Recognition: 2 theorem links
· Lean TheoremHiRL: Hierarchical Reinforcement Learning for Coordinated Resource Management in Heterogeneous Edge Computing
Pith reviewed 2026-05-12 05:18 UTC · model grok-4.3
The pith
A hierarchical reinforcement learning framework separates continuous power control from discrete task allocation to improve latency and energy use in heterogeneous edge computing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
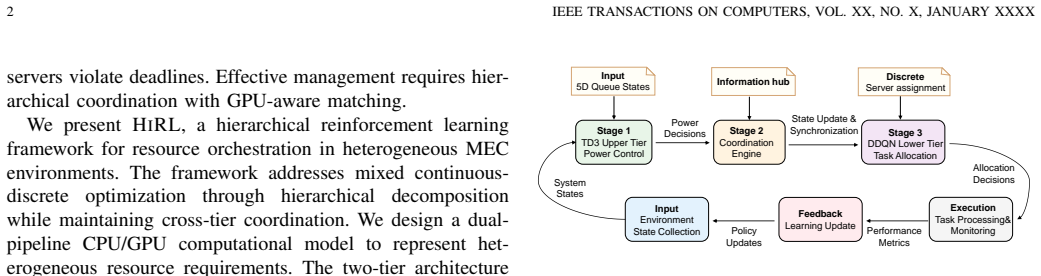
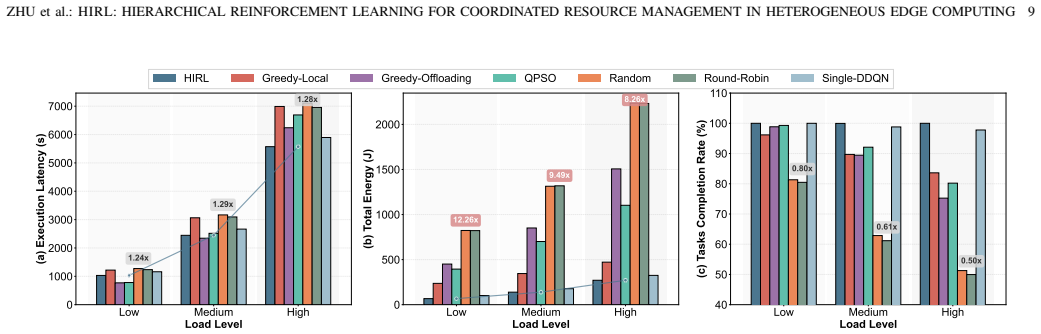
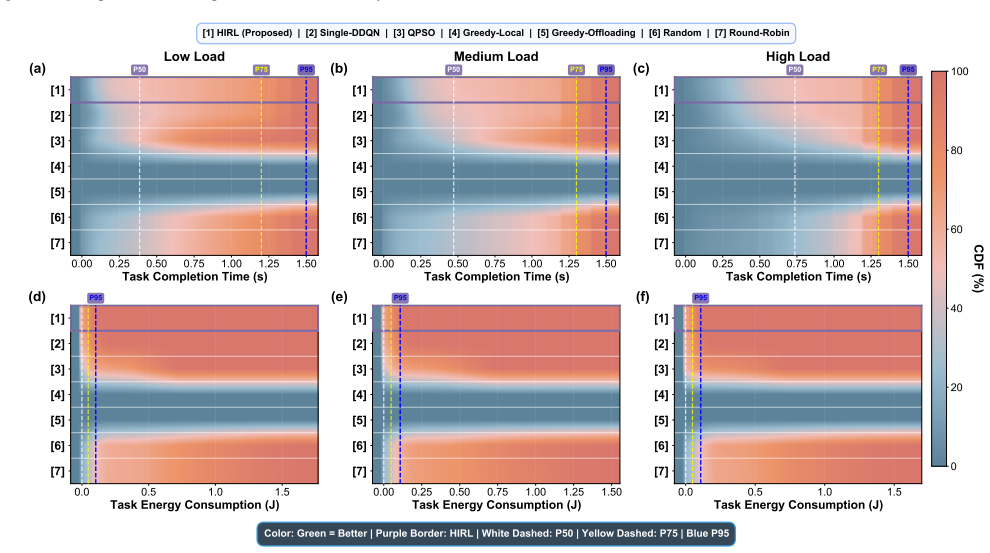
HiRL decomposes resource orchestration into coordinated power control using Twin Delayed Deep Deterministic Policy Gradient for continuous decisions and Double Deep Q-Network for discrete task placement, linked by a coordination engine with five-dimensional queue representation, heterogeneous compatibility assessment, and deadline-oriented prioritization with failure-penalized sampling, yielding 28 percent lower latency than Single-DDQN, nearly 100 percent task completion under all loads, up to 51 percent energy reduction at low load, and 24 percent better latency than static methods at high load.
