Recognition: 2 theorem links
· Lean TheoremVerifiable Process Rewards for Agentic Reasoning
Pith reviewed 2026-05-12 04:54 UTC · model grok-4.3
The pith
Converting oracles into dense turn-level rewards improves credit assignment for long-horizon LLM agent reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
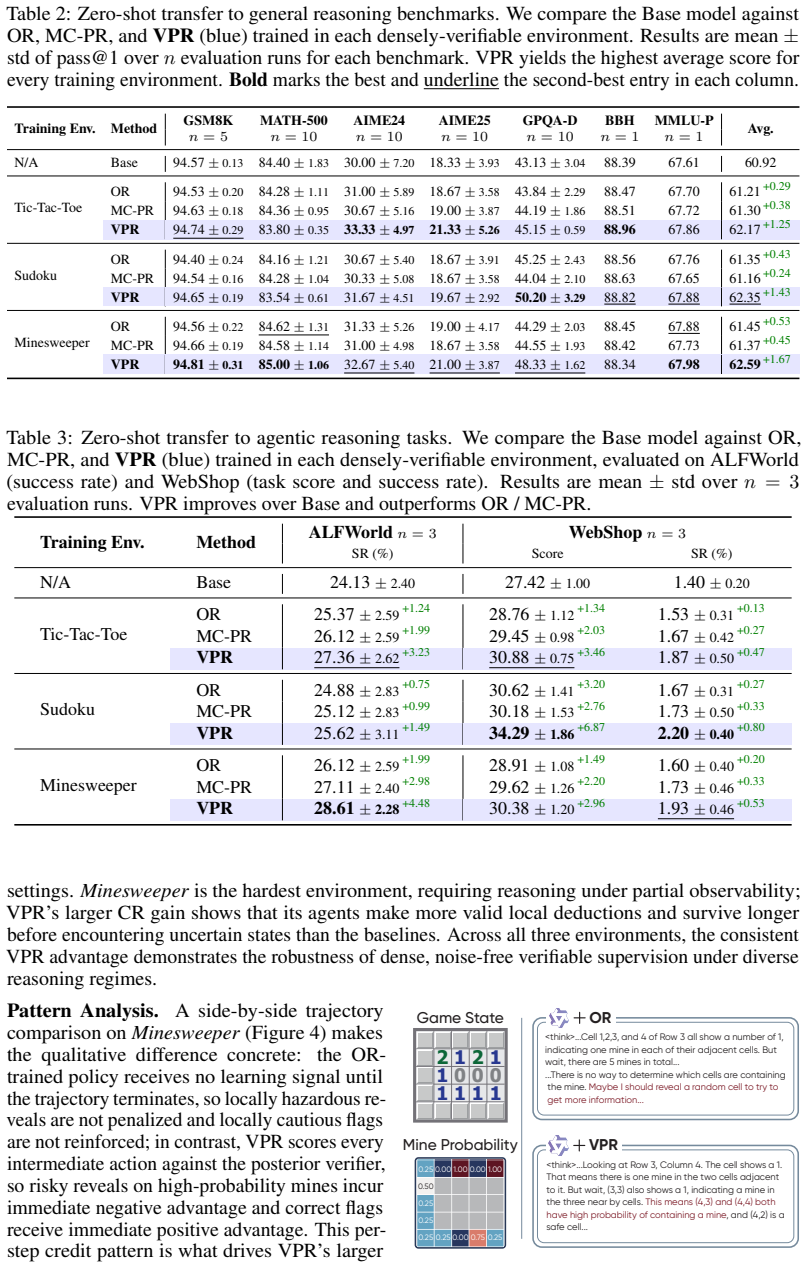
In densely-verifiable agentic reasoning problems, where intermediate actions can be checked by oracles, the VPR framework generates dense rewards at each turn. This provides more localized learning signals than sparse outcome feedback, improving credit assignment in reinforcement learning. The method is applied to dynamic deduction, logical reasoning, and probabilistic inference, outperforming baselines and transferring to general and agentic benchmarks.
What carries the argument
Verifiable Process Rewards (VPR), a framework that turns symbolic, algorithmic, or posterior-based oracles into dense turn-level supervision signals for reinforcement learning.
If this is right
- Outperforms outcome-level reward baselines in controlled environments.
- Outperforms rollout-based process reward baselines.
- Transfers to both general and agentic reasoning benchmarks.
- The improvement depends on the reliability of the verifier oracle.
Where Pith is reading between the lines
- Approximating oracles with learned models could extend VPR to open-ended tasks without perfect verifiers.
- Hybrid use of process and outcome rewards might balance dense signals with final accuracy.
