Recognition: 2 theorem links
· Lean TheoremBeyond Spatial Compression: Interface-Centric Generative States for Open-World 3D Structure
Pith reviewed 2026-05-12 04:27 UTC · model grok-4.3
The pith
3D tokenizers can expose local geometry, component ownership, and attachment validity as separate queryable variables rather than entangling them in compressed codes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
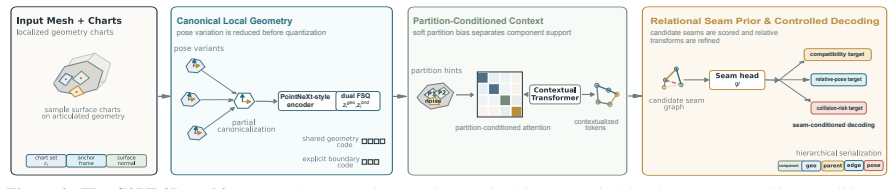
By constructing tokenization as an operational state rather than passive compression, Component-Conditioned Canonical Local Tokens (C2LT-3D) factorize representation into canonical local geometry, partition-conditioned context, and relational seam variables; each factor targets a distinct failure mode of compression-centric tokens, enabling attachment validation, latent structural repair, targeted intervention, and constrained serialization directly on the exposed state.
What carries the argument
Component-Conditioned Canonical Local Tokens (C2LT-3D), which factorize the generative state into canonical local geometry, partition-conditioned context, and relational seam variables to isolate and address pose leakage, cross-component interference, and invalid local attachments.
If this is right
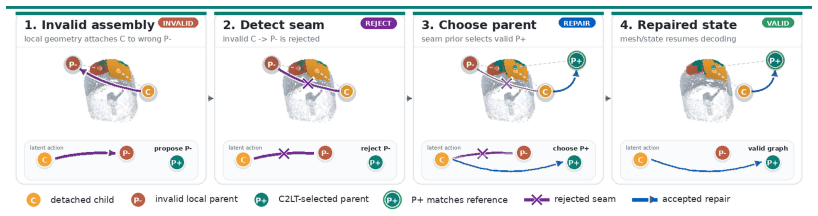
- Attachment validation and repair can be performed by directly querying or constraining the exposed seam and context variables.
- Targeted interventions on individual components become possible without affecting unrelated geometry.
- Constrained serialization of assemblies can be achieved natively during decoding.
- Generative 3D models can be evaluated by the operationality of their discrete states for assembly-level reasoning in addition to reconstruction fidelity.
Where Pith is reading between the lines
- If the factorization succeeds in isolating relations, it may reduce the need for large-scale multi-object training data in structural 3D tasks.
- The same interface-centric principle could apply to other generative domains where compressed codes currently hide relational structure.
- Zero-shot transfer from single to multi-object cases suggests that explicit interface modeling captures reusable assembly primitives.
Load-bearing premise
The chosen factorization will keep geometry, ownership, and seam relations independent enough that single-object training generalizes to noisy multi-component open-world assets without entanglement.
What would settle it
A test set of open-world multi-component assets with intersecting parts where C2LT-3D latent variables lose actionability for attachment validation or where structural robustness does not improve over standard compression tokenizers.
Figures











read the original abstract
Current 3D tokenizers largely treat representation as spatial compression: compact codes reconstruct surface geometry, but leave component ownership and attachment validity implicit. In open-world assets with intersecting components, noisy topology, and weak canonical structure, this creates a representation mismatch: local shape, component identity, and assembly relations become entangled in a latent stream and are not natively addressable during decoding. We formulate an alternative view, interface-centric generative states, in which tokenization constructs an operational state rather than a passive compressed code. The state exposes local geometry, component ownership, and attachment validity as variables that can be queried, constrained, and repaired during decoding. We instantiate this formulation with Component-Conditioned Canonical Local Tokens (C2LT-3D), factorizing representation into canonical local geometry, partition-conditioned context, and relational seam variables. Each factor targets a distinct failure mode of compression-centric tokens: pose leakage, cross-component interference, or invalid local attachment. This exposed state supports attachment validation, latent structural repair, targeted intervention, and constrained serialization without a separate post-hoc structure recovery module. Trained on single-object CAD models and evaluated zero-shot on open-world multi-component assets, C2LT-3D improves structural robustness and shows that its latent variables remain actionable under adversarial attachment settings. These results suggest that open-world 3D generative representations should be evaluated not only by reconstruction fidelity, but by whether their discrete states remain operational for assembly-level structural reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes 'interface-centric generative states' as an alternative to spatial compression in 3D tokenizers for open-world assets. It introduces Component-Conditioned Canonical Local Tokens (C2LT-3D), which factorize representation into canonical local geometry, partition-conditioned context, and relational seam variables. Each factor is claimed to independently address a distinct failure mode (pose leakage, cross-component interference, invalid attachments). The paper asserts that training on single-object CAD models enables zero-shot generalization to noisy multi-component assets, yielding improved structural robustness with latent variables that remain actionable for attachment validation and structural repair under adversarial settings, without needing post-hoc recovery modules.