What carries the argument
The coordination engine that unifies a continuous power-control agent with a discrete task-placement agent through multi-dimensional queue states and priority rules to produce joint decisions.
If this is right
- The system maintains nearly full task completion rates regardless of load level.
- Energy use drops substantially when demand is light while latency stays competitive when demand is heavy.
- The split between continuous and discrete decisions allows handling of mixed device and task types that single-agent methods struggle with.
- Incorporating mobility and congestion directly into state tracking improves robustness over static optimization.
Where Pith is reading between the lines
- The same split-agent pattern could be tested in cloud-edge hybrids where power and placement decisions cross network boundaries.
- If the coordination engine generalizes, it might reduce the need for manual tuning when new device types are added to an edge cluster.
- Physical deployment would reveal whether the five-dimensional queue view still captures the dominant delays once real radio interference appears.
Load-bearing premise
The simulations used to test the framework accurately reflect real device movement, queue buildup, device differences, and scheduling needs without overfitting to the training cases.
What would settle it
Running the same workload patterns on physical edge hardware with actual moving devices and measuring whether the reported latency and energy gains appear or disappear compared with the simulated baselines.
Figures





read the original abstract
Edge computing faces unprecedented resource orchestration challenges from multi-dimensional heterogeneity across device architectures, diverse task requirements in CPU-intensive, GPU-intensive, I/O-intensive, and dynamic network conditions. The edge environments demand real-time task processing within strict energy budgets, yet conventional approaches struggle with mixed continuous-discrete optimization while meeting deadline and energy constraints. This paper presents HiRL, a hierarchical reinforcement learning framework that decomposes complex resource orchestration into coordinated power control and task allocation decisions. Our approach separates continuous power management using the Twin Delayed Deep Deterministic Policy Gradient (TD3) and discrete task placement using Double Deep Q-Network (DDQN), unified through a coordination engine with five-dimensional queue state representation. We propose a heterogeneous assessment of resource compatibility with deadline-oriented prioritization and failure-penalized adaptive sampling to enhance decision quality under resource constraints. To improve practical applicability, the framework models comprehensive system dynamics including device mobility, queue congestion patterns, infrastructure heterogeneity, and priority-sensitive scheduling demands. Experimental results show that HiRL achieves effective latency-energy trade-offs with 28% latency reduction compared to Single-DDQN and maintains nearly 100% task completion rates under all load conditions. Compared to baseline algorithms, HiRL reduces energy consumption by up to 51% under low load while achieving 24% better latency performance than static optimization approaches under high load, establishing effective resource orchestration in heterogeneous edge environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HiRL, a hierarchical reinforcement learning framework for coordinated resource management in heterogeneous edge computing. It separates continuous power management using TD3 and discrete task placement using DDQN, coordinated through a five-dimensional queue state representation. The approach includes heterogeneous resource compatibility assessment, deadline-oriented prioritization, and failure-penalized adaptive sampling. Simulations incorporating device mobility, queue congestion, infrastructure heterogeneity, and priority-sensitive scheduling are used to demonstrate performance, with claims of 28% latency reduction versus Single-DDQN, nearly 100% task completion, up to 51% energy reduction under low load, and 24% better latency than static optimization under high load.
Significance. If the simulation-based results prove robust and the custom simulator accurately captures real-world edge dynamics, the work could advance resource orchestration in distributed computing by showing how hierarchical RL handles mixed continuous-discrete decisions under energy and latency constraints. The explicit separation of TD3 and DDQN actions plus the five-dimensional state representation is a reasonable response to heterogeneity, and the reported trade-offs with high completion rates address practical needs. The absence of validation details, however, currently caps the significance.
major comments (2)
- Abstract and Experimental Results: The specific quantitative claims (28% latency reduction vs. Single-DDQN, 51% energy reduction under low load, 24% latency improvement vs. static optimization under high load, near-100% completion) are presented without any information on simulation parameters, number of independent runs, statistical variance, exact baseline implementations, or TD3/DDQN hyperparameter choices. This is load-bearing for the central empirical claim of effective real-world orchestration.