- This approach could inform training of agents in domains like planning or scientific discovery where partial verification is feasible.
Load-bearing premise
Reliable oracles are available to verify the correctness of intermediate actions in the agentic reasoning problems considered.
What would settle it
A test where the oracle verifier is replaced with a noisy or inaccurate one, and VPR no longer shows gains over baselines, would indicate the claim depends on oracle quality as stated.
Figures



read the original abstract
Reinforcement learning from verifiable rewards (RLVR) has improved the reasoning abilities of large language models (LLMs), but most existing approaches rely on sparse outcome-level feedback. This sparsity creates a credit assignment challenge in long-horizon agentic reasoning: a trajectory may fail despite containing many correct intermediate decisions, or succeed despite containing flawed ones. In this work, we study a class of densely-verifiable agentic reasoning problems, where intermediate actions can be objectively checked by symbolic or algorithmic oracles. We propose Verifiable Process Rewards (VPR), a framework that converts such oracles into dense turn-level supervision for reinforcement learning, and instantiate it in three representative settings: search-based verification for dynamic deduction, constraint-based verification for logical reasoning, and posterior-based verification for probabilistic inference. We further provide a theoretical analysis showing that dense verifier-grounded rewards can improve long-horizon credit assignment by providing more localized learning signals, with the benefit depending on the reliability of the verifier. Empirically, VPR outperforms outcome-level reward and rollout-based process reward baselines across controlled environments, and more importantly, transfers to both general and agentic reasoning benchmarks, suggesting that verifiable process supervision can foster general reasoning skills applicable beyond the training environments. Our results indicate that VPR is a promising approach for enhancing LLM agents whenever reliable intermediate verification is available, while also highlighting its dependence on oracle quality and the open challenge of extending VPR to less structured, open-ended environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Verifiable Process Rewards (VPR) convert symbolic/algorithmic oracles into dense turn-level supervision for RLVR on long-horizon agentic reasoning tasks, instantiated in search-based deduction, constraint-based logic, and posterior inference settings. It provides a theoretical analysis showing that such dense verifier-grounded rewards improve credit assignment via more localized signals (with gains depending on verifier reliability), and reports that VPR empirically outperforms outcome-level rewards and rollout-based process reward baselines in controlled environments while transferring to general and agentic reasoning benchmarks, suggesting it fosters generalizable reasoning skills.
Significance. If the transfer results hold under controls that isolate the process-reward contribution, this work could meaningfully advance LLM agent training in domains admitting reliable intermediate oracles by addressing a core credit-assignment limitation of sparse RLVR. The explicit conditioning of theoretical benefits on verifier reliability and the three concrete oracle instantiations are clear strengths that provide a useful framework for future work on verifiable supervision.
major comments (2)
- [§4] §4 (Transfer Experiments): the outperformance on non-verifiable general and agentic benchmarks is reported without ablations that hold the base RL algorithm, training duration, and data distribution fixed while removing the dense process signals or substituting noisy oracles; this is load-bearing for the central claim that VPR produces generalizable reasoning skills rather than environment-specific effects tied to the three training oracles.
- [§3] §3 (Theoretical Analysis): the derivation correctly ties credit-assignment gains to verifier reliability, yet the manuscript provides no quantitative sensitivity analysis or simulations of performance degradation under noisy oracles when evaluating transfer; without this, the link between the theory and the reported generalization to open-ended benchmarks remains untested.
minor comments (3)
- [§2] The formal definition of 'densely-verifiable' problems in §2 would benefit from an explicit condition distinguishing full intermediate verifiability from partial or probabilistic cases.
- [Tables in §4] Tables reporting transfer results should include the number of random seeds and statistical significance tests to support the outperformance claims.
- [Introduction] A few citations to prior process-supervision and credit-assignment literature appear to be missing from the related-work discussion in the introduction.
Simulated Author's Rebuttal
We are grateful to the referee for the thoughtful review and for identifying key points that can strengthen the empirical validation of our claims. Below, we provide point-by-point responses to the major comments.
read point-by-point responses
-
Referee: [§4] §4 (Transfer Experiments): the outperformance on non-verifiable general and agentic benchmarks is reported without ablations that hold the base RL algorithm, training duration, and data distribution fixed while removing the dense process signals or substituting noisy oracles; this is load-bearing for the central claim that VPR produces generalizable reasoning skills rather than environment-specific effects tied to the three training oracles.
