Recognition: no theorem link
Robust Probabilistic Shielding for Safe Offline Reinforcement Learning
Pith reviewed 2026-05-12 04:22 UTC · model grok-4.3
The pith
Shielding policy improvement steps in offline RL guarantees a safe policy with high probability using only the dataset and safe/unsafe state knowledge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
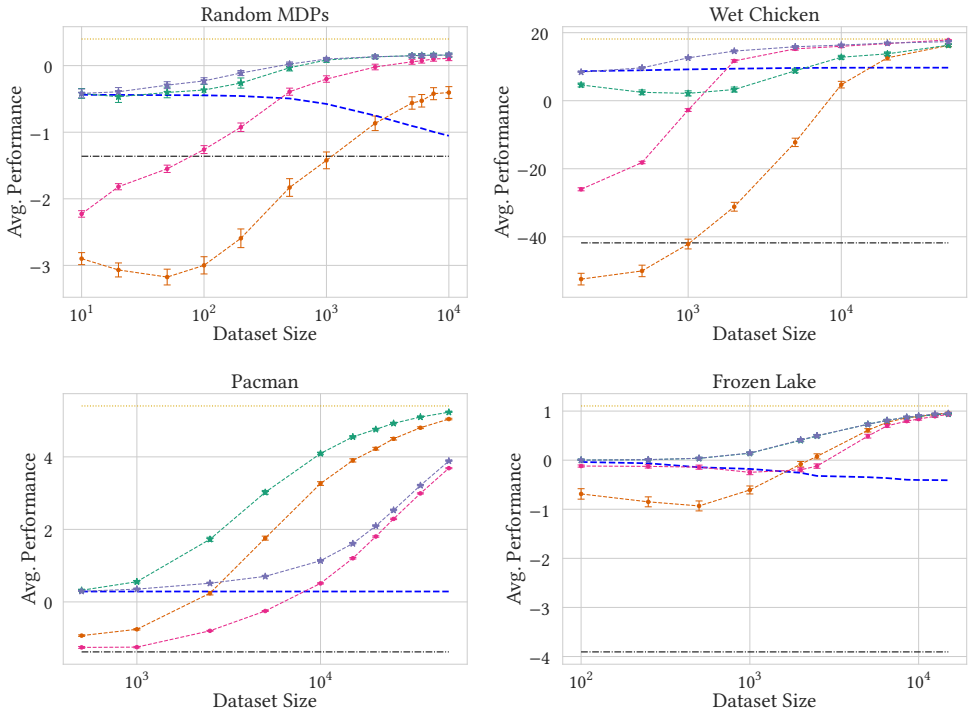
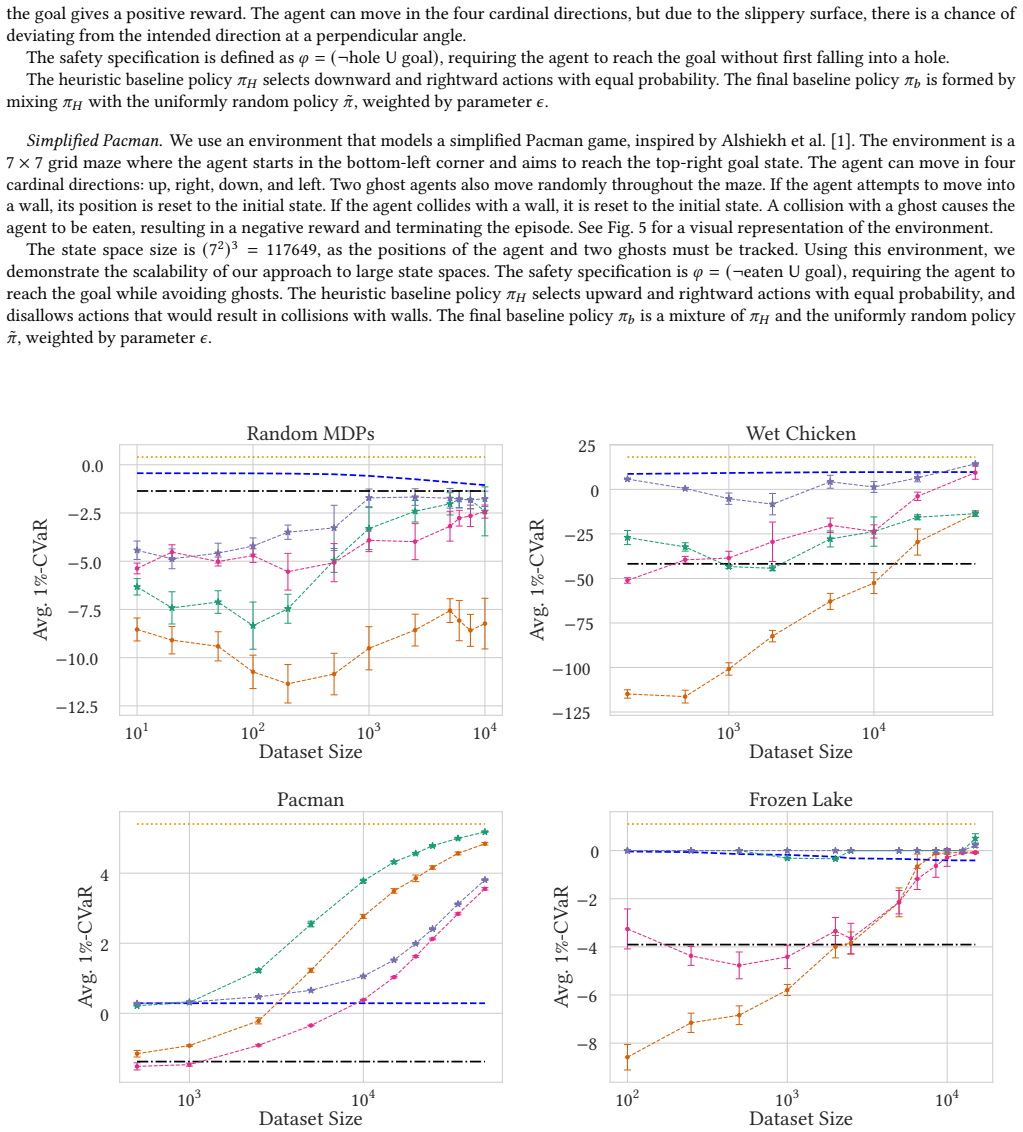
We integrate shielding with safe policy improvement for offline RL by shielding the policy improvement steps. This guarantees, with high probability, a safe policy, relying solely on the available dataset and knowledge of safe and unsafe states. Experimental results demonstrate that shielded SPI outperforms its unshielded counterpart, improving both average and worst-case performance, particularly in low-data regimes.
What carries the argument
The probabilistic shield that restricts the action space to safe actions during safe policy improvement steps, constructed from the offline dataset and labeled safe/unsafe states.
Load-bearing premise
The method assumes accurate knowledge of safe and unsafe states is available in addition to the offline dataset and that the baseline policy is safe.
What would settle it
Executing the shielded policy in repeated trials and observing unsafe states entered at a rate exceeding the claimed high-probability bound would falsify the safety guarantee.
Figures


read the original abstract
In offline reinforcement learning (RL), we learn policies from fixed datasets without environment interaction. The major challenges are to provide guarantees on the (1) performance and (2) safety of the resulting policy. A technique called safe policy improvement (SPI) provides a performance guarantee: with high probability, the new policy outperforms a given baseline policy, which is assumed to be safe. Orthogonally, in the context of safe RL, a shield provides a safety guarantee by restricting the action space to those actions that are provably safe with respect to a given safety-relevant model. We integrate these paradigms by extending shielding to offline RL, relying solely on the available dataset and knowledge of safe and unsafe states. Then, we shield the policy improvement steps, guaranteeing, with high probability, a safe policy. Experimental results demonstrate that shielded SPI outperforms its unshielded counterpart, improving both average and worst-case performance, particularly in low-data regimes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes robust probabilistic shielding for safe offline RL by integrating safe policy improvement (SPI) with shielding. It extends shielding to rely solely on the offline dataset plus labels for safe/unsafe states, then applies the shield during policy improvement steps to obtain a policy that is safe with high probability (while retaining SPI's performance guarantee over a safe baseline). Experiments are reported to show that the shielded variant improves both average and worst-case performance over unshielded SPI, with particular gains in low-data regimes.
