Recognition: no theorem link
CellDX AI Autopilot: Agent-Guided Training and Deployment of Pathology Classifiers
Pith reviewed 2026-05-12 04:34 UTC · model grok-4.3
The pith
CellDX AI Autopilot lets general-purpose AI agents train and deploy pathology classifiers through natural language on a pre-built dataset of 66,000 images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CellDX AI Autopilot is the first system to expose pathology-specialized agent skills and a pathology-specialized training platform to general-purpose AI agents, such as any LLM-based runtime, thereby delivering end-to-end automated model training without requiring the agent itself to be domain-specific. The platform rests on a Multiple Instance Learning framework that supports four classification strategies together with an iterative pairwise hyperparameter search that reduces tuning cost by more than 30 times relative to exhaustive search.
What carries the argument
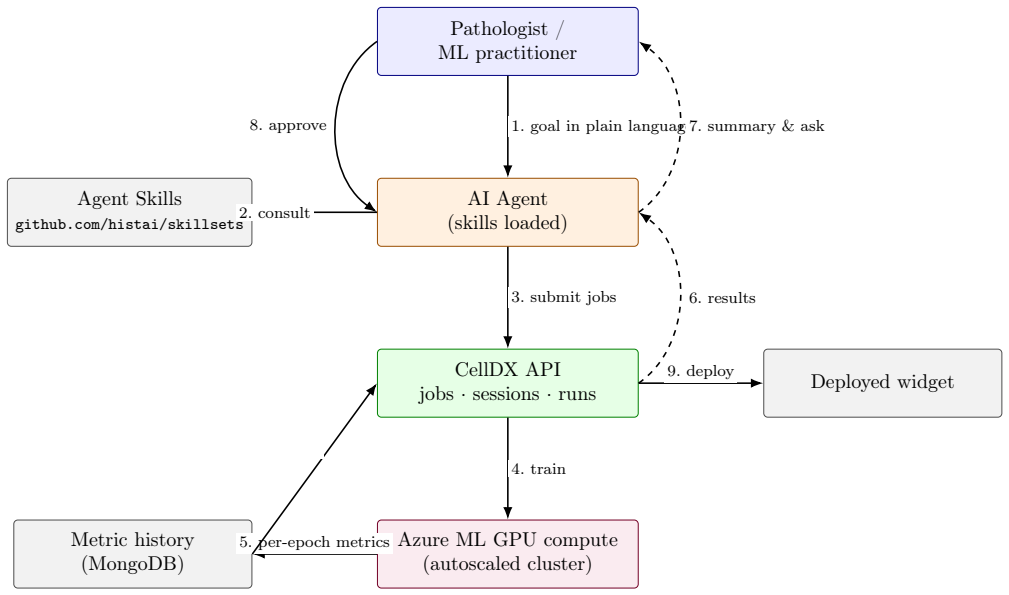
The structured agent skill architecture that guides the full workflow of dataset handling, hyperparameter tuning, model comparison, and deployment, built on top of a Multiple Instance Learning training framework with iterative pairwise search.
If this is right
- Pathologists with no ML background can create and deploy custom whole-slide classifiers through conversation alone.
- Researchers gain the ability to run many more parallel experiments at lower cost because hyperparameter tuning is reduced by over 30x.
- Four distinct classification strategies become directly comparable within a single automated run.
- Human-in-the-loop deployment steps keep final model release under pathologist control.
Where Pith is reading between the lines
- The same skill-exposure pattern could be applied to other data-intensive medical imaging domains that currently require rare expertise.
- Wider adoption of general agents for such tasks would shift the remaining bottleneck from model engineering to dataset coverage and validation standards.
- Integration with existing LLM agent runtimes would allow pathology teams to reuse familiar tools rather than adopt new specialized software.
Load-bearing premise
General-purpose AI agents can reliably and safely execute the supplied pathology-specific skills on the fixed pre-built dataset without domain-specific fine-tuning or further data.
What would settle it
A controlled test in which a standard LLM agent is given only the platform skills and asked to train a classifier on a held-out task, then measuring whether the resulting model meets accuracy thresholds and passes safety checks without additional human domain guidance.