Authors: We concur that more rigorous ablations are needed to isolate the contribution of the dense process rewards to the observed transfer performance. The manuscript currently demonstrates outperformance relative to outcome-only reward baselines under the same RL algorithm, but does not fully control for training duration and data distribution in the transfer evaluations. In the revised version, we will incorporate additional experiments that train models with and without the VPR signals on identical data and for the same number of steps, followed by evaluation on the general and agentic benchmarks. We will also consider experiments with noisy oracles to test robustness. revision: yes
-
Referee: [§3] §3 (Theoretical Analysis): the derivation correctly ties credit-assignment gains to verifier reliability, yet the manuscript provides no quantitative sensitivity analysis or simulations of performance degradation under noisy oracles when evaluating transfer; without this, the link between the theory and the reported generalization to open-ended benchmarks remains untested.
Authors: The theoretical analysis in §3 explicitly links the credit assignment improvements to the reliability of the verifier. Although the empirical sections include results from multiple oracle instantiations that implicitly vary in reliability, we did not include dedicated sensitivity simulations for noisy oracles in the context of transfer to open benchmarks. We agree this would better test the theory's implications for generalization. Accordingly, the revised manuscript will include quantitative sensitivity analyses and simulations demonstrating performance degradation under varying levels of oracle noise for the transfer tasks. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central claims rest on external symbolic/algorithmic oracles for dense supervision and a theoretical analysis that explicitly conditions benefits on verifier reliability as an independent factor. Empirical results are framed as outperformance against outcome-level and rollout baselines in controlled settings plus transfer to benchmarks, without any reduction of predictions to fitted parameters by construction or self-definitional loops. No load-bearing self-citations, ansatz smuggling, or renaming of known results appear in the derivation; the approach is self-contained against the stated external oracles and does not equate its outputs to its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reliable symbolic, algorithmic, or posterior-based oracles exist that can objectively verify intermediate actions in the target agentic reasoning problems.
invented entities (1)
-
Verifiable Process Rewards (VPR)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearProposition 2 (Bias scales linearly with verifier error)... gradient bias satisfies ‖bg(θ)−g⋆(θ)‖≤G¯ϵ.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative uncleardense verifier-grounded rewards can improve long-horizon credit assignment by providing more localized learning signals
Reference graph
Works this paper leans on
-
[1]
FireAct: Toward language agent fine-tuning,
Baian Chen, Chang Shu, Ehsan Shareghi, Nigel Collier, Karthik Narasimhan, and Shunyu Yao. Fireact: Toward language agent fine-tuning.arXiv preprint arXiv:2310.05915, 2023
-
[2]
Group-in-Group Policy Optimization for LLM Agent Training
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. Group-in-group policy optimization for llm agent training.arXiv preprint arXiv:2505.10978, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
CRITIC: Large language models can self-correct with tool-interactive critiquing
Zhibin Gou, Zhihong Shao, Yeyun Gong, yelong shen, Yujiu Yang, Nan Duan, and Weizhu Chen. CRITIC: Large language models can self-correct with tool-interactive critiquing. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Large language models cannot self-correct reasoning yet
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. Large language models cannot self-correct reasoning yet. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[6]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. SWE-bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[8]
Leslie Pack Kaelbling, Michael L. Littman, and Anthony R. Cassandra. Planning and acting in partially observable stochastic domains.Artificial Intelligence, 101(1):99–134, 1998
work page 1998
-
[9]
VinePPO: Refining credit assignment in RL training of LLMs
Amirhossein Kazemnejad, Milad Aghajohari, Eva Portelance, Alessandro Sordoni, Siva Reddy, Aaron Courville, and Nicolas Le Roux. VinePPO: Refining credit assignment in RL training of LLMs. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[10]
Adam: A Method for Stochastic Optimization
Diederik P Kingma. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[11]
Bandit based monte-carlo planning
Levente Kocsis and Csaba Szepesvári. Bandit based monte-carlo planning. In Johannes Fürnkranz, Tobias Scheffer, and Myra Spiliopoulou, editors,Machine Learning: ECML 2006, pages 282–293, Berlin, Heidelberg, 2006. Springer Berlin Heidelberg
work page 2006
-
[12]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large lan- guage model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
work page 2023
-
[13]
Openspiel: A framework for reinforcement learning in games.arXiv preprint arXiv:1908.09453, 2019
Marc Lanctot, Edward Lockhart, Jean-Baptiste Lespiau, Vinicius Zambaldi, Satyaki Upadhyay, Julien Pérolat, Sriram Srinivasan, Finbarr Timbers, Karl Tuyls, Shayegan Omidshafiei, Daniel Hennes, Dustin Morrill, Paul Muller, Timo Ewalds, Ryan Faulkner, János Kramár, Bart De Vylder, Brennan Saeta, James Bradbury, David Ding, Sebastian Borgeaud, Matthew Lai, Ju...
