Recognition: 2 theorem links
· Lean TheoremRegret Analysis of Guided Diffusion for Black-Box Optimization over Structured Inputs
Pith reviewed 2026-05-12 03:36 UTC · model grok-4.3
The pith
Guided diffusion black-box optimization admits expected simple-regret certificates based on mass lift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We develop a first certificate-based expected simple-regret framework for guided-diffusion BO that avoids maximum-information-gain bounds, RKHS assumptions, and exact acquisition maximization. The central quantity in our analysis is mass lift: the increase in probability mass assigned to near-optimal designs relative to the pretrained generator. This view explains how exponential-looking finite-budget convergence and polynomial acceleration can all arise from the same mechanism. We also give practical diagnostics for estimating search exponents from finite candidate pools and a proposal-corrected resampling construction that provides a fully certified sampler instance.
What carries the argument
mass lift, defined as the increase in probability mass assigned to near-optimal designs relative to the pretrained generator, which serves as the basis for regret certificates
If this is right
- Exponential-looking finite-budget convergence and polynomial acceleration can arise from the same mass-lift mechanism.
- Practical diagnostics allow estimating search exponents from finite candidate pools.
- A proposal-corrected resampling construction yields a fully certified sampler instance.
Where Pith is reading between the lines
- The mass-lift perspective could be applied to analyze other pretrained generative models used in sampling-based optimization.
- Diagnostics for search exponents could be validated by comparing predicted and observed performance on public molecular or crystal datasets.
- The framework suggests that regret bounds may be obtainable for any guidance mechanism that reliably shifts probability mass toward better designs.
Load-bearing premise
Mass lift can be defined, bounded, and estimated in a way that yields meaningful regret certificates for arbitrary pretrained diffusion generators and guidance mechanisms without hidden assumptions on the model or sampling process.
What would settle it
An experiment in which mass lift increases under stronger guidance yet measured simple regret fails to decrease would falsify the claimed link between mass lift and regret reduction.
Figures
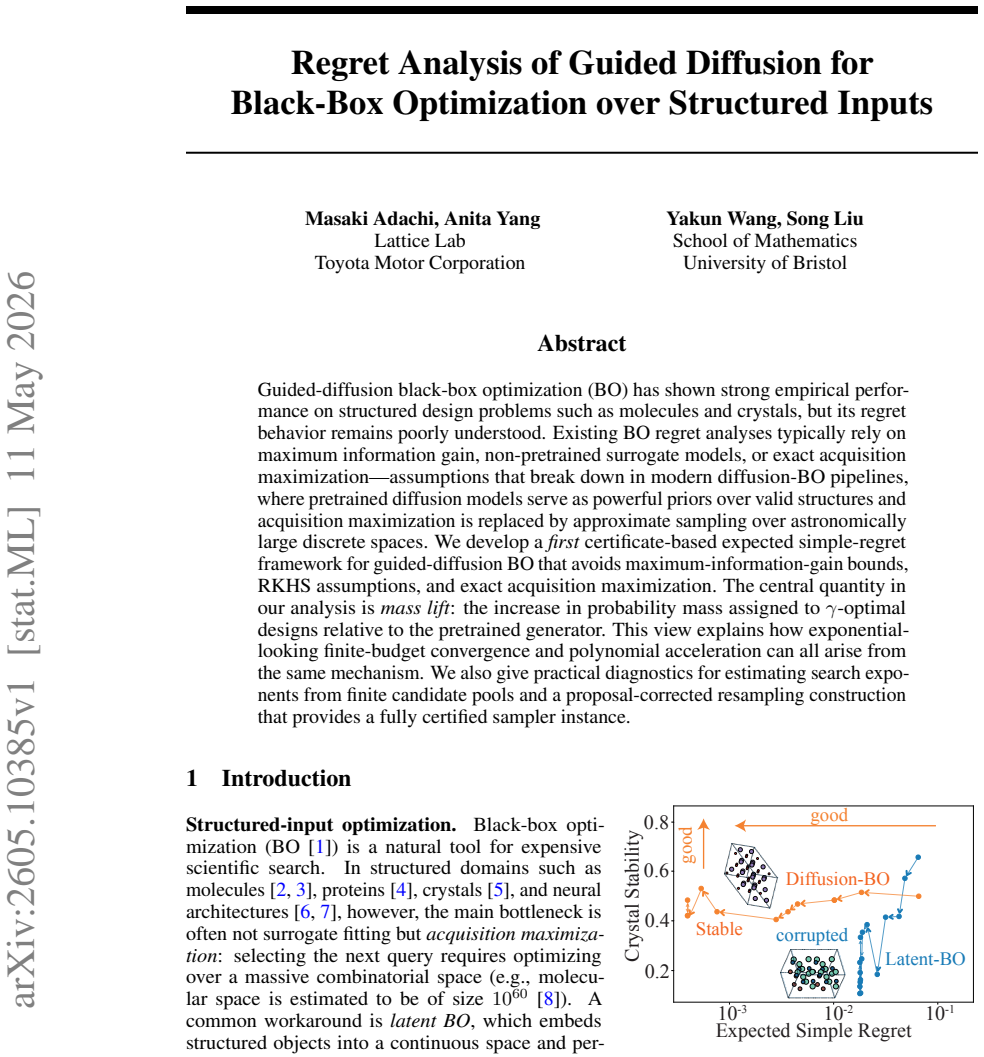
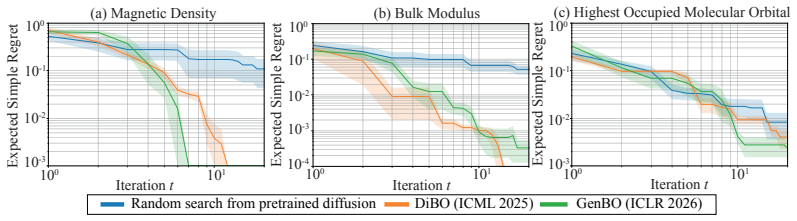
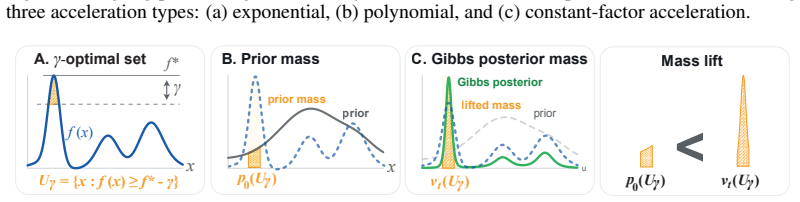








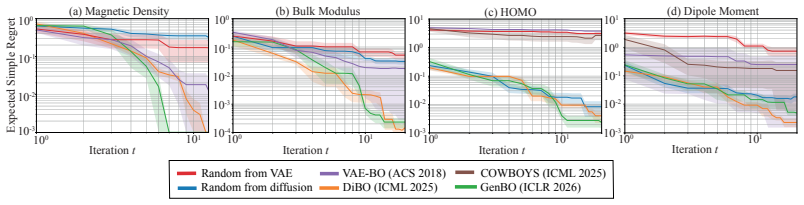
read the original abstract
