Recognition: unknown
EGL-SCA: Structural Credit Assignment for Co-Evolving Instructions and Tools in Graph Reasoning Agents
Pith reviewed 2026-05-12 04:12 UTC · model grok-4.3
The pith
Structural credit assignment routes agent failures to either instruction updates or tool synthesis in graph reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
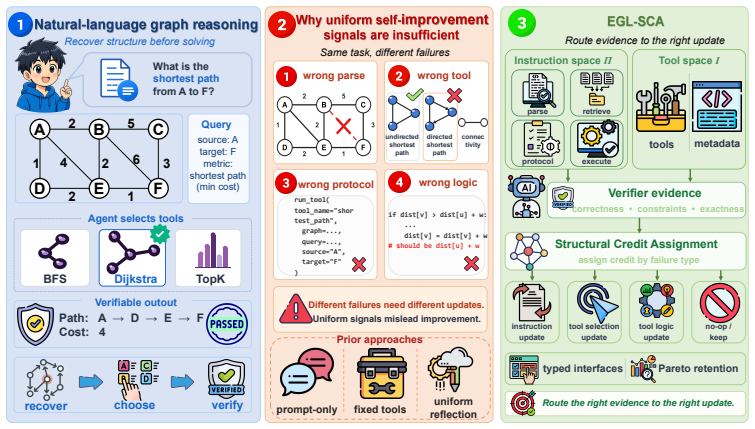
Our central mechanism is structural credit assignment, which maps trajectory evidence to conditional updates, precisely routing failures to either prompt optimization or tool synthesis and repair. This verifier-centric dual-space framework models a graph reasoning agent using two collaborative components: an instruction-side policy space for reasoning strategies, and a tool-side program space for executable algorithmic tools. A training distribution stratified by task family combined with Pareto-style retention balances success, generality, and parsimony.
What carries the argument
Structural credit assignment, which maps trajectory evidence to conditional updates that route failures between the instruction policy space and the tool program space.
If this is right
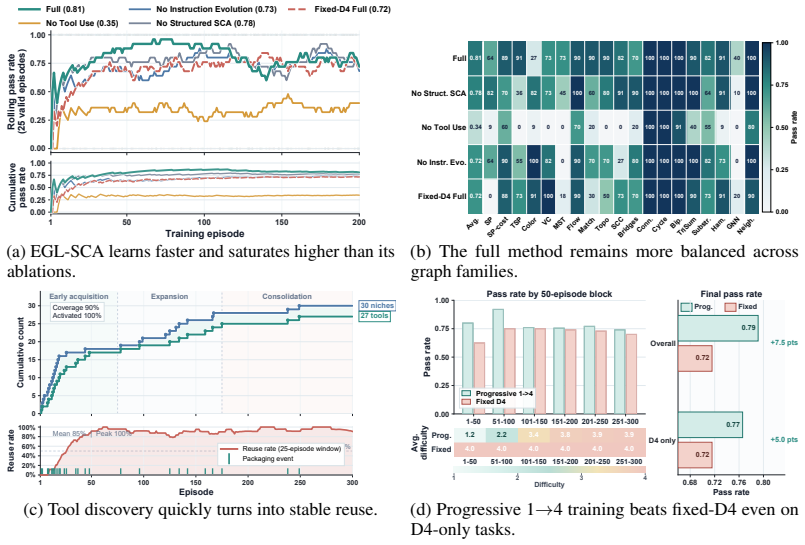
- Co-evolving instructions and tools reaches a 92.0 percent average success rate across four graph reasoning benchmarks.
- The dual-space model with structural routing outperforms both pure-prompting and fixed-toolbox baselines.
- Stratified training by task family supplies sufficient signals for adaptation in both spaces.
- Pareto-style retention keeps the evolved instructions and tools general and parsimonious.
Where Pith is reading between the lines
- Similar credit-assignment logic could extend to agents that must jointly manage language plans and external APIs in domains beyond graphs.
- Dynamic tool synthesis might eventually reduce the amount of hand-crafted code needed for new reasoning tasks.
- If the verifier is replaced by weaker or noisy feedback, the same routing mechanism could be tested for robustness in open-ended settings.
Load-bearing premise
Trajectory evidence can be mapped unambiguously to either the instruction space or the tool space without significant overlap or ambiguity, and the external verifier supplies clean enough signals for reliable credit assignment.
