Recognition: 2 theorem links
· Lean TheoremThe Alpha Blending Hypothesis: Compositing Shortcut in Deepfake Detection
Pith reviewed 2026-05-12 05:05 UTC · model grok-4.3
The pith
Deepfake detectors primarily search for alpha blending compositing artifacts rather than semantic or generative cues.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that state-of-the-art frame-based detectors primarily function as alpha blending searchers. They localize low-level compositing artifacts introduced during the integration of manipulated faces into target frames, rather than learning semantic anomalies or specific generative neural fingerprints.
What carries the argument
The Alpha Blending Hypothesis, which frames detector success as the detection of alpha blending artifacts created when fake faces are composited into target frames.
If this is right
- Detectors exhibit high sensitivity to self-blended images and to simple non-generative manipulations.
- Training on real images augmented only with synthetic blends produces strong average cross-dataset generalization on compositional deepfake collections.
- Explicit blending searchers and models that avoid blending shortcuts produce complementary predictions.
- An ensemble of the two types of models yields improved detection results.
Where Pith is reading between the lines
- Many existing deepfake benchmarks may be solved largely by exploiting compositing cues instead of learning forgery semantics.
- Future detectors could be hardened by training on data that deliberately varies or removes blending signals.
- The method suggests it is possible to build effective detectors without ever training on explicitly generated deepfake examples.
Load-bearing premise
High sensitivity to self-blended real images and non-generative manipulations shows that detectors rely primarily on compositing artifacts rather than other cues.
What would settle it
A detector that continues to generalize across deepfake datasets after all compositing artifacts have been removed from both training and test images would falsify the hypothesis.
Figures
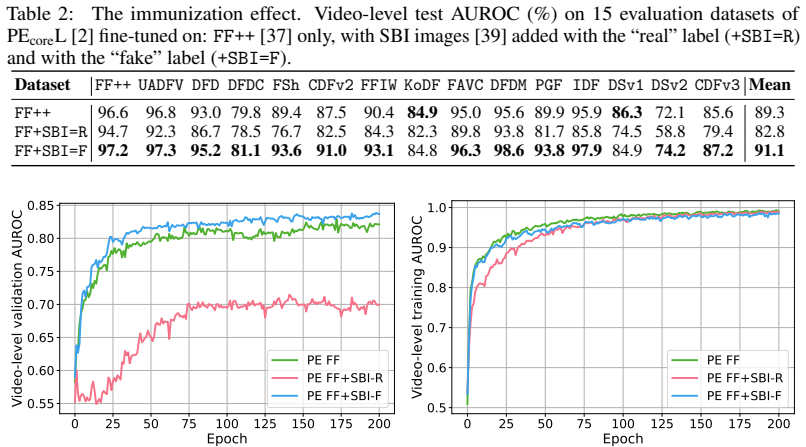

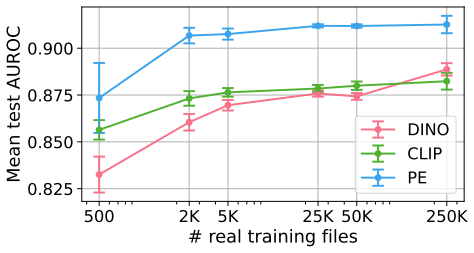
read the original abstract
Recent deepfake detection methods demonstrate improved cross-dataset generalization, yet the underlying mechanisms remain underexplored. We introduce the Alpha Blending Hypothesis, positing that state-of-the-art frame-based detectors primarily function as alpha blending searchers; rather than learning semantic anomalies or specific generative neural fingerprints, they localize low-level compositing artifacts introduced during the integration of manipulated faces into target frames. We experimentally validate the hypothesis, demonstrating that deepfake detectors exhibit high sensitivity to the so-called self-blended images (SBI) and non-generative manipulations. We propose the method BlenD that leverages a large-scale, diverse dataset of real-only facial images augmented with SBI. This approach achieves the best average cross-dataset generalization on 15 compositional deepfake datasets released between 2019 and 2025 without utilizing explicitly generated deepfakes during training. Furthermore, we show that predictions from explicit blending searchers and models resilient to blending shortcuts are highly complementary, yielding a state-of-the-art AUROC of 94.0% in an ensemble configuration. The code with experiments and the trained model will be publicly released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Alpha Blending Hypothesis, which posits that state-of-the-art frame-based deepfake detectors primarily function as alpha blending searchers that localize low-level compositing artifacts from face integration rather than semantic anomalies or generative neural fingerprints. It validates the hypothesis empirically by demonstrating high detector sensitivity to self-blended images (SBI) and non-generative manipulations, proposes the BlenD training method that uses only real facial images augmented with SBI to achieve the best average cross-dataset generalization across 15 compositional deepfake datasets (2019-2025) without any explicitly generated deepfakes, and shows that an ensemble of explicit blending searchers with blending-resilient models reaches 94.0% AUROC. The code, experiments, and trained model are to be released publicly.
