Recognition: 3 theorem links
· Lean TheoremAgentGR: Semantic-aware Agentic Group Decision-Making Simulator for Group Recommendation
Pith reviewed 2026-05-12 04:29 UTC · model grok-4.3
The pith
AgentGR uses LLM-driven agents to simulate group decision dynamics including leadership and influence for more accurate recommendations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
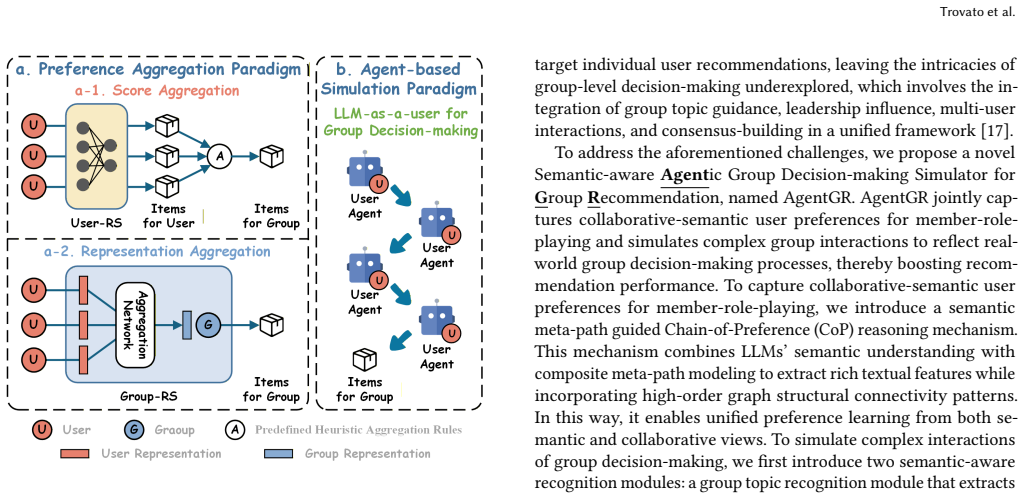
AgentGR is a semantic-aware agentic simulator that first constructs richer user preference profiles by chaining high-order collaborative filtering signals with textual semantics, then explicitly detects group topic and leadership to drive two forms of multi-agent simulation: an efficient static workflow and a precise dynamic dialogue. These steps together generate group recommendations that reflect real-world decision processes rather than mere preference averaging.
What carries the argument
Semantic meta-path guided chain-of-preference reasoning that feeds into multi-agent simulation strategies (static workflow for efficiency and dynamic dialogue for precision) to model topic recognition, leadership, and interaction dynamics.
If this is right
- Group recommendations will incorporate explicit modeling of intra-group influence instead of treating all members equally.
- Both recommendation precision and the realism of simulated decision processes improve on standard evaluation datasets.
- Platforms can choose between a fast static simulation mode and a slower but more detailed dialogue mode depending on latency needs.
- The approach supplies an interpretable trace of how leadership and topic recognition shaped the final group choice.
Where Pith is reading between the lines
- The same agentic simulation pattern could be tested in other multi-user settings such as team-based content curation or family media selection.
- If the simulation proves stable, it opens a route to online systems that let groups iteratively refine recommendations through continued agent dialogue.
- The method suggests that textual semantics can serve as a bridge between individual history and collective choice without requiring new data collection.
Load-bearing premise
LLM agents can accurately reproduce the complex, real-world social influences such as leadership and persuasion that shape how actual groups reach decisions.
What would settle it
Running the same two real-world datasets with AgentGR and finding that its accuracy metrics and decision-simulation fidelity do not exceed those of existing aggregation-based baselines.