Significance. If the high-probability safety guarantee can be established rigorously from dataset coverage and state labels alone, the work would meaningfully advance safe offline RL by addressing both performance and safety without online interaction or a learned dynamics model. The emphasis on low-data regimes targets a common practical bottleneck, and the explicit combination of two established paradigms (SPI and shielding) is a natural and potentially useful direction.
major comments (3)
- [Abstract / Method] Abstract and method description: the central claim that shielding policy-improvement steps using only the offline dataset and safe/unsafe state labels yields a high-probability safety guarantee does not address how the shield behaves for state-action pairs absent from the dataset. Without a dynamics model, no evidence exists to certify safety for unobserved transitions; the shield must either block such actions (risking violation of the SPI performance guarantee) or permit them (voiding the safety guarantee). The high-probability statement therefore appears to hold only under an implicit full-coverage assumption that is not stated or reduced to a data-dependent quantity.
- [Abstract / Theoretical Analysis] Theoretical claims: the abstract asserts the existence of high-probability guarantees on both safety and performance but supplies no derivation, proof sketch, or explicit reduction of the shielded policy to a quantity that can be bounded from the finite dataset. Without this reduction, the soundness of the combined guarantee cannot be verified.
- [Experiments] Experimental section: the reported improvements in low-data regimes are presented without details on dataset coverage statistics, how safety violations are measured or counted, or whether the high-probability bounds were empirically validated. This makes it impossible to determine whether the experiments actually test the regime where the skeptic's coverage concern would be most acute.
minor comments (1)
- [Abstract] The abstract could explicitly list the key assumptions (accurate safe/unsafe state labels and a safe baseline policy) to help readers immediately assess the scope of the guarantees.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important points regarding the precise handling of unobserved state-action pairs, the presentation of theoretical guarantees, and experimental transparency. We address each major comment below and will make corresponding revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract and method description: the central claim that shielding policy-improvement steps using only the offline dataset and safe/unsafe state labels yields a high-probability safety guarantee does not address how the shield behaves for state-action pairs absent from the dataset. Without a dynamics model, no evidence exists to certify safety for unobserved transitions; the shield must either block such actions (risking violation of the SPI performance guarantee) or permit them (voiding the safety guarantee). The high-probability statement therefore appears to hold only under an implicit full-coverage assumption that is not stated or reduced to a data-dependent quantity.
Authors: We thank the referee for this precise observation. Our shielding construction is explicitly conservative: from any state, an action is permitted by the shield only if the offline dataset contains at least one transition from that state-action pair to a labeled safe state (or the pair is directly labeled safe). All unobserved state-action pairs are blocked. This rule ensures that the probability of selecting an unsafe action is bounded solely by the probability of encountering an unobserved pair whose true safety is misclassified due to finite data; the bound is obtained via a coverage-dependent concentration inequality and does not rely on full coverage. Because the same conservative restriction is applied when evaluating the baseline policy, the safe-policy-improvement performance guarantee continues to hold relative to the (similarly restricted) baseline. We will revise the method section to state this rule explicitly, replace the implicit-coverage language with a data-dependent coverage term, and add the corresponding high-probability safety statement. revision: yes
-
Referee: [Abstract / Theoretical Analysis] Theoretical claims: the abstract asserts the existence of high-probability guarantees on both safety and performance but supplies no derivation, proof sketch, or explicit reduction of the shielded policy to a quantity that can be bounded from the finite dataset. Without this reduction, the soundness of the combined guarantee cannot be verified.