Significance. If the central results hold, the work is significant for offering a mechanistic account of why recent deepfake detectors generalize well across datasets and for introducing a practical, real-image-only training regime that sidesteps the need to generate or curate synthetic deepfakes. The scale of the evaluation (15 datasets spanning multiple years), the demonstration of complementarity via the ensemble, and the commitment to public code and model release are clear strengths that support reproducibility and further investigation in the field.
major comments (2)
- [Hypothesis validation experiments] Abstract and hypothesis validation: The claim that detectors 'primarily' function as alpha blending searchers is inferred from observed high sensitivity to SBI and non-generative manipulations plus the success of the SBI-only BlenD regime. However, this remains correlational evidence of sufficiency; the manuscript does not include a controlled ablation that removes or masks alpha-blending artifacts while preserving other potential cues (semantic inconsistencies or generative fingerprints) and then quantifies the resulting performance degradation. Such an isolation test is load-bearing for the 'primarily' qualifier and would be required to rule out mixed reliance on multiple cue types.
- [BlenD training and evaluation] BlenD method and cross-dataset results: While the average generalization across 15 datasets is presented as state-of-the-art, the manuscript should provide per-dataset AUROC breakdowns (ideally in a table) together with explicit details on SBI generation parameters, the real-to-blended sample ratio, and any post-processing steps. Without these, it is difficult to assess whether the reported gains are robust or could be influenced by unstated dataset-construction choices.
minor comments (3)
- [Abstract] The abstract states that BlenD 'achieves the best average cross-dataset generalization' but does not report the numerical average AUROC value or list the specific baseline methods and scores being compared; adding these figures would make the summary self-contained.
- [Figures illustrating SBI and detector responses] Figure captions and SBI examples should explicitly state the blending parameters (alpha range, mask type, source/target image selection) used to generate the illustrated self-blended images so that readers can reproduce the sensitivity tests.
- [Discussion or conclusion] The manuscript would benefit from a short discussion of potential limitations, such as whether the alpha-blending shortcut remains dominant for video-level or temporal deepfake detectors that may exploit additional motion cues.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: The claim that detectors 'primarily' function as alpha blending searchers is inferred from high sensitivity to SBI and non-generative manipulations plus BlenD success. This is correlational evidence; a controlled ablation removing alpha-blending artifacts while preserving other cues (semantic inconsistencies or generative fingerprints) is needed to quantify degradation and support the 'primarily' qualifier.
Authors: We agree that the current evidence is primarily correlational and that a direct ablation isolating blending artifacts from other potential cues would offer stronger causal support for the 'primarily' claim. Designing such an experiment without introducing new confounds is technically challenging. In the revised manuscript we will add a dedicated limitations subsection that explicitly discusses this gap, refine the abstract and hypothesis statements to avoid overclaiming, and include additional supporting analyses (e.g., further sensitivity tests on non-blending manipulations). We believe the combination of SBI sensitivity, BlenD's cross-dataset performance without synthetic deepfakes, and complementarity with blending-resilient models still provides meaningful mechanistic insight. revision: partial
-
Referee: The manuscript should provide per-dataset AUROC breakdowns (ideally in a table) together with explicit details on SBI generation parameters, the real-to-blended sample ratio, and any post-processing steps.