What would settle it
Run the system on a set of deliberately ambiguous failures where the error could plausibly arise from either instructions or tools, then measure whether success rates improve or degrade compared with random routing.
Figures

read the original abstract
Graph reasoning agents operating from natural-language inputs must solve a coupled problem: they must reconstruct a structured graph instance from text, decide whether existing computational assets are sufficient, interact with tools under a strict execution protocol, and satisfy an external verifier that checks structured correctness rather than textual plausibility. Existing approaches usually improve either the instruction side or the tool side in isolation, which leaves unclear what should be updated after failure. We propose EGL-SCA, a verifier-centric dual-space framework that models a graph reasoning agent using two collaborative components: an instruction-side policy space for reasoning strategies, and a tool-side program space for executable algorithmic tools. Our central mechanism is structural credit assignment, which maps trajectory evidence to conditional updates, precisely routing failures to either prompt optimization or tool synthesis and repair. To provide sufficient learning signals for dual-space adaptation, we introduce a training distribution stratified by task family, coupled with a Pareto-style retention strategy to balance success, generality, and parsimony. Experiments on four graph reasoning benchmarks show that EGL-SCA achieves a state-of-the-art 92.0\% average success rate. By effectively co-evolving instructions and tools, our framework significantly outperforms both pure-prompting and fixed-toolbox baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EGL-SCA, a verifier-centric dual-space framework for graph reasoning agents that must reconstruct graphs from text, interact with tools, and satisfy an external verifier. It models the agent with an instruction-side policy space for reasoning strategies and a tool-side program space for executable tools. The central mechanism is structural credit assignment, which maps trajectory evidence (graph reconstruction, tool execution, verifier feedback) to conditional updates that route failures to either prompt optimization or tool synthesis/repair. A stratified training distribution by task family and a Pareto-style retention strategy are used to generate learning signals. Experiments on four graph reasoning benchmarks report a state-of-the-art 92.0% average success rate, outperforming pure-prompting and fixed-toolbox baselines.
Significance. If the structural credit assignment reliably disambiguates failures between the two spaces, the work offers a principled approach to co-evolving instructions and tools in agentic systems for structured reasoning tasks, moving beyond isolated improvements in prompting or tool use. The verifier-centric design and emphasis on separable update routing could influence future agent architectures that handle coupled instruction-tool failures.
major comments (1)
- [Central mechanism (structural credit assignment)] Central mechanism section (structural credit assignment description): the claim that trajectory evidence can be mapped to 'precisely routing failures to either prompt optimization or tool synthesis and repair' is load-bearing for the co-evolution argument. In graph reasoning, errors frequently arise from tight coupling (suboptimal strategy producing tool inputs that expose latent bugs, or vice versa). The manuscript must supply the explicit mapping rules, decision procedure, or pseudocode for this routing, plus concrete examples showing how mixed-failure trajectories are disambiguated without significant overlap or ambiguity; without this, the 92% SOTA result cannot be confidently attributed to the proposed mechanism rather than post-hoc tuning or clean signals.
minor comments (2)
- [Experiments] Experimental results section: the reported 92.0% average success rate should be accompanied by per-benchmark breakdowns, standard deviations or error bars across runs, number of trials, and ablation studies that isolate the contribution of structural credit assignment from the stratified training distribution and Pareto retention strategy.
- [Method / Notation] The abstract and method sections use terms such as 'trajectory evidence' and 'conditional updates' without precise operational definitions or pseudocode; adding these would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for identifying the need for greater clarity on the structural credit assignment mechanism. We address the major comment below and commit to revisions that will strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Central mechanism (structural credit assignment)] Central mechanism section (structural credit assignment description): the claim that trajectory evidence can be mapped to 'precisely routing failures to either prompt optimization or tool synthesis and repair' is load-bearing for the co-evolution argument. In graph reasoning, errors frequently arise from tight coupling (suboptimal strategy producing tool inputs that expose latent bugs, or vice versa). The manuscript must supply the explicit mapping rules, decision procedure, or pseudocode for this routing, plus concrete examples showing how mixed-failure trajectories are disambiguated without significant overlap or ambiguity; without this, the 92% SOTA result cannot be confidently attributed to the proposed mechanism rather than post-hoc tuning or clean signals.