- System Dynamics Modeling section: The assertion that the framework 'models comprehensive system dynamics' including device mobility, queue congestion, and heterogeneity is not supported by trace-driven validation, sensitivity sweeps, or hardware-in-the-loop comparisons. Without such checks, the reported performance deltas cannot be confirmed to generalize beyond the training scenarios.
minor comments (1)
- Abstract: The dense listing of technical components (TD3, DDQN, five-dimensional queue, etc.) would benefit from a single sentence clarifying how the coordination engine unifies the two policies.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with point-by-point responses, indicating revisions where we have strengthened the manuscript.
read point-by-point responses
-
Referee: Abstract and Experimental Results: The specific quantitative claims (28% latency reduction vs. Single-DDQN, 51% energy reduction under low load, 24% latency improvement vs. static optimization under high load, near-100% completion) are presented without any information on simulation parameters, number of independent runs, statistical variance, exact baseline implementations, or TD3/DDQN hyperparameter choices. This is load-bearing for the central empirical claim of effective real-world orchestration.
Authors: We agree that these details are essential for reproducibility and to substantiate the empirical claims. In the revised manuscript, we have expanded the Experimental Setup section to include comprehensive simulation parameters (number of devices, task arrival rates, mobility models, energy consumption models), execution of 10 independent runs with reported means and standard deviations, error bars and variance in all figures, detailed baseline implementations (Single-DDQN, static optimization), and full hyperparameter choices for TD3 (actor-critic networks, learning rates, target policy noise) and DDQN (Q-network architecture, replay buffer, exploration schedule). These additions directly support the quantitative claims. revision: yes
-
Referee: System Dynamics Modeling section: The assertion that the framework 'models comprehensive system dynamics' including device mobility, queue congestion, and heterogeneity is not supported by trace-driven validation, sensitivity sweeps, or hardware-in-the-loop comparisons. Without such checks, the reported performance deltas cannot be confirmed to generalize beyond the training scenarios.
Authors: We acknowledge that our evaluation relies on synthetic simulations. The simulator incorporates explicit models for device mobility (random waypoint), queue congestion (dynamic M/M/1-style queuing), and heterogeneity (CPU/GPU/I/O compatibility). In the revision, we have added sensitivity sweeps over mobility speed, load levels, and heterogeneity degrees in the Experimental Results section, confirming consistent advantages. We have also added a limitations paragraph noting the lack of trace-driven validation and hardware-in-the-loop experiments, which we plan for future work as suitable public traces are unavailable. This improves transparency while demonstrating robustness within the modeled dynamics. revision: partial
Circularity Check
No circularity: empirical RL results from simulator, no derivation chain
full rationale
The paper introduces HiRL as a hierarchical RL framework combining TD3 for continuous power decisions and DDQN for discrete task allocation, coordinated via a five-dimensional queue state and custom simulator that includes mobility and heterogeneity. All reported gains (28% latency reduction, 51% energy savings, near-100% completion) are direct outputs of training and evaluation runs rather than any closed-form derivation, fitted parameter renamed as prediction, or self-citation that bears the central claim. No equations define a quantity in terms of itself, no uniqueness theorem is invoked from prior author work, and the simulator is presented as an evaluation environment rather than a source of self-referential predictions. The work is therefore self-contained as an applied RL study whose validity rests on simulation fidelity, not on internal logical reduction.