Authors: The full paper (Section 3) contains the formal reduction: the shielded policy is shown to be a data-dependent restriction of the SPI policy, after which standard concentration arguments (Hoeffding-type bounds on the empirical frequency of safe transitions) yield the joint high-probability safety and performance statements. The abstract, however, omits any sketch. We will insert a concise proof outline into the abstract and ensure every claim is explicitly tied to a finite-sample quantity. revision: yes
-
Referee: [Experiments] Experimental section: the reported improvements in low-data regimes are presented without details on dataset coverage statistics, how safety violations are measured or counted, or whether the high-probability bounds were empirically validated. This makes it impossible to determine whether the experiments actually test the regime where the skeptic's coverage concern would be most acute.
Authors: We agree that these details are necessary for readers to assess the coverage regime. We will add a dedicated paragraph (and accompanying table) reporting, for each environment and data budget: (i) the fraction of states and state-action pairs appearing in the dataset, (ii) the precise definition of a safety violation (reaching a labeled unsafe state during evaluation), and (iii) the empirical safety rate across 10 independent runs together with the theoretical high-probability bound computed from the observed coverage. This addition will directly demonstrate that the reported gains occur in the partial-coverage setting. revision: yes
Circularity Check
No significant circularity; extension of SPI and shielding uses dataset and labels without reducing guarantees to fitted inputs or self-citations
full rationale
The paper's central claim integrates safe policy improvement (SPI) with shielding for offline RL, using only the offline dataset plus known safe/unsafe state labels to shield policy improvement steps and obtain a high-probability safety guarantee. No equations or steps in the provided abstract or description reduce a prediction or guarantee to a quantity defined by the same data or by self-citation chains. Prior SPI and shielding results are cited as orthogonal paradigms being extended, not as load-bearing uniqueness theorems or ansatzes smuggled in. The derivation remains self-contained against external benchmarks for the extension itself; any coverage issues raised by the skeptic concern empirical validity rather than definitional circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A baseline policy is assumed to be safe.
- domain assumption Knowledge of safe and unsafe states is available alongside the offline dataset.
Reference graph
Works this paper leans on
-
[1]
Mohammed Alshiekh, Roderick Bloem, Rüdiger Ehlers, Bettina Könighofer, Scott Niekum, and Ufuk Topcu. 2018. Safe Reinforcement Learning via Shielding. In AAAI. AAAI Press, 2669–2678
work page 2018
-
[2]
2008.Principles of model checking
Christel Baier and Joost-Pieter Katoen. 2008.Principles of model checking. MIT Press
work page 2008
-
[3]
Richard Bellman. 1957. A Markovian Decision Process.Indiana University Math- ematics Journal6 (1957), 679–684. https://api.semanticscholar.org/CorpusID: 123329493
work page 1957
-
[4]
Federico Bianchi, Edoardo Zorzi, Alberto Castellini, Thiago D. Simão, Matthijs T. J. Spaan, and Alessandro Farinelli. 2024. Scalable Safe Policy Improvement for Factored Multi-Agent MDPs. InICML. OpenReview.net
work page 2024