Authors: We agree that these details will improve transparency and allow readers to better evaluate robustness. The revised manuscript will include a new table reporting AUROC for each of the 15 individual datasets. We will also expand the experimental setup section to specify all SBI generation parameters, the exact real-to-blended training ratio, and any post-processing steps applied. revision: yes
Circularity Check
No circularity: empirical hypothesis tested on external data without self-referential reduction
full rationale
The paper advances the Alpha Blending Hypothesis through experimental validation on external deepfake datasets and non-generative manipulations, then introduces BlenD trained exclusively on real images augmented with self-blended images. No derivation chain, equation, or central claim reduces by construction to fitted parameters, self-citations, or renamed inputs; the sufficiency of blending artifacts is demonstrated via cross-dataset AUROC on 15 independent compositional sets, and complementarity with other models is shown empirically. The approach remains self-contained against external benchmarks with no load-bearing self-citation or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Self-blended images (SBI) and non-generative manipulations isolate low-level compositing artifacts that match those in real deepfakes.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce the Alpha Blending Hypothesis, positing that state-of-the-art frame-based detectors primarily function as alpha blending searchers; rather than learning semantic anomalies or specific generative neural fingerprints, they localize low-level compositing artifacts introduced during the integration of manipulated faces into target frames.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
I=M⊙IF+(1−M)⊙IB (alpha blending equation) and SBI self-blended image construction
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Sarah Barrington, Matyas Bohacek, and Hany Farid. DeepSpeak dataset v1.0.arXiv preprint arXiv:2408.05366, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Perception encoder: The best visual embeddings are not at the output of the network
Daniel Bolya, Po-Yao Huang, Peize Sun, Jang Hyun Cho, Andrea Madotto, Chen Wei, Tengyu Ma, Jiale Zhi, Jathushan Rajasegaran, Hanoona Abdul Rasheed, Junke Wang, Marco Monteiro, Hu Xu, Shiyu Dong, Nikhila Ravi, Shang-Wen Li, Piotr Dollar, and Christoph Feichtenhofer. Perception encoder: The best visual embeddings are not at the output of the network. In The...
work page 2025
-
[3]
Peter J. Burt and Edward H. Adelson. A multiresolution spline with application to image mosaics. ACM Trans. Graph., 2(4):217–236, October 1983. ISSN 0730-0301. doi: 10.1145/245.247. URLhttps://doi.org/10.1145/245.247
-
[4]
Forensics adapter: Adapting CLIP for generalizable face forgery detection
Xinjie Cui, Yuezun Li, Ao Luo, Jiaran Zhou, and Junyu Dong. Forensics adapter: Adapting CLIP for generalizable face forgery detection. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 19207–19217, 2025
work page 2025
-
[5]
Soumyya Kanti Datta, Shan Jia, and Siwei Lyu. Detecting lip-syncing deepfakes: Vision temporal transformer for analyzing mouth inconsistencies.arXiv preprint arXiv:2504.01470, 2025
-
[6]
Retinaface: Single-shot multi-level face localisation in the wild
Jiankang Deng, Jia Guo, Evangelos Ververas, Irene Kotsia, and Stefanos Zafeiriou. Retinaface: Single-shot multi-level face localisation in the wild. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5203–5212, 2020
work page 2020
-
[7]
The DeepFake Detection Challenge (DFDC) Dataset
Brian Dolhansky, Joanna Bitton, Ben Pflaum, Jikuo Lu, Russ Howes, Menglin Wang, and Cristian Canton Ferrer. The deepfake detection challenge (DFDC) dataset.arXiv preprint arXiv:2006.07397, 2020
work page internal anchor Pith review arXiv 2006
-
[8]
Deepfakes Detection Dataset by Google & Jigsaw
Nicholas Dufour, Andrew Gully, Per Karlsson, Alexey Victor V orbyov, Thomas Leung, Jeremiah Childs, and Christoph Bregler. Deepfakes Detection Dataset by Google & Jigsaw. https:// research.google/blog/contributing-data-to-deepfake-detection-research/ , 2019
work page 2019
-
[9]
arXiv preprint arXiv:2407.03168 , year =
Jianzhu Guo, Dingyun Zhang, Xiaoqiang Liu, Zhizhou Zhong, Yuan Zhang, Pengfei Wan, and Di Zhang. Liveportrait: Efficient portrait animation with stitching and retargeting control.arXiv preprint arXiv:2407.03168, 2024