Axiom & Free-Parameter Ledger
free parameters (2)
- Reward function weights for latency, energy, and completion penalties
- TD3 and DDQN hyperparameters including learning rates, discount factors, and exploration noise
axioms (1)
- domain assumption The resource orchestration problem can be modeled as a Markov Decision Process with the five-dimensional queue state representation.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinctionreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hierarchical reinforcement learning framework that decomposes complex resource orchestration into coordinated power control and task allocation decisions... five-dimensional queue state representation
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Twin Delayed Deep Deterministic Policy Gradient (TD3) and Double Deep Q-Network (DDQN)... failure-penalized adaptive sampling
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mobile edge computing: A survey on archi- tecture and computation offloading,
P. Mach and Z. Becvar, “Mobile edge computing: A survey on archi- tecture and computation offloading,”IEEE communications surveys & tutorials, vol. 19, no. 3, pp. 1628–1656, 2017
work page 2017
-
[2]
A. Nasir, X. He, T. Wang, H. Shi, and Z. Wang, “Relto: A reliability- oriented drl approach with context-aware adaptive reward weighting for multi-objective task offloading in mec,”Ad Hoc Networks, p. 104065, 2025
work page 2025
-
[3]
Q. Zeng, Y . Du, K. Huang, and K. K. Leung, “Energy-efficient resource management for federated edge learning with cpu-gpu heterogeneous computing,”IEEE Transactions on Wireless Communications, vol. 20, no. 12, pp. 7947–7962, 2021
work page 2021
-
[4]
A. Islam and M. Ghose, “Delta: Deadline aware energy and latency- optimized task offloading and resource allocation in gpu-enabled, pim- enabled distributed heterogeneous mec architecture,”Journal of Systems Architecture, vol. 159, p. 103335, 2025
work page 2025
-
[5]
S. H. Lee, “Real-time edge computing on multi-processes and multi- threading architectures for deep learning applications,”Microprocessors and Microsystems, vol. 92, p. 104554, 2022
work page 2022
-
[6]
Gpu-specific task offloading in the mobile edge computing network,
N. Kim, Y . Lee, C. Lee, T. V . Nguyen, V . D. Tuong, and S. Cho, “Gpu-specific task offloading in the mobile edge computing network,” in2020 International Conference on Information and Communication Technology Convergence (ICTC). IEEE, 2020, pp. 1874–1876
work page 2020
-
[7]
M. Y . Akhlaqi and Z. B. M. Hanapi, “Task offloading paradigm in mobile edge computing-current issues, adopted approaches, and future directions,”Journal of Network and Computer Applications, vol. 212, p. 103568, 2023
work page 2023
-
[8]
Joint computation offload- ing and resource allocation for maritime mec with energy harvesting,
Z. Wang, B. Lin, Q. Ye, Y . Fang, and X. Han, “Joint computation offload- ing and resource allocation for maritime mec with energy harvesting,” IEEE Internet of Things Journal, vol. 11, no. 11, pp. 19 898–19 913, 2024
work page 2024
-
[9]
C. Hou and Q. Zhao, “Optimal control of wireless powered edge computing system for balance between computation rate and energy harvested,”IEEE Transactions on Automation Science and Engineering, vol. 20, no. 2, pp. 1108–1124, 2022
work page 2022
-
[10]
L. Pan, X. Liu, Z. Jia, J. Xu, and X. Li, “A multi-objective clustering evolutionary algorithm for multi-workflow computation offloading in mobile edge computing,”IEEE Transactions on Cloud Computing, vol. 11, no. 2, pp. 1334–1351, 2021
work page 2021
-
[11]
A deep reinforcement learning-based task offloading framework for edge-cloud computing,
P. Kalpana, M. Almusawi, Y . Chanti, V . S. Kumar, and M. V . Rao, “A deep reinforcement learning-based task offloading framework for edge-cloud computing,” in2024 International Conference on Integrated Circuits and Communication Systems (ICICACS). IEEE, 2024, pp. 1–5
work page 2024
-
[12]
Dependent task offloading in edge computing using gnn and deep reinforcement learning,