-
[5]
Asger Horn Brorholt, Andreas Holck Høeg-Petersen, Kim Guldstrand Larsen, and Christian Schilling. 2024. Efficient Shield Synthesis via State-Space Trans- formation. InAISoLA (Lecture Notes in Computer Science, Vol. 15217). Springer, 206–224
work page 2024
-
[6]
Asger Horn Brorholt, Peter Gjøl Jensen, Kim Guldstrand Larsen, Florian Lorber, and Christian Schilling. 2023. Shielded Reinforcement Learning for Hybrid Systems. InAISoLA (Lecture Notes in Computer Science, Vol. 14380). Springer, 33–54
work page 2023
-
[7]
Asger Horn Brorholt, Kim Guldstrand Larsen, and Christian Schilling. 2025. Compositional Shielding and Reinforcement Learning for Multi-Agent Systems. InAAMAS. International Foundation for Autonomous Agents and Multiagent Systems / ACM, 399–407
work page 2025
-
[8]
Steven Carr, Nils Jansen, Sebastian Junges, and Ufuk Topcu. 2023. Safe Rein- forcement Learning via Shielding under Partial Observability. InAAAI. AAAI Press, 14748–14756
work page 2023
-
[9]
Simão, Alessandro Farinelli, and Matthijs T
Alberto Castellini, Federico Bianchi, Edoardo Zorzi, Thiago D. Simão, Alessandro Farinelli, and Matthijs T. J. Spaan. 2023. Scalable Safe Policy Improvement via Monte Carlo Tree Search. InICML (Proceedings of Machine Learning Research, Vol. 202). PMLR, 3732–3756
work page 2023
-
[10]
Jordan, Georgios Theocharous, Martha White, and Philip S
Yash Chandak, Scott M. Jordan, Georgios Theocharous, Martha White, and Philip S. Thomas. 2020. Towards Safe Policy Improvement for Non-Stationary MDPs. InNeurIPS
work page 2020
-
[11]
Edwin Hamel-De le Court, Francesco Belardinelli, and Alexander W. Goodall
-
[12]
doi:10.48550/ arXiv.2503.07671 arXiv:2503.07671 [stat]
Probabilistic Shielding for Safe Reinforcement Learning. doi:10.48550/ arXiv.2503.07671 arXiv:2503.07671 [stat]
-
[13]
Christian Dehnert, Sebastian Junges, Joost-Pieter Katoen, and Matthias Volk
-
[14]
InComputer Aided Verification (CA V) (Lecture Notes in Computer Science, Vol
A Storm is Coming: A Modern Probabilistic Model Checker. InComputer Aided Verification (CA V) (Lecture Notes in Computer Science, Vol. 10427). Springer, 592–600
-
[15]
Kwiatkowska, David Parker, and Mateusz Ujma
Klaus Dräger, Vojtech Forejt, Marta Z. Kwiatkowska, David Parker, and Mateusz Ujma. 2014. Permissive Controller Synthesis for Probabilistic Systems. InTools and Algorithms for the Construction and Analysis of Systems (TACAS) (Lecture Notes in Computer Science, Vol. 8413). Springer, 531–546
work page 2014
-
[16]
Kasper Engelen, Guillermo A. Pérez, and Marnix Suilen. 2025. Data-Efficient Safe Policy Improvement Using Parametric Structure.CoRRabs/2507.15532 (2025)
-
[17]
Damien Ernst, Pierre Geurts, and Louis Wehenkel. 2003. Iteratively Extending Time Horizon Reinforcement Learning. InECML (Lecture Notes in Computer Science, Vol. 2837). Springer, 96–107
work page 2003
-
[18]
Mohammad Ghavamzadeh, Marek Petrik, and Yinlam Chow. 2016. Safe Policy Improvement by Minimizing Robust Baseline Regret. InNIPS. 2298–2306
work page 2016
-
[19]
Goodall and Francesco Belardinelli
Alexander W. Goodall and Francesco Belardinelli. 2023. Approximate Model- Based Shielding for Safe Reinforcement Learning. InECAI (Frontiers in Artificial Intelligence and Applications, Vol. 372). IOS Press, 883–890
work page 2023
-
[20]
Alexander Hans and Steffen Udluft. 2009. Efficient Uncertainty Propagation for Reinforcement Learning with Limited Data. InICANN (1) (Lecture Notes in Computer Science, Vol. 5768). Springer, 70–79
work page 2009
