Recognition: no theorem link
Filtering Memorization from Parameter-Space in Diffusion Models
Pith reviewed 2026-05-12 03:25 UTC · model grok-4.3
The pith
Base-Anchored Filtering reduces memorization in diffusion LoRAs by suppressing channels weakly aligned with the pretrained backbone's principal subspace.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
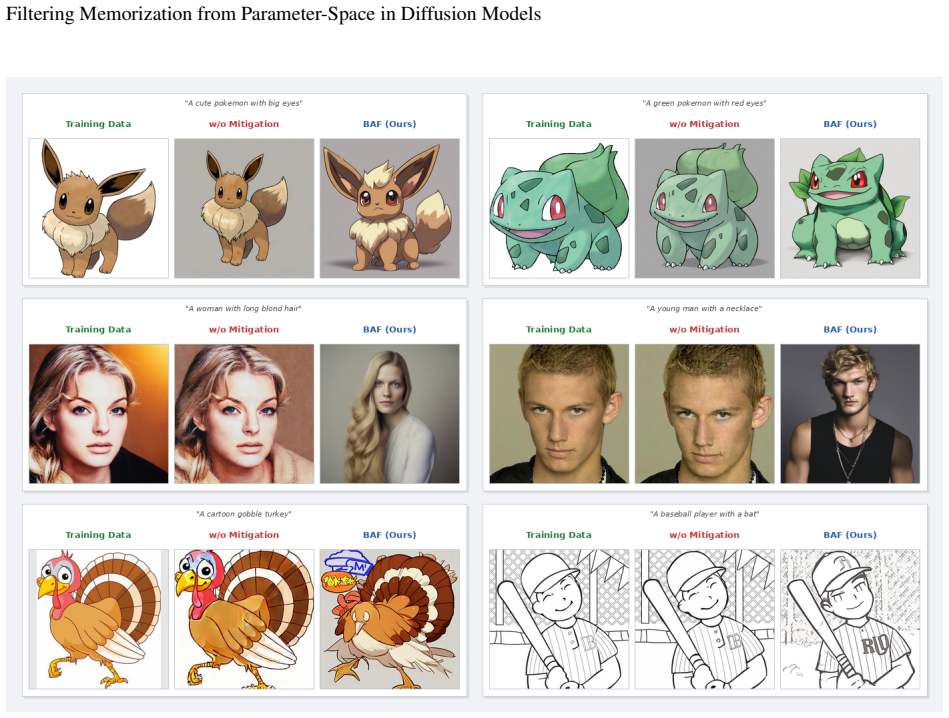
BAF decomposes LoRA updates into spectral channels and measures their alignment with the principal subspace of the pretrained backbone. Channels strongly aligned with this subspace are retained as generalizable adaptations, while weakly aligned channels are suppressed as potential carriers of memorized content. Experiments on multiple datasets and diffusion backbones demonstrate that BAF consistently reduces memorization while preserving or even improving generation quality.
What carries the argument
Spectral decomposition of LoRA weight updates followed by alignment scoring against the principal subspace of the base diffusion model, used to decide which channels to keep or remove.
If this is right
- LoRA weights can be released publicly with lower risk of reproducing copyrighted or sensitive training images.
- The filter works after training is complete and requires no access to the original training data or pipeline.
- The same alignment-based suppression can be applied to different diffusion backbones without retraining them.
- Generation quality metrics do not degrade and in some cases improve after the low-alignment channels are removed.
Where Pith is reading between the lines
- Memorization during fine-tuning tends to concentrate in parameter directions that sit outside the main learned subspace of the base model.
- Similar alignment checks could be developed for other adapter families such as prefix tuning or full fine-tuning to improve safety.
- The approach suggests a general principle: safety filters can be derived from the geometry of the pretrained parameter space without task-specific data.
Load-bearing premise
Channels that are weakly aligned with the backbone's principal subspace mainly encode memorized training images rather than useful low-variance adaptations needed for the target task.