Guided-diffusion black-box optimization (BO) has shown strong empirical performance on structured design problems such as molecules and crystals, but its regret behavior remains poorly understood. Existing BO regret analyses typically rely on maximum information gain, non-pretrained surrogate models, or exact acquisition maximization -- assumptions that break down in modern diffusion -- BO pipelines, where pretrained diffusion models serve as powerful priors over valid structures and acquisition maximization is replaced by approximate sampling over astronomically large discrete spaces. We develop a first certificate-based expected simple-regret framework for guided-diffusion BO that avoids maximum-information-gain bounds, RKHS assumptions, and exact acquisition maximization. The central quantity in our analysis is mass lift: the increase in probability mass assigned to near-optimal designs relative to the pretrained generator. This view explains how exponential-looking finite-budget convergence and polynomial acceleration can all arise from the same mechanism. We also give practical diagnostics for estimating search exponents from finite candidate pools and a proposal-corrected resampling construction that provides a fully certified sampler instance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a certificate-based expected simple-regret framework for guided-diffusion black-box optimization over structured inputs. It introduces 'mass lift' (the increase in probability mass on near-optimal designs relative to a pretrained generator) as the central quantity, derives regret bounds that avoid maximum information gain, RKHS assumptions, and exact acquisition maximization, explains various finite-budget convergence behaviors from this mechanism, and supplies practical diagnostics plus a proposal-corrected resampling construction for a certified sampler.
Significance. If the mass-lift bounds and resampling construction can be made rigorous for arbitrary pretrained diffusion generators, the work would supply a useful alternative analysis route for modern diffusion-BO pipelines on discrete structured domains, where standard BO tools are known to be mismatched. The explicit avoidance of information-gain and RKHS assumptions, together with the provision of observable diagnostics, would be a concrete strength.
major comments (3)
- [§3] §3 (mass-lift definition): the claim that mass lift yields meaningful regret certificates for arbitrary pretrained generators requires an explicit construction showing how positive probability mass is assigned to near-optimal sets when the underlying diffusion is continuous and the input space is discrete (individual designs have measure zero). Without a stated neighborhood or discretization argument, the lower bound on mass lift is not guaranteed to be well-defined or observable.