Figures








read the original abstract
Group Recommendation (GR) aims to suggest items to a group of users, which has become a critical component of modern social platforms. Existing GR methods focus on aggregating individual user preferences with advanced neural networks to infer group preferences. Despite effectiveness, they essentially treat group preference learning as a simple preference aggregation process, failing to capture the complex dynamics of real-world group decision-making. To address these limitations, we propose AgentGR, a novel Semantic-aware Agentic Group Decision-Making Simulator for Group Recommendations, inspired by the semantic reasoning and human behavior simulation capabilities of LLM-driven agents. It aims to jointly capture collaborative-semantic user preferences for member-role-playing and simulate dynamic group interactions to reflect real-world group decision-making processes, thereby boosting recommendation performance. Specifically, to capture collaborative-semantic user preferences, we introduce a semantic meta-path guided chain-of-preference reasoning mechanism that integrates high-order collaborative filtering signals and textual semantics to improve user preference profiles. To model the complex dynamics of group decision-making, we first recognize group topic and leadership to explicitly model the influencing factors within the group decision processes. Building on these, we simulate group-level decision dynamics via two multi-agent simulation strategies for recommendations: a static workflow-based strategy for efficiency and a dynamic dialogue-based strategy for precision. Extensive experiments on two real-world datasets show that AgentGR significantly outperforms state-of-the-art baselines in both recommendation accuracy and group decision simulation, highlighting its potential for real-world GR applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AgentGR, a semantic-aware agentic simulator for group recommendation. It uses LLM-driven agents with a semantic meta-path guided chain-of-preference reasoning mechanism to capture collaborative-semantic user preferences, recognizes group topics and leadership to model influence factors, and employs two multi-agent strategies (static workflow-based for efficiency and dynamic dialogue-based for precision) to simulate group decision dynamics. The central claim is that this approach significantly outperforms state-of-the-art baselines on two real-world datasets in both recommendation accuracy and the fidelity of group decision simulation.
Significance. If the simulation component is shown to be grounded, this work could meaningfully advance group recommendation by shifting from preference aggregation to explicit modeling of interaction dynamics such as leadership and influence. The integration of semantic meta-path reasoning with multi-agent LLM strategies represents a novel direction that may improve applicability to social platforms, provided the claimed realism is substantiated beyond internal consistency.
major comments (2)
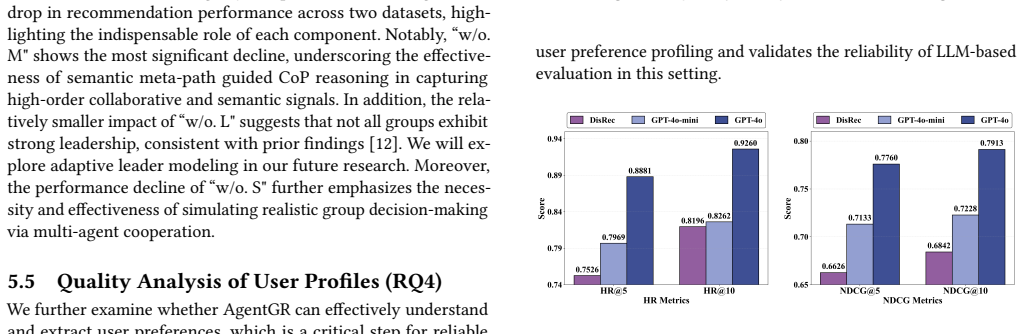
- [Experimental evaluation] Experimental evaluation section: the claim of significant outperformance in 'group decision simulation' is load-bearing for the paper's positioning against aggregation baselines, yet no direct calibration is reported against observed human group outcomes (e.g., decision logs, influence traces, or user studies from the datasets). Without such grounding, superior metrics may reflect prompted LLM consistency rather than fidelity to real-world processes.
- [Method (multi-agent simulation strategies)] Dynamic dialogue-based strategy description: leadership and influence are recognized but the quantitative modeling and evaluation of how these factors alter simulated decisions (versus static workflow) is not detailed with ablation results or comparison to human data, weakening support for the claim that the approach 'reflects real-world group decision-making processes'.
minor comments (2)
- [Abstract] The abstract states 'extensive experiments' but omits dataset names, key metrics, and baseline list; adding these would improve immediate readability.
- [Method (semantic meta-path)] Notation for the semantic meta-path guided reasoning could benefit from a concrete example or diagram to clarify integration of high-order CF signals and textual semantics.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript. We appreciate the referee's emphasis on the need for stronger grounding of the simulation claims. We address each major comment below, clarifying our evaluation approach and outlining planned revisions.
read point-by-point responses
-
Referee: [Experimental evaluation] Experimental evaluation section: the claim of significant outperformance in 'group decision simulation' is load-bearing for the paper's positioning against aggregation baselines, yet no direct calibration is reported against observed human group outcomes (e.g., decision logs, influence traces, or user studies from the datasets). Without such grounding, superior metrics may reflect prompted LLM consistency rather than fidelity to real-world processes.