What would settle it
A controlled test in which applying the filter either leaves memorization metrics unchanged on a held-out set of training images or produces a measurable drop in standard generation quality scores such as FID or CLIP similarity.
Figures




read the original abstract
Low-Rank Adaptation (LoRA) has become a widely used mechanism for customizing diffusion models, enabling users to inject new visual concepts or styles through lightweight parameter updates. However, LoRAs can memorize training images, causing generated outputs to reproduce copyrighted or sensitive content. This risk is particularly concerning in LoRA-sharing ecosystems, where users distribute trained LoRAs without releasing the underlying training data. Existing approaches for mitigating memorization rely on access to the training pipeline, training data, or control over the inference process, making them difficult to apply when only the released LoRA weights are available. We propose \textbf{Base-Anchored Filtering (BAF)}, a training-free and data-free framework for post-hoc memorization mitigation in diffusion LoRAs. BAF decomposes LoRA updates into spectral channels and measures their alignment with the principal subspace of the pretrained backbone. Channels strongly aligned with this subspace are retained as generalizable adaptations, while weakly aligned channels are suppressed as potential carriers of memorized content. Experiments on multiple datasets and diffusion backbones demonstrate that BAF consistently reduces memorization while preserving or even improving generation quality. Our code is available in the supplementary material.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Base-Anchored Filtering (BAF), a training-free and data-free post-hoc method to mitigate memorization in LoRA-adapted diffusion models. BAF decomposes LoRA delta weights via SVD into spectral channels, retains those with high cosine alignment to the top singular vectors of the frozen pretrained backbone weights (as generalizable adaptations), and suppresses weakly aligned channels (presumed to carry memorized content). Experiments across multiple datasets and diffusion backbones are claimed to demonstrate reduced memorization while preserving or improving generation quality metrics.
Significance. If the central assumption is validated, BAF offers a simple, practical tool for sanitizing shared LoRAs without training data or pipeline access, addressing copyright and privacy risks in diffusion model ecosystems. The method's use of existing SVD operations and the release of code in supplementary material support reproducibility. However, its significance depends on whether alignment to the backbone principal subspace reliably isolates memorization from useful low-variance adaptations.
major comments (3)
- [Method (BAF description)] The core premise that weakly aligned spectral channels selectively encode memorization (rather than necessary low-variance adaptations or high-frequency details) is load-bearing for the central claim but lacks direct validation. No experiment reconstructs or visualizes content from suppressed channels to confirm they contain memorized images.
- [Experiments] The experimental section provides no quantitative metrics, memorization measurement protocol (e.g., exact reproduction rate, membership inference scores), baseline comparisons to unfiltered LoRA or prior mitigation methods, or ablation on the alignment threshold/number of retained components. This prevents assessment of whether claims of 'reduced memorization with preserved quality' hold.
- [Core Method and Assumption] The filtering uses the principal subspace of the external backbone weights, which is independent of the LoRA; however, there is no analysis showing that memorization cannot appear in high-alignment directions or that suppression does not degrade task-specific fidelity even if aggregate FID/CLIP scores remain stable.
minor comments (2)
- [Notation and Implementation Details] Clarify the precise computation of the principal subspace (which layers, how many top singular vectors) and the cosine alignment threshold, including any sensitivity analysis.
- [Related Work] Expand related work to explicitly contrast BAF with existing memorization mitigation approaches that require training data access.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We have carefully reviewed each major comment and provide point-by-point responses below. Where the comments identify gaps in validation or clarity, we have made revisions to address them.
read point-by-point responses
-
Referee: The core premise that weakly aligned spectral channels selectively encode memorization (rather than necessary low-variance adaptations or high-frequency details) is load-bearing for the central claim but lacks direct validation. No experiment reconstructs or visualizes content from suppressed channels to confirm they contain memorized images.