- [§4.2] §4.2 (proposal-corrected resampling): the construction is asserted to produce a 'fully certified sampler instance,' yet the argument does not address the common practical case in which the guidance mechanism only approximately samples from the conditioned diffusion. The correction term must be shown to remain valid (or the resulting regret certificate must be shown to degrade gracefully) under such approximation; otherwise the bound can become vacuous.
- [§5] §5 (regret certificates): the derivation that exponential-looking and polynomial convergence both arise from the same mass-lift mechanism is load-bearing for the central claim, but it is not clear from the given analysis whether the search-exponent diagnostics remain parameter-free once the pretrained generator and guidance schedule are fixed; any hidden dependence on the generator's training distribution would undermine the 'avoids maximum-information-gain' advantage.
minor comments (2)
- [Abstract] The abstract states that the framework 'explains how exponential-looking finite-budget convergence and polynomial acceleration can all arise from the same mechanism,' but the corresponding section should include a short table or figure contrasting the two regimes under the mass-lift lens.
- Notation for the mass-lift quantity and the proposal correction should be introduced with a single consolidated definition block rather than scattered across sections.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and for the constructive major comments. We address each point below and indicate the revisions that will be made to the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (mass-lift definition): the claim that mass lift yields meaningful regret certificates for arbitrary pretrained generators requires an explicit construction showing how positive probability mass is assigned to near-optimal sets when the underlying diffusion is continuous and the input space is discrete (individual designs have measure zero). Without a stated neighborhood or discretization argument, the lower bound on mass lift is not guaranteed to be well-defined or observable.
Authors: We agree that an explicit construction is required. In the revised manuscript we will add a discretization argument: mass lift is defined with respect to ε-neighborhoods of discrete designs under a problem-appropriate metric (e.g., edit distance for molecules). Because the diffusion model induces a continuous density, each such neighborhood receives positive probability mass, making the lower bound on mass lift both well-defined and observable from finite samples. The regret certificates then apply directly to these neighborhoods. revision: yes
-
Referee: [§4.2] §4.2 (proposal-corrected resampling): the construction is asserted to produce a 'fully certified sampler instance,' yet the argument does not address the common practical case in which the guidance mechanism only approximately samples from the conditioned diffusion. The correction term must be shown to remain valid (or the resulting regret certificate must be shown to degrade gracefully) under such approximation; otherwise the bound can become vacuous.
Authors: This is a valid observation. The current analysis assumes exact sampling from the guided diffusion. In the revision we will augment §4.2 with an approximation-error analysis: the proposal correction remains valid up to an additive term bounded by the total-variation distance between the approximate and exact conditional distributions. Consequently the regret certificate degrades gracefully rather than becoming immediately vacuous; we will state the explicit dependence on the approximation error. revision: yes
-
Referee: [§5] §5 (regret certificates): the derivation that exponential-looking and polynomial convergence both arise from the same mass-lift mechanism is load-bearing for the central claim, but it is not clear from the given analysis whether the search-exponent diagnostics remain parameter-free once the pretrained generator and guidance schedule are fixed; any hidden dependence on the generator's training distribution would undermine the 'avoids maximum-information-gain' advantage.
Authors: We will clarify this point. The search-exponent diagnostics are computed exclusively from the empirical probability masses observed in a finite candidate pool drawn from the fixed pretrained generator under the chosen guidance schedule. No further access to the generator's original training distribution is required. Because the generator is treated as a black-box prior that is already fixed, the diagnostics inherit no hidden dependence on training details and therefore preserve the claimed avoidance of maximum-information-gain assumptions. A short remark will be added to §5 to make this explicit. revision: partial
Circularity Check
No significant circularity; mass lift defined relative to external pretrained generator
full rationale
The derivation introduces mass lift as the increase in probability mass on near-optimal designs relative to the pretrained generator, an external reference point independent of the regret analysis. The framework then bounds expected simple regret in terms of this quantity while explicitly avoiding max-info-gain, RKHS, and exact maximization assumptions. No equation or step in the abstract reduces a claimed prediction or certificate to a fitted parameter or self-citation by construction; the central result remains a bound expressed in observable terms of the input generator. This is the most common honest non-finding for papers whose key quantity is defined against an external model.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard probabilistic assumptions underlying expected simple regret bounds hold for the guided diffusion process
invented entities (1)
-
mass lift
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearThe central quantity in our analysis is mass lift: the increase in probability mass assigned to γ-optimal designs relative to the pretrained generator.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearWe develop a first certificate-based expected simple-regret framework ... without relying on MIG, RKHS assumptions, or exact acquisition maximization.