-
[10]
Lips don’t lie: A generalisable and robust approach to face forgery detection
Alexandros Haliassos, Konstantinos V ougioukas, Stavros Petridis, and Maja Pantic. Lips don’t lie: A generalisable and robust approach to face forgery detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5039–5049, 2021
work page 2021
-
[11]
Leveraging real talking faces via self-supervision for robust forgery detection
Alexandros Haliassos, Rodrigo Mira, Stavros Petridis, and Maja Pantic. Leveraging real talking faces via self-supervision for robust forgery detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14950–14962, 2022
work page 2022
-
[12]
Ahmed Abul Hasanaath, Hamzah Luqman, Raed Katib, and Saeed Anwar. FSBI: Deepfake detection with frequency enhanced self-blended images.Image and Vision Computing, 154: 105418, 2025
work page 2025
-
[13]
PolyGlotFake: A novel multilingual and multimodal deepfake dataset
Yang Hou, Haitao Fu, Chunkai Chen, Zida Li, Haoyu Zhang, and Jianjun Zhao. PolyGlotFake: A novel multilingual and multimodal deepfake dataset. InInternational Conference on Pattern Recognition, pages 180–193. Springer, 2024
work page 2024
-
[14]
Exposing gan-generated faces using inconsistent corneal specular highlights
Shu Hu, Yuezun Li, and Siwei Lyu. Exposing gan-generated faces using inconsistent corneal specular highlights. InICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 2500–2504. IEEE, 2021
work page 2021
-
[15]
Model attribution of face-swap deepfake videos
Shan Jia, Xin Li, and Siwei Lyu. Model attribution of face-swap deepfake videos. In2022 IEEE International Conference on Image Processing (ICIP), pages 2356–2360. IEEE, 2022. 10
work page 2022
- [16]
-
[17]
Beyond spatial frequency: Pixel-wise temporal frequency-based deepfake video detection
Taehoon Kim, Jongwook Choi, Yonghyun Jeong, Haeun Noh, Jaejun Yoo, Seungryul Baek, and Jongwon Choi. Beyond spatial frequency: Pixel-wise temporal frequency-based deepfake video detection. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11198–11207, 2025
work page 2025
-
[18]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[19]
KoDF: A large-scale korean deepfake detection dataset
Patrick Kwon, Jaeseong You, Gyuhyeon Nam, Sungwoo Park, and Gyeongsu Chae. KoDF: A large-scale korean deepfake detection dataset. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10744–10753, 2021
work page 2021
-
[20]
Seeable: Soft discrepancies and bounded contrastive learning for exposing deepfakes
Nicolas Larue, Ngoc-Son Vu, Vitomir Struc, Peter Peer, and Vassilis Christophides. Seeable: Soft discrepancies and bounded contrastive learning for exposing deepfakes. InProceedings of the IEEE/CVF international conference on computer vision, pages 21011–21021, 2023
work page 2023
-
[21]
Sok: Systematization and benchmarking of deepfake detectors in a unified framework
Binh M Le, Jiwon Kim, Simon S Woo, Kristen Moore, Alsharif Abuadbba, and Shahroz Tariq. Sok: Systematization and benchmarking of deepfake detectors in a unified framework. In2025 IEEE 10th European Symposium on Security and Privacy (EuroS&P), pages 883–902. IEEE, 2025
work page 2025
-
[22]
Chunyu Li, Chao Zhang, Weikai Xu, Jingyu Lin, Jinghui Xie, Weiguo Feng, Bingyue Peng, Cunjian Chen, and Weiwei Xing. Latentsync: Taming audio-conditioned latent diffusion models for lip sync with syncnet supervision.arXiv preprint arXiv:2412.09262, 2024
-
[23]
Advancing high fidelity identity swapping for forgery detection
Lingzhi Li, Jianmin Bao, Hao Yang, Dong Chen, and Fang Wen. Advancing high fidelity identity swapping for forgery detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5074–5083, 2020
work page 2020
-
[24]
In ictu oculi: Exposing ai generated fake face videos by detecting eye blinking
Yuezun Li, Ming-Ching Chang, and Siwei Lyu. In ictu oculi: Exposing ai generated fake face videos by detecting eye blinking. InIEEE International Workshop on Information Forensics and Security (WIFS), 2018
work page 2018
-
[25]
Celeb-DF: A large-scale challeng- ing dataset for deepfake forensics
Yuezun Li, Xin Yang, Pu Sun, Honggang Qi, and Siwei Lyu. Celeb-DF: A large-scale challeng- ing dataset for deepfake forensics. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3207–3216, 2020
work page 2020
-
[26]
Yuezun Li, Delong Zhu, Xinjie Cui, and Siwei Lyu. Celeb-DF++: A large-scale challenging video deepfake benchmark for generalizable forensics.arXiv preprint arXiv:2507.18015, 2025