Significance. If the empirical claims and factorization hold, the work could meaningfully advance 3D generative representations by treating tokenization as constructing an operational state rather than passive compression. This would support direct assembly-level reasoning in complex scenes and shift evaluation criteria toward operational utility, potentially reducing entanglement issues in multi-component 3D generation.
major comments (2)
- [Abstract] Abstract: The central claim that C2LT-3D 'improves structural robustness' and that 'its latent variables remain actionable under adversarial attachment settings' after zero-shot evaluation on open-world multi-component assets is unsupported by any quantitative metrics, baselines, error analysis, or experimental protocol. This absence is load-bearing because the abstract presents the result as demonstrated rather than hypothesized.
- [Abstract] Abstract / Formulation section: The assertion that the three factors independently target distinct failure modes rests on an unverified assumption of separability. No derivation, explicit loss terms, or constraints are shown to enforce independence between canonical local geometry, partition-conditioned context, and relational seam variables, raising the risk that pose leakage or cross-component interference remains entangled when generalizing from single-object training data.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly named the training and evaluation datasets or asset sources to contextualize the single-object to multi-component zero-shot transfer.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below, clarifying the experimental basis for our claims and the design rationale for factor independence. We will incorporate revisions to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that C2LT-3D 'improves structural robustness' and that 'its latent variables remain actionable under adversarial attachment settings' after zero-shot evaluation on open-world multi-component assets is unsupported by any quantitative metrics, baselines, error analysis, or experimental protocol. This absence is load-bearing because the abstract presents the result as demonstrated rather than hypothesized.
Authors: We agree the abstract wording presents the outcome as demonstrated. The manuscript reports zero-shot transfer results with qualitative structural robustness indicators and actionable latent variable behavior under adversarial attachments (detailed in the experiments section), but we acknowledge the absence of explicit quantitative baselines, error bars, and a consolidated protocol table. In revision we will (i) tone the abstract to 'demonstrates improved structural robustness via ...' with explicit cross-references, (ii) add a dedicated experimental protocol subsection, and (iii) include quantitative metrics and baseline comparisons to make the support fully explicit. revision: yes
-
Referee: [Abstract] Abstract / Formulation section: The assertion that the three factors independently target distinct failure modes rests on an unverified assumption of separability. No derivation, explicit loss terms, or constraints are shown to enforce independence between canonical local geometry, partition-conditioned context, and relational seam variables, raising the risk that pose leakage or cross-component interference remains entangled when generalizing from single-object training data.
Authors: The C2LT-3D factorization uses three separate loss terms (canonical geometry reconstruction, partition-conditioned context classification, and seam validity regression) plus explicit conditioning masks that isolate each variable during decoding. This modular construction is intended to target the three failure modes without explicit orthogonality penalties. We did not supply a formal separability derivation or ablation verifying zero entanglement. In revision we will add a short derivation in the formulation section showing how the conditioning and loss separation limit cross-talk, together with an ablation that measures residual pose leakage and interference on the zero-shot multi-component test set. revision: yes
Circularity Check
No circularity: formulation presented as independent proposal without reduction to inputs
full rationale
The paper introduces interface-centric generative states as an alternative to spatial compression and instantiates it via C2LT-3D by factorizing into canonical local geometry, partition-conditioned context, and relational seam variables, each claimed to target distinct failure modes. No equations, derivations, or self-citations are shown that reduce these factors, their claimed independence, or the zero-shot generalization claim to fitted parameters, self-definitions, or prior author results by construction. The abstract and description treat the factorization as a new operational state exposed for querying and repair, with evaluation results presented as empirical outcomes rather than forced by the method's own inputs. This leaves the central claims self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Factorization into canonical local geometry, partition-conditioned context, and relational seam variables targets distinct failure modes of pose leakage, cross-component interference, and invalid attachment.
invented entities (2)
-
interface-centric generative states
no independent evidence
-
Component-Conditioned Canonical Local Tokens (C2LT-3D)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearTrained on single-object CAD models and evaluated zero-shot on open-world multi-component assets
Reference graph
Works this paper leans on
-
[1]
ShapeNet: An Information-Rich 3D Model Repository
Angel X Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, et al. Shapenet: An information-rich 3d model repository.arXiv 11 preprint arXiv:1512.03012,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Christian Laforte, Vikram V oleti, Samir Yitzhak Gadre, et al. Objaverse-xl: A universe of 10m+ 3d objects.Advances in Neural Information Processing Systems, 36:35799–35813, 2023a. Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli Van...