Reference graph
Works this paper leans on
-
[1]
Cambridge University Press, 2023
Roman Garnett.Bayesian optimization. Cambridge University Press, 2023
work page 2023
-
[2]
Rafael Gómez-Bombarelli, Jennifer N Wei, David Duvenaud, José Miguel Hernández-Lobato, Benjamín Sánchez-Lengeling, Dennis Sheberla, Jorge Aguilera-Iparraguirre, Timothy D Hirzel, Ryan P Adams, and Alán Aspuru-Guzik. Automatic chemical design using a data-driven continuous representation of molecules.ACS Central Science, 4(2):268–276, 2018
work page 2018
-
[3]
DiGress: Discrete denoising diffusion for graph generation
Clement Vignac, Igor Krawczuk, Antoine Siraudin, Bohan Wang, V olkan Cevher, and Pas- cal Frossard. DiGress: Discrete denoising diffusion for graph generation. InInternational Conference on Learning Representations, 2023
work page 2023
-
[4]
Protein design with guided discrete diffusion
Nate Gruver, Samuel Stanton, Nathan Frey, Tim GJ Rudner, Isidro Hotzel, Julien Lafrance- Vanasse, Arvind Rajpal, Kyunghyun Cho, and Andrew G Wilson. Protein design with guided discrete diffusion. InAdvances in Neural Information Processing Systems, volume 36, pages 12489–12517, 2023
work page 2023
-
[5]
A generative model for inorganic materials design.Nature, 639(8055):624–632, 2025
Claudio Zeni, Robert Pinsler, Daniel Zügner, Andrew Fowler, Matthew Horton, Xiang Fu, Zilong Wang, Aliaksandra Shysheya, Jonathan Crabbé, Shoko Ueda, et al. A generative model for inorganic materials design.Nature, 639(8055):624–632, 2025
work page 2025
-
[6]
Bananas: Bayesian optimization with neural architectures for neural architecture search
Colin White, Willie Neiswanger, and Yash Savani. Bananas: Bayesian optimization with neural architectures for neural architecture search. InProceedings of the AAAI conference on artificial intelligence, volume 35, pages 10293–10301, 2021
work page 2021
-
[7]
Interpretable neural archi- tecture search via Bayesian optimisation with Weisfeiler-Lehman kernels
Binxin Ru, Xingchen Wan, Xiaowen Dong, and Michael Osborne. Interpretable neural archi- tecture search via Bayesian optimisation with Weisfeiler-Lehman kernels. InInternational Conference on Learning Representations, 2021
work page 2021
-
[8]
The chemical space project.Accounts of chemical research, 48(3):722– 730, 2015
Jean-Louis Reymond. The chemical space project.Accounts of chemical research, 48(3):722– 730, 2015
work page 2015
-
[9]
High- dimensional Bayesian optimisation with variational autoencoders and deep metric learning
Antoine Grosnit, Rasul Tutunov, Alexandre Max Maraval, Ryan-Rhys Griffiths, Alexander I Cowen-Rivers, Lin Yang, Lin Zhu, Wenlong Lyu, Zhitang Chen, Jun Wang, et al. High- dimensional Bayesian optimisation with variational autoencoders and deep metric learning. arXiv preprint arXiv:2106.03609, 2021
-
[10]
Henry Moss, Sebastian W. Ober, and Tom Diethe. Return of the latent space COWBOYS: Re-thinking the use of V AEs for Bayesian optimisation of structured spaces. InInternational Conference on Machine Learning, volume 267, pages 44956–44970, 2025
work page 2025
-
[11]
Natalie Maus, Haydn Jones, Juston Moore, Matt J Kusner, John Bradshaw, and Jacob Gardner. Local latent space Bayesian optimization over structured inputs.Advances in Neural Information Processing Systems, 35:34505–34518, 2022
work page 2022
-
[12]
Seunghun Lee, Jaewon Chu, Sihyeon Kim, Juyeon Ko, and Hyunwoo J Kim. Advancing Bayesian optimization via learning correlated latent space.Advances in Neural Information Processing Systems, 36:48906–48917, 2023
work page 2023
-
[13]
Verifier-constrained flow expansion for discovery beyond the data
Riccardo De Santi, Kimon Protopapas, Ya-Ping Hsieh, and Andreas Krause. Verifier-constrained flow expansion for discovery beyond the data. InInternational Conference on Learning Representations, 2026
work page 2026
-
[14]
Rui Jiao, Wenbing Huang, Peijia Lin, Jiaqi Han, Pin Chen, Yutong Lu, and Yang Liu. Crystal structure prediction by joint equivariant diffusion.Advances in Neural Information Processing Systems, 36:17464–17497, 2023. 10
work page 2023
-
[15]
Structural constraint integration in a generative model for the discovery of quantum materials