-
[27]
Yuzhen Lin, Wentang Song, Bin Li, Yuezun Li, Jiangqun Ni, Han Chen, and Qiushi Li. Fake it till you make it: Curricular dynamic forgery augmentations towards general deepfake detection. InEuropean conference on computer vision, pages 104–122. Springer, 2024
work page 2024
-
[28]
Weifeng Liu, Tianyi She, Jiawei Liu, Boheng Li, Dongyu Yao, and Run Wang. Lips are lying: Spotting the temporal inconsistency between audio and visual in lip-syncing deepfakes. Advances in Neural Information Processing Systems, 37:91131–91155, 2024
work page 2024
-
[29]
Generalizing face forgery detection with high-frequency features
Yuchen Luo, Yong Zhang, Junchi Yan, and Wei Liu. Generalizing face forgery detection with high-frequency features. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16317–16326, 2021
work page 2021
-
[30]
Exploiting visual artifacts to expose deepfakes and face manipulations
Falko Matern, Christian Riess, and Marc Stamminger. Exploiting visual artifacts to expose deepfakes and face manipulations. In2019 IEEE Winter Applications of Computer Vision Workshops (WACVW), pages 83–92, 2019
work page 2019
-
[31]
Diff2lip: Audio conditioned diffusion models for lip-synchronization
Soumik Mukhopadhyay, Saksham Suri, Ravi Teja Gadde, and Abhinav Shrivastava. Diff2lip: Audio conditioned diffusion models for lip-synchronization. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 5292–5302, January 2024. 11
work page 2024
-
[32]
Deconvolution and checkerboard artifacts
Augustus Odena, Vincent Dumoulin, and Chris Olah. Deconvolution and checkerboard artifacts. Distill, 2016. URLhttp://distill.pub/2016/deconv-checkerboard/
work page 2016
-
[33]
Towards universal fake image detectors that generalize across generative models
Utkarsh Ojha, Yuheng Li, and Yong Jae Lee. Towards universal fake image detectors that generalize across generative models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24480–24489, 2023
work page 2023
-
[34]
Poisson image editing.ACM Trans
Patrick Pérez, Michel Gangnet, and Andrew Blake. Poisson image editing.ACM Trans. Graph., 22(3):313–318, July 2003. ISSN 0730-0301. doi: 10.1145/882262.882269. URL https://doi.org/10.1145/882262.882269
-
[35]
Wang Qi, Yu-Ping Ruan, Yuan Zuo, and Taihao Li. Parameter-efficient tuning on layer normal- ization for pre-trained language models.arXiv preprint arXiv:2211.08682, 2022
-
[36]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning, pages 8748–8763. PmLR, 2021
work page 2021
-
[37]
Faceforensics++: Learning to detect manipulated facial images
Andreas Rossler, Davide Cozzolino, Luisa Verdoliva, Christian Riess, Justus Thies, and Matthias Nießner. Faceforensics++: Learning to detect manipulated facial images. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1–11, 2019
work page 2019
-
[38]
Junyu Shi, Minghui Li, Junguo Zuo, Zhifei Yu, Yipeng Lin, Shengshan Hu, Ziqi Zhou, Yechao Zhang, Wei Wan, Yinzhe Xu, et al. Towards real-world deepfake detection: A diverse in-the-wild dataset of forgery faces.arXiv preprint arXiv:2510.08067, 2025
-
[39]
Detecting deepfakes with self-blended images
Kaede Shiohara and Toshihiko Yamasaki. Detecting deepfakes with self-blended images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18720–18729, 2022
work page 2022
-
[40]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. DINOv3. arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Cyclical learning rates for training neural networks
Leslie N Smith. Cyclical learning rates for training neural networks. InProceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), pages 464–472. IEEE, 2017
work page 2017
-
[42]
Illumination enlightened spatial- temporal inconsistency for deepfake video detection
Kaiyue Tian, Chen Chen, Yichao Zhou, and Xiyuan Hu. Illumination enlightened spatial- temporal inconsistency for deepfake video detection. In2024 IEEE International Conference on Multimedia and Expo (ICME), pages 1–6. IEEE, 2024
work page 2024
-
[43]
Gaojian Wang, Feng Lin, Tong Wu, Zhenguang Liu, Zhongjie Ba, and Kui Ren. FSFM: A generalizable face security foundation model via self-supervised facial representation learning. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24364– 24376, 2025
work page 2025
-
[44]
