimized by comparing only their first- and second-order statistics.
- Misspecification between the feature map and the true data distribution does not invalidate the error formula.
- The regularization effect of augmentation is isolated to these low-order statistics even when the underlying network architecture varies.
Where Pith is reading between the lines
- Designers could engineer augmentation distributions to achieve target regularization levels by solving for desired moment values.
- The same moment-based reduction may apply to other convex losses or to settings beyond pure regression if analogous proportional limits are derived.
- In overparameterized regimes the result implies that higher-order properties of the augmentation become irrelevant for generalization.
Load-bearing premise
The dimension must grow proportionally with the number of samples and only the final readout layer is trained while preceding features remain frozen or randomly initialized.
What would settle it
Generate large finite samples from a known Gaussian distribution, apply a concrete augmentation with known first and second moments, train the random feature model, and check whether the observed test MSE converges to the predicted formula as dimension and sample size grow proportionally.
Figures
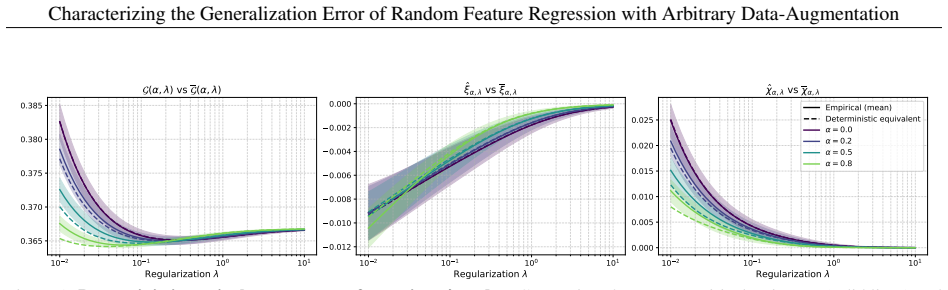
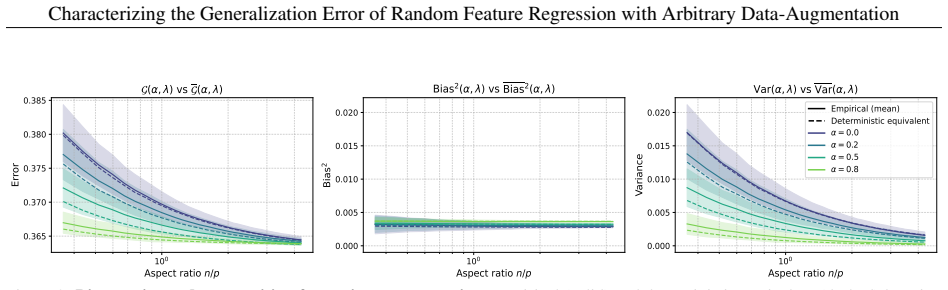

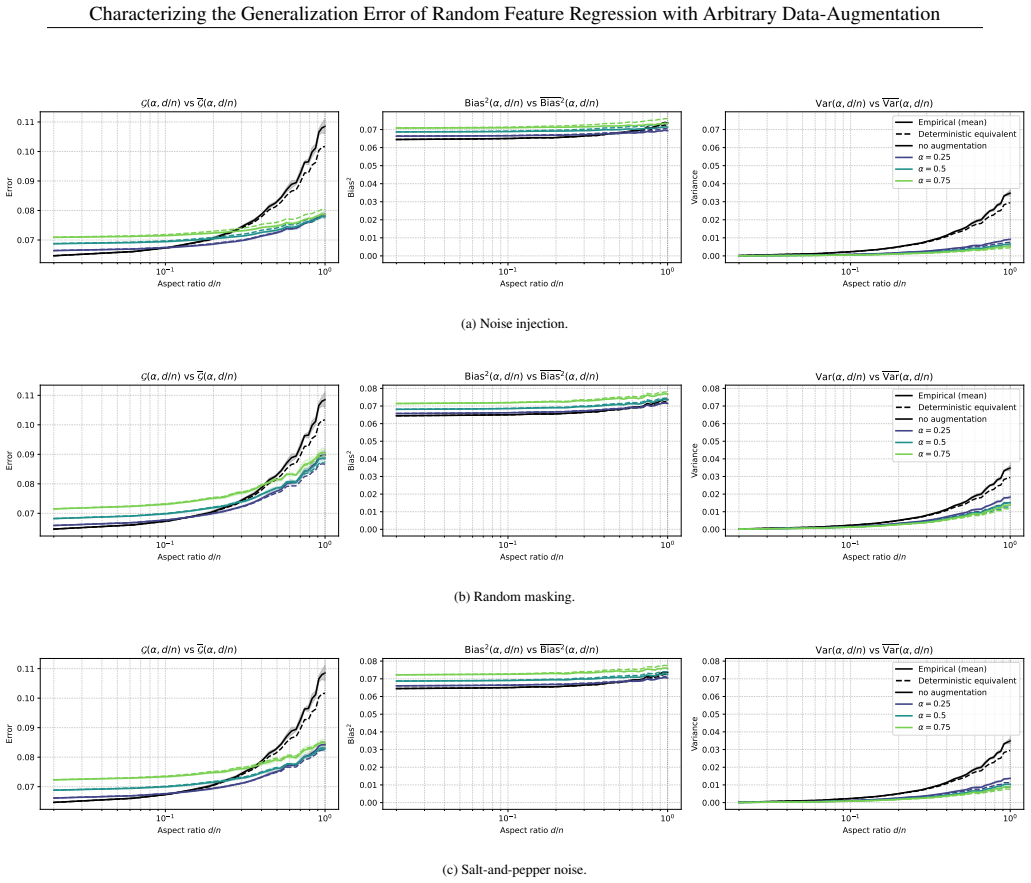

read the original abstract
This paper aims at analyzing the regularization effect that data augmentation induces on supervised regression methods in the proportional regime, where the number of covariates grows proportionally to the number of samples. We provide a tight characterization of the test error, measured in mean squared error, in terms only of the population quantities of the true data, as well as first and second order statistics of the augmentation scheme. Our results are valid under misspecified feature maps, and for any network architecture where only the last readout layer is trained, and the rest of the network is either frozen or randomly initialized. We specify our results in the case of Gaussian data, and show that our asymptotic characterization is tight in this setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript derives an asymptotic characterization of the test MSE for random feature regression with