Ryotaro Okabe, Mouyang Cheng, Abhijatmedhi Chotrattanapituk, Manasi Mandal, Kiran Mak, Denisse Córdova Carrizales, Nguyen Tuan Hung, Xiang Fu, Bowen Han, Yao Wang, et al. Structural constraint integration in a generative model for the discovery of quantum materials. Nature Materials, pages 1–8, 2025
work page 2025
-
[16]
Posterior inference with diffusion models for high-dimensional black-box optimization
Taeyoung Yun, Kiyoung Om, Jaewoo Lee, Sujin Yun, and Jinkyoo Park. Posterior inference with diffusion models for high-dimensional black-box optimization. InInternational Conference on Machine Learning, volume 267, pages 73897–73917, 2025
work page 2025
-
[17]
Rafael Oliveira, Daniel M. Steinberg, and Edwin V . Bonilla. Generative bayesian optimiza- tion: Generative models as acquisition functions. InInternational Conference on Learning Representations, 2026
work page 2026
-
[18]
Fast best-of-n decoding via speculative rejection
Hanshi Sun, Momin Haider, Ruiqi Zhang, Huitao Yang, Jiahao Qiu, Ming Yin, Mengdi Wang, Peter Bartlett, and Andrea Zanette. Fast best-of-n decoding via speculative rejection. In Advances in Neural Information Processing Systems, volume 37, pages 32630–32652, 2024
work page 2024
-
[19]
MatInvent: Reinforcement learning for 3D crystal diffusion generation
Junwu Chen, Jeff Guo, and Philippe Schwaller. MatInvent: Reinforcement learning for 3D crystal diffusion generation. InAI for Accelerated Materials Design - ICLR Workshop, 2025
work page 2025
-
[20]
Hyunsoo Park and Aron Walsh. Guiding generative models to uncover diverse and novel crystals via reinforcement learning.arXiv preprint arXiv:2511.07158, 2025
-
[21]
Gaussian process op- timization in the bandit setting: No regret and experimental design
Niranjan Srinivas, Andreas Krause, Sham M Kakade, and Matthias Seeger. Gaussian process op- timization in the bandit setting: No regret and experimental design. InInternational Conference on Machine Learning (ICML), pages 1015–1022, 2010
work page 2010
-
[22]
Masaki Adachi, Siu Lun Chau, Wenjie Xu, Anurag Singh, Michael A Osborne, and Krikamol Muandet. Bayesian optimization for building social-influence-free consensus.arXiv preprint arXiv:2502.07166, 2025
-
[23]
Adam D. Bull. Convergence rates of efficient global optimization algorithms.Journal of Machine Learning Research, 12(88):2879–2904, 2011
work page 2011
-
[24]
Neural contextual bandits with UCB-based exploration
Dongruo Zhou, Lihong Li, and Quanquan Gu. Neural contextual bandits with UCB-based exploration. InInternational Conference on Machine Learning, pages 11492–11502. PMLR, 2020
work page 2020
-
[25]
A rigorous link between deep ensembles and (variational) Bayesian methods
Veit David Wild, Sahra Ghalebikesabi, Dino Sejdinovic, and Jeremias Knoblauch. A rigorous link between deep ensembles and (variational) Bayesian methods. InAdvances in Neural Information Processing Systems, volume 36, pages 39782–39811, 2023
work page 2023
-
[26]
Diffusion Models are Evolutionary Algorithms
Yanbo Zhang, Benedikt Hartl, Hananel Hazan, and Michael Levin. Diffusion models are evolutionary algorithms.arXiv preprint arXiv:2410.02543, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Jeremias Knoblauch, Jack Jewson, and Theodoros Damoulas. Generalized variational inference: Three arguments for deriving new posteriors.arXiv preprint arXiv:1904.02063, 2019
-
[28]
Reinforcement learning by reward-weighted regression for operational space control
Jan Peters and Stefan Schaal. Reinforcement learning by reward-weighted regression for operational space control. InInternational Conference on Machine Learning, pages 745–750, 2007
work page 2007
-
[29]
Tomasz Korbak, Hady Elsahar, Germán Kruszewski, and Marc Dymetman. On reinforcement learning and distribution matching for fine-tuning language models with no catastrophic forget- ting. InAdvances in Neural Information Processing Systems, volume 35, pages 16203–16220, 2022
work page 2022
-
[30]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems, volume 36, pages 53728–53741, 2023
work page 2023
-
[31]
Akash Srivastava, Lazar Valkov, Chris Russell, Michael U Gutmann, and Charles Sutton. Veegan: Reducing mode collapse in gans using implicit variational learning.Advances in Neural Information Processing Systems, 30, 2017. 11
work page 2017
-
[32]
Harold J Kushner. A new method of locating the maximum point of an arbitrary multipeak curve in the presence of noise.Journal of Basic Engineering, 86:97 – 106, 1964