Z. Cao, X. Deng, S. Yue, P. Jiang, J. Ren, and J. Gui, “Dependent task offloading in edge computing using gnn and deep reinforcement learning,”IEEE Internet of Things Journal, vol. 11, no. 12, pp. 21 632– 21 646, 2024
work page 2024
-
[13]
Y . Chen, W. Gu, J. Xu, Y . Zhang, and G. Min, “Dynamic task offloading for digital twin-empowered mobile edge computing via deep reinforcement learning,”China Communications, vol. 20, no. 11, pp. 164–175, 2023
work page 2023
-
[14]
F. Zeng, Z. Zhang, and J. Wu, “Task offloading delay minimization in vehicular edge computing based on vehicle trajectory prediction,”Digital Communications and Networks, vol. 11, no. 2, pp. 537–546, 2025
work page 2025
-
[15]
Uav-assisted task offloading in vehicular edge computing networks,
X. Dai, Z. Xiao, H. Jiang, and J. C. Lui, “Uav-assisted task offloading in vehicular edge computing networks,”IEEE Transactions on Mobile Computing, vol. 23, no. 4, pp. 2520–2534, 2023
work page 2023
-
[16]
Energy efficiency of mobile clients in cloud computing,
A. P. Miettinen and J. K. Nurminen, “Energy efficiency of mobile clients in cloud computing,” in2nd USENIX workshop on hot topics in cloud computing (HotCloud 10), 2010
work page 2010
-
[17]
Noncooperative cellular wireless with unlimited num- bers of base station antennas,
T. L. Marzetta, “Noncooperative cellular wireless with unlimited num- bers of base station antennas,”IEEE transactions on wireless communi- cations, vol. 9, no. 11, pp. 3590–3600, 2010
work page 2010
-
[18]
Quantum particle swarm optimization for task offloading in mobile edge computing,
S. Dong, Y . Xia, and J. Kamruzzaman, “Quantum particle swarm optimization for task offloading in mobile edge computing,”IEEE Transactions on Industrial Informatics, vol. 19, no. 8, pp. 9113–9122, 2022
work page 2022
-
[19]
Dynamic computation offloading for mobile-edge computing with energy harvesting devices,
Y . Mao, J. Zhang, and K. B. Letaief, “Dynamic computation offloading for mobile-edge computing with energy harvesting devices,”IEEE Journal on Selected Areas in Communications, vol. 34, no. 12, pp. 3590– 3605, 2016
work page 2016
-
[20]
L. Liu, J. Feng, X. Mu, Q. Pei, D. Lan, and M. Xiao, “Asynchronous deep reinforcement learning for collaborative task computing and on- demand resource allocation in vehicular edge computing,”IEEE Trans- actions on Intelligent Transportation Systems, vol. 24, no. 12, pp. 15 513–15 526, 2023. 14 IEEE TRANSACTIONS ON COMPUTERS, VOL. XX, NO. X, JANUARY XXXX
work page 2023
-
[21]
J. Yang, J. Lu, X. Zhou, S. Li, C. Xiong, and J. Hu, “Ha-a2c: Hard attention and advantage actor-critic for addressing latency optimization in edge computing,”IEEE Transactions on Green Communications and Networking, vol. 9, no. 1, pp. 207–217, 2024
work page 2024
-
[22]
Efficient re- source allocation policy for cloud edge end framework by reinforcement learning,
C. Yang, H. Xu, S. Fan, X. Cheng, M. Liu, and X. Wang, “Efficient re- source allocation policy for cloud edge end framework by reinforcement learning,” in2022 IEEE 8th International Conference on Computer and Communications (ICCC). IEEE, 2022, pp. 1363–1367
work page 2022
-
[23]
C. Xu, Z. Tang, H. Yu, P. Zeng, and L. Kong, “Digital twin-driven collaborative scheduling for heterogeneous task and edge-end resource via multi-agent deep reinforcement learning,”IEEE Journal on Selected Areas in Communications, vol. 41, no. 10, pp. 3056–3069, 2023
work page 2023
-
[24]
J. Xue, Q. Wu, and H. Zhang, “Cost optimization of uav-mec network calculation offloading: A multi-agent reinforcement learning method,” Ad Hoc Networks, vol. 136, p. 102981, 2022
work page 2022
-
[25]
A. Mondal, D. Mishra, G. Prasad, and H. Johansson, “Joint trajectory, user-association, and power control for green uav-assisted data collection using deep reinforcement learning,”IEEE Transactions on Intelligent Vehicles, 2024
work page 2024
-
[26]
Deep reinforcement learning-based energy-efficient edge computing for internet of vehicles,