Authors: We acknowledge that direct calibration to human group decision logs, influence traces, or dedicated user studies would provide stronger substantiation for simulation fidelity. The two real-world datasets used do not contain such granular interaction annotations or accompanying studies. Our current evaluation of group decision simulation relies on downstream recommendation accuracy gains and internal consistency of the multi-agent outputs. In the revised manuscript, we will add an explicit limitations subsection discussing the proxy nature of this evaluation and the absence of direct human grounding. revision: partial
-
Referee: [Method (multi-agent simulation strategies)] Dynamic dialogue-based strategy description: leadership and influence are recognized but the quantitative modeling and evaluation of how these factors alter simulated decisions (versus static workflow) is not detailed with ablation results or comparison to human data, weakening support for the claim that the approach 'reflects real-world group decision-making processes'.
Authors: We will revise the method and experimental sections to include quantitative ablations isolating the impact of leadership and influence recognition within the dynamic dialogue strategy. These will compare variants with and without explicit leadership modeling, reporting differences in simulated decision trajectories and final recommendation metrics relative to the static workflow. This will provide concrete evidence on how these factors influence outcomes. As noted in response to the first comment, direct comparisons to human data are constrained by dataset limitations, which we will address in the added limitations discussion. revision: yes
Circularity Check
No circularity: AgentGR is a descriptive system proposal relying on external LLM capabilities.
full rationale
The paper describes an architecture for group recommendation via semantic meta-path reasoning, topic/leadership recognition, and two multi-agent LLM simulation strategies. No equations, fitted parameters, or self-citations appear in the provided text that would reduce any claimed result to its own inputs by construction. The central claims rest on the external capabilities of LLMs and the proposed mechanisms rather than internal redefinitions or renamings, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sihem Amer-Yahia, Senjuti Basu Roy, Ashish Chawlat, Gautam Das, and Cong Yu. 2009. Group recommendation: Semantics and efficiency.Proceedings of the VLDB Endowment2, 1 (2009), 754–765
work page 2009
-
[2]
Linas Baltrunas, Tadas Makcinskas, and Francesco Ricci. 2010. Group recom- mendations with rank aggregation and collaborative filtering. InProceedings of the fourth ACM conference on Recommender systems. 119–126
work page 2010
-
[3]
Keqin Bao, Jizhi Zhang, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He. 2023. Tallrec: An effective and efficient tuning framework to align large language model with recommendation. InProceedings of the 17th ACM conference on recommender systems. 1007–1014
work page 2023
-
[4]
Ludovico Boratto and Salvatore Carta. 2011. State-of-the-art in group recommen- dation and new approaches for automatic identification of groups. InInformation retrieval and mining in distributed environments. Springer, 1–20
work page 2011
-
[5]
Shihao Cai, Jizhi Zhang, Keqin Bao, Chongming Gao, Qifan Wang, Fuli Feng, and Xiangnan He. 2025. Agentic feedback loop modeling improves recommendation and user simulation. InProceedings of the 48th International ACM SIGIR conference on Research and Development in Information Retrieval. 2235–2244
work page 2025
-
[6]
Da Cao, Xiangnan He, Lianhai Miao, Yahui An, Chao Yang, and Richang Hong
-
[7]
Attentive Group Recommendation. InThe 41st International ACM SIGIR Conference on Research & Development in Information Retrieval(Ann Arbor, MI, USA)(SIGIR ’18). Association for Computing Machinery, New York, NY, USA, 645–654. doi:10.1145/3209978.3209998
-
[8]
Da Cao, Xiangnan He, Lianhai Miao, Guangyi Xiao, Hao Chen, and Jiao Xu
-
[9]
Social-enhanced attentive group recommendation.IEEE Transactions on Knowledge and Data Engineering33, 3 (2019), 1195–1209
work page 2019
-
[10]
Tong Chen, Hongzhi Yin, Jing Long, Quoc Viet Hung Nguyen, Yang Wang, and Meng Wang. 2022. Thinking inside the box: learning hypercube representations for group recommendation. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1664–1673