Authors: We agree that the load-bearing claim requires explicit support to substantiate the co-evolution argument, especially given the risk of coupled failures in graph reasoning. The current manuscript (Section 3.2) outlines the high-level mapping from trajectory evidence—graph reconstruction fidelity, tool execution logs, and verifier feedback—to conditional updates, but does not include the full decision procedure or examples. In revision we will add a dedicated subsection with pseudocode for the routing logic and two worked examples drawn from the experimental trajectories. The procedure first extracts an evidence vector from the verifier (structured error codes) and execution trace (success/failure flags plus input-output mismatches). It then applies a priority rule set: (1) if verifier flags indicate strategy-level structural errors (e.g., incorrect node ordering despite valid tool outputs), route exclusively to prompt optimization; (2) if execution failures or latent tool bugs are isolated (e.g., runtime exceptions with sound strategy), route to tool synthesis/repair; (3) for mixed signals, a tie-breaker examines the temporal order of first failure and assigns to the earlier component unless the verifier confidence exceeds a threshold, in which case both spaces receive targeted updates. This rule-based classifier is deterministic given the evidence and avoids post-hoc tuning. The added examples will illustrate one mixed-failure case routed to prompt optimization and one to tool repair, showing how overlap is resolved. These changes will allow readers to directly evaluate attribution of the reported performance gains. revision: yes
Circularity Check
No significant circularity; central claim is empirical validation on external benchmarks
full rationale
The paper introduces EGL-SCA as a verifier-centric dual-space framework whose central mechanism is structural credit assignment for routing trajectory evidence to either instruction or tool updates. The strongest claim is the 92.0% average success rate on four graph reasoning benchmarks, presented explicitly as an experimental result rather than a mathematical prediction or first-principles derivation. No equations, fitted parameters, or self-referential definitions appear in the provided abstract and text that would make any claimed quantity equivalent to its inputs by construction. No self-citations, uniqueness theorems, or ansatzes are quoted that load-bear on the result. The mapping procedure is described as a proposed design choice whose effectiveness is tested externally, satisfying the condition for a self-contained empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco JR Ruiz, Abbas Mehrabian, et al. Alphaevolve: A coding agent for scientific and algorithmic discovery.arXiv preprint arXiv:2506.13131, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Aflow: Automating agentic workflow generation
Jiayi Zhang, Jinyu Xiang, Zhaoyang Yu, Fengwei Teng, Xiong-Hui Chen, Jiaqi Chen, Mingchen Zhuge, Xin Cheng, Sirui Hong, Jinlin Wang, et al. Aflow: Automating agentic workflow generation. InThe Thirteenth International Conference on Learning Representations, 2024
work page 2024
-
[3]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020
work page 1901
-
[4]
Graphinsight: Unlocking insights in large language models for graph structure understanding
Yukun Cao, Shuo Han, Zengyi Gao, Zezhong Ding, Xike Xie, and S Kevin Zhou. Graphinsight: Unlocking insights in large language models for graph structure understanding. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12096–12134, 2025
work page 2025
-
[5]
Graphwiz: An instruction-following language model for graph computational problems
Nuo Chen, Yuhan Li, Jianheng Tang, and Jia Li. Graphwiz: An instruction-following language model for graph computational problems. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 353–364, 2024
work page 2024
-
[6]
Promptbreeder: Self-referential self-improvement via prompt evolution,
Chrisantha Fernando, Dylan Banarse, Henryk Michalewski, Simon Osindero, and Tim Rocktäschel. Promptbreeder: Self-referential self-improvement via prompt evolution.arXiv preprint arXiv:2309.16797, 2023
-
[7]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, et al. Gepa: Reflective prompt evolution can outperform reinforcement learning.arXiv preprint arXiv:2507.19457, 2025
work page internal anchor Pith review arXiv 2025
-
[8]
Graph meets llms: Towards large graph models.arXiv preprint arXiv:2308.14522, 2023
Ziwei Zhang, Haoyang Li, Zeyang Zhang, Yijian Qin, Xin Wang, and Wenwu Zhu. Graph meets llms: Towards large graph models.arXiv preprint arXiv:2308.14522, 2023