arbitrary data augmentation in the proportional regime. The formula is expressed solely in terms of population covariances of the true data and the first- and second-order moments of the augmentation distribution. The analysis covers misspecified (possibly nonlinear) feature maps with only the readout trained, and the characterization is shown to be tight when the underlying data is Gaussian.
Significance. If correct, the result supplies a practical tool for quantifying the regularization induced by data augmentation via low-order moments alone, extending random-matrix methods to augmented random-feature models while accommodating feature misspecification. The explicit tightness proof under Gaussian data is a concrete strength that allows direct validation of the formulas.
major comments (1)
- [Abstract and §3] Abstract and §3 (main theorem): the claim that the test-error characterization depends only on first- and second-order augmentation statistics for arbitrary augmentations and nonlinear feature maps φ is not obviously consistent with the fact that E[φ(aug(x))φ(aug(x))ᵀ] is in general a functional of the full law of aug(x), not merely its mean and covariance. The derivation therefore appears to require either linearity of φ or Gaussianity of the augmented data to close; the paper should state the precise assumptions under which the general (non-Gaussian) formula holds.
minor comments (1)
- [§2] The statement of the proportional regime (n,d→∞ with fixed ratio) and the precise definition of the random-feature map (frozen vs. randomly initialized) could be repeated explicitly in the theorem statements for clarity.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments. We address the major comment point by point below.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (main theorem): the claim that the test-error characterization depends only on first- and second-order augmentation statistics for arbitrary augmentations and nonlinear feature maps φ is not obviously consistent with the fact that E[φ(aug(x))φ(aug(x))ᵀ] is in general a functional of the full law of aug(x), not merely its mean and covariance. The derivation therefore appears to require either linearity of φ or Gaussianity of the augmented data to close; the paper should state the precise assumptions under which the general (non-Gaussian) formula holds.