work page 2022
-
[11]
Zhiyi Deng, Changyu Li, Shujin Liu, Waqar Ali, and Jie Shao. 2021. Knowledge- aware group representation learning for group recommendation. In2021 IEEE 37th International Conference on Data Engineering (ICDE). IEEE, 1571–1582
work page 2021
-
[12]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 4171–4186
work page 2019
- [13]
-
[14]
Dingyi Gan, Min Gao, Wentao Li, Zongwei Wang, Linxin Guo, Feng Jiang, and Yuqi Song. 2025. LARGE: A leadership perception framework for group recom- mendation.Expert Systems with Applications260 (2025), 125416
work page 2025
-
[15]
Chongming Gao, Ruijun Chen, Shuai Yuan, Kexin Huang, Yuanqing Yu, and Xiangnan He. 2025. Sprec: Self-play to debias llm-based recommendation. In Proceedings of the ACM on Web Conference 2025. 5075–5084
work page 2025
-
[16]
Jibing Gong, Shen Wang, Jinlong Wang, Wenzheng Feng, Hao Peng, Jie Tang, and Philip S Yu. 2020. Attentional graph convolutional networks for knowledge concept recommendation in moocs in a heterogeneous view. InProceedings of the 43rd international ACM SIGIR conference on research and development in information retrieval. 79–88
work page 2020
-
[17]
Lei Guo, Hongzhi Yin, Tong Chen, Xiangliang Zhang, and Kai Zheng. 2021. Hierarchical hyperedge embedding-based representation learning for group recommendation.ACM Transactions on Information Systems (TOIS)40, 1 (2021), 1–27
work page 2021
-
[18]
Zhixiang He, Chi-Yin Chow, and Jia-Dong Zhang. 2020. GAME: Learning graph- ical and attentive multi-view embeddings for occasional group recommendation. InProceedings of the 43rd international ACM SIGIR conference on research and development in information retrieval. 649–658
work page 2020
- [19]
-
[20]
Renqi Jia, Xiaofei Zhou, Linhua Dong, and Shirui Pan. 2021. Hypergraph convo- lutional network for group recommendation. In2021 ieee international conference on data mining (icdm). IEEE, 260–269
work page 2021
-
[21]
Chumeng Jiang, Jiayin Wang, Weizhi Ma, Charles LA Clarke, Shuai Wang, Chuhan Wu, and Min Zhang. 2025. Beyond Utility: Evaluating LLM as Rec- ommender. InProceedings of the ACM on Web Conference 2025. 3850–3862
work page 2025
-
[22]
Chae-Hyun Kim, Yoon-Ryung Choi, Jin-Duk Park, and Won-Yong Shin. 2025. Leveraging member-group relations via multi-view graph filtering for effective group recommendation. InCompanion Proceedings of the ACM on Web Conference
work page 2025
-
[23]
Yunshan Ma, Yingzhi He, An Zhang, Xiang Wang, and Tat-Seng Chua. 2022. CrossCBR: cross-view contrastive learning for bundle recommendation. InPro- ceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining. 1233–1241
work page 2022
-
[24]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback.Advances in neural information processing systems35 (2022), 27730–27744
work page 2022
-
[25]
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. 2023. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th annual acm symposium on user interface software and technology. 1–22
work page 2023
-
[26]
Xubin Ren, Wei Wei, Lianghao Xia, Lixin Su, Suqi Cheng, Junfeng Wang, Dawei Yin, and Chao Huang. 2024. Representation learning with large language models for recommendation. InProceedings of the ACM web conference 2024. 3464–3475
work page 2024
-
[27]
Aravind Sankar, Yanhong Wu, Yuhang Wu, Wei Zhang, Hao Yang, and Hari Sundaram. 2020. Groupim: A mutual information maximization framework for neural group recommendation. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. 1279–1288
work page 2020
-
[28]
Antonela Tommasel. 2024. Fairness Matters: A look at LLM-generated group recommendations. InProceedings of the 18th ACM Conference on Recommender Systems. 993–998
work page 2024
-
[29]
Lucas Vinh Tran, Tuan-Anh Nguyen Pham, Yi Tay, Yiding Liu, Gao Cong, and Xiaoli Li. 2019. Interact and decide: Medley of sub-attention networks for effective group recommendation. InProceedings of the 42nd International ACM SIGIR conference on research and development in information retrieval. 255–264
work page 2019
- [30]
-
[31]
Shuyao Wang, Zhi Zheng, Yongduo Sui, and Hui Xiong. 2025. Unleashing the Power of Large Language Model for Denoising Recommendation. InProceedings of the ACM on Web Conference 2025. 252–263
work page 2025
-
[32]