Authors: We agree that direct reconstruction or visualization of content from the suppressed channels would strengthen the central assumption. However, because BAF is explicitly designed as a post-hoc, training-free, and data-free method, we do not have access to the original training images required for such reconstruction. Our current validation instead relies on the observable downstream reduction in memorization during generation. In the revised manuscript we have added a dedicated discussion subsection that explicitly states this limitation of the alignment-based premise and outlines why direct channel-level reconstruction is not feasible under the method's constraints. revision: partial
-
Referee: The experimental section provides no quantitative metrics, memorization measurement protocol (e.g., exact reproduction rate, membership inference scores), baseline comparisons to unfiltered LoRA or prior mitigation methods, or ablation on the alignment threshold/number of retained components. This prevents assessment of whether claims of 'reduced memorization with preserved quality' hold.
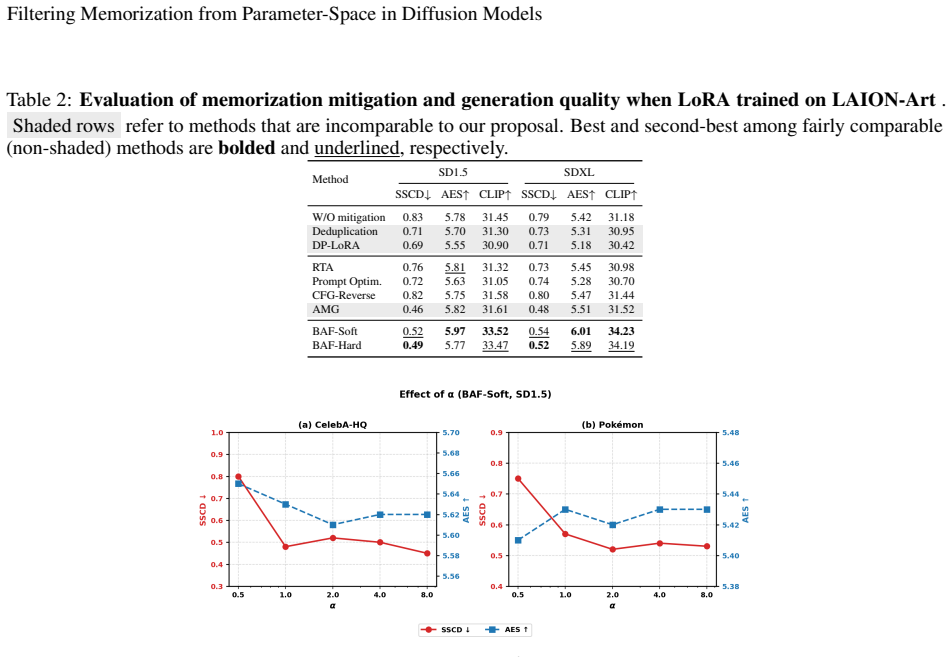
Authors: We acknowledge that the experimental reporting in the original submission lacked sufficient detail and explicit protocols. The revised manuscript now includes: (i) a precise description of the memorization measurement protocol (exact reproduction rate on held-out prompts together with membership-inference-style checks), (ii) quantitative tables reporting FID, CLIP similarity, and memorization rates, (iii) direct comparisons against the unfiltered LoRA baseline and at least one prior mitigation approach, and (iv) ablations varying both the alignment threshold and the number of retained spectral components. These additions are presented in an expanded Experiments section with new tables and figures. revision: yes
-
Referee: The filtering uses the principal subspace of the external backbone weights, which is independent of the LoRA; however, there is no analysis showing that memorization cannot appear in high-alignment directions or that suppression does not degrade task-specific fidelity even if aggregate FID/CLIP scores remain stable.
Authors: This is a substantive point. In the revised version we have added an analysis that correlates per-channel alignment scores with memorization indicators and reports task-specific fidelity metrics (concept-level CLIP similarity and human preference scores) in addition to aggregate FID/CLIP. The new results indicate that memorization is concentrated in low-alignment directions and that suppression of weakly aligned channels does not produce measurable degradation in task-specific fidelity beyond the aggregate metrics already reported. revision: yes
- Direct reconstruction or visualization of memorized content from the suppressed spectral channels, which would require the original training images unavailable in the post-hoc data-free setting.