-
[14]
Coderl: Mastering code generation through pretrained models and deep reinforcement learning
Hung Le, Yue Wang, Akhilesh Deepak Gotmare, Silvio Savarese, and Steven Chu Hong Hoi. Coderl: Mastering code generation through pretrained models and deep reinforcement learning. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems, volume 35, pages 21314–21328. Curran Associates, ...
work page 2022
-
[15]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, 2024. 10
work page 2024
-
[16]
Agentbench: Evaluating LLMs as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. Agentbench: Evaluating LLMs as agents. InThe Twelfth International Conference on Learning R...
work page 2024
-
[17]
arXiv preprint arXiv:2510.01051 , year=
Zichen Liu, Anya Sims, Keyu Duan, Changyu Chen, Simon Yu, Xiangxin Zhou, Haotian Xu, Shaopan Xiong, Bo Liu, Chenmien Tan, et al. Gem: A gym for agentic llms.arXiv preprint arXiv:2510.01051, 2025
-
[18]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedbac...
work page 2022
-
[19]
Logic-LM: Empowering large language models with symbolic solvers for faithful logical reasoning
Liangming Pan, Alon Albalak, Xinyi Wang, and William Wang. Logic-LM: Empowering large language models with symbolic solvers for faithful logical reasoning. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Findings of the Association for Computational Linguistics: EMNLP 2023, pages 3806–3824, Singapore, December 2023. Association for Computational Linguistics
work page 2023
-
[20]
Code Llama: Open Foundation Models for Code
Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. Code llama: Open foundation models for code.arXiv preprint arXiv:2308.12950, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Reflex- ion: language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflex- ion: language agents with verbal reinforcement learning. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 8634–8652. Curran Associates, Inc., 2023
work page 2023
-
[23]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter language models using model parallelism.arXiv preprint arXiv:1909.08053, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[24]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. Alfworld: Aligning text and embodied environments for interactive learning.arXiv preprint arXiv:2010.03768, 2020
work page internal anchor Pith review arXiv 2010
-
[25]
EvalScope: Evaluation framework for large models, 2024
ModelScope Team. EvalScope: Evaluation framework for large models, 2024
work page 2024
-
[26]
Solving math word problems with process- and outcome-based feedback
Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process-and outcome-based feedback.arXiv preprint arXiv:2211.14275, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[27]
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345, 2024
work page 2024
-
[28]
Math-shepherd: Verify and reinforce LLMs step-by-step without human annotations
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce LLMs step-by-step without human annotations. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), page...
work page 2024
-
[29]
Weixun Wang, Shaopan Xiong, Gengru Chen, Wei Gao, Sheng Guo, Yancheng He, Ju Huang, Jiaheng Liu, Zhendong Li, Xiaoyang Li, et al. Reinforcement learning optimization for large- scale learning: An efficient and user-friendly scaling library.arXiv preprint arXiv:2506.06122, 2025
-
[30]
what it can create, it may not understand
Peter West, Ximing Lu, Nouha Dziri, Faeze Brahman, Linjie Li, Jena D. Hwang, Liwei Jiang, Jillian Fisher, Abhilasha Ravichander, Khyathi Chandu, Benjamin Newman, Pang Wei Koh, Allyson Ettinger, and Yejin Choi. The generative AI paradox: “what it can create, it may not understand”. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[31]
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, et al. The rise and potential of large language model based agents: A survey.Science China Information Sciences, 68(2):121101, 2025
work page 2025
-
[32]
Zelai Xu, Zhexuan Xu, Xiangmin Yi, Huining Yuan, Xinlei Chen, Yi Wu, Chao Yu, and Yu Wang. Vs-bench: Evaluating vlms for strategic reasoning and decision-making in multi- agent environments.coming soon, 2025
work page 2025
-
[33]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Information Processing Systems, 35:20744–20757, 2022
work page 2022
-
[35]
Tree of thoughts: Deliberate problem solving with large language models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 11809–11822. Curran Associates, Inc., 2023
work page 2023
-
[36]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[37]
OVM, outcome-supervised value models for planning in mathematical reasoning
Fei Yu, Anningzhe Gao, and Benyou Wang. OVM, outcome-supervised value models for planning in mathematical reasoning. In Kevin Duh, Helena Gomez, and Steven Bethard, editors, Findings of the Association for Computational Linguistics: NAACL 2024, pages 858–875, Mexico City, Mexico, June 2024. Association for Computational Linguistics
work page 2024
-
[38]
Judging llm-as-a-judge with mt-bench and chatbot arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, Hao Zhang, Joseph E Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Sys...