Authors: We thank the referee for this observation. The manuscript already states that the results are specified and shown to be tight in the Gaussian data case (see the abstract and the main theorem in §3). Under the Gaussian assumption, the law of aug(x) is fully determined by its first- and second-order moments, so that for any measurable (possibly nonlinear) feature map φ the expectation E[φ(aug(x))φ(aug(x))ᵀ] depends only on those moments. We agree that the role of the Gaussian assumption should be stated more explicitly to avoid any ambiguity about non-Gaussian settings. We will revise the abstract and §3 accordingly. revision: yes
Circularity Check
No circularity: characterization expressed via independent population quantities
full rationale
The paper's central result is an asymptotic MSE characterization for random-feature regression under arbitrary data augmentation, expressed directly in terms of population covariances of the data-generating process together with the first- and second-order moments of the augmentation map. These quantities are defined independently of the trained readout weights and of the fitted model itself; the derivation therefore does not reduce any claimed prediction to a tautological re-expression of its own inputs. The analysis is further restricted to the Gaussian-data case where the stated tightness is verified, and the provided abstract and claims contain no load-bearing self-citations, uniqueness theorems imported from prior author work, or ansatzes smuggled via citation. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Proportional regime: number of features p and samples n satisfy p/n -> gamma in (0,infty)
- domain assumption Only the final readout layer is trained; the feature map is frozen or randomly initialized
Reference graph
Works this paper leans on
-
[1]
IEEE Transactions on Knowledge and Data Engineering , year=
A comprehensive survey on data augmentation , author=. IEEE Transactions on Knowledge and Data Engineering , year=
-
[2]
Data augmentation: A comprehensive survey of modern approaches , author=. Array , volume=. 2022 , publisher=
work page 2022
-
[3]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
Masked Autoencoders Are Scalable Vision Learners , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
-
[4]
Improved Regularization of Convolutional Neural Networks with Cutout
Improved regularization of convolutional neural networks with cutout , author=. arXiv preprint arXiv:1708.04552 , year=
work page internal anchor Pith review arXiv
-
[5]
How does mixup help with robustness and generalization? , author=. arXiv preprint arXiv:2010.04819 , year=
- [6]
-
[7]
and Muthukumar, Vidya , title =
Lin, Chi-Heng and Kaushik, Chiraag and Dyer, Eva L. and Muthukumar, Vidya , title =. Journal of Machine Learning Research , year =
-
[8]
Proceedings of the 36th International Conference on Machine Learning , editor =
Dao, Tri and Gu, Albert and Ratner, Alexander and Smith, Virginia and De Sa, Chris and Re, Christopher , title =. Proceedings of the 36th International Conference on Machine Learning , editor =. 2019 , month = jun, publisher =
work page 2019
- [9]
-
[10]
Advances in Neural Information Processing Systems , year =
Van Assel, Hugues and Ibrahim, Mark and Biancalani, Tommaso and Regev, Aviv and Balestriero, Randall , title =. Advances in Neural Information Processing Systems , year =
-
[11]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Autoaugment: Learning augmentation strategies from data , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[12]
Advances in neural information processing systems , volume=
Fast autoaugment , author=. Advances in neural information processing systems , volume=
-
[13]
European conference on computer vision , pages=
Faster autoaugment: Learning augmentation strategies using backpropagation , author=. European conference on computer vision , pages=. 2020 , organization=
work page 2020
-
[14]
2016 IEEE international conference on image processing (ICIP) , pages=
Adaptive data augmentation for image classification , author=. 2016 IEEE international conference on image processing (ICIP) , pages=. 2016 , organization=
work page 2016
- [15]
-
[16]
Image data augmentation approaches: A comprehensive survey and future directions , author=. IEEE Access , year=
-
[17]
arXiv preprint arXiv:2002.12478 , year=
Time series data augmentation for deep learning: A survey , author=. arXiv preprint arXiv:2002.12478 , year=
-
[18]
Neural Computing and Applications , volume=
Data augmentation techniques in time series domain: a survey and taxonomy , author=. Neural Computing and Applications , volume=. 2023 , publisher=
work page 2023
-
[19]