Figures
read the original abstract
Training AI models for computational pathology currently requires access to expensive whole-slide-image datasets, GPU infrastructure, deep expertise in machine learning, and substantial engineering effort. We present CellDX AI Autopilot, a platform that lets users -- from pathologists with no ML background to ML practitioners running many parallel experiments -- train, evaluate, and deploy whole-slide image classifiers through natural language interaction with an AI agent. The platform provides a structured set of agent skills that guide the user through dataset curation, automated hyperparameter tuning, multi-strategy model comparison, and human-in-the-loop deployment, all on a pre-built dataset of over 32,000 cases and 66,000 H&E-stained whole-slide images with pre-extracted features. We describe the agent skill architecture, the underlying Multiple Instance Learning (MIL) training framework supporting four classification strategies, and an iterative pairwise hyperparameter search (grid or seeded random) that reduces tuning cost by over 30x compared to exhaustive search. CellDX AI Autopilot is, to our knowledge, the first system to expose pathology-specialized agent skills and a pathology-specialized training platform to general-purpose AI agents (e.g. any LLM-based agent runtime), delivering end-to-end automated model training without requiring the agent itself to be domain-specific. The platform addresses both the ML-expertise bottleneck that limits adoption in diagnostic pathology and the engineering bottleneck that limits how many experiments a researcher can run cost-effectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents CellDX AI Autopilot, a platform enabling natural-language interaction with general-purpose AI agents to train, evaluate, and deploy whole-slide image classifiers on a pre-built dataset of over 32,000 cases and 66,000 H&E slides with pre-extracted features. It describes a structured set of pathology-specialized agent skills for dataset curation, iterative pairwise hyperparameter search (grid or seeded random) claiming over 30x tuning-cost reduction versus exhaustive search, multi-strategy Multiple Instance Learning (MIL) training across four classification strategies, and human-in-the-loop deployment. The central claim is that this is the first system to expose such pathology-specialized skills and training platform to general LLM-based agents, achieving end-to-end automated training without requiring the agent to be domain-specific, thereby addressing ML-expertise and engineering bottlenecks in computational pathology.
Significance. If the platform's claims are validated through experiments, it could have substantial significance by lowering barriers for pathologists and researchers to develop and deploy pathology AI models, enabling more parallel experiments at reduced cost. The integration of general-purpose agents with pre-built pathology skills and a fixed large-scale dataset represents a practical engineering contribution that could accelerate adoption in diagnostic settings. The manuscript receives credit for clearly describing the skill architecture and the MIL framework supporting multiple strategies, though these strengths are currently descriptive rather than empirically demonstrated.
major comments (2)
- [Abstract] Abstract: The central claim that the system 'delivers end-to-end automated model training without requiring the agent itself to be domain-specific' is load-bearing but unsupported, as the manuscript provides no agent interaction logs, success rates, error recovery metrics, or comparative trials (general-purpose vs. domain-tuned agents) on the 32k-case dataset to demonstrate reliable execution of the full workflow including curation, tuning, MIL training, and deployment.
- [Abstract] Abstract: The stated 'over 30x' tuning-cost reduction via the iterative pairwise hyperparameter search lacks any quantitative details on measurement (e.g., wall-clock time, GPU-hours, or number of evaluations), the exhaustive-search baseline, specific results, or validation on the described dataset, rendering the efficiency claim unverified and central to the platform's value proposition.
minor comments (1)
- The manuscript would benefit from a diagram or figure illustrating the agent skill architecture, workflow, and how skills interface with general-purpose LLM runtimes to improve clarity for readers.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each of the major comments point-by-point below and will make the necessary revisions to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the system 'delivers end-to-end automated model training without requiring the agent itself to be domain-specific' is load-bearing but unsupported, as the manuscript provides no agent interaction logs, success rates, error recovery metrics, or comparative trials (general-purpose vs. domain-tuned agents) on the 32k-case dataset to demonstrate reliable execution of the full workflow including curation, tuning, MIL training, and deployment.
Authors: We agree that providing empirical evidence of the agent's performance would better support the central claim. The manuscript describes the skill architecture that allows general-purpose agents to perform the full workflow by leveraging pre-defined pathology-specialized functions, without the agent needing domain expertise itself. However, to address the lack of supporting data, we will revise the manuscript to include representative agent interaction examples, success rates from our testing on the dataset, and details on error handling mechanisms. This will be added as a new subsection in the methods or results. revision: yes
-
Referee: [Abstract] Abstract: The stated 'over 30x' tuning-cost reduction via the iterative pairwise hyperparameter search lacks any quantitative details on measurement (e.g., wall-clock time, GPU-hours, or number of evaluations), the exhaustive-search baseline, specific results, or validation on the described dataset, rendering the efficiency claim unverified and central to the platform's value proposition.