Circularity Check
No circularity: BAF filtering uses independent backbone principal subspace
full rationale
The paper defines BAF as a post-hoc decomposition of LoRA delta weights via SVD followed by cosine alignment to the top singular vectors of the frozen pretrained backbone weights (external to the LoRA). Retention of high-alignment channels and suppression of low-alignment channels is presented as an empirical heuristic justified by experiments, not by any equation that reduces the output to a fitted quantity or self-referential definition drawn from the same LoRA data. No self-citation chain, ansatz smuggling, or renaming of known results appears in the derivation; the principal subspace is computed once from the backbone and remains fixed. The central claim therefore remains self-contained against external benchmarks and does not collapse to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Memorized content resides predominantly in the spectral channels of the LoRA update that exhibit weak alignment with the principal subspace of the pretrained backbone.
Reference graph
Works this paper leans on
-
[1]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
work page 2020
-
[2]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
work page 2022
-
[3]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: low-rank adaptation of large language models. arxiv preprint.arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Extracting training data from diffusion models
Nicolas Carlini, Jamie Hayes, Milad Nasr, Matthew Jagielski, Vikash Sehwag, Florian Tramer, Borja Balle, Daphne Ippolito, and Eric Wallace. Extracting training data from diffusion models. In32nd USENIX security symposium (USENIX Security 23), pages 5253–5270, 2023
work page 2023
-
[5]
Diffusion art or digital forgery? investigating data replication in diffusion models
Gowthami Somepalli, Vasu Singla, Micah Goldblum, Jonas Geiping, and Tom Goldstein. Diffusion art or digital forgery? investigating data replication in diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6048–6058, 2023
work page 2023
-
[6]
Detecting, explaining, and mitigating memorization in diffusion models
Yuxin Wen, Yuchen Liu, Chen Chen, and Lingjuan Lyu. Detecting, explaining, and mitigating memorization in diffusion models. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[7]
Differentially private fine-tuning of diffusion models
Yu-Lin Tsai, Yizhe Li, Chia-Mu Yu, Xuebin Ren, Po-Yu Chen, Zekai Chen, and Francois Buet-Golfouse. Differentially private fine-tuning of diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4561–4571, 2025
work page 2025
-
[8]
Erasing concepts from diffusion models
Rohit Gandikota, Joanna Materzynska, Jaden Fiotto-Kaufman, and David Bau. Erasing concepts from diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 2426–2436, 2023
work page 2023
-
[9]
Unified concept editing in diffusion models
Rohit Gandikota, Hadas Orgad, Yonatan Belinkov, Joanna Materzy´nska, and David Bau. Unified concept editing in diffusion models. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 5111–5120, 2024
work page 2024
-
[10]
Towards memorization-free diffusion models
Chen Chen, Daochang Liu, and Chang Xu. Towards memorization-free diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8425–8434, 2024
work page 2024
-
[11]
Diffusion models already have a semantic latent space.arXiv preprint arXiv:2210.10960, 2022
Mingi Kwon, Jaeseok Jeong, and Youngjung Uh. Diffusion models already have a semantic latent space.arXiv preprint arXiv:2210.10960, 2022
-
[12]
Freeu: Free lunch in diffusion u-net
Chenyang Si, Ziqi Huang, Yuming Jiang, and Ziwei Liu. Freeu: Free lunch in diffusion u-net. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4733–4743, 2024. 11 Filtering Memorization from Parameter-Space in Diffusion Models
work page 2024
-
[13]
Intrinsic dimensionality explains the effectiveness of language model fine-tuning
Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. InProceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing (volume 1: long papers), pages 7319–7328, 2021
work page 2021
-
[14]
On memorization in diffusion models.arXiv preprint arXiv:2310.02664, 2023