An empirical survey of data augmentation for time series classification with neural networks , author=. Plos one , volume=. 2021 , publisher=
work page 2021
-
[20]
ACM Computing Surveys , volume=
A survey on data augmentation for text classification , author=. ACM Computing Surveys , volume=. 2022 , publisher=
work page 2022
-
[21]
arXiv preprint arXiv:2105.03075 , year=
A survey of data augmentation approaches for NLP , author=. arXiv preprint arXiv:2105.03075 , year=
-
[22]
Text data augmentation for deep learning , author=. Journal of big Data , volume=. 2021 , publisher=
work page 2021
-
[23]
Proceedings of the National Academy of Sciences of the United States of America , year =
Belkin, Mikhail and Hsu, Daniel and Ma, Siyuan and Mandal, Soumik , title =. Proceedings of the National Academy of Sciences of the United States of America , year =
-
[24]
Bartlett, Peter L. and Long, Philip M. and Lugosi, G. Benign overfitting in linear regression , journal =. 2020 , volume =
work page 2020
-
[25]
Asymptotics of Learning with Deep Structured (Random) Features , author =. 2024 , eprint =. doi:10.48550/arXiv.2402.13999 , note =
-
[26]
Proceedings of the 2nd Mathematical and Scientific Machine Learning Conference , pages =
The Gaussian equivalence of generative models for learning with shallow neural networks , author =. Proceedings of the 2nd Mathematical and Scientific Machine Learning Conference , pages =. 2022 , editor =
work page 2022
-
[27]
Goldt, Sebastian and M\'ezard, Marc and Krzakala, Florent and Zdeborov\'a, Lenka , title =. Physical Review X , year =
-
[28]
Journal of Statistical Mechanics: Theory and Experiment , year =
Gerace, Federica and Loureiro, Bruno and Krzakala, Florent and M\'ezard, Marc and Zdeborov\'a, Lenka , title =. Journal of Statistical Mechanics: Theory and Experiment , year =
- [29]
- [30]
-
[31]
Communications on Pure and Applied Mathematics , year =
Mei, Song and Montanari, Andrea , title =. Communications on Pure and Applied Mathematics , year =
-
[32]
Proceedings of Thirty Sixth Conference on Learning Theory , editor =
Precise Asymptotic Analysis of Deep Random Feature Models , author =. Proceedings of Thirty Sixth Conference on Learning Theory , editor =. 2023 , month =
work page 2023
-
[33]
Advances in Neural Information Processing Systems , editor =
Zavatone-Veth, Jacob and Pehlevan, Cengiz , title =. Advances in Neural Information Processing Systems , editor =. 2023 , publisher =
work page 2023
-
[34]
A Rainbow in Deep Network Black Boxes , journal =
Guth, Florentin and M. A Rainbow in Deep Network Black Boxes , journal =. 2023 , eprint =
work page 2023
- [35]
-
[36]
Electronic Communications in Probability , year =
Adamczak, Radoslaw , title =. Electronic Communications in Probability , year =. doi:10.1214/ECP.v20-3781 , publisher =
-
[37]
High-Dimensional Probability: An Introduction with Applications in Data Science , author =. 2018 , publisher =. doi:10.1017/9781108231596 , isbn =
-
[38]
arXiv preprint arXiv:2211.13044 , year=
Quantitative deterministic equivalent of sample covariance matrices with a general dependence structure , author=. arXiv preprint arXiv:2211.13044 , year=. 2211.13044 , archivePrefix=
-
[39]
The Annals of Mathe- matical Statistics22(1), 79–86 (1951) https://doi.org/10.1214/aoms/1177729694
Sherman, Jack and Morrison, Winifred J. , title =. Annals of Mathematical Statistics , year =. doi:10.1214/aoms/1177729893 , mrnumber=
-
[40]
Henderson, H. V. and Searle, S. R. , title =. SIAM Review , year =
- [41]
- [42]
- [43]
-
[44]
Eigenvectors of some large sample covariance matrix ensembles , journal =
Ledoit, Olivier and P. Eigenvectors of some large sample covariance matrix ensembles , journal =. 2011 , volume =
work page 2011
-
[45]
Annales Henri Poincar\'e , volume =
Averaging fluctuations in resolvents of random band matrices , author =. Annales Henri Poincar\'e , volume =. 2013 , doi =. 1205.5664 , archivePrefix =
-
[46]
Proceedings of the 40th International Conference on Machine Learning , pages =
Deterministic equivalent and error universality of deep random features learning , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
work page 2023
-
[47]
AI models collapse when trained on recursively generated data , author =. Nature , volume =
-
[48]
The Thirty-eighth Annual Conference on Neural Information Processing Systems (NeurIPS 2024) , year =
Model Collapse Demystified: The Case of Regression , author =. The Thirty-eighth Annual Conference on Neural Information Processing Systems (NeurIPS 2024) , year =
work page 2024
-
[49]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Non-Asymptotic Analysis of Data Augmentation for Precision Matrix Estimation , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=. 2510.02119 , archivePrefix=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.