Gaojian Wang, Feng Lin, Tong Wu, Zhisheng Yan, and Kui Ren. Scalable face security vision foundation model for deepfake, diffusion, and spoofing detection.arXiv preprint arXiv:2510.10663, 2025
-
[45]
arXiv preprint arXiv:2510.16320 , year=
Wenhao Wang, Longqi Cai, Taihong Xiao, Yuxiao Wang, and Ming-Hsuan Yang. Scaling laws for deepfake detection.arXiv preprint arXiv:2510.16320, 2025
-
[46]
Identity- driven multimedia forgery detection via reference assistance
Junhao Xu, Jingjing Chen, Xue Song, Feng Han, Haijun Shan, and Yu-Gang Jiang. Identity- driven multimedia forgery detection via reference assistance. InProceedings of the 32nd ACM International Conference on Multimedia, pages 3887–3896, 2024
work page 2024
-
[47]
Yuting Xu, Jian Liang, Lijun Sheng, and Xiao-Yu Zhang. Learning spatiotemporal inconsistency via thumbnail layout for face deepfake detection.International Journal of Computer Vision, 132(12):5663–5680, 2024. 12
work page 2024
-
[48]
UCF: Uncovering common features for generalizable deepfake detection
Zhiyuan Yan, Yong Zhang, Yanbo Fan, and Baoyuan Wu. UCF: Uncovering common features for generalizable deepfake detection. InProceedings of the IEEE/CVF international conference on computer vision, pages 22412–22423, 2023
work page 2023
-
[49]
Deep- fakebench: A comprehensive benchmark of deepfake detection
Zhiyuan Yan, Yong Zhang, Xinhang Yuan, Siwei Lyu, and Baoyuan Wu. Deep- fakebench: A comprehensive benchmark of deepfake detection. In A. Oh, T. Neu- mann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neu- ral Information Processing Systems, volume 36, pages 4534–4565. Curran Associates, Inc., 2023. URL https://proceedings.neurips...
work page 2023
-
[50]
Transcending forgery specificity with latent space augmentation for generalizable deepfake detection
Zhiyuan Yan, Yuhao Luo, Siwei Lyu, Qingshan Liu, and Baoyuan Wu. Transcending forgery specificity with latent space augmentation for generalizable deepfake detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8984–8994, 2024
work page 2024
-
[51]
Orthogonal subspace decomposition for generalizable AI-generated image detection
Zhiyuan Yan, Jiangming Wang, Peng Jin, Ke-Yue Zhang, Chengchun Liu, Shen Chen, Taiping Yao, Shouhong Ding, Baoyuan Wu, and Li Yuan. Orthogonal subspace decomposition for generalizable AI-generated image detection. InProceedings of the International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=GFpjO8S8Po
work page 2025
-
[52]
Exposing deep fakes using inconsistent head poses
Xin Yang, Yuezun Li, and Siwei Lyu. Exposing deep fakes using inconsistent head poses. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 8261–8265. IEEE, 2019
work page 2019
-
[53]
Deepfake detection that generalizes across benchmarks
Andrii Yermakov, Jan Cech, Jiri Matas, and Mario Fritz. Deepfake detection that generalizes across benchmarks. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), March 2026
work page 2026
-
[54]
Shengkai Zhang, Nianhong Jiao, Tian Li, Chaojie Yang, Chenhui Xue, Boya Niu, and Jun Gao. HelloMeme: Integrating spatial knitting attentions to embed high-level and fidelity-rich conditions in diffusion models.arXiv preprint arXiv:2410.22901, 2024
-
[55]
Detecting and simulating artifacts in GAN fake images
Xu Zhang, Svebor Karaman, and Shih-Fu Chang. Detecting and simulating artifacts in GAN fake images. In2019 IEEE international workshop on information forensics and security (WIFS), pages 1–6. IEEE, 2019
work page 2019
-
[56]
Longtao Zheng, Yifan Zhang, Hanzhong Guo, Jiachun Pan, Zhenxiong Tan, Jiahao Lu, Chuanxin Tang, Bo An, and Shuicheng Yan. Memo: Memory-guided diffusion for expressive talking video generation.arXiv preprint arXiv:2412.04448, 2024
-
[57]
Jiaran Zhou, Yuezun Li, Baoyuan Wu, Bin Li, Junyu Dong, et al. FreqBlender: Enhancing deep- fake detection by blending frequency knowledge.Advances in Neural Information Processing Systems, 37:44965–44988, 2024
work page 2024
-
[58]
Tianfei Zhou, Wenguan Wang, Zhiyuan Liang, and Jianbing Shen. Face forensics in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5778–5788, 2021
work page 2021
-
[59]
Xiangyu Zhu, Hao Wang, Hongyan Fei, Zhen Lei, and Stan Z Li. Face forgery detection by 3D decomposition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2929–2939, 2021. 13 Supplementary Material S1 Supplementary material overview This supplementary material provides additional experimental results and detailed d...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.