-
[3]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Finite scalar quantization: Vq-vae made simple.arXiv preprint arXiv:2309.15505, 2023
Fabian Mentzer, David Minnen, Eirikur Agustsson, and Michael Tschannen. Finite scalar quantization: Vq-vae made simple.arXiv preprint arXiv:2309.15505,
-
[5]
Kaichun Mo, Paul Guerrero, Li Yi, Hao Su, Peter Wonka, Niloy Mitra, and Leonidas J Guibas. Structurenet: Hierarchical graph networks for 3d shape generation.arXiv preprint arXiv:1908.00575, 2019a. Kaichun Mo, Shilin Zhu, Angel X Chang, Li Yi, Subarna Tripathi, Leonidas J Guibas, and Hao Su. Partnet: A large-scale benchmark for fine-grained and hierarchica...
-
[6]
Llama-mesh: Unifying 3d mesh generation with language models.arXiv preprint arXiv:2411.09595, 2024
Zhengyi Wang, Jonathan Lorraine, Yikai Wang, Hang Su, Jun Zhu, Sanja Fidler, and Xiaohui Zeng. Llama-mesh: Unifying 3d mesh generation with language models.arXiv preprint arXiv:2411.09595,
-
[7]
Its compressed output does not expose ownership or seam-repair state
Main external compression-centric baseline Released pretrained mesh-token pipeline can be run on the fixed 1,024 Objaverse-LVIS assets and evaluated under the same structural protocol. Its compressed output does not expose ownership or seam-repair state. VQ-Patch Spatial-only reference baselineIn-house VQ spatial tokenizer trained and evaluated under the ...
work page 2024
-
[8]
Mesh-token geometry output; no native component ownership or seam-repair operator
Released high-capacity mesh-token baseline evaluated on the fixed 1,024 Objaverse-LVIS objects. Mesh-token geometry output; no native component ownership or seam-repair operator. Quantitative external baseline in Table 1; full 1,024-object row included. MeshGPT / PolyGen (Siddiqui et al., 2024; Nash et al., 2020)Clean-CAD mesh-token generation references....
work page 2024
-
[9]
Separation Whether distinct components remain structurally isolated instead of being fused into a single support. Interpreted jointly with Chamfer, Hausdorff, contamination, and normal consistency, so a method cannot win by simply pushing components apart or eroding geometry. Repair and seam-ranking metrics Whether the latent state exposes attachment vari...
-
[10]
Confidence intervals are 95% bootstrap intervals over objects
Positive values always favor C2LT-3D: for distance/error metrics this is baseline minus C2LT-3D, and for higher-is-better metrics this is C2LT-3D minus baseline. Confidence intervals are 95% bootstrap intervals over objects. Baseline Metric Mean Improvement 95% CI Object Win Rate VQ-Patch Chamfer 0.0035 [0.0033, 0.0038] 84.8% VQ-Patch Hausdorff 0.0995 [0....
-
[11]
Method Subset Size Chamfer↓Contamination↓Separation↑Norm
The performance gap widens on this structurally heavier slice: BPT incurs substantially higher contamination and lower separation, while the learned seam-prior C2LT-3D variant retains the strongest structural isolation. Method Subset Size Chamfer↓Contamination↓Separation↑Norm. Cons.↑ BPT (Spatial Comp.) 54 0.0607 0.1341 0.9026 0.0194 C2LT-3D w/o Partition...
-
[12]
Starting from a serialized prefix, we detach one child token, keep all previously placed tokens as candidate parents, and mark the serialized reference parent as the valid target. The main-text benchmark uses a larger edge bank over all valid inter-part attachments; the prefix protocol shows the deployment-style variant where only earlier serialized token...
-
[13]
Used through the released baseline artifacts and cited paper
External compression-centric baseline evaluated under the same structural protocol. Used through the released baseline artifacts and cited paper. We do not redistribute upstream weights or code beyond instructions for reproducing the evaluation. MeshAnythingV2 / MeshArt / MeshGPT / PolyGen / LoST (Chen et al., 2025; Gao et al., 2025; Siddiqui et al., 2024...
work page 2025
-
[14]
Table 27: Canonicalization ablation on tokenizer local-field metrics.We compare the standard canonical input frame against aw/o Canonicalizationvariant that feeds the same tokenizer in the world-local frame. Results are measured on 32 validation batches from the ShapeNet protocol split using the validation-selected tokenizer. Removing canonicalization red...
work page 2022
-
[15]
Boundary FSQ: 4 slots with 7 levels each (74 effective codes)
Discrete code streams Geometry FSQ: 6 slots with 7 levels each (76 effective codes). Boundary FSQ: 4 slots with 7 levels each (74 effective codes). Pose residual dimension 6 plus one scale residual. Provides a pure spatial patch code without semantic part labels or seam attachment states. Context/realization network Context width 256, depth 4, 4 attention...
work page 2017
-
[16]
Table 30: Training phases and optimization parameters.Later phases are initialized from the validation-selected checkpoint of the preceding phase. Phase Trainable modules Optimizer and schedule Objective / weights Tokenizer and local-field phase Tokenizer, token projection, local decoder; support-geometry branch added in the final continuation AdamW (Losh...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.