work page 2023
-
[39]
Language agent tree search unifies reasoning, acting, and planning in language models
Andy Zhou, Kai Yan, Michal Shlapentokh-Rothman, Haohan Wang, and Yu-Xiong Wang. Language agent tree search unifies reasoning, acting, and planning in language models. In Forty-first International Conference on Machine Learning, 2024. 12 A Reproducibility Statement To facilitate future research and ensure the reproducibility of our results, we have made al...
work page 2024
-
[40]
Tic - tac - toe is a two - player board game played on a three - by - three grid . The grid is 0 - indexed , where (0 ,0) is the top - left corner and (2 ,2) is the bottom - right corner
-
[41]
Two players take turns placing their marks X and O in empty cells of the grid
-
[42]
The player who first places three of their marks in a horizontal , vertical , or diagonal line wins
-
[43]
PLAYER I N F O R M A T I O N :
If all cells are filled and no player wins , the game ends in a draw . PLAYER I N F O R M A T I O N :
-
[44]
You are c om pe ti ng with another player c o n t r o l l i n g the mark O
Your mark is X . You are c om pe ti ng with another player c o n t r o l l i n g the mark O . 16
-
[45]
In each of your turns : a . The game state d e m o n s t r a t e s the current board with a three - line text grid , where ’X ’ and ’O ’ are the marks of the two players , and ’. ’ r e p r e s e n t s empty cells . b . You need to choose an action to place your mark in an empty cell , based on the given game state and the history of your d eci si on s . c...
-
[46]
Rows and columns are 1 - indexed (1 to 9)
Sudoku is played on a 9 x9 grid . Rows and columns are 1 - indexed (1 to 9)
-
[47]
The goal is to fill the empty cells with digits from 1 to 9
-
[48]
Each row must contain all digits from 1 to 9 without r e p e t i t i o n
-
[49]
Each column must contain all digits from 1 to 9 without r e p e t i t i o n
-
[50]
Each of the nine 3 x3 subgrids must contain all digits from 1 to 9 without r e p e t i t i o n
-
[51]
PLAYER I N F O R M A T I O N :
You cannot o ve rw ri te pre - filled cells . PLAYER I N F O R M A T I O N :
-
[52]
The current board state is d is pl ay ed as a text grid . - ’. ’ r e p r e s e n t s an empty cell . - Numbers re pr es ent filled cells . - Rows are labeled R1 , R2 ... and Columns C1 , C2
-
[53]
In each turn , you choose an action to fill an empty cell with a number
-
[54]
All legal actions are provided in the format ‘< fill ({ row } ,{ col } ,{ number }) > ‘. RESPONSE I N S T R U C T I O N S : 17 Always choose strictly one action and output ‘< answer >{ your chosen action } </ answer > ‘ with no extra text after you finish the thinking process . For example , to fill row 1 , column 1 with number 5 , output ‘< answer > < fi...
-
[55]
The grid contains exactly 5 hidden mines
M i n e s w e e p e r is played on a 5 x5 grid of cells . The grid contains exactly 5 hidden mines . The grid is 0 - indexed , where (0 ,0) is the top - left corner and (4 ,4) is the bottom - right corner
-
[56]
The goal is to reveal all cells that do not contain mines without re ve al in g any mine
-
[57]
If you reveal a mine , you lose the game i m m e d i a t e l y
-
[58]
If you reveal a safe cell , it will show a number i n d i c a t i n g how many mines are adjacent to it ( n ei gh bo rs include d ia go nal s )
-
[59]
PLAYER I N F O R M A T I O N :
You can also place a flag on a cell if you suspect it contains a mine , or remove a flag if you change your mind . PLAYER I N F O R M A T I O N :
-
[60]
’ r e p r e s e n t s an u n r e v e a l e d cell
The current board state is d is pl ay ed as a text grid , where : - ’. ’ r e p r e s e n t s an u n r e v e a l e d cell . - ’F ’ r e p r e s e n t s a flagged cell . - A number (0 -8) r e p r e s e n t s a revealed safe cell with that many adjacent mines
-
[61]
In each turn , you must choose an action to either reveal a cell or flag / unflag a cell
-
[62]
All legal actions are provided in the format ‘< reveal ({ row } ,{ col }) >‘ or ‘< flag ({ row } ,{ col }) > ‘. The ’ flag ’ command acts as a toggle : play it on an un fl agg ed cell to place a flag , or on a flagged cell to remove it . RESPONSE I N S T R U C T I O N S : 18 Always choose strictly one action and output ‘< answer >{ your chosen action } </...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.