-
[21]
León, and Francesco Belardinelli
Chloe He, Borja G. León, and Francesco Belardinelli. 2022. Do Androids Dream of Electric Fences? Safety-Aware Reinforcement Learning with Latent Shielding. InSafeAI@AAAI (CEUR Workshop Proceedings, Vol. 3087). CEUR-WS.org
work page 2022
- [22]
-
[23]
Garud N. Iyengar. 2005. Robust Dynamic Programming.Math. Oper. Res.30, 2 (2005), 257–280
work page 2005
-
[24]
Nils Jansen, Bettina Könighofer, Sebastian Junges, Alex Serban, and Roderick Bloem. 2020. Safe Reinforcement Learning Using Probabilistic Shields (Invited Paper). InCONCUR (LIPIcs, Vol. 171). Schloss Dagstuhl - Leibniz-Zentrum für Informatik, 3:1–3:16
work page 2020
-
[25]
Sebastian Junges, Nils Jansen, Christian Dehnert, Ufuk Topcu, and Joost-Pieter Katoen. 2016. Safety-Constrained Reinforcement Learning for MDPs. InTools and Algorithms for the Construction and Analysis of Systems (TACAS) (Lecture Notes in Computer Science, Vol. 9636). Springer, 130–146
work page 2016
-
[26]
Bettina Koenighofer, Roderick Bloem, Nils Jansen, Sebastian Junges, and Ste fan Pranger. 2025. Shields for safe reinforcement learning.CACM(2025)
work page 2025
-
[27]
2011.Prism4.0: Verifi- cation of Probabilistic Real-Time Systems
Marta Kwiatkowska, Gethin Norman, and David Parker. 2011.Prism4.0: Verifi- cation of Probabilistic Real-Time Systems. InComputer Aided Verification (CA V) (Lecture Notes in Computer Science, Vol. 6806). Springer, 585–591
work page 2011
-
[28]
Romain Laroche, Paul Trichelair, and Remi Tachet des Combes. 2019. Safe Policy Improvement with Baseline Bootstrapping. InICML (Proceedings of Machine Learning Research, Vol. 97). PMLR, 3652–3661
work page 2019
-
[29]
Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. 2020. Offline Re- inforcement Learning: Tutorial, Review, and Perspectives on Open Problems. CoRRabs/2005.01643 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[30]
2025 (to appear, preprint at https://arxiv.org/abs/2404.05424)
Tobias Meggendorfer, Maximilian Weininger, and Patrick Wienhöft. 2025 (to appear, preprint at https://arxiv.org/abs/2404.05424). What Are the Odds? Im- proving the foundations of Statistical Model Checking. InQEST + FORMATS
-
[31]
Daniel Melcer, Christopher Amato, and Stavros Tripakis. 2024. Shield Decentral- ization for Safe Reinforcement Learning in General Partially Observable Multi- Agent Environments. InAAMAS. International Foundation for Autonomous Agents and Multiagent Systems / ACM, 2384–2386
work page 2024
-
[32]
Kimia Nadjahi, Romain Laroche, and Rémi Tachet des Combes. 2019. Safe Policy Improvement with Soft Baseline Bootstrapping. InECML/PKDD (3) (Lecture Notes in Computer Science, Vol. 11908). Springer, 53–68
work page 2019
-
[33]
Arnab Nilim and Laurent El Ghaoui. 2005. Robust Control of Markov Decision Processes with Uncertain Transition Matrices.Oper. Res.53, 5 (2005), 780–798
work page 2005
-
[34]
Matteo Pirotta, Marcello Restelli, Alessio Pecorino, and Daniele Calandriello. 2013. Safe Policy Iteration. InICML (3) (JMLR Workshop and Conference Proceedings, Vol. 28). JMLR.org, 307–315
work page 2013
-
[35]
Stefan Pranger, Bettina Könighofer, Martin Tappler, Martin Deixelberger, Nils Jansen, and Roderick Bloem. 2021. Adaptive Shielding under Uncertainty. In ACC. IEEE, 3467–3474
work page 2021
-
[36]
Sangiovanni-Vincentelli, and Sanjit A
Alberto Puggelli, Wenchao Li, Alberto L. Sangiovanni-Vincentelli, and Sanjit A. Seshia. 2013. Polynomial-Time Verification of PCTL Properties of MDPs with Convex Uncertainties. InCA V (Lecture Notes in Computer Science, Vol. 8044). Springer, 527–542