-
[9]
Jiawei Zhang. Graph-toolformer: To empower llms with graph reasoning ability via prompt augmented by chatgpt.arXiv preprint arXiv:2304.11116, 2023
-
[10]
Graphinstruct: Empowering large language models with graph understanding and reasoning capability
Zihan Luo, Xiran Song, Hong Huang, Jianxun Lian, Chenhao Zhang, Jinqi Jiang, Xing Xie, and Hai Jin. Graphinstruct: Empowering large language models with graph understanding and reasoning capability. arXiv preprint arXiv:2403.04483, 2024
-
[11]
Optimizing instructions and demonstrations for multi-stage language model programs
Krista Opsahl-Ong, Michael J Ryan, Josh Purtell, David Broman, Christopher Potts, Matei Zaharia, and Omar Khattab. Optimizing instructions and demonstrations for multi-stage language model programs. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 9340–9366, 2024
work page 2024
-
[12]
Art: Automatic multi-step reasoning and tool-use for large language models
Bhargavi Paranjape, Scott Lundberg, Sameer Singh, Hannaneh Hajishirzi, Luke Zettlemoyer, and Marco Tulio Ribeiro. Art: Automatic multi-step reasoning and tool-use for large language models. arXiv preprint arXiv:2303.09014, 2023
-
[13]
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M Pawan Kumar, Emilien Dupont, Francisco JR Ruiz, Jordan S Ellenberg, Pengming Wang, Omar Fawzi, et al. Mathematical discoveries from program search with large language models.Nature, 625(7995):468–475, 2024
work page 2024
-
[14]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36:68539–68551, 2023
work page 2023
-
[15]
Agentsquare: Automatic llm agent search in modular design space
Yu Shang, Yu Li, Keyu Zhao, Likai Ma, Jiahe Liu, Fengli Xu, and Yong Li. Agentsquare: Automatic llm agent search in modular design space. InThe Thirteenth International Conference on Learning Representations, 2024. 10
work page 2024
-
[16]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
work page 2023
-
[17]
Grapharena: Evaluating and exploring large language models on graph computation,
Jianheng Tang, Qifan Zhang, Yuhan Li, Nuo Chen, and Jia Li. Grapharena: Evaluating and exploring large language models on graph computation.arXiv preprint arXiv:2407.00379, 2024
-
[18]
Heng Wang, Shangbin Feng, Tianxing He, Zhaoxuan Tan, Xiaochuang Han, and Yulia Tsvetkov. Can language models solve graph problems in natural language?Advances in Neural Information Processing Systems, 36:30840–30861, 2023
work page 2023
-
[19]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
work page 2022
-
[20]
Hao Xu, Xiangru Jian, Xinjian Zhao, Wei Pang, Chao Zhang, Suyuchen Wang, Qixin Zhang, Zhengyuan Dong, Joao Monteiro, Bang Liu, et al. Graphomni: A comprehensive and extendable benchmark framework for large language models on graph-theoretic tasks.arXiv preprint arXiv:2504.12764, 2025
-
[21]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
Gracore: Benchmarking graph comprehension and complex reasoning in large language models
Zike Yuan, Ming Liu, Hui Wang, and Bing Qin. Gracore: Benchmarking graph comprehension and complex reasoning in large language models. InProceedings of the 31st International Conference on Computational Linguistics, pages 7925–7948, 2025
work page 2025
-
[23]
Ma-gts: A multi-agent framework for solving complex graph problems in real-world applications
Zike Yuan, Ming Liu, Hui Wang, and Bing Qin. Ma-gts: A multi-agent framework for solving complex graph problems in real-world applications. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 19297–19315, 2025
work page 2025
-
[24]
Expel: Llm agents are experiential learners
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. Expel: Llm agents are experiential learners. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19632–19642, 2024
work page 2024
-
[25]
Pal: Program-aided language models
Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. Pal: Program-aided language models. InInternational conference on machine learning, pages 10764–10799. PMLR, 2023
work page 2023
-
[26]
Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W Cohen. Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks.arXiv preprint arXiv:2211.12588, 2022
work page internal anchor Pith review arXiv 2022
-
[27]
Kalyanmoy Deb, Amrit Pratap, Sameer Agarwal, and TAMT Meyarivan. A fast and elitist multiobjective genetic algorithm: Nsga-ii.IEEE transactions on evolutionary computation, 6(2):182–197, 2002. A Reproducibility and Implementation Details Model and decoding.All reported benchmark results use the same underlying GPT-5.4-nano model family and the same verifi...
work page 2002
-
[28]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.