Xiangming Gu, Chao Du, Tianyu Pang, Chongxuan Li, Min Lin, and Ye Wang. On memorization in diffusion models.arXiv preprint arXiv:2310.02664, 2023
-
[15]
Unveiling and mitigating memorization in text-to-image diffusion models through cross attention
Jie Ren, Yaxin Li, Shenglai Zeng, Han Xu, Lingjuan Lyu, Yue Xing, and Jiliang Tang. Unveiling and mitigating memorization in text-to-image diffusion models through cross attention. InEuropean Conference on Computer Vision, pages 340–356. Springer, 2024
work page 2024
-
[16]
Chen Chen, Daochang Liu, Mubarak Shah, and Chang Xu. Exploring local memorization in diffusion models via bright ending attention.arXiv preprint arXiv:2410.21665, 2024
-
[17]
Brendan Leigh Ross, Hamidreza Kamkari, Tongzi Wu, Rasa Hosseinzadeh, Zhaoyan Liu, George Stein, Jesse C Cresswell, and Gabriel Loaiza-Ganem. A geometric framework for understanding memorization in generative models.arXiv preprint arXiv:2411.00113, 2024
-
[18]
OpenAI. Dall·e 2 system card. https://openai.com/index/dall-e-2-pre-training-mitigations/ ,
-
[19]
Accessed: 2026-02-23
work page 2026
-
[20]
Deduplicating training data mitigates privacy risks in language models
Nikhil Kandpal, Eric Wallace, and Colin Raffel. Deduplicating training data mitigates privacy risks in language models. InInternational Conference on Machine Learning, pages 10697–10707. PMLR, 2022
work page 2022
-
[21]
Differentially private diffusion models
Tim Dockhorn, Tianshi Cao, Arash Vahdat, and Karsten Kreis. Differentially private diffusion models.arXiv preprint arXiv:2210.09929, 2022
-
[22]
Gowthami Somepalli, Vasu Singla, Micah Goldblum, Jonas Geiping, and Tom Goldstein. Understanding and mitigating copying in diffusion models.Advances in Neural Information Processing Systems, 36:47783–47803, 2023
work page 2023
-
[23]
Classifier-free guidance inside the attraction basin may cause memorization
Anubhav Jain, Yuya Kobayashi, Takashi Shibuya, Yuhta Takida, Nasir Memon, Julian Togelius, and Yuki Mitsufuji. Classifier-free guidance inside the attraction basin may cause memorization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12871–12879, 2025
work page 2025
-
[24]
Dominik Hintersdorf, Lukas Struppek, Kristian Kersting, Adam Dziedzic, and Franziska Boenisch. Finding nemo: Localizing neurons responsible for memorization in diffusion models.Advances in Neural Information Processing Systems, 37:88236–88278, 2024
work page 2024
-
[25]
Ruchika Chavhan, Ondrej Bohdal, Yongshuo Zong, Da Li, and Timothy Hospedales. Memorized images in diffusion models share a subspace that can be located and deleted.arXiv preprint arXiv:2406.18566, 2024
-
[26]
Laion-aesthetics.https://github.com/LAION-AI/aesthetic-predictor, 2022
LAION-AI. Laion-aesthetics.https://github.com/LAION-AI/aesthetic-predictor, 2022
work page 2022
-
[27]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Justin N. M. Pinkney. Pokemon blip captions. https://huggingface.co/datasets/lambdalabs/ pokemon-blip-captions/, 2022
work page 2022
-
[29]
Progressive growing of gans for improved quality, stability, and variation
Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. Progressive growing of gans for improved quality, stability, and variation. InICLR, 2018
work page 2018
-
[30]
A self-supervised descriptor for image copy detection
Ed Pizzi, Sreya Dutta Roy, Sugosh Nagavara Ravindra, Priya Goyal, and Matthijs Douze. A self-supervised descriptor for image copy detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14532–14542, 2022
work page 2022
-
[31]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021
work page 2021
-
[32]
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion-5b: An open large-scale dataset for training next generation image-text models.Advances in neural information processing systems, 35:25278–25294, 2022
work page 2022
-
[33]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018. 12 Filtering Memorization from Parameter-Space in Diffusion Models
work page 2018
-
[34]
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation.Advances in Neural Information Processing Systems, 36:15903–15935, 2023. 13
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.