Zekai Wang, Hongzhi Liu, Yingpeng Du, Zhonghai Wu, and Xing Zhang. 2019. Unified embedding model over heterogeneous information network for person- alized recommendation. InProceedings of the 28th international joint conference on artificial intelligence. 3813–3819
work page 2019
-
[33]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reason- ing in large language models.Advances in neural information processing systems 35 (2022), 24824–24837
work page 2022
-
[34]
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. 2024. Autogen: Enabling next-gen LLM applications via multi-agent conversations. InFirst Conference on Language Modeling
work page 2024
-
[35]
Tong Wu, Yanpeng Zhao, and Zilong Zheng. 2024. An efficient recipe for long context extension via middle-focused positional encoding.Advances in Neural Information Processing Systems37 (2024), 56349–56373
work page 2024
-
[36]
Xixi Wu, Yun Xiong, Yao Zhang, Yizhu Jiao, Jiawei Zhang, Yangyong Zhu, and Philip S Yu. 2023. Consrec: Learning consensus behind interactions for group recommendation. InProceedings of the acm web conference 2023. 240–250
work page 2023
-
[37]
Jinfeng Xu, Zheyu Chen, Jinze Li, Shuo Yang, Hewei Wang, and Edith CH Ngai
-
[38]
InProceedings of the 33rd ACM International Conference on Information and Knowledge Management
Aligngroup: Learning and aligning group consensus with member prefer- ences for group recommendation. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management. 2682–2691
-
[39]
Guangze Ye, Wen Wu, Guoqing Wang, Xi Chen, Hong Zheng, and Liang He
-
[40]
Disentangled Modeling of Preferences and Social Influence for Group Recommendation.Proceedings of the AAAI Conference on Artificial Intelligence 39, 12 (April 2025), 13052–13060. doi:10.1609/aaai.v39i12.33424
-
[41]
Hongzhi Yin, Qinyong Wang, Kai Zheng, Zhixu Li, Jiali Yang, and Xiaofang Zhou. 2019. Social influence-based group representation learning for group AgentGR: Semantic-aware Agentic Group Decision-Making Simulator for Group Recommendation recommendation. In2019 IEEE 35th International Conference on Data Engineering (ICDE). IEEE, 566–577
work page 2019
-
[42]
Junjie Zhang, Yupeng Hou, Ruobing Xie, Wenqi Sun, Julian McAuley, Wayne Xin Zhao, Leyu Lin, and Ji-Rong Wen. 2024. Agentcf: Collaborative learning with autonomous language agents for recommender systems. InProceedings of the ACM Web Conference 2024. 3679–3689
work page 2024
-
[43]
Xiaoyu Zhang, Yishan Li, Jiayin Wang, Bowen Sun, Weizhi Ma, Peijie Sun, and Min Zhang. 2024. Large language models as evaluators for recommendation explanations. InProceedings of the 18th ACM Conference on Recommender Systems. 33–42
work page 2024
-
[44]
Yang Zhang, Fuli Feng, Jizhi Zhang, Keqin Bao, Qifan Wang, and Xiangnan He
-
[45]
Collm: Integrating collaborative embeddings into large language models for recommendation.IEEE Transactions on Knowledge and Data Engineering (2025)
work page 2025
-
[46]
Zijian Zhang, Shuchang Liu, Ziru Liu, Rui Zhong, Qingpeng Cai, Xiangyu Zhao, Chunxu Zhang, Qidong Liu, and Peng Jiang. 2025. Llm-powered user simulator for recommender system. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 13339–13347
work page 2025
-
[47]
Yangtao Zhou, Hua Chu, Yongxiang Chen, Ziwen Wang, Jiacheng Liu, Jianan Li, Yueying Feng, Xiangming Li, Zihan Han, and Qingshan Li. [n. d.]. Knowledge Starts with Practice: Knowledge-Aware Exercise Generative Recommendation with Adaptive Multi-Agent Cooperation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[48]
Yangtao Zhou, Hua Chu, Qingshan Li, Jianan Li, Shuai Zhang, Feifei Zhu, Jingzhao Hu, Luqiao Wang, and Wanqiang Yang. 2025. Dual-tower model with semantic perception and timespan-coupled hypergraph for next-basket recom- mendation.Neural Networks184 (2025), 107001
work page 2025
-
[49]
Yangtao Zhou, Qingshan Li, Hua Chu, Jianan Li, Biaobiao Wei, Shuai Zhang, and Jialong Han. 2025. Spatiotemporal-view member preference contrastive representation learning for group recommendation.Machine Learning114, 3 (2025), 79
work page 2025
-
[50]
Yaochen Zhu, Liang Wu, Qi Guo, Liangjie Hong, and Jundong Li. 2024. Collab- orative large language model for recommender systems. InProceedings of the ACM Web Conference 2024. 3162–3172. Received 20 February 2007; revised 12 March 2009; accepted 5 June 2009
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.