Authors: The claim is based on internal benchmarks comparing the iterative pairwise approach to exhaustive grid search. We will expand the manuscript to include the quantitative validation details, such as the specific number of hyperparameter evaluations, measured wall-clock times and GPU-hours on the 32,000-case dataset, and the exact reduction factor achieved. This will be incorporated into the results section with a dedicated table or figure. revision: yes
Circularity Check
No significant circularity; system-description paper with no derivations
full rationale
The manuscript is a platform description with no equations, no fitted parameters, no derivation chain, and no self-citations invoked as load-bearing premises. The central claim is a novelty assertion about exposing skills to general agents; it does not reduce to any input by construction or self-reference. No steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
invented entities (1)
-
CellDX AI Autopilot platform
no independent evidence
Reference graph
Works this paper leans on
-
[1]
G. Campanella, M. G. Hanna, L. Geneslaw, A. Miraflor, V. Werneck Krauss Silva, K. J. Busam, E. Brogi, V. E. Reuter, D. S. Klimstra, and T. J. Fuchs. Clinical-grade computational pathology using weakly supervised deep learning on whole slide images.Nature Medicine, 25(8):1301–1309, 2019
work page 2019
-
[2]
R. J. Chen, T. Ding, M. Y. Lu, D. F. K. Williamson, G. Jaume, A. H. Song, B. Chen, A. Zhang, D. Shao, M. Shaban, M. Williams, L. Oldenburg, L. L. Humphrey, J. N. Steinberg, M. Vanguri, T. Roesner, F. Mahmood. Towards a general-purpose foundation model for computational pathology.Nature Medicine, 30(3):850–862, 2024
work page 2024
-
[3]
R. J. Chen, C. Chen, Y. Li, T. Y. Chen, A. D. Trister, R. G. Krishnan, and F. Mahmood. Scaling vision transformers to gigapixel images via hierarchical self-supervised learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022
work page 2022
-
[4]
J. M. Dolezal, A. Srisuwananukorn, D. Karpeyev, S. Ramesh, S. Venkatesh, A. Trikalinos, A. T. Pearson. SlideFlow: deep learning for digital histopathology with real-time whole-slide visualization.BMC Bioinformatics, 25(1):134, 2024
work page 2024
- [5]
- [6]
- [7]
-
[8]
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, and W. Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Rep- resentations, 2022
work page 2022
- [9]
-
[10]
M. Ilse, J. M. Tomczak, and M. Welling. Attention-based deep multiple instance learning. In International Conference on Machine Learning, pages 2127–2136, 2018
work page 2018
-
[11]
M. Y. Lu, B. Chen, D. F. K. Williamson, R. J. Chen, M. Ikber, D. Ding, L. Jaume, I. Odintsov, A. Zhang, L. P. Le, G. Gerber, A. V. Parwani, and F. Mahmood. A visual-language foundation model for computational pathology.Nature Medicine, 30(3):863–874, 2024. 15
work page 2024
-
[12]
M. Y. Lu, D. F. K. Williamson, T. Y. Chen, R. J. Chen, M. Barbieri, and F. Mahmood. Data-efficient and weakly supervised computational pathology on whole-slide images.Nature Biomedical Engineering, 5(6):555–570, 2021
work page 2021
-
[13]
A. Myronenko, D. Yang, Y. He, and D. Xu. MONAI Auto3DSeg: Automated 3D medical image segmentation with minimal interaction. InMICCAI Workshop on Data Augmentation, Labelling, and Imperfections, 2023
work page 2023
-
[14]
GenBio AI Research Group. GenBio-PathFM: A state-of-the-art foundation model for histopathology.bioRxiv preprint, 2026.https://www.biorxiv.org/content/10.64898/2026. 03.17.712534v1
-
[15]
D.Nechaev, A.Pchelnikov, andE.Ivanova. Hibou: Afamilyoffoundationalvisiontransformers for pathology.arXiv preprint arXiv:2406.05074, 2024
-
[16]
E. Vorontsov, A. Bozkurt, A. Casson, G. Shaikovski, M. Zeber, M. Ghaleb, M. Kuber, S. Saini, S. Zheng, T. Jahromi, T. Tong, and S. Klimstra. Virchow: A million-slide digital pathology foundation model.Nature Medicine, 2024
work page 2024
-
[17]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Q.Wu, G.Banber, Y.Zhang, Y.Wu, B.Li, E.Zhu, H.Wang, andC.Wang. AutoGen: Enabling next-gen LLM applications via multi-agent conversation.arXiv preprint arXiv:2308.08155, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
H. Xu, S. Usuyama, J. Bagga, S. Zhang, R. Rao, T. Naumann, C. Wong, Z. Gero, J. González, Y. Gu, Y. Hou, V. Shcherbina, A. Lozano, M. Mahesar, N. Narasimhan, X. Wang, and H. Poon. A whole-slide foundation model for digital pathology from real-world data.Nature, 630:181– 188, 2024. 16
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.