work page 1964
-
[33]
InInternational Conference on Learning Representations, 2022
Carl Hvarfner, Danny Stoll, Artur Souza, Luigi Nardi, Marius Lindauer, and Frank Hutter.πBO: Augmenting acquisition functions with user beliefs for Bayesian optimization. InInternational Conference on Learning Representations, 2022
work page 2022
-
[34]
Masaki Adachi, Satoshi Hayakawa, Martin Jørgensen, Saad Hamid, Harald Oberhauser, and Michael A Osborne. A quadrature approach for general-purpose batch Bayesian optimization via probabilistic lifting.arXiv preprint arXiv:2404.12219, 2024
-
[35]
Osborne, Sebastian Orbell, Natalia Ares, Krikamol Muandet, and Siu Lun Chau
Masaki Adachi, Brady Planden, David Howey, Michael A. Osborne, Sebastian Orbell, Natalia Ares, Krikamol Muandet, and Siu Lun Chau. Looping in the human: collaborative and explainable Bayesian optimization. InInternational Conference on Artificial Intelligence and Statistics, volume 238, pages 505–513, 2024
work page 2024
-
[36]
Wenjie Xu, Masaki Adachi, Colin N Jones, and Michael A Osborne. Principled Bayesian optimization in collaboration with human experts.Advances in Neural Information Processing Systems, 37:104091–104137, 2024
work page 2024
-
[37]
Jonas Mockus. On the Bayes methods for seeking the extremal point.IFAC Proceedings Volumes, 8(1, Part 1):428–431, 1975
work page 1975
-
[38]
Gaussian processes in machine learning
Carl Edward Rasmussen. Gaussian processes in machine learning. InSummer school on machine learning, pages 63–71. Springer, 2003
work page 2003
-
[39]
Amortizing intractable inference in diffusion models for vision, language, and control
Siddarth Venkatraman, Moksh Jain, Luca Scimeca, Minsu Kim, Marcin Sendera, Mohsin Hasan, Luke Rowe, Sarthak Mittal, Pablo Lemos, Emmanuel Bengio, et al. Amortizing intractable inference in diffusion models for vision, language, and control. InAdvances in Neural Information Processing Systems, volume 37, pages 76080–76114, 2024
work page 2024
-
[40]
A general recipe for likelihood-free Bayesian optimization
Jiaming Song, Lantao Yu, Willie Neiswanger, and Stefano Ermon. A general recipe for likelihood-free Bayesian optimization. InInternational Conference on Machine Learning, pages 20384–20404. PMLR, 2022
work page 2022
-
[41]
Cambridge University Press, 2012
Masashi Sugiyama, Taiji Suzuki, and Takafumi Kanamori.Density ratio estimation in machine learning. Cambridge University Press, 2012
work page 2012
-
[42]
BORE: Bayesian optimization by density-ratio estimation
Louis C Tiao, Aaron Klein, Matthias W Seeger, Edwin V Bonilla, Cedric Archambeau, and Fabio Ramos. BORE: Bayesian optimization by density-ratio estimation. InInternational Conference on Machine Learning, pages 10289–10300. PMLR, 2021
work page 2021
-
[43]
Rafael Oliveira, Louis Tiao, and Fabio T. Ramos. Batch Bayesian optimisation via density-ratio estimation with guarantees. InAdvances in Neural Information Processing Systems, volume 35, pages 29816–29829, 2022
work page 2022
-
[44]
Diffusion model alignment using direct preference optimization
Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik. Diffusion model alignment using direct preference optimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8228–8238, 2024
work page 2024
-
[45]
Scalable valuation of human feed- back through provably robust model alignment
Masahiro Fujisawa, Masaki Adachi, and Michael A Osborne. Scalable valuation of human feed- back through provably robust model alignment. InAdvances in Neural Information Processing Systems, 2025
work page 2025
-
[46]
Strictly proper scoring rules, prediction, and estimation
Tilmann Gneiting and Adrian E Raftery. Strictly proper scoring rules, prediction, and estimation. Journal of the American Statistical Association, 102(477):359–378, 2007
work page 2007
-
[47]
Fixing the pitfalls of probabilistic time-series forecasting evaluation by kernel quadrature
Masaki Adachi, Masahiro Fujisawa, and Michael A Osborne. Fixing the pitfalls of probabilistic time-series forecasting evaluation by kernel quadrature. In Motonobu Kanagawa, Jon Cockayne, Alexandra Gessner, and Philipp Hennig, editors,Proceedings of the First International Confer- ence on Probabilistic Numerics, volume 271 ofProceedings of Machine Learning...