work page 2013
- [37]
-
[38]
Thomas, Joelle Pineau, and Romain Laroche
Harsh Satija, Philip S. Thomas, Joelle Pineau, and Romain Laroche. 2021. Multi- Objective SPIBB: Seldonian Offline Policy Improvement with Safety Constraints in Finite MDPs. InNeurIPS. 2004–2017
work page 2021
-
[39]
2010.Uncertainty in Reinforcement Learning - A wareness, Quantisation, and Control
Daniel Schneegass, Alexander Hans, and Steffen Udluft. 2010.Uncertainty in Reinforcement Learning - A wareness, Quantisation, and Control. doi:10.5772/10250
-
[40]
Philipp Scholl, Felix Dietrich, Clemens Otte, and Steffen Udluft. 2022. Safe Policy Improvement Approaches and Their Limitations. InICAART (Revised Selected Paper (Lecture Notes in Computer Science, Vol. 13786). Springer, 74–98
work page 2022
-
[41]
Simão, Romain Laroche, and Rémi Tachet des Combes
Thiago D. Simão, Romain Laroche, and Rémi Tachet des Combes. 2020. Safe Policy Improvement with an Estimated Baseline Policy. InAAMAS. International Foundation for Autonomous Agents and Multiagent Systems, 1269–1277
work page 2020
-
[42]
Simão, David Parker, and Nils Jansen
Marnix Suilen, Thiago D. Simão, David Parker, and Nils Jansen. 2022. Robust Anytime Learning of Markov Decision Processes. InNeurIPS
work page 2022
-
[43]
Martin Tappler, Stefan Pranger, Bettina Könighofer, Edi Muskardin, Roderick Bloem, and Kim G. Larsen. 2022. Automata Learning Meets Shielding. InISoLA (1) (Lecture Notes in Computer Science, Vol. 13701). Springer, 335–359
work page 2022
-
[44]
Thomas, Georgios Theocharous, and Mohammad Ghavamzadeh
Philip S. Thomas, Georgios Theocharous, and Mohammad Ghavamzadeh. 2015. High-Confidence Off-Policy Evaluation. InAAAI. AAAI Press, 3000–3006
work page 2015
-
[45]
Mark Towers, Ariel Kwiatkowski, Jordan Terry, John U. Balis, Gianluca De Cola, Tristan Deleu, Manuel Goulão, Andreas Kallinteris, Markus Krimmel, Arjun KG, Rodrigo Perez-Vicente, Andrea Pierré, Sander Schulhoff, Jun Jet Tai, Hannah Tan, and Omar G. Younis. 2024. Gymnasium: A Standard Interface for Reinforcement Learning Environments. arXiv:2407.17032 [cs....
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
Simão, Clemens Dubslaff, Christel Baier, and Nils Jansen
Patrick Wienhöft, Marnix Suilen, Thiago D. Simão, Clemens Dubslaff, Christel Baier, and Nils Jansen. 2023. More for Less: Safe Policy Improvement with Stronger Performance Guarantees. InIJCAI. ijcai.org, 4406–4415
work page 2023
-
[47]
Wolfram Wiesemann, Daniel Kuhn, and Berç Rustem. 2013. Robust Markov Decision Processes.Math. Oper. Res.38, 1 (2013), 153–183
work page 2013
-
[48]
Wolff, Ufuk Topcu, and Richard M
Eric M. Wolff, Ufuk Topcu, and Richard M. Murray. 2012. Robust control of uncertain Markov Decision Processes with temporal logic specifications. InCDC. IEEE, 3372–3379. Table 2: The dimensions of the benchmarks and full range of hyperparameters used in the experiments. Benchmarks|𝑆| |𝐴|𝑁 ∧ 𝜈 𝜖 𝜃 𝜅 𝜂 𝛼 𝜉 Random MDPs50 4 3 0.1 0.5 0.2 0.05 0.1 51×10 −8 Wet...
work page 2012
-
[49]
for a more extensive discussion. During policy iteration, DUIPI updates the baseline policy by iteratively increasing the probability of the action with the highest penalized action-value 𝑈 . Actions not selected as best are adjusted accordingly to maintain a valid probability distribution. The rate of change decreases as the iteration count increases. Fo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.