X. Kong, G. Duan, M. Hou, G. Shen, H. Wang, X. Yan, and M. Collotta, “Deep reinforcement learning-based energy-efficient edge computing for internet of vehicles,”IEEE Transactions on Industrial Informatics, vol. 18, no. 9, pp. 6308–6316, 2022
work page 2022
-
[27]
Toward energy-aware caching for intelligent connected vehicles,
H. Wu, J. Zhang, Z. Cai, F. Liu, Y . Li, and A. Liu, “Toward energy-aware caching for intelligent connected vehicles,”IEEE Internet of Things Journal, vol. 7, no. 9, pp. 8157–8166, 2020
work page 2020
-
[28]
Y . Chen, J. Xu, Y . Wu, J. Gao, and L. Zhao, “Dynamic task offloading and resource allocation for noma-aided mobile edge computing: An energy efficient design,”IEEE Transactions on Services Computing, vol. 17, no. 4, pp. 1492–1503, 2024
work page 2024
-
[29]
Joint power and time allocation for noma–mec offloading,
Z. Ding, J. Xu, O. A. Dobre, and H. V . Poor, “Joint power and time allocation for noma–mec offloading,”IEEE Transactions on Vehicular Technology, vol. 68, no. 6, pp. 6207–6211, 2019
work page 2019
-
[30]
Energy-efficient uav- mounted ris assisted mobile edge computing,
Z. Zhai, X. Dai, B. Duo, X. Wang, and X. Yuan, “Energy-efficient uav- mounted ris assisted mobile edge computing,”IEEE wireless communi- cations letters, vol. 11, no. 12, pp. 2507–2511, 2022
work page 2022
-
[31]
Y . Yang, Y . Gong, and Y .-C. Wu, “Intelligent-reflecting-surface-aided mobile edge computing with binary offloading: Energy minimization for iot devices,”IEEE Internet of Things Journal, vol. 9, no. 15, pp. 12 973–12 983, 2022
work page 2022
-
[32]
Game theoretical task offloading for profit maximization in mobile edge computing,
H. Teng, Z. Li, K. Cao, S. Long, S. Guo, and A. Liu, “Game theoretical task offloading for profit maximization in mobile edge computing,”IEEE Transactions on Mobile Computing, vol. 22, no. 9, pp. 5313–5329, 2022
work page 2022
-
[33]
Energy-latency aware offloading for hierarchical mobile edge computing,
B. Wu, J. Zeng, L. Ge, X. Su, and Y . Tang, “Energy-latency aware offloading for hierarchical mobile edge computing,”IEEE Access, vol. 7, pp. 121 982–121 997, 2019
work page 2019
-
[34]
K. Zhang, X. Gui, D. Ren, and D. Li, “Energy–latency tradeoff for computation offloading in uav-assisted multiaccess edge computing system,”IEEE Internet of Things Journal, vol. 8, no. 8, pp. 6709–6719, 2020
work page 2020
-
[35]
A multi-layer guided reinforce- ment learning-based tasks offloading in edge computing,
A. Robles-Enciso and A. F. Skarmeta, “A multi-layer guided reinforce- ment learning-based tasks offloading in edge computing,”Computer Networks, vol. 220, p. 109476, 2023
work page 2023
-
[36]
L. Ale, N. Zhang, X. Fang, X. Chen, S. Wu, and L. Li, “Delay-aware and energy-efficient computation offloading in mobile-edge computing using deep reinforcement learning,”IEEE Transactions on Cognitive Communications and Networking, vol. 7, no. 3, pp. 881–892, 2021
work page 2021
-
[37]
H. Ma, P. Huang, Z. Zhou, X. Zhang, and X. Chen, “Greenedge: Joint green energy scheduling and dynamic task offloading in multi-tier edge computing systems,”IEEE Transactions on Vehicular Technology, vol. 71, no. 4, pp. 4322–4335, 2022
work page 2022
-
[38]
Minimizing the delay and cost of computation offloading for vehicular edge computing,
Q. Luo, C. Li, T. H. Luan, and W. Shi, “Minimizing the delay and cost of computation offloading for vehicular edge computing,”IEEE Transactions on Services Computing, vol. 15, no. 5, pp. 2897–2909, 2021
work page 2021
-
[39]
F. Song, H. Xing, X. Wang, S. Luo, P. Dai, and K. Li, “Offloading dependent tasks in multi-access edge computing: A multi-objective reinforcement learning approach,”Future Generation Computer Systems, vol. 128, pp. 333–348, 2022
work page 2022
-
[40]
C. Xu, M. Lv, K. Zhang, K. Cao, G. Wang, M. Wei, and B. Peng, “Energy consumption and time-delay optimization of dependency-aware tasks offloading for industry 5.0 applications,”IEEE Transactions on Consumer Electronics, vol. 70, no. 1, pp. 1590–1600, 2023. Jianyong Zhuis currently an assistant professor with the Department of Computing at North China Ele...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.