work page 2025
-
[48]
Simon Jackman.Bayesian analysis for the social sciences. John Wiley & Sons, 2009
work page 2009
-
[49]
Diffusion models are minimax optimal distribution estimators
Kazusato Oko, Shunta Akiyama, and Taiji Suzuki. Diffusion models are minimax optimal distribution estimators. InInternational Conference on Machine Learning, pages 26517–26582. PMLR, 2023
work page 2023
-
[50]
Direct distributional optimization for provable alignment of diffusion models
Ryotaro Kawata, Kazusato Oko, Atsushi Nitanda, and Taiji Suzuki. Direct distributional optimization for provable alignment of diffusion models. InInternational Conference on Learning Representations, 2025
work page 2025
-
[51]
Taiji Suzuki. Adaptivity of deep reLU network for learning in Besov and mixed smooth Besov spaces: optimal rate and curse of dimensionality. InInternational Conference on Learning Representations, 2019
work page 2019
-
[52]
Deep neural networks learn non-smooth functions effectively
Masaaki Imaizumi and Kenji Fukumizu. Deep neural networks learn non-smooth functions effectively. InInternational Conference on Artificial Intelligence and Statistics, volume 89, pages 869–878. PMLR, 16–18 Apr 2019
work page 2019
-
[53]
Geoffroy Hautier. Finding the needle in the haystack: Materials discovery and design through computational ab initio high-throughput screening.Computational Materials Science, 163:108– 116, 2019
work page 2019
-
[54]
Alexander E Siemenn, Zekun Ren, Qianxiao Li, and Tonio Buonassisi. Fast Bayesian optimiza- tion of needle-in-a-haystack problems using zooming memory-based initialization (ZoMBI). npj Computational Materials, 9(1):79, 2023
work page 2023
-
[55]
Bayesian optimisation with unknown hyperparameters: regret bounds logarithmically closer to optimal
Juliusz Ziomek, Masaki Adachi, and Michael A Osborne. Bayesian optimisation with unknown hyperparameters: regret bounds logarithmically closer to optimal. InAdvances in Neural Information Processing Systems, volume 37, pages 86346–86374, 2024
work page 2024
-
[56]
Diffusion models for black-box optimization
Siddarth Krishnamoorthy, Satvik Mehul Mashkaria, and Aditya Grover. Diffusion models for black-box optimization. InInternational Conference on Machine Learning, volume 202, pages 17842–17857, 2023
work page 2023
-
[57]
Diffusion model for data-driven black-box optimization.arXiv preprint arXiv:2403.13219, 2024
Zihao Li, Hui Yuan, Kaixuan Huang, Chengzhuo Ni, Yinyu Ye, Minshuo Chen, and Mengdi Wang. Diffusion model for data-driven black-box optimization.arXiv preprint arXiv:2403.13219, 2024
-
[58]
GAUCHE: a library for Gaussian processes in chemistry
Ryan-Rhys Griffiths, Leo Klarner, Henry Moss, Aditya Ravuri, Sang Truong, Yuanqi Du, Samuel Stanton, Gary Tom, Bojana Rankovic, Arian Jamasb, et al. GAUCHE: a library for Gaussian processes in chemistry. InAdvances in Neural Information Processing Systems, volume 36, pages 76923–76946, 2023
work page 2023
-
[59]
Boss: Bayesian optimization over string spaces
Henry Moss, David Leslie, Daniel Beck, Javier Gonzalez, and Paul Rayson. Boss: Bayesian optimization over string spaces. InAdvances in Neural Information Processing Systems, volume 33, pages 15476–15486, 2020
work page 2020
-
[60]
Anil Ramachandran, Sunil Gupta, Santu Rana, Cheng Li, and Svetha Venkatesh. Incorpo- rating expert prior in Bayesian optimisation via space warping.Knowledge-Based Systems, 195:105663, 2020
work page 2020
-
[61]
Bayesian optimization with a prior for the optimum
Artur Souza, Luigi Nardi, Leonardo B Oliveira, Kunle Olukotun, Marius Lindauer, and Frank Hutter. Bayesian optimization with a prior for the optimum. InJoint European Conference on Machine Learning and Knowledge Discovery in Databases, pages 265–296. Springer, 2021
work page 2021
-
[62]
A general framework for user-guided Bayesian optimization
Carl Hvarfner, Frank Hutter, and Luigi Nardi. A general framework for user-guided Bayesian optimization. InInternational Conference on Learning Representations, 2024
work page 2024
-
[63]
Scalable global optimization via local Bayesian optimization
David Eriksson, Michael Pearce, Jacob Gardner, Ryan D Turner, and Matthias Poloczek. Scalable global optimization via local Bayesian optimization. InAdvances in Neural Information Processing Systems, volume 32, 2019
work page 2019
-
[64]
High-dimensional Bayesian optimization with sparse axis-aligned subspaces
David Eriksson and Martin Jankowiak. High-dimensional Bayesian optimization with sparse axis-aligned subspaces. InConference on Uncertainty in Artificial Intelligence, pages 493–503. PMLR, 2021. 13
work page 2021
-
[65]
Felix Berkenkamp, Angela P Schoellig, and Andreas Krause. No-regret Bayesian optimization with unknown hyperparameters.Journal of Machine Learning Research, 20(50):1–24, 2019
work page 2019
-
[66]
Time-varying Gaussian process bandits with unknown prior
Juliusz Ziomek, Masaki Adachi, and Michael A Osborne. Time-varying Gaussian process bandits with unknown prior. InInternational Conference on Artificial Intelligence and Statistics, volume 258, pages 4294–4302, 2025
work page 2025
-
[67]
Natalie Maus, Kyurae Kim, Geoff Pleiss, David Eriksson, John P Cunningham, and Jacob R Gardner. Approximation-aware Bayesian optimization.Advances in Neural Information Processing Systems, 37:21114–21140, 2024
work page 2024
-
[68]
Adaptive batch sizes for active learning: A probabilistic numerics approach
Masaki Adachi, Satoshi Hayakawa, Martin Jørgensen, Xingchen Wan, Vu Nguyen, Harald Oberhauser, and Michael A Osborne. Adaptive batch sizes for active learning: A probabilistic numerics approach. InInternational Conference on Artificial Intelligence and Statistics, pages 496–504, 2024
work page 2024
-
[69]
Natural evolutionary search meets probabilistic numerics
Pierre Osselin, Masaki Adachi, Xiaowen Dong, and Michael A Osborne. Natural evolutionary search meets probabilistic numerics. InInternational Conference on Probabilistic Numerics, volume 271, pages 50–74, 2025
work page 2025
-
[70]
Kamal Choudhary and Brian DeCost. Atomistic line graph neural network for improved materials property predictions.npj Computational Materials, 7(1):185, 2021
work page 2021
-
[71]
Christoph Bannwarth, Sebastian Ehlert, and Stefan Grimme. GFN2-xTB—An accurate and broadly parametrized self-consistent tight-binding quantum chemical method with multipole electrostatics and density-dependent dispersion contributions.Journal of Chemical Theory and Computation, 15(3):1652–1671, 2019
work page 2019
-
[72]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[73]
Anita Yang, Krikamol Muandet, Michele Caprio, Siu Lun Chau, and Masaki Adachi. Verbalizing LLM’s higher-order uncertainty via imprecise probabilities.arXiv preprint arXiv:2603.10396, 2026
-
[74]
Open-Ended Task Discovery via Bayesian Optimization
Masaki Adachi, Yuta Suzuki, and Juliusz Ziomek. Open-ended task discovery via Bayesian optimization.arXiv preprint arXiv:2605.07572, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[75]
Deep learning.Nature, 521(7553):436–444, 2015
Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. Deep learning.Nature, 521(7553):436–444, 2015
work page 2015
-
[76]
Tian Xie and Jeffrey C Grossman. Crystal graph convolutional neural networks for an accurate and interpretable prediction of material properties.Physical review letters, 120(14):145301, 2018
work page 2018
- [77]
-
[78]
Anubhav Jain, Shyue Ping Ong, Geoffroy Hautier, Wei Chen, William Davidson Richards, Stephen Dacek, Shreyas Cholia, Dan Gunter, David Skinner, Gerbrand Ceder, and Kristin A. Persson. Commentary: The materials project: A materials genome approach to accelerating materials innovation.APL Materials, 1(1):011002, 07 2013
work page 2013
-
[79]
MoleculeNet: a benchmark for molecular machine learning.Chemical Science, 9(2):513–530, 2018
Zhenqin Wu, Bharath Ramsundar, Evan N Feinberg, Joseph Gomes, Caleb Geniesse, Aneesh S Pappu, Karl Leswing, and Vijay Pande. MoleculeNet: a benchmark for molecular machine learning.Chemical Science, 9(2):513–530, 2018
work page 2018
-
[80]
How powerful are graph neural networks? InInternational Conference on Learning Representations, 2019
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? InInternational Conference on Learning Representations, 2019. 14 Part I Appendix Table of Contents A Notation 16 B Extended background 18 B.1 Likelihood-free BO. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18 B.2 Diffusion models in one p...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.